Recognition: no theorem link
Beyond the Global Scores: Fine-Grained Token Grounding as a Robust Detector of LVLM Hallucinations
Pith reviewed 2026-05-10 19:51 UTC · model grok-4.3
The pith
Hallucinated tokens in vision-language models show diffuse attention and weak patch alignment, enabling fine-grained detection at up to 90 percent accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
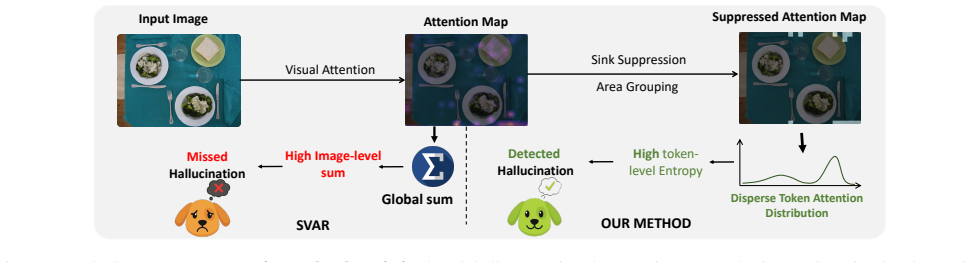
A faithful object token must be strongly grounded in a specific image region. Hallucinated tokens instead produce diffuse, non-localized attention patterns and fail to exhibit meaningful semantic alignment with any visual region. These two signatures, observed through patch-level analysis across model layers, allow a lightweight detector that combines patch statistical features with hidden-layer representations to identify hallucinations at the token level.
What carries the argument
Patch-level hallucination detection framework that extracts statistical features from token-to-patch attention maps and hidden representations to measure attention locality and semantic alignment.
If this is right
- Token-level hallucination detection can outperform global relevance scoring on the same models and data.
- Attention locality and semantic alignment serve as interpretable signals that separate faithful from hallucinated outputs.
- The method requires no extra training and works with existing model internals.
- Detection remains accurate even when global scores are misleading due to scattered low-level correlations.
Where Pith is reading between the lines
- The same patch signatures could be used to guide correction steps that replace hallucinated tokens with better-grounded alternatives.
- Extending the analysis to video or multi-frame inputs might reveal temporal versions of the same diffuse-attention pattern.
- If the signatures hold across architectures, they offer a way to audit new models without task-specific fine-tuning.
Load-bearing premise
The two observed signatures of diffuse attention and missing semantic alignment are assumed to be consistent indicators of hallucination in any LVLM, task, or dataset.
What would settle it
Finding a token that is verifiably hallucinated yet shows compact localized attention and strong semantic alignment with at least one image patch, or a faithful token that shows diffuse attention, would disprove the detection rule.
Figures









read the original abstract
Large vision-language models (LVLMs) achieve strong performance on visual reasoning tasks but remain highly susceptible to hallucination. Existing detection methods predominantly rely on coarse, whole-image measures of how an object token relates to the input image. This global strategy is limited: hallucinated tokens may exhibit weak but widely scattered correlations across many local regions, which aggregate into deceptively high overall relevance, thus evading the current global hallucination detectors. We begin with a simple yet critical observation: a faithful object token must be strongly grounded in a specific image region. Building on this insight, we introduce a patch-level hallucination detection framework that examines fine-grained token-level interactions across model layers. Our analysis uncovers two characteristic signatures of hallucinated tokens: (i) they yield diffuse, non-localized attention patterns, in contrast to the compact, well-focused attention seen in faithful tokens; and (ii) they fail to exhibit meaningful semantic alignment with any visual region. Guided by these findings, we develop a lightweight and interpretable detection method that leverages patch-level statistical features, combined with hidden-layer representations. Our approach achieves up to 90% accuracy in token-level hallucination detection, demonstrating the superiority of fine-grained structural analysis for detecting hallucinations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that existing global-score methods for detecting hallucinations in large vision-language models (LVLMs) are limited because hallucinated tokens can produce weak but scattered correlations that aggregate into misleadingly high relevance scores. It introduces a patch-level framework that analyzes fine-grained token interactions across layers, identifies two signatures of hallucinated tokens (diffuse/non-localized attention patterns and absence of semantic alignment with any image patch), and builds a lightweight detector from patch-level statistical features plus hidden representations. The approach is reported to reach up to 90% token-level accuracy and to demonstrate the superiority of fine-grained structural analysis.
Significance. If the signatures prove general and the accuracy holds under rigorous cross-model and cross-dataset testing, the work would offer a practical, interpretable alternative to coarse global metrics, directly addressing a key reliability bottleneck in multimodal reasoning systems. The emphasis on lightweight, feature-based detection without heavy additional training is a potential strength for deployment.
major comments (2)
- [Abstract] Abstract: The central claim of up to 90% token-level accuracy and superiority over global methods is presented without any reference to datasets, number of LVLMs evaluated, baselines, evaluation protocol, or statistical measures. This information is load-bearing for assessing whether the two signatures are reliable and general rather than artifacts of the specific test distribution.
- [Abstract] Abstract: The argument that diffuse attention and lack of semantic alignment are characteristic signatures of hallucination assumes these patterns hold across models, tasks, and datasets. No cross-validation results or diversity details are supplied, leaving open the possibility that the reported performance reflects overfitting rather than a robust, fine-grained advantage.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. The feedback highlights important aspects of how the abstract presents our claims, and we address each point below with a commitment to revision where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim of up to 90% token-level accuracy and superiority over global methods is presented without any reference to datasets, number of LVLMs evaluated, baselines, evaluation protocol, or statistical measures. This information is load-bearing for assessing whether the two signatures are reliable and general rather than artifacts of the specific test distribution.
Authors: We agree that the abstract's brevity leaves the central claim without immediate context on scope. The full manuscript details evaluations across multiple LVLMs, standard hallucination benchmarks, global-score baselines, and protocols with accuracy metrics. To strengthen the abstract, we will add a concise clause referencing the evaluation breadth (e.g., 'evaluated on multiple LVLMs and datasets with comparisons to global baselines'). This revision will make the claim more self-contained without expanding the abstract's length substantially. revision: yes
-
Referee: [Abstract] Abstract: The argument that diffuse attention and lack of semantic alignment are characteristic signatures of hallucination assumes these patterns hold across models, tasks, and datasets. No cross-validation results or diversity details are supplied, leaving open the possibility that the reported performance reflects overfitting rather than a robust, fine-grained advantage.
Authors: The signatures emerge from layer-wise patch-level analysis conducted on diverse LVLMs and tasks in the manuscript, with the detector validated across datasets to show consistency. Our approach relies on lightweight, non-trained statistical features rather than complex models prone to overfitting. We will revise the abstract to explicitly note the cross-model and cross-dataset scope of the evaluation, thereby underscoring the generality of the signatures while preserving conciseness. revision: yes
Circularity Check
No circularity; purely empirical observation and lightweight detector
full rationale
The paper describes an observational study: patch-level analysis reveals two attention signatures for hallucinated tokens, which are then used to construct a statistical-feature detector. No equations, parameter fits, derivations, or self-citations appear in the provided text that would reduce any claimed result to its own inputs by construction. The 90% accuracy is reported as an empirical outcome on the examined models and data, not a prediction forced by prior fitting or definitional equivalence. This satisfies the default expectation of no circularity for an empirical method without load-bearing self-referential steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Flamingo: a visual language model for few-shot learning
Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, et al. Flamingo: a visual language model for few-shot learning. InProceedings of the 36th International Confer- ence on Neural Information Processing Systems, Red Hook, NY , USA, 2022. Curran Associates Inc. 2
work page 2022
-
[2]
Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and Jingren Zhou. Qwen-vl: A versatile vision-language model for un- derstanding, localization, text reading, and beyond, 2023. 1, 2
work page 2023
-
[3]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025. 6
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Krzysztof Baron-Lis, Matthias Rottmann, Annika Mütze, Sina Honari, Pascal Fua, and Mathieu Salzmann. Attentropy: On the generalization ability of supervised semantic segmen- tation transformers to new objects in new domains. In35th British Machine Vision Conference 2024, BMVC 2024, Glas- gow, UK, November 25-28, 2024. BMV A, 2024. 5
work page 2024
-
[5]
Multi-object hallucination in vision language models
Xuweiyi Chen, Ziqiao Ma, Xuejun Zhang, Sihan Xu, Shengyi Qian, Jianing Yang, David Fouhey, and Joyce Chai. Multi-object hallucination in vision language models. In The Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024. 3
work page 2024
-
[6]
Zhe Chen, Weiyun Wang, Yue Cao, Yangzhou Liu, Zhang- wei Gao, Erfei Cui, Jinguo Zhu, Shenglong Ye, Hao Tian, Zhaoyang Liu, et al. Expanding performance boundaries of open-source multimodal models with model, data, and test- time scaling.arXiv preprint arXiv:2412.05271, 2024. 2, 6
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
InstructBLIP: Towards general-purpose vision-language models with instruction tuning
Wenliang Dai, Junnan Li, Dongxu Li, Anthony Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale Fung, and Steven Hoi. InstructBLIP: Towards general-purpose vision-language models with instruction tuning. InThirty- seventh Conference on Neural Information Processing Sys- tems, 2023. 1, 2
work page 2023
-
[8]
Metatoken: Detecting hallucination in image descriptions by meta classification
Laura Fieback, Jakob Spiegelberg, and Hanno Gottschalk. Metatoken: Detecting hallucination in image descriptions by meta classification. InVISIGRAPP : VISAPP, 2024. 1, 3, 7, 8
work page 2024
-
[9]
Detecting and pre- venting hallucinations in large vision language models
Anisha Gunjal, Jihan Yin, and Erhan Bas. Detecting and pre- venting hallucinations in large vision language models. In Proceedings of the Thirty-Eighth AAAI Conference on Artifi- cial Intelligence and Thirty-Sixth Conference on Innovative Applications of Artificial Intelligence and Fourteenth Sym- posium on Educational Advances in Artificial Intelligence....
work page 2024
-
[10]
Yixiao He, Haifeng Sun, Pengfei Ren, Jingyu Wang, Huazheng Wang, Qi Qi, Zirui Zhuang, and Jing Wang. Eval- uating and mitigating object hallucination in large vision- language models: Can they still see removed objects? In Proceedings of the 2025 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Tech...
work page 2025
-
[11]
Interpreting and editing vision-language representations to mitigate hallucinations
Nicholas Jiang, Anish Kachinthaya, Suzanne Petryk, and Yossi Gandelsman. Interpreting and editing vision-language representations to mitigate hallucinations. InThe Thir- teenth International Conference on Learning Representa- tions, 2025. 7, 8
work page 2025
-
[12]
Zhangqi Jiang, Junkai Chen, Beier Zhu, Tingjin Luo, Yankun Shen, and Xu Yang. Devils in middle layers of large vision- language models: Interpreting, detecting and mitigating ob- ject hallucinations via attention lens. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 25004–25014, 2025. 1, 2, 3, 4, 7, 8
work page 2025
-
[13]
Your large vision-language model only needs a few attention heads for visual grounding
Seil Kang, Jinyeong Kim, Junhyeok Kim, and Seong Jae Hwang. Your large vision-language model only needs a few attention heads for visual grounding. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 9339–9350, 2025. 5
work page 2025
-
[14]
Sicong Leng, Hang Zhang, Guanzheng Chen, Xin Li, Shi- jian Lu, Chunyan Miao, and Lidong Bing. Mitigating object hallucinations in large vision-language models through vi- sual contrastive decoding. In2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 13872–13882, 2024. 4
work page 2024
-
[15]
Bo Li, Yuanhan Zhang, Liangyu Chen, Jinghao Wang, Fanyi Pu, Joshua Adrian Cahyono, Jingkang Yang, Chunyuan Li, and Ziwei Liu. Otter: A multi-modal model with in-context instruction tuning.IEEE Transactions on Pattern Analysis and Machine Intelligence, 47(9):7543–7557, 2025. 1
work page 2025
-
[16]
VisualBERT: A Simple and Performant Baseline for Vision and Language
Liunian Harold Li, Mark Yatskar, Da Yin, Cho-Jui Hsieh, and Kai-Wei Chang. Visualbert: A simple and performant baseline for vision and language.ArXiv, abs/1908.03557,
work page internal anchor Pith review arXiv 1908
-
[17]
Evaluating object hallucination in large vision-language models
Yifan Li, Yifan Du, Kun Zhou, Jinpeng Wang, Wayne Xin Zhao, and Ji-Rong Wen. Evaluating object hallucination in large vision-language models. InProceedings of the 2023 conference on empirical methods in natural language pro- cessing, pages 292–305, 2023. 1, 2, 3, 7
work page 2023
-
[18]
Microsoft coco: Common objects in context
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick. Microsoft coco: Common objects in context. In European conference on computer vision, pages 740–755. Springer, 2014. 4
work page 2014
-
[19]
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning. InAdvances in Neural Information Processing Systems, pages 34892–34916. Curran Associates, Inc., 2023. 1, 2, 6
work page 2023
-
[20]
Self- CheckGPT: Zero-resource black-box hallucination detection for generative large language models
Potsawee Manakul, Adian Liusie, and Mark Gales. Self- CheckGPT: Zero-resource black-box hallucination detection for generative large language models. InProceedings of the 2023 Conference on Empirical Methods in Natural Lan- guage Processing, pages 9004–9017, Singapore, 2023. As- sociation for Computational Linguistics. 3
work page 2023
-
[21]
Hal- loc: Token-level localization of hallucinations for vision lan- guage models
Eunkyu Park, Minyeong Kim, and Gunhee Kim. Hal- loc: Token-level localization of hallucinations for vision lan- guage models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 29893–29903, 2025. 1, 3, 6, 7, 8
work page 2025
-
[22]
Object hallucination in image cap- tioning
Anna Rohrbach, Lisa Anne Hendricks, Kaylee Burns, Trevor Darrell, and Kate Saenko. Object hallucination in image cap- tioning. InProceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 4035–4045,
work page 2018
-
[23]
From pixels to tokens: Revisiting object hallucina- tions in large vision-language models
Yuying Shang, Xinyi Zeng, Yutao Zhu, Xiao Yang, Zheng- wei Fang, Jingyuan Zhang, Jiawei Chen, Zinan Liu, and Yu Tian. From pixels to tokens: Revisiting object hallucina- tions in large vision-language models. InProceedings of the 33rd ACM International Conference on Multimedia, pages 10496–10505, 2025. 3
work page 2025
- [24]
-
[25]
Logical closed loop: Uncover- ing object hallucinations in large vision-language models
Junfei Wu, Qiang Liu, Ding Wang, Jinghao Zhang, Shu Wu, Liang Wang, and Tieniu Tan. Logical closed loop: Uncover- ing object hallucinations in large vision-language models. In Findings of ACL 2024, 2024. 3
work page 2024
-
[26]
Detecting and mitigating hallucination in large vision language models via fine-grained ai feedback
Wenyi Xiao, Ziwei Huang, Leilei Gan, Wanggui He, Haoyuan Li, Zhelun Yu, Fangxun Shu, Hao Jiang, and Lin- chao Zhu. Detecting and mitigating hallucination in large vision language models via fine-grained ai feedback. InPro- ceedings of the AAAI Conference on Artificial Intelligence, pages 25543–25551, 2025. 3
work page 2025
-
[27]
mPLUG- owl3: Towards long image-sequence understanding in multi- modal large language models
Jiabo Ye, Haiyang Xu, Haowei Liu, Anwen Hu, Ming Yan, Qi Qian, Ji Zhang, Fei Huang, and Jingren Zhou. mPLUG- owl3: Towards long image-sequence understanding in multi- modal large language models. InThe Thirteenth Interna- tional Conference on Learning Representations, 2025. 1
work page 2025
-
[28]
Shukang Yin, Chaoyou Fu, Sirui Zhao, Tong Xu, Hao Wang, Dianbo Sui, Yunhang Shen, Ke Li, Xing Sun, and Enhong Chen. Woodpecker: hallucination correction for multimodal large language models.Science China Information Sciences, 67(12), 2024. 3
work page 2024
-
[29]
Dhcp: Detecting hallucinations by cross-modal attention pat- tern in large vision-language models
Yudong Zhang, Ruobing Xie, Xingwu Sun, Yiqing Huang, Jiansheng Chen, Zhanhui Kang, Di Wang, and Yu Wang. Dhcp: Detecting hallucinations by cross-modal attention pat- tern in large vision-language models. InProceedings of the 33rd ACM International Conference on Multimedia, pages 3555–3564, 2025. 3, 7, 8
work page 2025
-
[30]
MiniGPT-4: Enhancing vision-language understanding with advanced large language models
Deyao Zhu, Jun Chen, Xiaoqian Shen, Xiang Li, and Mo- hamed Elhoseiny. MiniGPT-4: Enhancing vision-language understanding with advanced large language models. InThe Twelfth International Conference on Learning Representa- tions, 2024. 1, 2 Beyond the Global Scores: Fine-Grained Token Grounding as a Robust Detector of LVLM Hallucinations Supplementary Material
work page 2024
-
[31]
11 of the original paper is always zero; we instead use token probability directly
Experimental configurations For hallucination detection, our configurations are as fol- lows: •MetaToken: For our greedy decoding setup, the proba- bility difference term in Eq. 11 of the original paper is always zero; we instead use token probability directly. We implement two binary classifiers, Logistic Regression (LR) withlbfgssolver and Gradient Boos...
-
[32]
This is be- cause the CHAIR toolkit often misses or return excessive words in case of ambiguity
Dataset curation In order to construct a hallucination detection dataset, in- stead of following previous papers to use CHAIR [22], we used GPT-4o API to extract hallucinated words. This is be- cause the CHAIR toolkit often misses or return excessive words in case of ambiguity. The prompt structure we used is as follows 11: It is possible that an object w...
-
[33]
The results for our two features are shown in Tab
Ablation Studies We keep the classifier fixed (LLaV A features + MLP) and vary which layer combinations are included. The results for our two features are shown in Tab. 6. We observe that, typ- ically the middle layers (around 12-24) are the layers with richest semantic features and best alignment between text and images, yielding the best results. Meanwh...
-
[34]
The re- sult is displayed with Fig 11
Feature Importance We compute the mean SHAP values of layer-wise ADS and CGC features, for LLaV A-1.5 + MLP classifier. The re- sult is displayed with Fig 11. We observe the findings is consistent with 8, where features from the middle layers are the most influential for cross-modal attention and align- ment, meanwhile for the final layers these informati...
-
[35]
Effect of adding CGC and ADS features to hallucination detectors across three VLMs
Combining Our Features With SV AR Model Features AUC F1 LLaV A-1.5 SV AR 85.12 69.35 +CGC 87.72 73.52 +ADS 89.04 74.03 +CGC+ADS89.41 74.07 Qwen 2.5-VL-8B SV AR 87.85 76.38 +CGC 86.79 76.24 +ADS 89.11 79.12 +CGC+ADS90.28 81.09 InternVL-2.5-8B SV AR 86.21 76.31 +CGC 86.39 79.43 +ADS 88.02 81.03 +CGC+ADS89.54 81.56 Table 7. Effect of adding CGC and ADS featu...
-
[36]
Ablation Studies We report the sensitivity of our detector to two important threshold parameter choices: Top-x% (Equation 1, page 5), which determines how many attention patches we recognize as object patches with 8-connected components for ADS, and Top-kfor CGC (Equation 7), which are the percentage ADS CGC Top-x% AUC F1 Top-k% AUC F1 5% 81.65 76.54 1% 8...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.