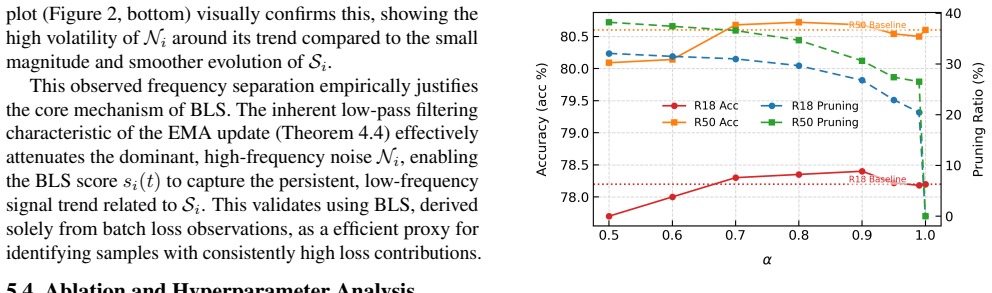
Recognition: no theorem link
Batch Loss Score for Dynamic Data Pruning
Pith reviewed 2026-05-10 19:13 UTC · model grok-4.3
The pith
The Batch Loss Score approximates each sample's smoothed contribution to the loss by applying an exponential moving average to batch losses.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By treating the batch loss as a noisy measurement of the scaled individual loss of samples in the batch, with noise originating from stochastic batch composition, it is formally shown that the exponential moving average mechanism functions as a first-order low-pass filter that attenuates the high-frequency noise and yields a score approximating the smoothed and persistent contribution of the individual sample to the loss.
What carries the argument
The exponential moving average applied to batch losses, which filters stochastic composition noise to produce per-sample importance scores.
Load-bearing premise
The batch loss can be viewed as a noisy scaled version of an individual sample's loss whose noise is dominated by random batch composition that a simple exponential moving average can reliably filter.
What would settle it
Compute true per-sample losses on a model where they are directly accessible, smooth them over training, and test whether the resulting values match the BLS scores; a clear mismatch, especially under small batch sizes or correlated sampling, would falsify the approximation.
Figures



read the original abstract
Dynamic data pruning accelerates deep learning by selectively omitting less informative samples during training. While per-sample loss is a common importance metric, obtaining it can be challenging or infeasible for complex models or loss functions, often requiring significant implementation effort. This work proposes the Batch Loss Score (BLS), a computationally efficient alternative using an Exponential Moving Average (EMA) of readily available batch losses to assign scores to individual samples. We frame the batch loss, from the perspective of a single sample, as a noisy measurement of its scaled individual loss, with noise originating from stochastic batch composition. It is formally shown that the EMA mechanism functions as a first-order low-pass filter, attenuating high-frequency batch composition noise. This yields a score approximating the smoothed and persistent contribution of the individual sample to the loss, providing a theoretical grounding for BLS as a proxy for sample importance. BLS demonstrates remarkable code integration simplicity (\textbf{three-line injection}) and readily adapts existing per-sample loss-based methods (\textbf{one-line proxy}). Its effectiveness is demonstrated by enhancing two such methods to losslessly prune \textbf{20\%-50\%} of samples across \textit{14 datasets}, \textit{11 tasks} and \textit{18 models}, highlighting its utility and broad applicability, especially for complex scenarios where per-sample loss is difficult to access. Code is available at https://github.com/mrazhou/BLS.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Batch Loss Score (BLS) as a computationally efficient proxy for per-sample loss in dynamic data pruning. It frames the observed batch loss as a noisy measurement of the scaled individual sample loss (with noise from stochastic batch composition) and formally shows that an Exponential Moving Average (EMA) of batch losses functions as a first-order low-pass filter, yielding a score that approximates the smoothed, persistent contribution of each sample. BLS is presented as a simple drop-in replacement (three-line code change) that can enhance existing per-sample-loss-based pruning methods, with empirical results showing lossless pruning of 20%-50% of samples across 14 datasets, 11 tasks, and 18 models.
Significance. If the noise-model assumptions underlying the filter derivation hold and the empirical gains are robust to hyperparameter choices and dataset variations, BLS could meaningfully simplify data pruning pipelines for complex models where direct per-sample loss computation is expensive or infeasible. The reported breadth of experiments and emphasis on code simplicity are clear strengths; the public code release further supports reproducibility.
major comments (1)
- [theoretical analysis / filter derivation] The section presenting the formal filter derivation (abstract and theoretical analysis): the claim that EMA attenuates high-frequency batch-composition noise to recover a smoothed individual loss relies on modeling the noise as zero-mean and uncorrelated with the target sample's loss. This independence assumption is load-bearing for the central theoretical grounding yet is not generally true for small batch sizes (where variance scaling does not eliminate persistent offsets) or correlated batch compositions (e.g., same-class or similar-difficulty samples). A concrete counter-example or sensitivity analysis with known per-sample losses would be needed to confirm the approximation remains valid.
minor comments (2)
- [experiments] The abstract states that BLS enables 'losslessly prune 20%-50%' of samples; an explicit definition of 'lossless' (e.g., final accuracy within statistical error of the unpruned baseline, with reported standard deviations) should appear in the experimental section.
- The practical claim of 'three-line injection' and 'one-line proxy' is attractive; including a short, self-contained code snippet in the main text or appendix would make the integration simplicity immediately verifiable.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the theoretical grounding of BLS. We address the concern regarding the noise-model assumptions point by point below and outline planned revisions.
read point-by-point responses
-
Referee: The section presenting the formal filter derivation (abstract and theoretical analysis): the claim that EMA attenuates high-frequency batch-composition noise to recover a smoothed individual loss relies on modeling the noise as zero-mean and uncorrelated with the target sample's loss. This independence assumption is load-bearing for the central theoretical grounding yet is not generally true for small batch sizes (where variance scaling does not eliminate persistent offsets) or correlated batch compositions (e.g., same-class or similar-difficulty samples). A concrete counter-example or sensitivity analysis with known per-sample losses would be needed to confirm the approximation remains valid.
Authors: We agree that the zero-mean uncorrelated noise assumption is an idealization and does not hold in general. From a single sample's perspective the observed batch loss equals its own scaled loss plus the average loss of the remaining B-1 samples; when batches are small or contain correlated samples (same class, similar difficulty), this average can introduce non-zero mean offsets or low-frequency correlations rather than purely high-frequency noise. The EMA nevertheless continues to act as a temporal low-pass filter that emphasizes persistent per-sample contributions across successive batches. Our broad empirical results (lossless 20-50% pruning on 14 datasets, 11 tasks, 18 models) indicate the resulting scores remain practically useful even when the idealized model is violated. In the revision we will (i) explicitly state the modeling assumptions and their limitations in the theoretical section and (ii) add a sensitivity-analysis subsection that reports BLS performance across a range of batch sizes and on class-balanced versus class-imbalanced subsets, comparing against ground-truth per-sample losses where computationally feasible. revision: yes
Circularity Check
No circularity: derivation from explicit noise model and standard filter theory
full rationale
The paper's central claim frames batch loss as a noisy scaled individual loss (with noise from stochastic batch composition) and shows via the EMA update rule that it acts as a first-order low-pass filter attenuating high-frequency components. This is presented as a direct consequence of the stated noise model and the known properties of exponential moving averages in signal processing, without any parameter fitting to the target quantity, self-citation of prior uniqueness results, or redefinition of inputs as outputs. No load-bearing step reduces by construction to the paper's own fitted values or self-referential premises; the approximation is derived independently from the modeling assumptions.
Axiom & Free-Parameter Ledger
free parameters (1)
- EMA smoothing factor
axioms (1)
- domain assumption The batch loss serves as a noisy measurement of the scaled individual sample loss due to stochastic batch composition.
Reference graph
Works this paper leans on
-
[1]
Agrawal, K
H. Agrawal, K. Desai, Y . Wang, X. Chen, R. Jain, M. Johnson, D. Batra, D. Parikh, S. Lee, and P. Anderson. Nocaps: Novel object captioning at scale. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 8948– 8957, 2019. 5
2019
-
[2]
Variance reduction in sgd by distributed importance sampling.arXiv preprint arXiv:1511.06481,
G. Alain, A. Lamb, C. Sankar, A. Courville, and Y . Bengio. Variance reduction in sgd by distributed importance sampling. arXiv preprint arXiv:1511.06481, 2015. 2
-
[3]
Bengio, J
Y . Bengio, J. Louradour, R. Collobert, and J. Weston. Curricu- lum learning. InProceedings of the 26th annual international conference on machine learning, pages 41–48, 2009. 2
2009
-
[4]
Carion, F
N. Carion, F. Massa, G. Synnaeve, N. Usunier, A. Kirillov, and S. Zagoruyko. End-to-end object detection with trans- formers. InEuropean conference on computer vision, pages 213–229. Springer, 2020. 1
2020
-
[5]
L.-C. Chen, G. Papandreou, I. Kokkinos, K. Murphy, and A. L. Yuille. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. volume 40, pages 834–848. IEEE, 2017. 1
2017
-
[7]
X. Chen, H. Fang, T.-Y . Lin, R. Vedantam, S. Gupta, P. Dollár, and C. L. Zitnick. Microsoft coco captions: Data collection and evaluation server.arXiv preprint arXiv:1504.00325, 2015. 5
work page internal anchor Pith review arXiv 2015
-
[8]
Coleman, C
C. Coleman, C. Yeh, S. Mussmann, B. Mirzasoleiman, P. Bailis, P. Liang, J. Leskovec, and M. Zaharia. Selection via proxy: Efficient data selection for deep learning. InInter- national Conference on Learning Representations, 2020. 1, 2
2020
-
[9]
L. Deng. The mnist database of handwritten digit images for machine learning research [best of the web].IEEE Signal Processing Magazine, 29(6):141–142, 2012. 5
2012
-
[10]
Dosovitskiy, L
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale. InInternational Conference on Learning Representations, 2021. 1, 5
2021
-
[11]
Evans, S
T. Evans, S. Pathak, H. Merzic, J. Schwarz, R. Tanno, and O. J. Hénaff. Bad students make great teachers: Active learning accelerates large-scale visual understanding. InProceedings of the 18th European Conference on Computer Vision, volume 15075, pages 264–280. Springer, 2024. 4
2024
-
[12]
S. Fang, H. Xie, Y . Wang, Z. Mao, and Y . Zhang. Read like humans: Autonomous, bidirectional and iterative lan- guage modeling for scene text recognition. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7094–7103, 2021. 5
2021
-
[13]
J. Fei, T. Wang, J. Zhang, Z. He, C. Wang, and F. Zheng. Transferable decoding with visual entities for zero-shot image captioning. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 3136–3146, 2023. 5
2023
-
[14]
Y . Feng, L. Ma, W. Liu, and J. Luo. Unsupervised image captioning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4125–4134,
-
[15]
Gupta, A
A. Gupta, A. Vedaldi, and A. Zisserman. Synthetic data for text localisation in natural images. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2315–2324, 2016. 5
2016
-
[16]
K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 770–778, 2016. 5
2016
-
[17]
M. He, S. Yang, T. Huang, and B. Zhao. Large-scale dataset pruning with dynamic uncertainty. pages 7713–7722, 2024. 1
2024
-
[18]
J. Ho, A. Jain, and P. Abbeel. Denoising diffusion proba- bilistic models.Advances in neural information processing systems, 33:6840–6851, 2020. 5
2020
-
[19]
Classifier-Free Diffusion Guidance
J. Ho and T. Salimans. Classifier-free diffusion guidance. arXiv preprint arXiv:2207.12598, 2022. 5
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[20]
Huang, H
S. Huang, H. Zhang, and X. Li. Enhance vision-language alignment with noise. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 17449–17457,
-
[21]
R. Iyer, N. Khargoankar, J. Bilmes, and H. Asanani. Submod- ular combinatorial information measures with applications in machine learning. InProceedings of the 34th Annual Confer- ence on Algorithmic Learning Theory, pages 722–754, 2021. 2
2021
-
[22]
M. Jaderberg, K. Simonyan, A. Vedaldi, and A. Zisserman. Synthetic data and artificial neural networks for natural scene text recognition.ArXiv, abs/1406.2227, 2014. 5
-
[23]
Katharopoulos and F
A. Katharopoulos and F. Fleuret. Not all samples are created equal: Deep learning with importance sampling. InInter- national conference on machine learning, pages 2538–2547. PMLR, 2018. 2
2018
-
[24]
D. P. Kingma and M. Welling. Auto-encoding variational bayes. In Y . Bengio and Y . LeCun, editors,International Conference on Learning Representations, 2014. 5
2014
-
[25]
Krizhevsky, V
A. Krizhevsky, V . Nair, and G. Hinton. Cifar-100 (canadian institute for advanced research). 5
-
[26]
J. Liu, J. Gao, S. Ji, C. Zeng, S. Zhang, and J. Gong. Deep learning based multi-view stereo matching and 3d scene re- construction from oblique aerial images.ISPRS Journal of Photogrammetry and Remote Sensing, 204:42–60, 2023. 5
2023
-
[27]
Liu and S
J. Liu and S. Ji. A novel recurrent encoder-decoder structure for large-scale multi-view stereo reconstruction from an open aerial dataset. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6050–6059,
-
[28]
Z. Liu, Y . Lin, Y . Cao, H. Hu, Y . Wei, Z. Zhang, S. Lin, and B. Guo. Swin transformer: Hierarchical vision transformer using shifted windows. InProceedings of the IEEE/CVF international conference on computer vision, pages 10012– 10022, 2021. 5
2021
-
[29]
J. Long, E. Shelhamer, and T. Darrell. Fully convolutional networks for semantic segmentation. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 3431–3440, 2015. 1
2015
-
[30]
Loshchilov and F
I. Loshchilov and F. Hutter. Online batch selection for faster training of neural networks. InInternational Conference on Learning Representations, 2016. 1, 2
2016
-
[31]
Mindermann, I
S. Mindermann, I. Babuschkin, J. DWI Setyawan, J. W. Rae, M. Warkentin, N. Savinov, O. Vinyals, R. Hadsell, M. Vla- dymyrov, and J. Grau-Moya. Prioritized training on points that are learnable, worth learning, and not yet learned. In International Conference on Machine Learning, pages 15703– 15731. PMLR, 2022. 1, 2
2022
-
[32]
A. V . Oppenheim.Discrete-time signal processing. Pearson Education India, 1999. 3, 4
1999
-
[33]
Paszke, S
A. Paszke, S. Gross, F. Massa, A. Lerer, J. Bradbury, G. Chanan, T. Killeen, Z. Lin, N. Gimelshein, L. Antiga, et al. Pytorch: An imperative style, high-performance deep learning library. InAdvances in neural information processing systems, volume 32, 2019. 1
2019
-
[34]
M. Paul, S. Ganguli, and G. K. Dziugaite. Deep learning on a data diet: Finding important examples early in training. Advances in neural information processing systems, 34:20596– 20607, 2021. 1, 2, 5
2021
-
[35]
K. J. Piczak. Esc: Dataset for environmental sound clas- sification. InProceedings of the 23rd ACM international conference on Multimedia, pages 1015–1018, 2015. 5
2015
-
[36]
Z. Qin, K. Wang, Z. Zheng, J. Gu, X. Peng, xu Zhao Pan, D. Zhou, L. Shang, B. Sun, X. Xie, and Y . You. Infobatch: Lossless training speed up by unbiased dynamic data prun- ing. InThe Twelfth International Conference on Learning Representations, 2024. 1, 2, 5, 4
2024
-
[37]
Radford, J
A. Radford, J. Wu, R. Child, D. Luan, D. Amodei, and I. Sutskever. Language models are unsupervised multitask learners. 2019. 1
2019
- [38]
-
[39]
Redmon, S
J. Redmon, S. Divvala, R. Girshick, and A. Farhadi. You only look once: Unified, real-time object detection. InProceed- ings of the IEEE conference on computer vision and pattern recognition, pages 779–788, 2016. 1, 5, 2, 3
2016
-
[40]
Russakovsky, J
O. Russakovsky, J. Deng, H. Su, J. Krause, S. Satheesh, S. Ma, Z. Huang, A. Karpathy, A. Khosla, M. S. Bernstein, A. C. Berg, and L. Fei-Fei. Imagenet large scale visual recognition challenge. InProceedings of the IEEE/CVF International Conference on Computer Vision, volume 115, pages 211–252,
-
[41]
Sener and S
O. Sener and S. Savarese. Active learning for convolutional neural networks: A core-set approach. InInternational Con- ference on Learning Representations, 2018. 2
2018
- [42]
-
[43]
K. Sohn, D. Berthelot, N. Carlini, Z. Zhang, H. Zhang, C. A. Raffel, E. D. Cubuk, A. Kurakin, and C.-L. Li. Fixmatch: Simplifying semi-supervised learning with consistency and confidence.Advances in neural information processing sys- tems, 33:596–608, 2020. 5
2020
-
[44]
Tan and Q
M. Tan and Q. Le. Efficientnet: Rethinking model scaling for convolutional neural networks. InInternational conference on machine learning, pages 6105–6114, 2019. 5
2019
-
[45]
Toneva, A
M. Toneva, A. Sordoni, A. V . Comport, A. Trischler, Y . Ben- gio, and G. J. Gordon. An empirical study of example forget- ting during deep neural network learning. InInternational Conference on Learning Representations, 2019. 2, 5
2019
-
[46]
Y . Wang, H. Chen, Y . Fan, W. Sun, R. Tao, W. Hou, R. Wang, L. Yang, Z. Zhou, L.-Z. Guo, et al. Usb: A unified semi- supervised learning benchmark for classification.Advances in Neural Information Processing Systems, 35:3938–3961,
-
[47]
P. Welch. The use of fast fourier transform for the estimation of power spectra: A method based on time averaging over short, modified periodograms.IEEE Transactions on Audio and Electroacoustics, 15(2):70–73, 1967. 7
1967
-
[48]
J. Xu, T. Mei, T. Yao, and Y . Rui. Msr-vtt: A large video description dataset for bridging video and language. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5288–5296, 2016. 5
2016
-
[49]
Y . Xu, L. Shang, J. Ye, Q. Qian, Y .-F. Li, B. Sun, H. Li, and R. Jin. Dash: Semi-supervised learning with dynamic thresh- olding. InInternational conference on machine learning, pages 11525–11536, 2021. 5
2021
-
[50]
S. Yang, Z. Xie, H. Peng, M. Xu, M. Sun, and P. Li. Dataset pruning: Reducing training data by examining generaliza- tion influence. InThe Eleventh International Conference on Learning Representations, 2023. 5
2023
-
[51]
Yelp Open Dataset
Yelp, Inc. Yelp Open Dataset. Web Page. Accessed: 2025- 05-12. 5
2025
-
[52]
Zhang, Y
B. Zhang, Y . Wang, W. Hou, H. Wu, J. Wang, M. Okumura, and T. Shinozaki. Flexmatch: Boosting semi-supervised learning with curriculum pseudo labeling.Advances in neural information processing systems, 34:18408–18419, 2021. 5
2021
-
[53]
Zhang, S
H. Zhang, S. Huang, Y . Guo, and X. Li. Variational positive- incentive noise: How noise benefits models.IEEE Trans- actions on Pattern Analysis and Machine Intelligence, 2025. 1
2025
-
[54]
Q. Zhou, J. Gao, and Q. Wang. Scale efficient training for large datasets. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 20458–20467, 2025. 1, 2, 5, 4
2025
- [55]
-
[56]
L. Zhu, B. Liao, Q. Zhang, X. Wang, W. Liu, and X. Wang. Vision mamba: Efficient visual representation learning with bidirectional state space model. InProceedings of the 41st International Conference on Machine Learning, 2024. 5 Batch Loss Score for Dynamic Data Pruning Supplementary Material
2024
-
[57]
Simplicity of BLS:One-Line Proxyand Seam- less Integration A hallmark of BLS is its exceptional ease of integration into existing training workflows, particularly when enhancing dynamic data selection frameworks like InfoBatch [36] or SeTa [54] that were originally designed around per-sample losses (li(t)). BLS achieves this through a conceptualone- line ...
-
[58]
This is the standard initializa- tion of the base pruning framework (e.g., InfoBatch)
Line 3 (Framework Wrapping): InfoBatchInst ←InfoBatch(...) . This is the standard initializa- tion of the base pruning framework (e.g., InfoBatch). The subsequent BLS proxy (Line 4) builds upon this
-
[59]
The Dat- aLoader utilizes the custom sampler provided by the DataHandler (the BLS-proxied InfoBatch instance)
Line 5 (Sampler Integration): Loader ←DataLoader(DataHandler, sampler=DataHandler.sampler). The Dat- aLoader utilizes the custom sampler provided by the DataHandler (the BLS-proxied InfoBatch instance). This sampler now implicitly operates based on scores that will be generated and maintained by BLS
-
[60]
This line, within the training loop, calls the update method
Line 12 (Proxied Update Call): loss_final← DataHandler.update(Lt). This line, within the training loop, calls the update method. Crucially, due to the BLS proxy, this method now takes the standard Effort Width ∝ Code Lines (BLS: 3 | InfoBatch: 33+) BLS Linear Path Per-Sample Loss (InfoBatch) – Complex Branches BLS: Lightweight Black-Box Integration vs. In...
-
[61]
hardness
On the Practical Difficulty of Obtaining Per- Sample Losses The main text highlights the practical challenges in obtain- ing per-sample losses li(t) for dynamic data selection. This appendix provides a more granular discussion of these diffi- culties, underscoring the motivation for methods like BLS that operate solely on aggregated batch losses. We first...
-
[62]
Efficiency Metric Justification. Table 9. Computational overhead of BLS with InfoBatch and SeTa (1M samples, NVIDIA RTX 3090 GPU). Method Overhead R18 P/B 734.1s R50 P/B 2122.4s InfoBatch 0.236s 0.03% 0.01% BLS-InfoBatch 0.253s 0.03% 0.01% SeTa 10.001s 1.4% 0.5% BLS-SeTa 10.021s 1.4% 0.5% Reproducing wall-clock time reductions for dynamic pruning is notor...
-
[63]
Primarily, BLS functions as a scoring mechanism
Limitations While BLS offers significant advantages in simplicity and applicability, its current operational scope has some consid- erations. Primarily, BLS functions as a scoring mechanism. When integrated into existing dynamic pruning frameworks like InfoBatch [36] or SeTa [54], it replaces their per-sample loss-based scoring but does not inherently alt...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.