Recognition: 2 theorem links
· Lean TheoremForgetting to Witness: Efficient Federated Unlearning and Its Visible Evaluation
Pith reviewed 2026-05-10 20:22 UTC · model grok-4.3
The pith
A federated unlearning pipeline removes specific data influence using knowledge distillation without storing history and evaluates forgetting via GAN-generated samples.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
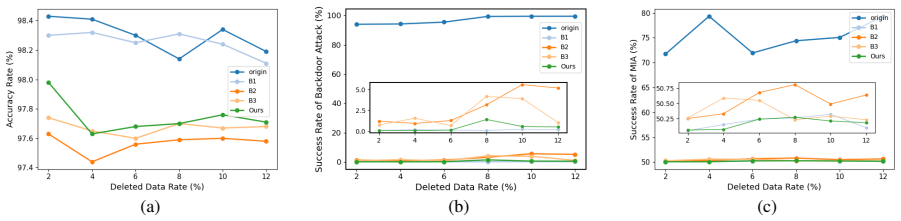
The authors propose the first complete federated unlearning pipeline consisting of an unlearning approach that leverages a knowledge distillation model together with optimization mechanisms to achieve efficient forgetting and maintained accuracy without historical data storage, plus the Skyeye framework that integrates the unlearned model as classifier into a GAN; the classifier and discriminator then guide the generator to produce samples whose relevance to the deleted data measures the model's forgetting capacity.
What carries the argument
The Skyeye GAN setup, where the federated unlearning model serves as classifier to steer sample generation and the relevance of those samples to deleted data quantifies forgetting.
If this is right
- Federated models can delete specific client data effects efficiently while preserving overall performance.
- Forgetting can be checked visually by inspecting whether GAN outputs resemble the removed data.
- No historical data storage is required, lowering memory overhead in repeated unlearning rounds.
- The pipeline supports privacy compliance in distributed learning without retraining from scratch.
Where Pith is reading between the lines
- The approach could extend to non-federated settings where data deletion requests must be honored quickly.
- Visual sample inspection might reveal patterns in what the model still 'remembers' that numerical metrics miss.
- If Skyeye works reliably, regulators could require similar visible audits for unlearning claims.
Load-bearing premise
The Skyeye GAN visualization where the unlearned model acts as classifier accurately and without bias reflects the model's true forgetting capacity for the deleted data.
What would settle it
Run Skyeye on a model known to still classify deleted data correctly; if the generated samples show low relevance to that data, the evaluation framework fails to detect retained information.
Figures







read the original abstract
With the increasing importance of data privacy and security, federated unlearning has emerged as a novel research field dedicated to ensuring that federated learning models no longer retain or leak relevant information once specific data has been deleted. In this paper, to the best of our knowledge, we propose the first complete pipeline for federated unlearning, which includes a federated unlearning approach and an evaluation framework. Our proposed federated unlearning approach ensures high efficiency and model accuracy without the need to store historical data.It effectively leverages the knowledge distillation model alongside various optimization mechanisms. Moreover, we propose a framework named Skyeye to visualize the forgetting capacity of federated unlearning models. It utilizes the federated unlearning model as the classifier integrated into a Generative Adversarial Network (GAN). Afterward, both the classifier and discriminator guide the generator in generating samples. Throughout this process, the generator learns from the classifier's knowledge. The generator then visualizes this knowledge through sample generation. Finally, the model's forgetting capability is evaluated based on the relevance between the deleted data and the generated samples. Comprehensive experiments are conducted to illustrate the effectiveness of the proposed federated unlearning approach and the corresponding evaluation framework.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes the first complete pipeline for federated unlearning. It consists of an efficient unlearning method that leverages knowledge distillation together with optimization mechanisms to remove the influence of deleted data from federated models without storing historical data, and the Skyeye evaluation framework. In Skyeye the unlearned model is inserted as the classifier inside a GAN; both the classifier and the discriminator then guide the generator to produce samples, after which forgetting is quantified by a relevance metric between the generated samples and the deleted data. Comprehensive experiments are claimed to demonstrate the effectiveness of both components.
Significance. If the central claims are substantiated, the work would be significant for supplying both a storage-free federated unlearning procedure and a visible, GAN-driven evaluation method that directly visualizes residual knowledge. The emphasis on efficiency and the absence of historical-data requirements addresses practical constraints in privacy-sensitive federated deployments. The Skyeye framework, if shown to be reliable, could become a useful diagnostic tool for the broader unlearning literature.
major comments (2)
- [Skyeye evaluation framework] Skyeye evaluation framework (abstract and §4): the assertion that relevance between GAN-generated samples and deleted data quantifies forgetting capacity lacks supporting derivation or ablation. It is not shown that the metric is monotonic with residual membership information, nor that the joint classifier-discriminator guidance avoids introducing new correlations or GAN artifacts (mode collapse, soft-label boundary effects) that could produce high relevance even after complete scrubbing. This is load-bearing for the headline claim of a 'visible evaluation' framework.
- [Federated unlearning approach] Federated unlearning approach (abstract and §3): the claims of 'high efficiency and model accuracy' without historical data rest on descriptive assertions rather than explicit complexity bounds, convergence rates, or communication-round analysis. If the method is parameter-free or reduces to a known baseline under certain conditions, this must be stated; otherwise the efficiency advantage over prior federated unlearning techniques cannot be assessed.
minor comments (2)
- [Abstract] Abstract: the phrase 'various optimization mechanisms' is too vague; name the specific mechanisms and their integration with knowledge distillation.
- [Abstract] Abstract: the relevance metric used to compare generated samples with deleted data is never defined (e.g., cosine similarity on features, classification accuracy, or another quantity).
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We address each major comment point by point below and will revise the paper to incorporate the requested analysis and clarifications.
read point-by-point responses
-
Referee: [Skyeye evaluation framework] Skyeye evaluation framework (abstract and §4): the assertion that relevance between GAN-generated samples and deleted data quantifies forgetting capacity lacks supporting derivation or ablation. It is not shown that the metric is monotonic with residual membership information, nor that the joint classifier-discriminator guidance avoids introducing new correlations or GAN artifacts (mode collapse, soft-label boundary effects) that could produce high relevance even after complete scrubbing. This is load-bearing for the headline claim of a 'visible evaluation' framework.
Authors: We agree that the current presentation of the Skyeye framework would be strengthened by an explicit derivation of the relevance metric and targeted ablations. In the revised manuscript we will add a subsection deriving the metric from the perspective of membership inference (showing that expected relevance decreases as the classifier's posterior on deleted classes approaches the unlearned distribution). We will also include new ablation tables that vary unlearning intensity and report the resulting relevance scores, together with controls that isolate GAN artifacts (e.g., mode-collapse diagnostics via intra-class diversity and comparisons against a vanilla GAN baseline). These additions will directly address monotonicity and artifact concerns. revision: yes
-
Referee: [Federated unlearning approach] Federated unlearning approach (abstract and §3): the claims of 'high efficiency and model accuracy' without historical data rest on descriptive assertions rather than explicit complexity bounds, convergence rates, or communication-round analysis. If the method is parameter-free or reduces to a known baseline under certain conditions, this must be stated; otherwise the efficiency advantage over prior federated unlearning techniques cannot be assessed.
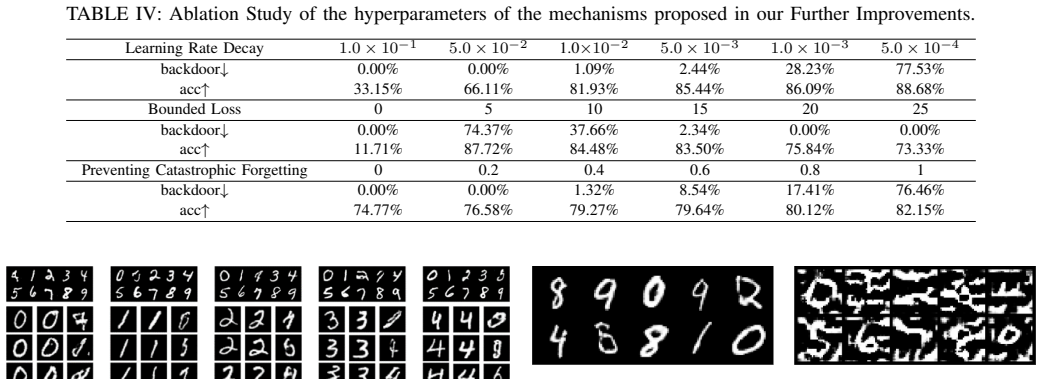
Authors: We accept that the efficiency claims require formal analysis. The revised version will contain a dedicated complexity subsection in §3 that states the per-round communication cost, the overall time complexity (O(T · (C + D)) where T is communication rounds, C is client computation, and D is distillation overhead), and a convergence-rate sketch under standard smoothness assumptions on the distillation loss. We will also clarify that the method is not parameter-free and does not collapse to any cited baseline; the specific combination of knowledge-distillation loss with the proposed optimization mechanisms is what enables storage-free unlearning while preserving accuracy. revision: yes
Circularity Check
No circularity: proposed pipeline and Skyeye metric are definitional contributions, not self-referential derivations
full rationale
The paper advances a federated unlearning method via knowledge distillation plus optimizations (no historical data storage) and introduces Skyeye as an evaluation framework that inserts the unlearned model as a GAN classifier to generate samples whose relevance to deleted data quantifies forgetting. These are methodological proposals and a new visualization metric; the abstract and claims contain no equations, fitted parameters renamed as predictions, self-citations that bear the central load, or uniqueness theorems. The relevance-based forgetting score is defined by the framework itself rather than derived from prior results that reduce to the same inputs. The 'first complete pipeline' assertion is a novelty claim, not a tautological reduction. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We propose an efficient federated unlearning approach that ensures both model accuracy and robustness, without the need for additional historical data storage. By utilizing a knowledge distillation model, minimizing adjustments to internal attention maps...
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Skyeye framework... integrates the unlearned model into a GAN... evaluates... based on the relevance between the deleted data and the generated samples.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Federated Learning: Strategies for Improving Communication Efficiency
J. Kone ˇcn`y, H. B. McMahan, F. X. Yu, P. Richt ´arik, A. T. Suresh, and D. Bacon, “Federated learning: Strategies for improving communication efficiency,”arXiv preprint arXiv:1610.05492, 2016
work page internal anchor Pith review arXiv 2016
-
[2]
Communication-efficient learning of deep networks from decentralized data,
B. McMahan, E. Moore, D. Ramage, S. Hampson, and B. A. y Arcas, “Communication-efficient learning of deep networks from decentralized data,” inArtificial intelligence and statistics, pp. 1273–1282, PMLR, 2017
2017
-
[3]
General data protection regulation (gdpr),
G. D. P. Regulation, “General data protection regulation (gdpr),”Intersoft Consulting, Accessed in October, vol. 24, no. 1, 2018
2018
-
[4]
The california consumer privacy act: Towards a european- style privacy regime in the united states,
S. L. Pardau, “The california consumer privacy act: Towards a european- style privacy regime in the united states,”J. Tech. L. & Pol’y, vol. 23, p. 68, 2018
2018
-
[5]
Comprehensive privacy analysis of deep learning,
M. Nasr, R. Shokri, and A. Houmansadr, “Comprehensive privacy analysis of deep learning,” inProceedings of the 2019 IEEE Symposium on Security and Privacy (SP), pp. 1–15, 2018
2019
-
[6]
Analyzing user-level privacy attack against federated learning,
M. Song, Z. Wang, Z. Zhang, Y . Song, Q. Wang, J. Ren, and H. Qi, “Analyzing user-level privacy attack against federated learning,”IEEE Journal on Selected Areas in Communications, vol. 38, no. 10, pp. 2430– 2444, 2020
2020
-
[7]
A. Salem, Y . Zhang, M. Humbert, P. Berrang, M. Fritz, and M. Backes, “Ml-leaks: Model and data independent membership inference at- tacks and defenses on machine learning models,”arXiv preprint arXiv:1806.01246, 2018
work page Pith review arXiv 2018
-
[8]
How to backdoor federated learning,
E. Bagdasaryan, A. Veit, Y . Hua, D. Estrin, and V . Shmatikov, “How to backdoor federated learning,” inInternational conference on artificial intelligence and statistics, pp. 2938–2948, PMLR, 2020
2020
-
[9]
Fedrecovery: Differentially private machine unlearning for federated learning frame- works,
L. Zhang, T. Zhu, H. Zhang, P. Xiong, and W. Zhou, “Fedrecovery: Differentially private machine unlearning for federated learning frame- works,”IEEE Transactions on Information Forensics and Security, 2023
2023
-
[10]
Machine unlearning,
L. Bourtoule, V . Chandrasekaran, C. A. Choquette-Choo, H. Jia, A. Travers, B. Zhang, D. Lie, and N. Papernot, “Machine unlearning,” in2021 IEEE Symposium on Security and Privacy (SP), pp. 141–159, IEEE, 2021
2021
-
[11]
Federaser: Enabling efficient client-level data removal from federated learning models,
G. Liu, X. Ma, Y . Yang, C. Wang, and J. Liu, “Federaser: Enabling efficient client-level data removal from federated learning models,” in 2021 IEEE/ACM 29th International Symposium on Quality of Service (IWQOS), pp. 1–10, IEEE, 2021
2021
-
[12]
Approximate data deletion from machine learning models,
Z. Izzo, M. A. Smart, K. Chaudhuri, and J. Zou, “Approximate data deletion from machine learning models,” inInternational Conference on Artificial Intelligence and Statistics, pp. 2008–2016, PMLR, 2021
2008
-
[13]
Descent-to-delete: Gradient-based methods for machine unlearning,
S. Neel, A. Roth, and S. Sharifi-Malvajerdi, “Descent-to-delete: Gradient-based methods for machine unlearning,” inAlgorithmic Learn- ing Theory, pp. 931–962, PMLR, 2021
2021
-
[14]
Deltagrad: Rapid retraining of machine learning models,
Y . Wu, E. Dobriban, and S. Davidson, “Deltagrad: Rapid retraining of machine learning models,” inInternational Conference on Machine Learning, pp. 10355–10366, PMLR, 2020
2020
-
[15]
Making ai forget you: Data deletion in machine learning,
A. Ginart, M. Guan, G. Valiant, and J. Y . Zou, “Making ai forget you: Data deletion in machine learning,”Advances in neural information processing systems, vol. 32, 2019
2019
-
[16]
arXiv preprint arXiv:1911.03030 (2019)
C. Guo, T. Goldstein, A. Hannun, and L. Van Der Maaten, “Cer- tified data removal from machine learning models,”arXiv preprint arXiv:1911.03030, 2019
-
[17]
Remember what you want to forget: Algorithms for machine unlearning,
A. Sekhari, J. Acharya, G. Kamath, and A. T. Suresh, “Remember what you want to forget: Algorithms for machine unlearning,”Advances in Neural Information Processing Systems, vol. 34, pp. 18075–18086, 2021
2021
-
[18]
Machine unlearning via algorithmic stability,
E. Ullah, T. Mai, A. Rao, R. A. Rossi, and R. Arora, “Machine unlearning via algorithmic stability,” inConference on Learning Theory, pp. 4126–4142, PMLR, 2021
2021
-
[20]
Adaptive machine unlearning,
V . Gupta, C. Jung, S. Neel, A. Roth, S. Sharifi-Malvajerdi, and C. Waites, “Adaptive machine unlearning,”Advances in Neural Information Pro- cessing Systems, vol. 34, pp. 16319–16330, 2021
2021
-
[21]
On the necessity of auditable algorithmic definitions for machine unlearning,
A. Thudi, H. Jia, I. Shumailov, and N. Papernot, “On the necessity of auditable algorithmic definitions for machine unlearning,” in31st USENIX Security Symposium (USENIX Security 22), pp. 4007–4022, 2022
2022
-
[22]
Manipulating sgd with data ordering attacks,
I. Shumailov, Z. Shumaylov, D. Kazhdan, Y . Zhao, N. Papernot, M. A. Erdogdu, and R. J. Anderson, “Manipulating sgd with data ordering attacks,”Advances in Neural Information Processing Systems, vol. 34, pp. 18021–18032, 2021
2021
-
[23]
Verifi: Towards verifiable federated unlearning,
X. Gao, X. Ma, J. Wang, Y . Sun, B. Li, S. Ji, P. Cheng, and J. Chen, “Verifi: Towards verifiable federated unlearning,”IEEE Transactions on Dependable and Secure Computing, 2024
2024
-
[24]
Athena: Probabilistic verification of machine unlearning,
D. M. Sommer, L. Song, S. Wagh, and P. Mittal, “Athena: Probabilistic verification of machine unlearning,”Proceedings on Privacy Enhancing Technologies, 2022
2022
-
[25]
Verifying in the dark: Verifiable machine unlearning by using invisible backdoor triggers,
Y . Guo, Y . Zhao, S. Hou, C. Wang, and X. Jia, “Verifying in the dark: Verifiable machine unlearning by using invisible backdoor triggers,” IEEE Transactions on Information Forensics and Security, 2023
2023
-
[26]
Generative adversarial nets,
I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y . Bengio, “Generative adversarial nets,” Advances in neural information processing systems, vol. 27, 2014
2014
-
[27]
Gradient obfus- cation gives a false sense of security in federated learning,
K. Yue, R. Jin, C.-W. Wong, D. Baron, and H. Dai, “Gradient obfus- cation gives a false sense of security in federated learning,” in32nd USENIX Security Symposium (USENIX Security 23), pp. 6381–6398, 2023
2023
-
[28]
Deep models under the gan: information leakage from collaborative deep learning,
B. Hitaj, G. Ateniese, and F. Perez-Cruz, “Deep models under the gan: information leakage from collaborative deep learning,” inProceedings of the 2017 ACM SIGSAC conference on computer and communications security, pp. 603–618, 2017
2017
-
[29]
Machine unlearning for random forests,
J. Brophy and D. Lowd, “Machine unlearning for random forests,” in International Conference on Machine Learning, pp. 1092–1104, PMLR, 2021
2021
-
[30]
Asynchronous federated unlearning,
N. Su and B. Li, “Asynchronous federated unlearning,” inIEEE INFO- COM 2023-IEEE Conference on Computer Communications, pp. 1–10, IEEE, 2023
2023
-
[31]
Towards making systems forget with machine unlearning,
Y . Cao and J. Yang, “Towards making systems forget with machine unlearning,” in2015 IEEE symposium on security and privacy, pp. 463– 480, IEEE, 2015
2015
-
[32]
The right to be forgotten in federated learning: An efficient realization with rapid retraining,
Y . Liu, L. Xu, X. Yuan, C. Wang, and B. Li, “The right to be forgotten in federated learning: An efficient realization with rapid retraining,” in IEEE INFOCOM 2022-IEEE Conference on Computer Communications, pp. 1749–1758, IEEE, 2022
2022
-
[33]
Machine unlearning: Linear filtration for logit-based classifiers,
T. Baumhauer, P. Sch ¨ottle, and M. Zeppelzauer, “Machine unlearning: Linear filtration for logit-based classifiers,”Machine Learning, vol. 111, no. 9, pp. 3203–3226, 2022
2022
-
[34]
Forget unlearning: Towards true data- deletion in machine learning,
R. Chourasia and N. Shah, “Forget unlearning: Towards true data- deletion in machine learning,” inInternational Conference on Machine Learning, pp. 6028–6073, PMLR, 2023
2023
-
[35]
arXiv preprint arXiv:2404.03180 (2024)
H. Wang, X. Zhu, C. Chen, and P. Esteves-Ver ´ıssimo, “Gold- fish: An efficient federated unlearning framework,”arXiv preprint arXiv:2404.03180, 2024
-
[36]
Gan-dp: Generative adversarial net driven differentially privacy-preserving big data publishing,
Y . Qu, S. Yu, J. Zhang, H. T. T. Binh, L. Gao, and W. Zhou, “Gan-dp: Generative adversarial net driven differentially privacy-preserving big data publishing,” inICC 2019-2019 IEEE International Conference on Communications (ICC), pp. 1–6, IEEE, 2019
2019
-
[37]
Conditional Generative Adversarial Nets
M. Mirza and S. Osindero, “Conditional generative adversarial nets,” arXiv preprint arXiv:1411.1784, 2014
work page internal anchor Pith review arXiv 2014
-
[38]
Beyond inferring class representatives: User-level privacy leakage from federated learning,
Z. Wang, M. Song, Z. Zhang, Y . Song, Q. Wang, and H. Qi, “Beyond inferring class representatives: User-level privacy leakage from federated learning,” inIEEE INFOCOM 2019-IEEE conference on computer communications, pp. 2512–2520, IEEE, 2019
2019
-
[39]
Poisoning attack in federated learning using generative adversarial nets,
J. Zhang, J. Chen, D. Wu, B. Chen, and S. Yu, “Poisoning attack in federated learning using generative adversarial nets,” in2019 18th IEEE international conference on trust, security and privacy in computing and communications/13th IEEE international conference on big data science and engineering (TrustCom/BigDataSE), pp. 374–380, IEEE, 2019
2019
-
[40]
Privacy preserving machine learning with ho- momorphic encryption and federated learning,
H. Fang and Q. Qian, “Privacy preserving machine learning with ho- momorphic encryption and federated learning,”Future Internet, vol. 13, no. 4, p. 94, 2021
2021
-
[41]
When machine unlearning jeopardizes privacy,
M. Chen, Z. Zhang, T. Wang, M. Backes, M. Humbert, and Y . Zhang, “When machine unlearning jeopardizes privacy,” inProceedings of the 2021 ACM SIGSAC conference on computer and communications security, pp. 896–911, 2021
2021
-
[42]
Can bad teaching induce forgetting? unlearning in deep networks using an incompetent teacher,
V . S. Chundawat, A. K. Tarun, M. Mandal, and M. Kankanhalli, “Can bad teaching induce forgetting? unlearning in deep networks using an incompetent teacher,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 37, pp. 7210–7217, 2023
2023
-
[43]
Redeem myself: Purifying backdoors in deep learning models using self attention distillation,
X. Gong, Y . Chen, W. Yang, Q. Wang, Y . Gu, H. Huang, and C. Shen, “Redeem myself: Purifying backdoors in deep learning models using self attention distillation,” in2023 IEEE Symposium on Security and Privacy (SP), pp. 755–772, IEEE, 2023
2023
-
[44]
Machine unlearning: Solutions and challenges,
J. Xu, Z. Wu, C. Wang, and X. Jia, “Machine unlearning: Solutions and challenges,”IEEE Transactions on Emerging Topics in Computational Intelligence, 2024
2024
-
[45]
arXiv preprint arXiv:2201.09441 (2022)
C. Wu, S. Zhu, and P. Mitra, “Federated unlearning with knowledge distillation,”arXiv preprint arXiv:2201.09441, 2022
-
[46]
Gradient-based learning applied to document recognition,
Y . LeCun, L. Bottou, Y . Bengio, and P. Haffner, “Gradient-based learning applied to document recognition,”Proceedings of the IEEE, vol. 86, no. 11, pp. 2278–2324, 1998
1998
-
[47]
Parameterisation of a stochastic model for human face identification,
F. S. Samaria and A. C. Harter, “Parameterisation of a stochastic model for human face identification,” inProceedings of 1994 IEEE workshop on applications of computer vision, pp. 138–142, IEEE, 1994
1994
-
[48]
Learning multiple layers of features from tiny images,
A. Krizhevsky, G. Hinton,et al., “Learning multiple layers of features from tiny images,” 2009
2009
-
[49]
Deep residual learning for image recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” inProceedings of the IEEE conference on computer vision and pattern recognition, pp. 770–778, 2016
2016
-
[50]
Machine unlearning via rep- resentation forgetting with parameter self-sharing,
W. Wang, C. Zhang, Z. Tian, and S. Yu, “Machine unlearning via rep- resentation forgetting with parameter self-sharing,”IEEE Transactions on Information Forensics and Security, 2023
2023
-
[51]
Y . Li, X. Lyu, N. Koren, L. Lyu, B. Li, and X. Ma, “Neural attention distillation: Erasing backdoor triggers from deep neural networks,”arXiv preprint arXiv:2101.05930, 2021
-
[52]
Eternal sunshine of the spotless net: Selective forgetting in deep networks,
A. Golatkar, A. Achille, and S. Soatto, “Eternal sunshine of the spotless net: Selective forgetting in deep networks,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 9304–9312, 2020
2020
-
[53]
J. Chen and D. Yang, “Unlearn what you want to forget: Efficient unlearning for llms,”arXiv preprint arXiv:2310.20150, 2023
-
[54]
Towards unbounded machine unlearning,
M. Kurmanji, P. Triantafillou, J. Hayes, and E. Triantafillou, “Towards unbounded machine unlearning,”Advances in neural information pro- cessing systems, vol. 36, 2024
2024
-
[55]
Model sparsification can simplify machine unlearning,
J. Jia, J. Liu, P. Ram, Y . Yao, G. Liu, Y . Liu, P. Sharma, and S. Liu, “Model sparsification can simplify machine unlearning,”arXiv preprint arXiv:2304.04934, vol. 1, no. 2, p. 3, 2023
-
[56]
Machine unlearning of pre-trained large language models,
J. Yao, E. Chien, M. Du, X. Niu, T. Wang, Z. Cheng, and X. Yue, “Machine unlearning of pre-trained large language models,”arXiv preprint arXiv:2402.15159, 2024
-
[57]
Machine learning: Trends, perspec- tives, and prospects,
M. I. Jordan and T. M. Mitchell, “Machine learning: Trends, perspec- tives, and prospects,”Science, vol. 349, no. 6245, pp. 255–260, 2015. APPENDIX A PRELIMINARIES A.1 Machine Learning Machine learning algorithms developed allow computers to learn and improve automatically based on data. This process typically involves statistical analysis of large datase...
2015
-
[58]
Generator
The core idea of GANs is to simultaneously train two models: a Generator and a Discriminator, which compete against each other during the training process to improve the quality of the generated data. Generator. The goal of the Generator is to create realistic data samples that cannot be distinguished by the Discriminator. It receives a random noise vecto...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.