Recognition: no theorem link
How Far Are We? Systematic Evaluation of LLMs vs. Human Experts in Mathematical Contest in Modeling
Pith reviewed 2026-05-10 18:43 UTC · model grok-4.3
The pith
State-of-the-art LLMs perform well on early modeling stages but show persistent shortfalls in solving models, writing code, and analyzing results, even at larger scales.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
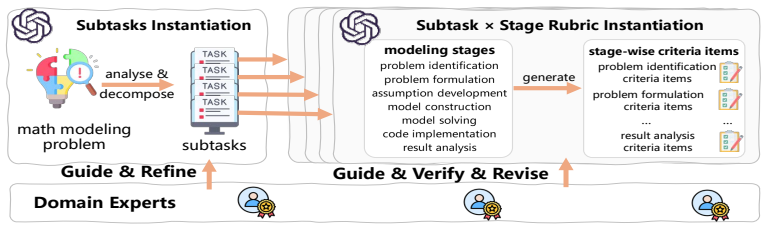
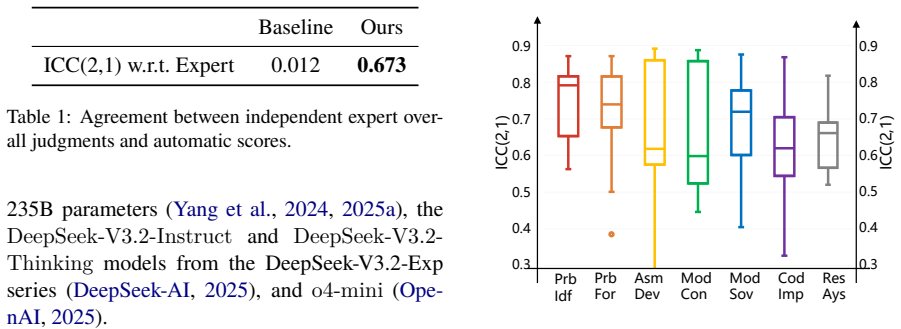
Using a new problem-oriented, stage-wise evaluation framework validated against human expert judgments on China Postgraduate Mathematical Contest in Modeling problems, the paper finds that LLMs exhibit a comprehension-execution gap: they succeed in problem identification and formulation but display clear deficiencies in model solving, code implementation, and result analysis. These execution weaknesses persist across larger models and stem from insufficient specification, absent verification, and lack of validation, allowing errors to propagate uncorrected through the workflow.
What carries the argument
A problem-oriented, stage-wise evaluation framework that breaks the modeling process into sequential stages and scores LLM outputs against expert-verified criteria for each stage.
If this is right
- Approaches beyond simply scaling model size are needed to close the identified execution gap in complex problem solving.
- Errors originating in early stages propagate to later ones because current LLMs lack built-in mechanisms for specification checking and validation.
- The new framework offers a more reliable alternative to existing benchmarks for measuring multi-stage reasoning capabilities.
- Insights into the specific failure modes can guide the design of LLM systems for other end-to-end real-world tasks.
Where Pith is reading between the lines
- Adding external verification tools or iterative self-checking loops could reduce error propagation in modeling workflows.
- Comparable execution gaps are likely to appear in other domains that require chained specification, implementation, and validation steps.
- Future evaluations could automate checks for verification behavior to isolate whether the deficiencies are architectural or training-related.
Load-bearing premise
The stage-wise scoring system, when checked against human expert judgments on contest problems, accurately measures genuine end-to-end problem-solving ability rather than just surface-level text quality.
What would settle it
A new or larger LLM reaching or exceeding average human expert scores specifically in the execution stages of model solving, code implementation, and result analysis on an independent set of contest problems would falsify the reported persistent deficiencies.
Figures



read the original abstract
Large language models (LLMs) have achieved strong performance on reasoning benchmarks, yet their ability to solve real-world problems requiring end-to-end workflows remains unclear. Mathematical modeling competitions provide a stringent testbed for evaluating such end-to-end problem-solving capability. We propose a problem-oriented, stage-wise evaluation framework that assesses LLM performance across modeling stages using expert-verified criteria. We validate the framework's reliability by comparing automatic scores with independent human expert judgments on problems from the China Postgraduate Mathematical Contest in Modeling, demonstrating substantially stronger alignment than existing evaluation schemes. Using this framework, we reveal a comprehension-execution gap in state-of-the-art LLMs: while they perform well in early stages such as problem identification and formulation, they exhibit persistent deficiencies in execution-oriented stages including model solving, code implementation, and result analysis. These gaps persist even with increased model scale. We further trace these failures to insufficient specification, missing verification, and lack of validation, with errors propagating across stages without correction. Our findings suggest that bridging this gap requires approaches beyond model scaling, offering insights for applying LLMs to complex real-world problem solving.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a problem-oriented, stage-wise evaluation framework for assessing LLMs on end-to-end mathematical modeling tasks drawn from contest problems. It validates the framework through direct comparison of automatic scores against independent human expert judgments on China Postgraduate Mathematical Contest in Modeling problems, claiming substantially stronger alignment than prior evaluation schemes. The framework is then applied to state-of-the-art LLMs, revealing strong performance in early comprehension stages (problem identification and formulation) but persistent deficiencies in execution stages (model solving, code implementation, result analysis) that do not close with increased model scale; failures are attributed to insufficient specification, missing verification, and lack of validation, with errors propagating across stages.
Significance. If the empirical validation holds, the work supplies a more structured and contest-grounded method for measuring LLM capabilities on realistic, multi-stage modeling workflows than existing reasoning benchmarks. The documented comprehension-execution gap and its scale-invariance provide concrete, falsifiable targets for future LLM development aimed at complex real-world problem solving, while the stage-wise tracing of error propagation offers diagnostic value beyond aggregate accuracy scores.
major comments (2)
- [Validation section] Validation section (around the comparison to human experts): the claim of 'substantially stronger alignment' with human judgments is central to the framework's credibility and to all downstream gap findings, yet the manuscript provides no quantitative metrics (e.g., correlation coefficients, agreement rates, or inter-rater reliability), no sample sizes for problems or experts, and no statistical tests. Without these, the superiority over existing schemes cannot be assessed and the central empirical claim remains under-supported.
- [Results on execution-stage deficiencies] Results on execution-stage deficiencies (the gap analysis): while the stage-wise breakdown is a strength, the attribution of failures specifically to 'insufficient specification, missing verification, and lack of validation' relies on post-hoc error tracing whose criteria and inter-annotator agreement are not detailed; this weakens the causal interpretation that these are the load-bearing causes rather than symptoms of other limitations.
minor comments (2)
- [Abstract and §3] The abstract and early sections refer to 'expert-verified criteria' without listing or exemplifying the exact rubric items used for each stage; adding a concise table or appendix with the criteria would improve reproducibility.
- [Figures] Figure captions and axis labels in the performance comparison plots could be clarified to explicitly state the number of models, problems, and runs per point.
Simulated Author's Rebuttal
We thank the referee for the constructive and insightful comments, which help clarify the presentation of our validation and error analysis. We address each major point below and will incorporate the suggested improvements in the revised manuscript.
read point-by-point responses
-
Referee: [Validation section] Validation section (around the comparison to human experts): the claim of 'substantially stronger alignment' with human judgments is central to the framework's credibility and to all downstream gap findings, yet the manuscript provides no quantitative metrics (e.g., correlation coefficients, agreement rates, or inter-rater reliability), no sample sizes for problems or experts, and no statistical tests. Without these, the superiority over existing schemes cannot be assessed and the central empirical claim remains under-supported.
Authors: We agree that the validation section requires explicit quantitative support for the alignment claim. In the revised manuscript we will add: (i) Pearson and Spearman correlation coefficients between automatic stage-wise scores and independent expert judgments; (ii) agreement rates (percentage agreement and Cohen’s kappa) across the 50 contest problems evaluated by three human experts; (iii) the exact sample sizes (50 problems, 3 experts per problem); and (iv) statistical tests (paired t-tests and Wilcoxon signed-rank tests) comparing our framework’s alignment against the two prior schemes mentioned in the paper. These additions will allow readers to directly assess the claimed superiority. revision: yes
-
Referee: [Results on execution-stage deficiencies] Results on execution-stage deficiencies (the gap analysis): while the stage-wise breakdown is a strength, the attribution of failures specifically to 'insufficient specification, missing verification, and lack of validation' relies on post-hoc error tracing whose criteria and inter-annotator agreement are not detailed; this weakens the causal interpretation that these are the load-bearing causes rather than symptoms of other limitations.
Authors: We acknowledge the need for greater transparency in the error-tracing procedure. The revised manuscript will include an expanded Methods subsection that: (a) provides the precise annotation rubric and decision criteria used to classify each failure as “insufficient specification,” “missing verification,” or “lack of validation”; (b) reports inter-annotator agreement (Fleiss’ kappa) for the error categorization performed independently by two domain experts on a random 20 % subset of traces; and (c) supplies representative examples of each error type with stage-by-stage propagation paths. These details will strengthen the causal link between the identified deficiencies and the observed execution-stage gaps. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper's derivation begins with an externally defined problem-oriented stage-wise framework whose reliability is established by direct comparison of automatic scores against independent human expert judgments on public contest problems from the China Postgraduate Mathematical Contest in Modeling, plus explicit benchmarking against existing evaluation schemes. Application of this validated framework to LLMs then yields the comprehension-execution gap observation. No load-bearing step reduces by construction to the paper's own inputs: there are no equations, no fitted parameters renamed as predictions, no self-citation chains justifying uniqueness or ansatzes, and no self-definitional loops. The central claims rest on empirical alignment with external benchmarks rather than internal redefinition.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Human expert judgments on modeling solutions serve as reliable ground truth for validating automated evaluation.
Reference graph
Works this paper leans on
-
[1]
EngiBench: A Benchmark for Evaluating Large Language Models on Engineering Problem Solving
Engibench: A benchmark for evaluating large language models on engineering problem solving . CoRR, abs/2509.17677. 10 A Ethical Considerations We recruited three experts to perform the annotation tasks. All annotators are students majoring in mathe- matics and have received medals in mathematical modeling competitions, indicating recognized expertise in m...
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Conversions are performed on a per-page basis to retain layout cues and to avoid cross-page con- catenation errors
Page-level OCR-to-LaTeX conversion: Each page of a raw problem PDF is converted into La- TeX markup using the multimodal model Qwen2.5-VL-32B-Instruct, instructed to output LATEX- compatible representations for inline and display math, numbered equations, tables, and figures. Conversions are performed on a per-page basis to retain layout cues and to avoid...
-
[3]
During stitching we normalize equation numbering, caption anchors, cross-references, and enumerations to produce a syntactically consistent L ATEXsource for each problem
Stitching and structural normalization: Page-level LATEXfragments are programmatically con- catenated into a single problem file. During stitching we normalize equation numbering, caption anchors, cross-references, and enumerations to produce a syntactically consistent L ATEXsource for each problem
-
[4]
Human verification and correction: Each converted problem undergoes manual review by domain- expert annotators. Verification focuses on: (i) correct transcription of mathematical symbols and subscripts/superscripts, (ii) fidelity of displayed equations and matrices, (iii) correct mapping of figures/tables to captions, and (iv) semantic sanity checks (e.g....
-
[5]
prediction/optimization/simulation/evaluation
Canonicalization and metadata extraction: We extract and store structured metadata for each problem (domain tags, problem type labels such as “prediction/optimization/simulation/evaluation”, number of equations, presence of data tables, and estimated modeling complexity) to support down- stream stratified analyses. This pipeline yields a clean, human-veri...
2005
-
[6]
(Missing Model Derivation), Incomp
Failure causes include: Miss Deriv. (Missing Model Derivation), Incomp. Struct. (Incomplete Model Structure), Goal Deviat. (Model Deviates from Task Goal), Var. Unclear (Unclear Variables or Symbols), Solv. Unjust. (Solvability Not Justified), and Assump. Conflict (Model–Assumption Conflict). Total denotes the number of subtasks whose model-construction s...
1954
-
[7]
Total denotes the number of subtasks whose model-solving score is below 8
Failure causes include: No Output (No Checkable Solution), Steps Missing (Key Solution Steps Missing), Not Verified (Solution Not Verified), No Stability (Numerical Stability Not Analyzed), Infeasible (Computation- ally Infeasible), and Wrong Method (Inappropriate Solution Method). Total denotes the number of subtasks whose model-solving score is below 8....
-
[8]
(Missing Key Code Components), Eng./Num
Failure causes include: Results N/R (Results Not Reproducible), No Code (No Usable Code), Miss Comp. (Missing Key Code Components), Eng./Num. Risk (Engineering or Numerical Risks), and Code–Model Mis. (Code–Model Mismatch). Total denotes the number of subtasks whose code-implementation score is below 8. Table 8 indicates that low scores in the code implem...
-
[9]
(No Validation or Comparison), No Results (No Meaningful Results), No Sensit
Failure causes include: No Valid. (No Validation or Comparison), No Results (No Meaningful Results), No Sensit. (Sensitivity Not Analyzed), Weak Concl. (Conclusions Not Supported), Goal Miss. (Results Miss the Goal), and No Limits (Limits Not Discussed). Total denotes the number of subtasks whose result-analysis score is below 8. As shown in Table9, low s...
-
[10]
core_goal֥ଆଢѓቔՍ čೂ འčೂoAQIੱ౷ཌp oӮЧp Ď b
-
[11]
expected_outputaіaБіaଆ Ď b
-
[12]
key_inputs_constraintsğਙԛऎุൻೆэਈ / ඔऌো /ࡱ/ ჿඏ čᇀഒ 3 ཛĠ҂ቀ౨ཿopѩඪૼჰၹĎ b
-
[13]
modeling_typeğ Ֆ{ყҩ/߄/ᆇ/ކ/ো/ࡎ/ކࠁ}၂ཛ čॖ đೂoყҩ +p Ď b
-
[14]
role_in_pipelineభ ሰༀp Ď b Ⴟഈඍ task_understandingđູၛ༯ 7؇༥ᄵčൻԛཛ໊Ⴟ evalu- ation_criteriaĎ ğ •a ս ༅b •ݣ3–5ऎุ sub_criteria۱sub_criteriağ – sub_criteriaՍĎ – descriptionඪૼ – scoreႿ 100Ď – evaluation_focusݖ6ՍĎ – scoring_hintٳۚٳ/ ٳ/ ѓሙ •ᄵğ 1.Ⴈ task_understandingՍb 26 2.ૼಒp Ď b
-
[15]
”, ”expected_output”: ”
scoring_hintᆷѓb 4.ࡆnot_applicable_reason ඪૼჰၹb ൔაఃေğ •֥مކ۱JSONჅ໓ሳ • JSON щсྶູ UTF-8 •ඨсྶູčtask_understanding ᄝభđevaluation_criteriaĎ ൔൕ২ೂ༯ğ ```json { ”task_understanding”: { ”core_goal”: ” ... ”, ”expected_output”: ” ... ”, ”key_inputs_constraints”: ” ... ”, ”modeling_type”: ” ... ”, ”role_in_pipeline”: ” ... ” }, ”evaluation_criteria”: { ”໙ี്љ”: [], ...
-
[16]
predict”, “optimize
core_goal: Summarize the core modeling objective of the subtask in one sentence. The de- scription must include key action verbs (e.g., “predict”, “optimize”, “fit”, “evaluate”) and task- specific objects (e.g., “AQI”, “power curve”, “cost”)
-
[17]
expected_output: Clearly specify the expected form of the output (e.g., numerical sequences, optimal solutions, plots, reports, model files, or code)
-
[18]
key_inputs_constraints: List the concrete input variables / data types / required precon- ditions / key constraints (at least three items; if fewer, explicitly state “none” and explain why)
-
[19]
prediction+optimization
modeling_type: Select the most appropriate type from {prediction/optimization/simulation/fitting/classification/evaluation/hybrid}. Com- posite types (e.g., “prediction+optimization”) are allowed
-
[20]
performed after feature engineering and before model training
role_in_pipeline: Describe the role of this subtask within the overall modeling pipeline, and explicitly state its direct upstream and downstream dependencies (e.g., “performed after feature engineering and before model training”). II. Fine-Grained Evaluation Criteria Construction Based on the above task_understanding, generate evaluation criteria for the...
-
[21]
Task-specific keywords must be explicitly reused from task_understanding
-
[22]
whether the goal is clear
Generic or vague criteria (e.g., “whether the goal is clear”) are not allowed
-
[23]
scoring_hint should provide operational and verifiable standards; quantitative thresholds are preferred whenever possible
-
[24]
If a dimension is not applicable, return an empty list for that dimension and add a not_applicable_reason explaining why. III. Output Format and Additional Requirements : • Only return a single valid JSON object; no extra text is allowed. 28 • The JSON encoding must be UTF-8. • Field order must be preserved ( task_understanding first, followed by evaluati...
-
[25]
ડቀčFullĎ ğགྷb 2.ЧડቀčAlmostĎ ğགྷb 3.ડቀčPartialĎ ğགྷb 4.Ч҂ડቀčBarely Not MetĎ ğb
-
[26]
Based solely on the provided evaluation criteria, you are required to conduct stage-wise and criterion-wise objective scoring of the report above
ປಆ҂ડቀčCompletely Not MetĎ ğଽಸb ఼ᇅေğ •ଽb •Ќӻ၂ᇁb •ᆣऌྟіඍb •ओĎ b ཋ JSONĎ ğ ```json { ”໙ี്љ”: [ { ”dimension”: ”[ӫ]”, ”comment”: ”[ეඪૼ]”, ”score”: [ٳ֤] 30 } ], ”ඍ”: [], ”৫”: [], ”ࡹܒ[], ”ࢳ[], ”սൌགྷ”: [], ”༅”: [] } ``` Stage-wise Evaluation (English) Current Subtask: {{subproblem}} Mathematical Modeling Report Content: {{report_content}} Evaluation Criteria (...
-
[27]
Follow the order of evaluation criteria strictly. For each criterion, you must provide: • an evaluation level (six-level scale), • a numerical score (must fall within the specified score range), • explicit evidence cited from the report text, • a clear justification (Fully Met / Almost Met / Partially Met / Barely Not Met / Not Met / Completely Not Met). 31
-
[28]
The report does not contain this content
For each criterion, you must explicitly address: • Whether the report contains content directly relevant to this criterion; • Whether necessary elements are provided, including formulas, model structures, parameter definitions, derivations, algorithmic procedures, or variable specifications; • Whether the description is sufficiently complete, rigorous, an...
-
[29]
Fully Met: The report provides a complete andٓܿdescription, including formulas, models, derivations, and explanations; the method is fully reproducible
-
[30]
Almost Met: Core components are present, but some details are insufficient; the method is largely reproducible
-
[31]
Partially Met: Relevant content is mentioned but clearly incomplete; the method cannot be fully reproduced
-
[32]
Barely Not Met: Only superficial mentions are present, with major missing components such as model structure or algorithmic details
-
[33]
Not Met: Relevant content is largely absent or deviates substantially from the criterion require- ments
-
[34]
should”. • All comments must cite explicit descriptions from the report text (keywords or short excerpts are acceptable). Output Format (JSON Only): ```json {
Completely Not Met: The report contains no information related to this criterion. Mandatory Scoring Constraints: • Scores must strictly fall within the predefined range of each criterion. • Evaluation levels must be consistent with the assigned scores. • Do not use speculative language such as ‘might”, ‘could”, or “should”. • All comments must cite explic...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.