Recognition: no theorem link
The Blind Spot of Adaptation: Quantifying and Mitigating Forgetting in Fine-tuned Driving Models
Pith reviewed 2026-05-10 19:59 UTC · model grok-4.3
The pith
Adapting vision-language models to driving via prompt-space routing prevents catastrophic forgetting of general knowledge.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The Drive Expert Adapter shifts adaptation from the weight space to the prompt space by dynamically routing inference through different knowledge experts selected according to scene-specific cues. This enables stronger results on driving tasks without corrupting the model's foundational parameters, thereby reducing catastrophic forgetting and retaining the generalization that VLMs bring to long-tail scenarios.
What carries the argument
The Drive Expert Adapter (DEA), a framework that performs adaptation by routing inference through prompt-based knowledge experts conditioned on scene cues rather than by modifying model weights.
If this is right
- Standard fine-tuning methods produce measurable erosion of general VLM capabilities on driving tasks.
- The 180K-scene dataset establishes the first quantitative benchmark for forgetting in autonomous driving VLMs.
- DEA delivers state-of-the-art driving performance while keeping pre-trained generalization intact.
- Preserving foundational knowledge allows VLMs to handle long-tail driving situations more reliably than weight-altered models.
Where Pith is reading between the lines
- The prompt-routing idea could transfer to other domains where VLMs must specialize without losing broad capabilities, such as medical or robotic applications.
- Automatic methods for discovering or composing the knowledge experts might reduce the need for manual scene cue design.
- Combining DEA with replay-based or regularization techniques could produce even stronger retention of general knowledge.
Load-bearing premise
That routing inference through prompt-space knowledge experts based on scene-specific cues can improve driving performance without degrading the model's original parameters or generalization.
What would settle it
A direct comparison showing that DEA-adapted models score lower than the untouched base VLM on standard general-purpose vision-language benchmarks unrelated to driving would falsify the claim of preserved knowledge.
Figures




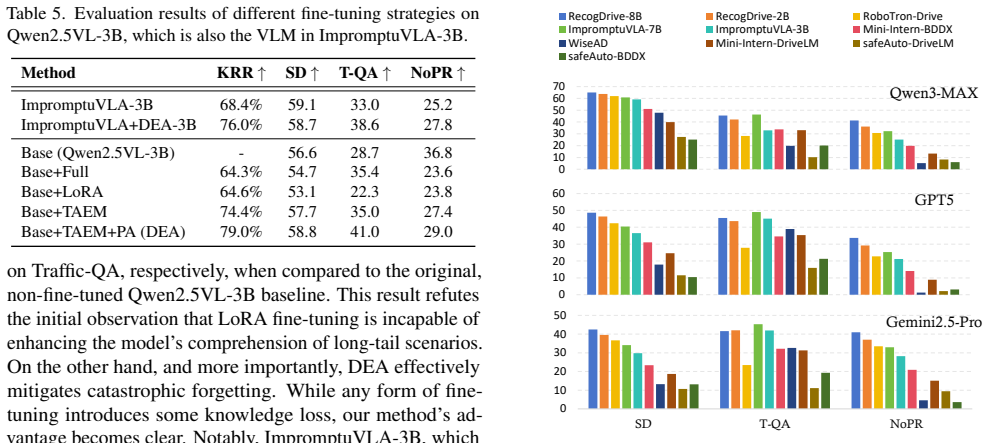

read the original abstract
The integration of Vision-Language Models (VLMs) into autonomous driving promises to solve long-tail scenarios, but this paradigm faces the critical and unaddressed challenge of catastrophic forgetting. The very fine-tuning process used to adapt these models to driving-specific data simultaneously erodes their invaluable pre-trained world knowledge, creating a self-defeating paradox that undermines the core reason for their use. This paper provides the first systematic investigation into this phenomenon. We introduce a new large-scale dataset of 180K scenes, which enables the first-ever benchmark specifically designed to quantify catastrophic forgetting in autonomous driving. Our analysis reveals that existing methods suffer from significant knowledge degradation. To address this, we propose the Drive Expert Adapter (DEA), a novel framework that circumvents this trade-off by shifting adaptation from the weight space to the prompt space. DEA dynamically routes inference through different knowledge experts based on scene-specific cues, enhancing driving-task performance without corrupting the model's foundational parameters. Extensive experiments demonstrate that our approach not only achieves state-of-the-art results on driving tasks but also effectively mitigates catastrophic forgetting, preserving the essential generalization capabilities that make VLMs a transformative force for autonomous systems. Data and model are released at FidelityDrivingBench.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that fine-tuning Vision-Language Models (VLMs) for autonomous driving causes catastrophic forgetting of pre-trained knowledge, creating a paradox that undermines their utility. It introduces a new 180K-scene dataset (FidelityDrivingBench) as the first benchmark to quantify this forgetting in driving contexts. To address it, the authors propose the Drive Expert Adapter (DEA), which performs adaptation exclusively in prompt space by dynamically routing inference to scene-specific knowledge experts. The central claim is that DEA achieves state-of-the-art results on driving tasks while mitigating forgetting and preserving generalization, with data and models released publicly.
Significance. If the empirical claims hold with rigorous validation, this work would be significant for VLM adaptation in safety-critical domains. The dedicated forgetting benchmark fills a gap in the literature, and shifting adaptation to prompt space offers a principled way to avoid weight-space degradation. The public release of the dataset and models is a clear strength that supports reproducibility and follow-on research in computer vision and robotics.
major comments (1)
- Abstract: the claim that the approach 'achieves state-of-the-art results on driving tasks but also effectively mitigates catastrophic forgetting' supplies no quantitative numbers, error bars, baseline comparisons, or measurement details for forgetting; central claims cannot be evaluated from the available text and this is load-bearing for the empirical contribution.
minor comments (2)
- The manuscript would benefit from an explicit definition or equation for the forgetting metric used in the benchmark (e.g., performance drop on a held-out pre-training task) in the methods section.
- Figure and table captions should include more detail on what is being compared (e.g., specific driving metrics and forgetting scores) to improve readability.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback and for highlighting the need for greater transparency in the abstract. We address the major comment point-by-point below and have revised the manuscript to strengthen the presentation of our empirical claims.
read point-by-point responses
-
Referee: Abstract: the claim that the approach 'achieves state-of-the-art results on driving tasks but also effectively mitigates catastrophic forgetting' supplies no quantitative numbers, error bars, baseline comparisons, or measurement details for forgetting; central claims cannot be evaluated from the available text and this is load-bearing for the empirical contribution.
Authors: We agree that the abstract, in its current form, does not supply the quantitative details necessary for readers to evaluate the central claims at a glance. Although the full manuscript contains extensive results—including specific performance metrics on driving tasks, baseline comparisons, error bars, and the precise protocol for measuring forgetting via the FidelityDrivingBench dataset—the abstract should summarize these findings more explicitly. In the revised version we will update the abstract to include key quantitative results (e.g., task-performance gains and forgetting-reduction metrics relative to fine-tuning baselines), while continuing to direct readers to the experimental sections for full details, error bars, and measurement methodology. This change directly addresses the load-bearing nature of the empirical contribution. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper is an empirical study that introduces a new 180K-scene benchmark dataset to quantify forgetting and proposes the Drive Expert Adapter (DEA) framework, which performs adaptation exclusively via prompt-space routing to knowledge experts based on scene cues. No equations, derivations, fitted parameters presented as predictions, or self-referential definitions appear in the described approach or abstract. Central claims of SOTA driving performance with preserved generalization rest on experimental results rather than reducing to inputs by construction. This matches the reader's assessment and qualifies as score 0 with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Flamingo: a visual language model for few-shot learning.Advances in neural information processing systems, 35:23716–23736,
Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katherine Millican, Malcolm Reynolds, et al. Flamingo: a visual language model for few-shot learning.Advances in neural information processing systems, 35:23716–23736,
-
[2]
Covla: Comprehensive vision-language-action dataset for au- tonomous driving
Hidehisa Arai, Keita Miwa, Kento Sasaki, Kohei Watan- abe, Yu Yamaguchi, Shunsuke Aoki, and Issei Yamamoto. Covla: Comprehensive vision-language-action dataset for au- tonomous driving. In2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), pages 1933–1943. IEEE, 2025. 3
1933
-
[3]
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and Jingren Zhou. Qwen-vl: A versatile vision-language model for understand- ing, localization, text reading, and beyond.arXiv preprint arXiv:2308.12966, 2023. 2, 4
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
Meteor: An automatic metric for mt evaluation with improved correlation with hu- man judgments
Satanjeev Banerjee and Alon Lavie. Meteor: An automatic metric for mt evaluation with improved correlation with hu- man judgments. InProceedings of the acl workshop on intrin- sic and extrinsic evaluation measures for machine translation and/or summarization, pages 65–72, 2005. 5
2005
-
[5]
Lang, Sourabh V ora, Venice Erin Liong, Qiang Xu, Anush Krishnan, Yu Pan, Gi- ancarlo Baldan, and Oscar Beijbom
Holger Caesar, Varun Bankiti, Alex H. Lang, Sourabh V ora, Venice Erin Liong, Qiang Xu, Anush Krishnan, Yu Pan, Gi- ancarlo Baldan, and Oscar Beijbom. nuscenes: A multimodal dataset for autonomous driving, 2020. 3
2020
-
[6]
Continual llava: Continual instruction tuning in large vision-language models
Meng Cao, Yuyang Liu, Yingfei Liu, Tiancai Wang, Jiahua Dong, Henghui Ding, Xiangyu Zhang, Ian Reid, and Xiaodan Liang. Continual llava: Continual instruction tuning in large vision-language models.arXiv preprint arXiv:2411.02564,
-
[7]
Maplm: A real-world large-scale vision- language benchmark for map and traffic scene understanding
Xu Cao, Tong Zhou, Yunsheng Ma, Wenqian Ye, Can Cui, Kun Tang, Zhipeng Cao, Kaizhao Liang, Ziran Wang, James M Rehg, et al. Maplm: A real-world large-scale vision- language benchmark for map and traffic scene understanding. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 21819–21830, 2024. 3
2024
-
[8]
Automated evaluation of large vision-language models on self-driving corner cases
Kai Chen, Yanze Li, Wenhua Zhang, Yanxin Liu, Pengxi- ang Li, Ruiyuan Gao, Lanqing Hong, Meng Tian, Xinhai Zhao, Zhenguo Li, et al. Automated evaluation of large vision-language models on self-driving corner cases. In2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), pages 7817–7826. IEEE, 2025. 3
2025
-
[9]
End-to-end autonomous driving: Challenges and frontiers, 2024
Li Chen, Penghao Wu, Kashyap Chitta, Bernhard Jaeger, Andreas Geiger, and Hongyang Li. End-to-end autonomous driving: Challenges and frontiers, 2024. 1
2024
-
[10]
Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks
Zhe Chen, Jiannan Wu, Wenhai Wang, Weijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qinglong Zhang, Xizhou Zhu, Lewei Lu, et al. Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks. InProceed- ings of the IEEE/CVF conference on computer vision and pattern recognition, pages 24185–24198, 2024. 1
2024
-
[11]
Impromptu vla: Open weights and open data for driving vision-language-action models, 2025
Haohan Chi, Huan ang Gao, Ziming Liu, Jianing Liu, Chenyu Liu, Jinwei Li, Kaisen Yang, Yangcheng Yu, Zeda Wang, Wenyi Li, Leichen Wang, Xingtao Hu, Hao Sun, Hang Zhao, and Hao Zhao. Impromptu vla: Open weights and open data for driving vision-language-action models, 2025. 1, 3, 6, 7
2025
-
[12]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long con- text, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261, 2025. 8
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
Xinpeng Ding, Jianhua Han, Hang Xu, Wei Zhang, and Xi- aomeng Li. Hilm-d: Towards high-resolution understanding in multimodal large language models for autonomous driving. arXiv preprint arXiv:2309.05186, 2023. 2
-
[14]
Carla: An open urban driving simulator
Alexey Dosovitskiy, German Ros, Felipe Codevilla, Antonio Lopez, and Vladlen Koltun. Carla: An open urban driving simulator. InConference on robot learning, 2017. 3
2017
-
[15]
Mini-internvl: A flexible-transfer pocket multimodal model with 5% parameters and 90% performance
Zhangwei Gao, Zhe Chen, Erfei Cui, Yiming Ren, Weiyun Wang, Jinguo Zhu, Hao Tian, Shenglong Ye, Junjun He, Xizhou Zhu, et al. Mini-internvl: A flexible-transfer pocket multimodal model with 5% parameters and 90% performance. arXiv preprint arXiv:2410.16261, 2024. 6
-
[16]
Continual learning for generative ai: From llms to mllms and beyond,
Haiyang Guo, Fanhu Zeng, Fei Zhu, Jiayi Wang, Xukai Wang, Jingang Zhou, Hongbo Zhao, Wenzhuo Liu, Shijie Ma, Da- Han Wang, Xu-Yao Zhang, and Cheng-Lin Liu. Continual learning for generative ai: From llms to mllms and beyond,
-
[17]
Planning-oriented autonomous driv- ing, 2023
Yihan Hu, Jiazhi Yang, Li Chen, Keyu Li, Chonghao Sima, Xizhou Zhu, Siqi Chai, Senyao Du, Tianwei Lin, Wenhai Wang, Lewei Lu, Xiaosong Jia, Qiang Liu, Jifeng Dai, Yu Qiao, and Hongyang Li. Planning-oriented autonomous driv- ing, 2023. 1
2023
-
[18]
Robotron- drive: All-in-one large multimodal model for autonomous driving
Zhijian Huang, Chengjian Feng, Feng Yan, Baihui Xiao, Ze- qun Jie, Yujie Zhong, Xiaodan Liang, and Lin Ma. Robotron- drive: All-in-one large multimodal model for autonomous driving. InProceedings of the IEEE/CVF International Con- ference on Computer Vision, pages 8011–8021, 2025. 6
2025
-
[19]
Vad: Vectorized scene representation for efficient autonomous driving, 2023
Bo Jiang, Shaoyu Chen, Qing Xu, Bencheng Liao, Jiajie Chen, Helong Zhou, Qian Zhang, Wenyu Liu, Chang Huang, and Xinggang Wang. Vad: Vectorized scene representation for efficient autonomous driving, 2023. 1
2023
-
[20]
Bo Jiang, Shaoyu Chen, Qian Zhang, Wenyu Liu, and Xing- gang Wang. Alphadrive: Unleashing the power of vlms in autonomous driving via reinforcement learning and reasoning. arXiv preprint arXiv:2503.07608, 2025. 3
-
[21]
Textual explanations for self-driving vehicles
Jinkyu Kim, Anna Rohrbach, Trevor Darrell, John Canny, and Zeynep Akata. Textual explanations for self-driving vehicles. InECCV, pages 563–578, 2018. 1
2018
-
[22]
Blip- 2: Bootstrapping language-image pre-training with frozen image encoders and large language models
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip- 2: Bootstrapping language-image pre-training with frozen image encoders and large language models. pages 19730– 19742. PMLR, 2023. 1
2023
-
[23]
Fine-grained evaluation of large vision-language mod- els in autonomous driving
Yue Li, Meng Tian, Zhenyu Lin, Jiangtong Zhu, Dechang Zhu, Haiqiang Liu, Yueyi Zhang, Zhiwei Xiong, and Xinhai 9 Zhao. Fine-grained evaluation of large vision-language mod- els in autonomous driving. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 9431– 9442, 2025. 3
2025
-
[24]
ReCogDrive: A Reinforced Cognitive Framework for End-to-End Autonomous Driving
Yongkang Li, Kaixin Xiong, Xiangyu Guo, Fang Li, Sixu Yan, Gangwei Xu, Lijun Zhou, Long Chen, Haiyang Sun, Bing Wang, et al. Recogdrive: A reinforced cognitive framework for end-to-end autonomous driving.arXiv:2506.08052, 2025. 1, 3, 6
work page internal anchor Pith review arXiv 2025
-
[25]
Visual instruction tuning
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning. 36:34892–34916, 2023. 1
2023
-
[26]
Wenru Liu, Pei Liu, and Jun Ma. Dsdrive: Distilling large language model for lightweight end-to-end autonomous driv- ing with unified reasoning and planning.arXiv preprint arXiv:2505.05360, 2025. 3
-
[27]
Llava-c: Continual improved visual instruc- tion tuning.arXiv preprint arXiv:2506.08666, 2025
Wenzhuo Liu, Fei Zhu, Haiyang Guo, Longhui Wei, and Cheng-Lin Liu. Llava-c: Continual improved visual instruc- tion tuning.arXiv preprint arXiv:2506.08666, 2025. 3
-
[28]
arXiv preprint arXiv:2505.20024 , year=
Xueyi Liu, Zuodong Zhong, Yuxin Guo, Yun-Fu Liu, Zhiguo Su, Qichao Zhang, Junli Wang, Yinfeng Gao, Yupeng Zheng, Qiao Lin, et al. Reasonplan: Unified scene prediction and decision reasoning for closed-loop autonomous driving.arXiv preprint arXiv:2505.20024, 2025. 3
-
[29]
Gradient episodic memory for continual learning.Advances in neural information processing systems, 30, 2017
David Lopez-Paz and Marc’Aurelio Ranzato. Gradient episodic memory for continual learning.Advances in neural information processing systems, 30, 2017. 5
2017
-
[30]
Moelora: Contrastive learning guided mixture of experts on parameter-efficient fine-tuning for large language models, 2024
Tongxu Luo, Jiahe Lei, Fangyu Lei, Weihao Liu, Shizhu He, Jun Zhao, and Kang Liu. Moelora: Contrastive learning guided mixture of experts on parameter-efficient fine-tuning for large language models, 2024. 3
2024
-
[31]
Lingoqa: Visual question answering for autonomous driving
Ana-Maria Marcu, Long Chen, Jan H¨unermann, Alice Karn- sund, Benoit Hanotte, Prajwal Chidananda, Saurabh Nair, Vijay Badrinarayanan, Alex Kendall, Jamie Shotton, et al. Lingoqa: Visual question answering for autonomous driving. InEuropean Conference on Computer Vision, pages 252–269. Springer, 2024. 3
2024
-
[32]
Reason2drive: Towards interpretable and chain-based reasoning for autonomous driv- ing
Ming Nie, Renyuan Peng, Chunwei Wang, Xinyue Cai, Jian- hua Han, Hang Xu, and Li Zhang. Reason2drive: Towards interpretable and chain-based reasoning for autonomous driv- ing. InECCV, pages 292–308. Springer, 2024. 1, 2
2024
-
[33]
Gpt-5 system card.openai.com/index/gpt-5-system- card, 2025
OpenAI. Gpt-5 system card.openai.com/index/gpt-5-system- card, 2025. 8
2025
-
[34]
gpt-oss-120b & gpt-oss-20b model card, 2025
OpenAI. gpt-oss-120b & gpt-oss-20b model card, 2025. 3
2025
-
[35]
Bleu: a method for automatic evaluation of machine translation
Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. Bleu: a method for automatic evaluation of machine translation. InProceedings of the 40th annual meeting of the Association for Computational Linguistics, pages 311–318,
-
[36]
Weiguo Pian, Shijian Deng, Shentong Mo, Yunhui Guo, and Yapeng Tian. Modality-inconsistent continual learn- ing of multimodal large language models.arXiv preprint arXiv:2412.13050, 2024. 3
work page internal anchor Pith review arXiv 2024
-
[37]
Understanding inverse document fre- quency: on theoretical arguments for idf.Journal of Docu- mentation, 60(5):503–520, 2004
Stephen Robertson. Understanding inverse document fre- quency: on theoretical arguments for idf.Journal of Docu- mentation, 60(5):503–520, 2004. 4
2004
-
[38]
Lmdrive: Closed-loop end-to-end driving with large language models
Hao Shao, Yuxuan Hu, Letian Wang, Guanglu Song, Steven L Waslander, Yu Liu, and Hongsheng Li. Lmdrive: Closed-loop end-to-end driving with large language models. InCVPR, pages 15120–15130, 2024. 1, 2
2024
-
[39]
Drivelm: Driving with graph visual question answering
Chonghao Sima, Katrin Renz, Kashyap Chitta, Li Chen, Hanxue Zhang, Chengen Xie, Jens Beißwenger, Ping Luo, Andreas Geiger, and Hongyang Li. Drivelm: Driving with graph visual question answering. InEuropean conference on computer vision, pages 256–274. Springer, 2024. 1, 3
2024
-
[40]
Cider: Consensus-based image description evalu- ation
Ramakrishna Vedantam, C Lawrence Zitnick, and Devi Parikh. Cider: Consensus-based image description evalu- ation. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 4566–4575, 2015. 5
2015
-
[41]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, et al. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191, 2024. 1
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[42]
Omnidrive: A holistic llm-agent framework for autonomous driving with 3d perception, reasoning and planning.CoRR,
Shihao Wang, Zhiding Yu, Xiaohui Jiang, Shiyi Lan, Min Shi, Nadine Chang, Jan Kautz, Ying Li, and Jose M Alvarez. Omnidrive: A holistic llm-agent framework for autonomous driving with 3d perception, reasoning and planning.CoRR,
-
[43]
Wenhai Wang, Jiangwei Xie, ChuanYang Hu, Haoming Zou, Jianan Fan, Wenwen Tong, Yang Wen, Silei Wu, Hanming Deng, Zhiqi Li, et al. Drivemlm: Aligning multi-modal large language models with behavioral planning states for autonomous driving.arXiv:2312.09245, 2023. 1, 2
-
[44]
Dilu: A knowledge-driven approach to autonomous driving with large language models
Licheng Wen, Daocheng Fu, Xin Li, Xinyu Cai, Tao Ma, Pinlong Cai, Min Dou, Botian Shi, Liang He, and Yu Qiao. Dilu: A knowledge-driven approach to autonomous driving with large language models.arXiv preprint arXiv:2309.16292,
-
[45]
Trajectory-guided control prediction for end-to-end autonomous driving: A simple yet strong baseline,
Penghao Wu, Xiaosong Jia, Li Chen, Junchi Yan, Hongyang Li, and Yu Qiao. Trajectory-guided control prediction for end-to-end autonomous driving: A simple yet strong baseline,
-
[46]
Shaoyuan Xie, Lingdong Kong, Yuhao Dong, Chonghao Sima, Wenwei Zhang, Qi Alfred Chen, Ziwei Liu, and Liang Pan. Are vlms ready for autonomous driving? an empirical study from the reliability, data, and metric perspectives.arXiv preprint arXiv:2501.04003, 2025. 3
-
[47]
Wod-e2e: Waymo open dataset for end-to-end driving in challenging long-tail scenarios, 2025
Runsheng Xu, Hubert Lin, Wonseok Jeon, Hao Feng, Yuliang Zou, Liting Sun, John Gorman, Kate Tolstaya, Sarah Tang, Brandyn White, Ben Sapp, Mingxing Tan, Jyh-Jing Hwang, and Drago Anguelov. Wod-e2e: Waymo open dataset for end-to-end driving in challenging long-tail scenarios, 2025. 3, 6
2025
-
[48]
Drivegpt4: Interpretable end-to-end autonomous driving via large language model.IEEE Robotics and Automation Letters,
Zhenhua Xu, Yujia Zhang, Enze Xie, Zhen Zhao, Yong Guo, Kwan-Yee K Wong, Zhenguo Li, and Hengshuang Zhao. Drivegpt4: Interpretable end-to-end autonomous driving via large language model.IEEE Robotics and Automation Letters,
-
[49]
Qwen3 technical report, 2025
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report, 2025. 8
2025
-
[50]
Survey of general end-to-end autonomous driving: A unified perspec- tive.TechRxiv, 2025
Yixiang Yang, Chuanrong Han, Runhao Mao, et al. Survey of general end-to-end autonomous driving: A unified perspec- tive.TechRxiv, 2025. 1 10
2025
-
[51]
Zhenlong Yuan, Jing Tang, Jinguo Luo, Rui Chen, Chengxuan Qian, Lei Sun, Xiangxiang Chu, Yujun Cai, Dapeng Zhang, and Shuo Li. Autodrive-r 2: Incentivizing reasoning and self- reflection capacity for vla model in autonomous driving.arXiv preprint arXiv:2509.01944, 2025. 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[52]
Fanhu Zeng, Fei Zhu, Haiyang Guo, Xu-Yao Zhang, and Cheng-Lin Liu. Modalprompt: Towards efficient multi- modal continual instruction tuning with dual-modality guided prompt.arXiv preprint arXiv:2410.05849, 2024. 3
-
[53]
Futuresightdrive: Thinking visually with spatio-temporal cot for autonomous driving,
Shuang Zeng, Xinyuan Chang, Mengwei Xie, Xinran Liu, Yi- fan Bai, Zheng Pan, Mu Xu, and Xing Wei. Futuresightdrive: Thinking visually with spatio-temporal cot for autonomous driving.arXiv preprint arXiv:2505.17685, 2025. 2
-
[54]
Feedback-guided autonomous driving
Jimuyang Zhang, Zanming Huang, Arijit Ray, and Eshed Ohn- Bar. Feedback-guided autonomous driving. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15000–15011, 2024. 3
2024
-
[55]
Safeauto: Knowledge-enhanced safe autonomous driving with multimodal foundation models
Jiawei Zhang, Xuan Yang, Taiqi Wang, Yu Yao, Aleksandr Petiushko, and Bo Li. Safeauto: Knowledge-enhanced safe autonomous driving with multimodal foundation models. In Proceedings of the 42nd International Conference on Machine Learning, pages 76497–76517. PMLR, 2025. 6
2025
-
[56]
Multi-prototype grouping for continual learning in visual question answering
Licheng Zhang, Zhendong Mao, Yixing Peng, Zheren Fu, and Yongdong Zhang. Multi-prototype grouping for continual learning in visual question answering. InICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1–5. IEEE, 2025. 3
2025
-
[57]
Songyan Zhang, Wenhui Huang, Zihui Gao, Hao Chen, and Chen Lv. Wisead: Knowledge augmented end- to-end autonomous driving with vision-language model. arXiv:2412.09951, 2024. 6
-
[58]
Vqacl: A novel visual question answering continual learning setting
Xi Zhang, Feifei Zhang, and Changsheng Xu. Vqacl: A novel visual question answering continual learning setting. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 19102–19112, 2023. 3
2023
-
[59]
Hengyuan Zhao, Ziqin Wang, Qixin Sun, Kaiyou Song, Yilin Li, Xiaolin Hu, Qingpei Guo, and Si Liu. Llava-cmoe: To- wards continual mixture of experts for large vision-language models.arXiv preprint arXiv:2503.21227, 2025. 3
-
[60]
Sce2drivex: A generalized mllm framework for scene-to-drive learning.IEEE Robotics and Automation Letters, 2025
Rui Zhao, Qirui Yuan, Jinyu Li, Haofeng Hu, Yun Li, Zhen- hai Gao, and Fei Gao. Sce2drivex: A generalized mllm framework for scene-to-drive learning.IEEE Robotics and Automation Letters, 2025. 2
2025
-
[61]
Xingcheng Zhou, Xuyuan Han, Feng Yang, Yunpu Ma, and Alois C Knoll. Opendrivevla: Towards end-to-end au- tonomous driving with large vision language action model. arXiv preprint arXiv:2503.23463, 2025. 2
-
[62]
Zewei Zhou, Tianhui Cai, Seth Z Zhao, Yun Zhang, Zhiyu Huang, Bolei Zhou, and Jiaqi Ma. Autovla: A vision- language-action model for end-to-end autonomous driv- ing with adaptive reasoning and reinforcement fine-tuning. arXiv:2506.13757, 2025. 1, 3
work page internal anchor Pith review arXiv 2025
-
[63]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
Jinguo Zhu, Weiyun Wang, Zhe Chen, Zhaoyang Liu, Shen- glong Ye, Lixin Gu, Hao Tian, Yuchen Duan, Weijie Su, Jie Shao, et al. Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models.arXiv preprint arXiv:2504.10479, 2025. 2 11
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.