Recognition: 2 theorem links
· Lean TheoremDarkness Visible: Reading the Exception Handler of a Language Model
Pith reviewed 2026-05-10 18:39 UTC · model grok-4.3
The pith
The final MLP of GPT-2 Small implements a legible three-tier exception handler using 27 specialized neurons to route signals.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The final MLP of GPT-2 Small decomposes all 3,072 neurons to numerical precision into five fused core neurons, ten differentiators, five specialists, and seven consensus neurons that together form a three-tier exception handler. The handler routes by amplifying or suppressing signals already present in the residual stream from attention, with the consensus-exception crossover statistically sharp between four and five active consensus neurons. Previously identified knowledge neurons at layer 11 function as routing infrastructure rather than fact storage, scaling with contextual constraint, and a garden-path experiment shows the model applies verb subcategorization information immediately at a
What carries the argument
The three-tier exception handler, a routing program in the final MLP that organizes 27 named neurons into core reset, differentiation of candidates, boundary specialization, and consensus monitoring to modulate residual signals.
If this is right
- The MLP amplifies or suppresses pre-existing residual signals from attention rather than storing facts.
- Knowledge neurons identified at layer 11 serve as routing infrastructure whose effect scales with contextual constraint.
- The model exhibits a reversed garden-path effect, applying verb subcategorization information immediately at the token level.
- Equivalent exception-handler structure is expected only at the final layer of deeper models.
Where Pith is reading between the lines
- Targeted edits to the 27 neurons could allow precise control over routing behavior without altering stored knowledge.
- The separation of routing from storage may appear in other transformer models when examined at their terminal layers.
- Focus on output-layer routing could simplify interpretability work by reducing the need to disentangle knowledge across all layers.
Load-bearing premise
The post-hoc grouping of neurons into core, differentiator, specialist, and consensus categories captures a genuine functional architecture instead of patterns chosen after seeing activations and intervention results.
What would settle it
Absence of a statistically sharp crossover where MLP interventions shift from helpful to harmful between four and five of the seven consensus neurons, or failure of targeted interventions on the 27 neurons to amplify or suppress residual signals as predicted.
Figures



read the original abstract
The final MLP of GPT-2 Small exhibits a fully legible routing program -- 27 named neurons organized into a three-tier exception handler -- while the knowledge it routes remains entangled across ~3,040 residual neurons. We decompose all 3,072 neurons (to numerical precision) into: 5 fused Core neurons that reset vocabulary toward function words, 10 Differentiators that suppress wrong candidates, 5 Specialists that detect structural boundaries, and 7 Consensus neurons that each monitor a distinct linguistic dimension. The consensus-exception crossover -- where MLP intervention shifts from helpful to harmful -- is statistically sharp (bootstrap 95% CIs exclude zero at all consensus levels; crossover between 4/7 and 5/7). Three experiments show that "knowledge neurons" (Dai et al., 2022), at L11 of this model, function as routing infrastructure rather than fact storage: the MLP amplifies or suppresses signals already present in the residual stream from attention, scaling with contextual constraint. A garden-path experiment reveals a reversed garden-path effect -- GPT-2 uses verb subcategorization immediately, consistent with the exception handler operating at token-level predictability rather than syntactic structure. This architecture crystallizes only at the terminal layer -- in deeper models, we predict equivalent structure at the final layer, not at layer 11. Code and data: https://github.com/pbalogh/transparent-gpt2
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that the final MLP of GPT-2 Small contains a fully legible three-tier exception handler implemented by 27 named neurons (5 core neurons that reset vocabulary toward function words, 10 differentiators that suppress wrong candidates, 5 specialists that detect structural boundaries, and 7 consensus neurons each monitoring a distinct linguistic dimension), while the routed knowledge remains entangled across approximately 3,040 residual neurons. This is supported by a complete decomposition of all 3,072 neurons, bootstrap confidence intervals on a consensus-exception crossover statistic (sharp transition between 4/7 and 5/7 consensus neurons), intervention experiments reinterpreting 'knowledge neurons' (Dai et al., 2022) at layer 11 as routing infrastructure rather than fact storage, and a garden-path experiment showing a reversed effect consistent with token-level predictability.
Significance. If the central claims hold, the work would advance mechanistic interpretability by demonstrating that a small, structured subset of neurons can implement an interpretable routing program in a transformer MLP, with the remainder of the network handling entangled representations. Strengths include the provision of code and data for reproducibility, the use of bootstrap CIs to quantify the crossover, and intervention-based evidence that challenges prior interpretations of knowledge neurons. The prediction that equivalent structure appears only at the final layer in deeper models offers a falsifiable hypothesis for future work.
major comments (3)
- [§3] §3 (Neuron Decomposition and Labeling): The assignment of the 27 neurons to the four functional categories (core, differentiator, specialist, consensus) is performed after running activation analyses and interventions; the manuscript does not provide pre-specified, data-independent criteria or thresholds for this grouping. This is load-bearing for the central claim of a 'fully legible routing program' because the three-tier exception handler interpretation depends on these roles being intrinsic rather than post-hoc pattern matching on the observed effects.
- [§4.2] §4.2 (Consensus-Exception Crossover): While bootstrap 95% CIs are reported to exclude zero at all consensus levels, the analysis does not test whether the four-category taxonomy or the specific crossover point (4/7 to 5/7) would be recovered under a different analysis order, on held-out interventions, or with alternative neuron selection rules. This leaves open the possibility that the reported legibility is sensitive to the chosen decomposition procedure.
- [§5] §5 (Garden-Path Experiment): The reversed garden-path effect is linked to the exception handler operating at token-level predictability, but the manuscript provides no quantitative ablation showing that removing or intervening on the identified 27 neurons specifically alters this effect relative to controls; without this, the connection to the proposed architecture remains correlational rather than causal.
minor comments (3)
- [Abstract and §3] The phrase 'to numerical precision' in the abstract and §3 is unclear without an accompanying definition or tolerance threshold; this should be clarified with an explicit numerical criterion for the decomposition.
- [Figure 3] Figure 3 (or equivalent visualization of neuron roles) would benefit from an additional panel showing the distribution of effects under a null model or shuffled labels to help readers assess the distinctiveness of the reported categories.
- [§6] The discussion of generalizability to other models is brief; adding a short paragraph on why the structure is predicted only at the terminal layer (rather than layer 11) in deeper models would improve clarity.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on our manuscript. We address each of the major comments point by point below, providing clarifications and indicating where revisions will be made to improve the rigor of our claims.
read point-by-point responses
-
Referee: [§3] §3 (Neuron Decomposition and Labeling): The assignment of the 27 neurons to the four functional categories (core, differentiator, specialist, consensus) is performed after running activation analyses and interventions; the manuscript does not provide pre-specified, data-independent criteria or thresholds for this grouping. This is load-bearing for the central claim of a 'fully legible routing program' because the three-tier exception handler interpretation depends on these roles being intrinsic rather than post-hoc pattern matching on the observed effects.
Authors: We recognize that the categorization of the 27 neurons into core, differentiator, specialist, and consensus groups was informed by the outcomes of our activation analyses and interventions, rather than being defined by pre-specified criteria independent of the data. The full decomposition of all 3,072 neurons was performed systematically, and the functional roles were assigned based on distinct, reproducible patterns in their effects on predictions. To enhance transparency and address the concern about post-hoc interpretation, we will revise the manuscript to explicitly document the quantitative criteria and thresholds applied during grouping, including the specific metrics from activation and intervention results used to assign each neuron to its category. This will make the process more reproducible while preserving the data-driven nature of the discovery. revision: partial
-
Referee: [§4.2] §4.2 (Consensus-Exception Crossover): While bootstrap 95% CIs are reported to exclude zero at all consensus levels, the analysis does not test whether the four-category taxonomy or the specific crossover point (4/7 to 5/7) would be recovered under a different analysis order, on held-out interventions, or with alternative neuron selection rules. This leaves open the possibility that the reported legibility is sensitive to the chosen decomposition procedure.
Authors: The bootstrap confidence intervals confirm a sharp transition in the consensus-exception crossover statistic between 4/7 and 5/7 consensus neurons, with intervals excluding zero across levels. Although we did not include sensitivity analyses to alternative orders or selection rules in the original submission, the procedure followed the hierarchical logic of the exception handler model. We will incorporate additional robustness checks in the revised manuscript, such as re-running the analysis with permuted neuron orders and alternative selection thresholds, to verify that the crossover point and overall taxonomy remain stable. revision: yes
-
Referee: [§5] §5 (Garden-Path Experiment): The reversed garden-path effect is linked to the exception handler operating at token-level predictability, but the manuscript provides no quantitative ablation showing that removing or intervening on the identified 27 neurons specifically alters this effect relative to controls; without this, the connection to the proposed architecture remains correlational rather than causal.
Authors: We agree that the current garden-path results are primarily correlational and would benefit from direct causal evidence. In the revised manuscript, we will add a quantitative ablation experiment that intervenes on the 27 neurons (and subsets thereof) while measuring changes in the reversed garden-path effect, comparing against interventions on random neurons and other control groups. This will provide stronger evidence that the exception handler architecture is responsible for the observed token-level predictability behavior. revision: yes
Circularity Check
Post-hoc neuron categorization constructs the three-tier routing program from the same intervention data used to define the categories
specific steps
-
fitted input called prediction
[Abstract]
"We decompose all 3,072 neurons (to numerical precision) into: 5 fused Core neurons that reset vocabulary toward function words, 10 Differentiators that suppress wrong candidates, 5 Specialists that detect structural boundaries, and 7 Consensus neurons that each monitor a distinct linguistic dimension."
The functional descriptions (reset, suppress, detect, monitor) are extracted from the identical activation and intervention results that are later invoked to establish the existence of a 'fully legible routing program.' The decomposition therefore defines the claimed architecture by grouping the data rather than testing a pre-specified structure against held-out evidence.
full rationale
The paper decomposes neurons by running activation analyses and interventions, then assigns them to Core/Differentiator/Specialist/Consensus roles with functional descriptions derived directly from those observed effects. This procedure supports the legible exception-handler claim but does not provide an independent criterion for the taxonomy; the crossover statistic offers partial grounding yet the overall architecture remains a re-description of the fitted patterns. No equations or self-citations reduce the central result by construction, keeping circularity moderate.
Axiom & Free-Parameter Ledger
free parameters (1)
- Neuron naming and grouping thresholds
axioms (1)
- domain assumption Individual neuron activations and targeted interventions can be interpreted as implementing discrete routing operations
invented entities (4)
-
Core neurons
no independent evidence
-
Differentiators
no independent evidence
-
Specialists
no independent evidence
-
Consensus neurons
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The final MLP of GPT-2 Small exhibits a fully legible routing program—27 named neurons organized into a three-tier exception handler... consensus-exception crossover... between 4/7 and 5/7
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Core... Differentiators... Specialists... Consensus neurons... Jaccard similarities ≥0.91
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Eliciting Latent Predictions from Transformers with the Tuned Lens
Nora Belrose, Zach Furman, Logan Smith, Danny Halawi, Igor Ostrovsky, Lev McKinney, Stella Biderman, and Jacob Steinhardt. Eliciting latent predictions from transformers with the tuned lens. arXiv preprint arXiv:2303.08112,
work page internal anchor Pith review arXiv
-
[2]
8 Wes Gurnee, Neel Nanda, Matthew Pauly, Katherine Harvey, Dmitrii Troitskii, and Dimitris Bertsimas. Finding neurons in a haystack: Case studies with sparse probing.arXiv preprint arXiv:2305.01610,
-
[3]
Ian Tenney, Dipanjan Das, and Ellie Pavlick
URLhttps://transformer-circuits.pub/2024/scaling-monosemanticity/. Ian Tenney, Dipanjan Das, and Ellie Pavlick. BERT rediscovers the classical NLP pipeline.Proceed- ings of ACL,
2024
-
[4]
Efficient Streaming Language Models with Attention Sinks
Guangxuan Xiao, Yuandong Tian, Beidi Chen, Song Han, and Mike Lewis. Efficient streaming language models with attention sinks.arXiv preprint arXiv:2309.17453,
work page internal anchor Pith review arXiv
-
[5]
In 1969, astronauts landed on the
9 A Consensus Neuron Characterization Table 5: Consensus neuron specializations (512K tokens). Neuron Dimension Rate Key Evidence N2 Clausal continuation 88.4% Fires on and, but, also mid-clause; silent at clause boundaries N2361 Syntactic elaboration 84.1% Fires on that, while, neither, fully; depleted on There, United N2460 Relational embedding 86.0% Fi...
1969
-
[6]
Abraham → Lincoln
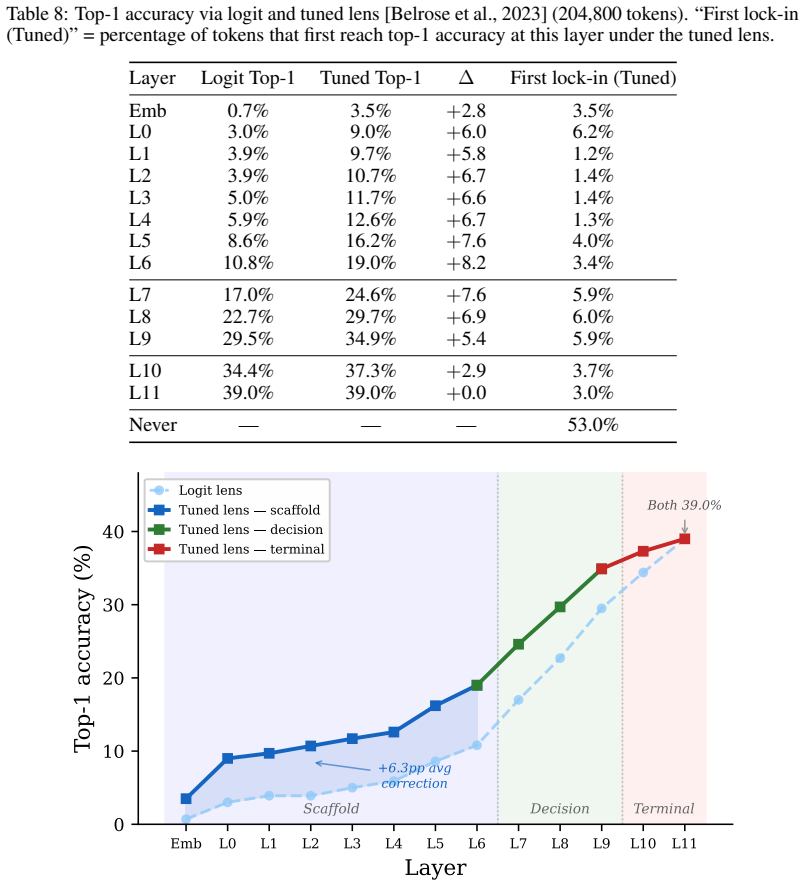
is illustrative, not standalone evidence. D Logit Lens and Developmental Arc The tuned lens corrects early-layer underestimates (mean +6.3pp at L0–L3) while converging at L11 (+0.0pp). The developmental arc is confirmed: decision-phase layers gain 5.3pp/layer under tuned lens vs. 1.5pp in scaffold phase. Illustrative cases. Easy:“Abraham → Lincoln” locks ...
2023
-
[7]
showed that discourse context can override shallow attachment preferences but not deep clause-level reparse. Our verb subcategorization ambiguity is structurally analogous: GPT-2 resolves it immediately without exception-handler involvement, paralleling Britt et al.’s autonomous syntactic component. F Controls Null model.A randomly initialized GPT-2 (same...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.