Recognition: 2 theorem links
· Lean TheoremFairLogue: A Toolkit for Intersectional Fairness Analysis in Clinical Machine Learning Models
Pith reviewed 2026-05-10 20:04 UTC · model grok-4.3
The pith
A toolkit for intersectional fairness shows larger disparities in clinical ML models than single-axis methods.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
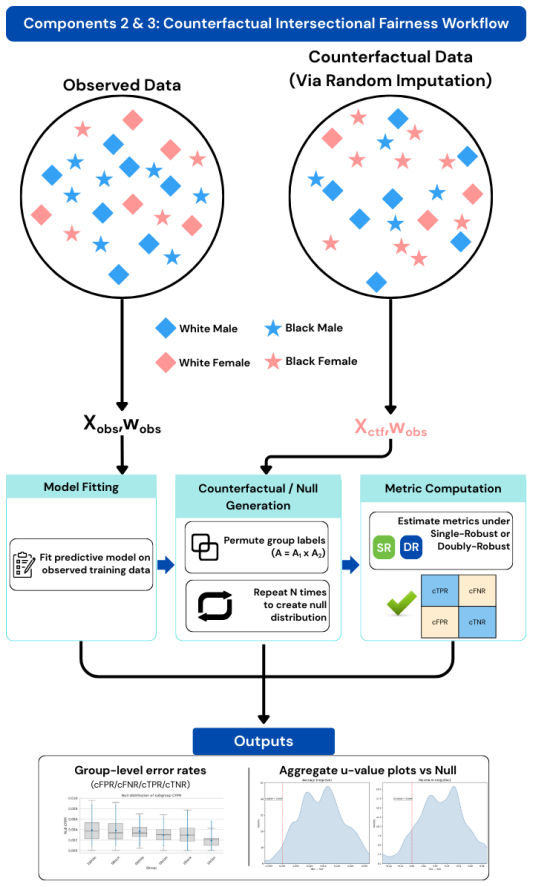
The authors claim that FairLogue operationalizes intersectional fairness assessment through an observational framework that extends demographic parity, equalized odds, and equal opportunity to intersectional populations, a counterfactual framework for treatment-based contexts, and a generalized counterfactual framework for interventions on intersectional group membership, as demonstrated by larger fairness gaps in the All of Us glaucoma surgery prediction task than single-axis analyses.
What carries the argument
FairLogue's modular structure of an observational framework extending fairness metrics to intersections plus two counterfactual frameworks for assessing fairness under interventions on group membership.
Load-bearing premise
The permutation-based null distributions accurately represent fairness under chance after conditioning on covariates, and the All of Us dataset with logistic regression generalizes to other clinical tasks.
What would settle it
Applying FairLogue to a different clinical prediction task or dataset where intersectional fairness gaps are not larger than single-axis gaps would challenge the demonstrated advantage of the toolkit.
Figures

read the original abstract
Objective: Algorithmic fairness is essential for equitable and trustworthy machine learning in healthcare. Most fairness tools emphasize single-axis demographic comparisons and may miss compounded disparities affecting intersectional populations. This study introduces Fairlogue, a toolkit designed to operationalize intersectional fairness assessment in observational and counterfactual contexts within clinical settings. Methods: Fairlogue is a Python-based toolkit composed of three components: 1) an observational framework extending demographic parity, equalized odds, and equal opportunity difference to intersectional populations; 2) a counterfactual framework evaluating fairness under treatment-based contexts; and 3) a generalized counterfactual framework assessing fairness under interventions on intersectional group membership. The toolkit was evaluated using electronic health record data from the All of Us Controlled Tier V8 dataset in a glaucoma surgery prediction task using logistic regression with race and gender as protected attributes. Results: Observational analysis identified substantial intersectional disparities despite moderate model performance (AUROC = 0.709; accuracy = 0.651). Intersectional evaluation revealed larger fairness gaps than single-axis analyses, including demographic parity differences of 0.20 and equalized odds true positive and false positive rate gaps of 0.33 and 0.15, respectively. Counterfactual analysis using permutation-based null distributions produced unfairness ("u-value") estimates near zero, suggesting observed disparities were consistent with chance after conditioning on covariates. Conclusion: Fairlogue provides a modular toolkit integrating observational and counterfactual methods for quantifying and evaluating intersectional bias in clinical machine learning workflows.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
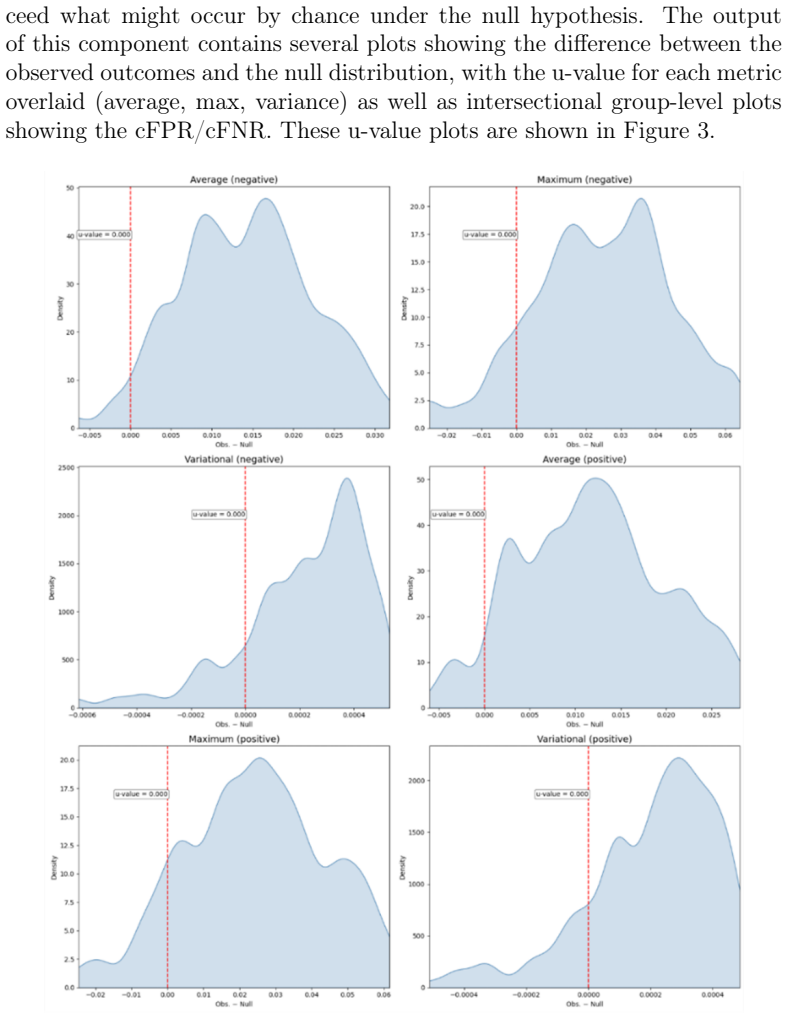
Summary. The manuscript introduces FairLogue, a Python toolkit for intersectional fairness analysis in clinical machine learning. It comprises an observational framework extending demographic parity, equalized odds, and equal opportunity to intersectional groups; a counterfactual framework using permutation-based null distributions; and a generalized counterfactual framework for interventions on group membership. The toolkit is demonstrated on the All of Us dataset for predicting glaucoma surgery with logistic regression, revealing larger fairness gaps in intersectional analyses (demographic parity difference of 0.20, equalized odds gaps of 0.33 and 0.15) compared to single-axis, with counterfactual u-values near zero indicating disparities consistent with chance after covariate conditioning, despite moderate model performance (AUROC=0.709).
Significance. If the methodological details are clarified, the toolkit could provide a useful modular resource for operationalizing intersectional fairness in healthcare ML, where single-axis tools are common. The evaluation on a public dataset offers a concrete, reproducible example of how intersectional gaps can exceed single-axis ones, and the open-source design supports extension. The finding that observational disparities may be consistent with chance under the counterfactual is potentially valuable for distinguishing bias from covariate effects, but its impact depends on the validity of the null distribution construction.
major comments (2)
- [Abstract/Methods] Abstract and Methods: The permutation procedure underlying the counterfactual framework's null distributions is not described (e.g., whether it shuffles outcomes while preserving the joint distribution of covariates and protected attributes, uses exact matching, or applies unconditional shuffling). This directly affects the claim that u-values near zero show disparities are 'consistent with chance after conditioning on covariates,' as an unconditioned permutation would miscalibrate the null for variables correlated with both race/gender and the glaucoma surgery outcome.
- [Results] Results: The reported intersectional fairness gaps (demographic parity difference of 0.20; equalized odds TPR/FPR gaps of 0.33 and 0.15) and model performance metrics are given as point estimates without error bars, confidence intervals, or per-group sample sizes. This weakens the central claim that intersectional evaluation reveals substantially larger gaps than single-axis analyses, as the magnitude and reliability of the differences cannot be assessed without these details.
minor comments (2)
- [Methods] The definition and exact computation of the 'u-value' (unfairness estimate) should be stated explicitly in the Methods, including its relation to the permutation null.
- [Methods] Clarify how intersectional groups were defined and sampled (e.g., handling of missing race/gender data or minimum group size thresholds) to allow replication of the observational results.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major point below and will revise the manuscript to incorporate the requested clarifications and details.
read point-by-point responses
-
Referee: [Abstract/Methods] Abstract and Methods: The permutation procedure underlying the counterfactual framework's null distributions is not described (e.g., whether it shuffles outcomes while preserving the joint distribution of covariates and protected attributes, uses exact matching, or applies unconditional shuffling). This directly affects the claim that u-values near zero show disparities are 'consistent with chance after conditioning on covariates,' as an unconditioned permutation would miscalibrate the null for variables correlated with both race/gender and the glaucoma surgery outcome.
Authors: We agree that the permutation procedure requires explicit description to support the interpretation of the u-values. In the revised manuscript, we will expand the Methods section to detail that the null distributions are constructed by permuting the outcome labels while preserving the joint distribution of covariates and protected attributes. This ensures proper conditioning on covariates, consistent with our claim that observed disparities align with chance under the null after covariate adjustment. We will also include implementation pseudocode for clarity and reproducibility. revision: yes
-
Referee: [Results] Results: The reported intersectional fairness gaps (demographic parity difference of 0.20; equalized odds TPR/FPR gaps of 0.33 and 0.15) and model performance metrics are given as point estimates without error bars, confidence intervals, or per-group sample sizes. This weakens the central claim that intersectional evaluation reveals substantially larger gaps than single-axis analyses, as the magnitude and reliability of the differences cannot be assessed without these details.
Authors: We agree that uncertainty measures and subgroup sizes are needed to assess the reliability of the reported gaps. In the revised Results section, we will include per-group sample sizes for the intersectional subgroups from the All of Us dataset. We will also add bootstrap confidence intervals for the fairness gap estimates (demographic parity difference, equalized odds TPR/FPR gaps) and model performance metrics (AUROC, accuracy) to allow evaluation of the differences between intersectional and single-axis analyses. revision: yes
Circularity Check
No circularity: toolkit applies standard metrics to external dataset without self-referential reductions.
full rationale
The paper defines FairLogue as a modular Python toolkit that extends established fairness metrics (demographic parity, equalized odds, equal opportunity) to intersectional groups in observational and counterfactual settings. Results are obtained by applying these methods to the public All of Us dataset in a logistic regression task for glaucoma surgery prediction, with permutation-based null distributions used to generate u-values. No equations, self-citations, or ansatzes reduce the reported disparities or u-values to fitted parameters by construction; the evaluation remains externally verifiable on independent data.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Standard definitions of demographic parity, equalized odds, and equal opportunity can be directly extended to intersectional subgroups without additional assumptions about group independence.
- domain assumption Permutation-based null distributions correctly model fairness under chance after conditioning on observed covariates.
invented entities (1)
-
u-value (unfairness estimate)
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Counterfactual analysis using permutation-based null distributions produced overall measures of unfairness (u-values) approaching zero
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
intersectional extensions of demographic parity, equalized odds, and equal opportunity difference
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
- [1]
-
[2]
Walsh, C.G., et al., Stigma, biomarkers, and algorithmic bias: recommendations for precision behavioral health with artificial intelligence, JAMIA Open 3(1) (2020) 9--15
2020
-
[3]
Baxter, S.L., et al., Predictive Analytics for Glaucoma Using Data From the All of Us Research Program, Am. J. Ophthalmol. 227 (2021) 74--86
2021
-
[4]
ACM SIGKDD (2022) 1452--1462
Rahman, M.M., Purushotham, S., Fair and Interpretable Models for Survival Analysis, Proc. ACM SIGKDD (2022) 1452--1462
2022
-
[5]
Poulain, R., Bin Tarek, M.F., Beheshti, R., Improving Fairness in AI Models on Electronic Health Records: The Case for Federated Learning Methods, ACM FAccT (2023) 1599--1608
2023
-
[6]
Wastvedt, S., Huling, J., Wolfson, J., An intersectional framework for counterfactual fairness in risk prediction, Biostatistics (2023) kxad021
2023
- [7]
-
[8]
La Cava, W.G., Lett, E., Wan, G., Fair admission risk prediction with proportional multicalibration, PMLR 209 (2023) 350--378
2023
-
[9]
Department of Health and Human Services, All of Us Research Program Core Values, National Institutes of Health
U.S. Department of Health and Human Services, All of Us Research Program Core Values, National Institutes of Health
- [10]
-
[11]
Saleiro, P., et al., Aequitas: A bias and fairness audit toolkit, arXiv:1811.05577, 2018
work page Pith review arXiv 2018
-
[12]
Johnson, B., Brun, Y., Fairkit-learn: A fairness evaluation and comparison toolkit, ICSE Companion (2022) 70--74
2022
-
[13]
Weerts, H., et al., Fairlearn: Assessing and improving fairness of AI systems, JMLR 24(257) (2023) 1--8
2023
-
[14]
Abadi, M., et al., TensorFlow: Large-scale machine learning on heterogeneous systems, 2015
2015
-
[15]
Panigutti, C., et al., FairLens: Auditing black-box clinical decision support systems, Inf. Process. Manage. 58(5) (2021) 102657
2021
-
[16]
Wiśniewski, J., Biecek, P., fairmodels: A flexible tool for bias detection, visualization, and mitigation in binary classification models, R Journal 14(1) (2022) 227--243
2022
-
[17]
Kozodoi, N., Varga, T.V., fairness: Algorithmic fairness metrics, CRAN, 2021
2021
-
[18]
Lu, J., et al., Considerations in the reliability and fairness audits of predictive models for advance care planning, Front. Digit. Health 4 (2022) 943768
2022
-
[19]
Yang, Y., et al., Demographic bias of expert-level vision-language foundation models in medical imaging, Science Advances 11(13) eadq0305
-
[20]
FAIM, Fairness-aware interpretable modeling for trustworthy machine learning in healthcare, Patterns 5(10) (2024) 101059
2024
-
[21]
Barocas, S., Hardt, M., Narayanan, A., Fairness and Machine Learning, 2023
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.