Recognition: no theorem link
Bayesian Global-Local Shrinkage with Univariate Guidance for Ultra-High-Dimensional Regression
Pith reviewed 2026-05-13 17:49 UTC · model grok-4.3
The pith
BUGS modulates the regularized horseshoe prior with univariate marginal associations to achieve adaptive shrinkage and posterior contraction in ultra-high dimensions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
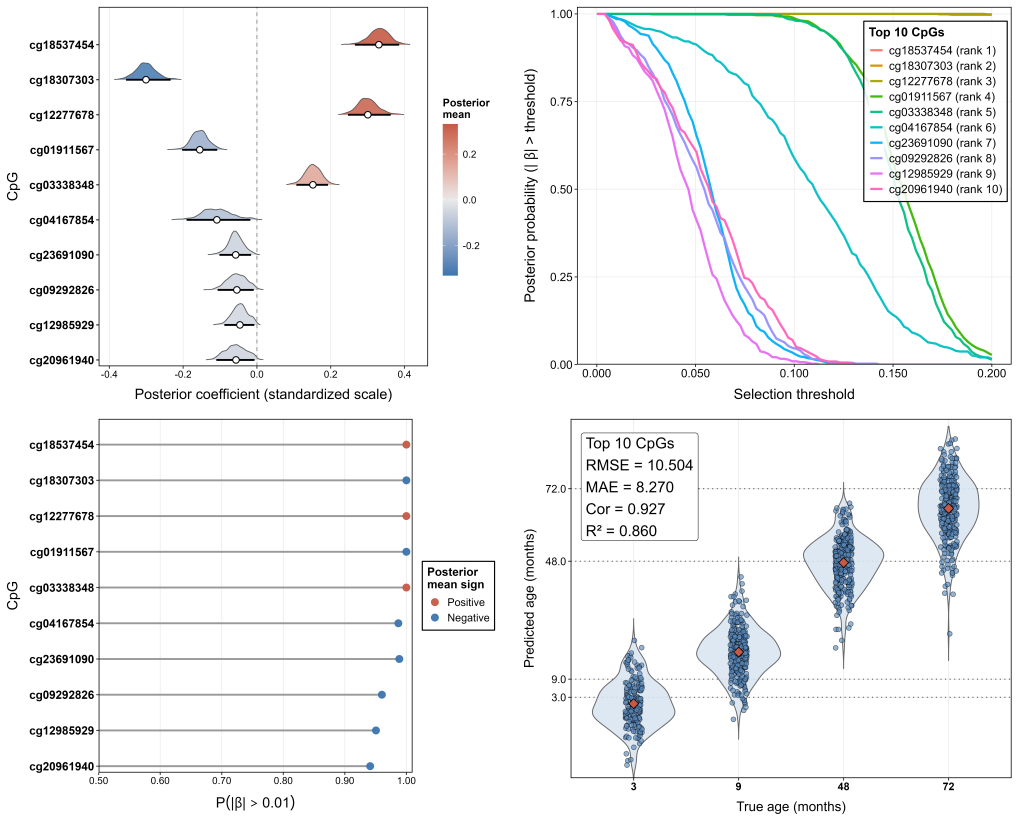
BUGS embeds univariate guidance within the nonlinear variance structure of a regularized horseshoe prior, inducing adaptive shrinkage that enhances signal-noise separation. The framework establishes prior concentration, posterior contraction, and guidance-induced shrinkage separation. BUGS-Active, an active-set MCMC approximation, reduces per-iteration complexity from O(p) to O(|A_n|) while preserving sure screening and contraction.
What carries the argument
Continuous modulation of local shrinkage variance parameters by univariate marginal associations, placed inside the regularized horseshoe prior.
If this is right
- Prior concentration around sparse vectors and posterior contraction at the minimax rate continue to hold under the guided prior.
- Guidance-induced shrinkage separation improves recovery of true signals while tightening control of false discoveries.
- BUGS-Active preserves sure screening and contraction rates at O(|A_n|) per-iteration cost, enabling scaling to p=1,000,000.
- Performance remains robust when the supplied univariate guidance carries little or no information about the true signals.
Where Pith is reading between the lines
- Marginal screening statistics can be fused directly into the prior rather than applied only as a pre-filter.
- The same continuous-modulation idea may transfer to other global-local shrinkage families beyond the horseshoe.
- In genomic applications the resulting sparse models may yield more interpretable selections because marginal relevance is explicitly respected.
Load-bearing premise
The continuous modulation of local shrinkage variance by univariate marginal associations produces the claimed separation and contraction even when the marginal information is noisy or only partially correlated with the true signals, and the active-set restriction does not materially alter the posterior geometry.
What would settle it
A simulation study in which marginal associations are generated independently of the true nonzero coefficients, testing whether posterior contraction at the claimed rate still occurs and whether BUGS-Active continues to recover the correct support.
Figures




read the original abstract
We propose Bayesian Univariate-Guided Sparse Regression (BUGS), a novel global-local shrinkage framework that incorporates marginal association information directly into the prior through a continuous modulation of shrinkage. Unlike existing approaches that treat predictors symmetrically or rely on post hoc screening, BUGS embeds univariate guidance within the nonlinear variance structure of a regularized horseshoe prior, inducing adaptive shrinkage that enhances signal-noise separation. We establish theoretical guarantees including prior concentration, posterior contraction, and guidance-induced shrinkage separation, while demonstrating robustness under uninformative guidance. To enable scalability in ultra-high dimensions, we develop BUGS-Active, an active-set MCMC approximation that restricts local updates to a data-adaptive subset A_n, reducing per-iteration complexity from O(p) to O(|A_n|) while preserving key theoretical properties such as sure screening and contraction. Empirically, the proposed framework achieves strong signal recovery together with substantially improved control of false discovery rates relative to existing methods. BUGS-Active scales to dimensions up to p = 1,000,000, and is applied to a DNA methylation study with n=1051 subjects and approximately 850,000 CpG sites, yielding accurate prediction and interpretable sparse selection. These results establish marginally guided shrinkage as a powerful and scalable paradigm for high-dimensional Bayesian inference.
Editorial analysis
A structured set of objections, weighed in public.
Circularity Check
Minor circularity in presenting 'guidance-induced shrinkage separation' as derived result
specific steps
-
self definitional
[Abstract]
"BUGS embeds univariate guidance within the nonlinear variance structure of a regularized horseshoe prior, inducing adaptive shrinkage that enhances signal-noise separation. We establish theoretical guarantees including prior concentration, posterior contraction, and guidance-induced shrinkage separation"
The separation is asserted as a theoretical guarantee, yet it is produced by construction when the univariate marginal associations (the 'guidance') are inserted into the local shrinkage variances. No additional derivation step is required beyond the prior definition.
full rationale
The core construction modulates the horseshoe prior variance directly with univariate marginal associations computed from the same data. The abstract and theoretical claims then list 'guidance-induced shrinkage separation' among the established guarantees. This separation follows immediately from the prior definition once the marginals are plugged in, rather than emerging as an independent consequence. Standard posterior contraction arguments remain non-circular, but the separation claim reduces to the model specification itself. No load-bearing self-citation chain or fitted-parameter renaming is evident from the provided text.
Axiom & Free-Parameter Ledger
free parameters (1)
- local shrinkage modulation parameters
axioms (1)
- standard math Standard results on posterior contraction for global-local shrinkage priors hold under the modulated variance structure
Reference graph
Works this paper leans on
-
[1]
, " * write output.state after.block = add.period write newline
ENTRY address author booktitle chapter edition editor howpublished institution journal key month note number organization pages publisher school series title type url volume year label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block FUNCTION init.state.consts #0 'before.all := #1 'mid.sentence := ...
-
[2]
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
-
[3]
The horseshoe+ estimator of ultra-sparse signals
Bhadra et al. The horseshoe+ estimator of ultra-sparse signals. Bayesian Analysis, 12 0 (4): 0 1105--1131, 2017
work page 2017
-
[4]
A. Bhattacharya, A. Chakraborty, and B. Mallick. Fast sampling with gaussian scale mixture priors in high-dimensional regression. Biometrika, 103 0 (4): 0 985--991, 2016. doi:10.1093/biomet/asw042
-
[5]
Dirichlet--laplace priors for optimal shrinkage
Bhattacharya et al. Dirichlet--laplace priors for optimal shrinkage. Journal of the American Statistical Association, 110 0 (512): 0 1479--1490, 2015
work page 2015
-
[6]
Global patterns of 16s rrna diversity at a depth of millions of sequences per sample
Caporaso et al. Global patterns of 16s rrna diversity at a depth of millions of sequences per sample. Proc. Natl. Acad. Sci., 108 0 (1): 0 4516--4522, 2011. doi:10.1073/pnas.1000080107
-
[7]
C. Carvalho, N. Polson, and J. Scott. The horseshoe estimator for sparse signals. Biometrika, 97 0 (2): 0 465--480, 2010
work page 2010
-
[8]
S. Chatterjee, T. Hastie, and R. Tibshirani. Univariate-guided sparse regression. Harvard Data Science Review, 7 0 (3), 2025
work page 2025
-
[9]
B. Efron. Large-Scale Inference: Empirical Bayes Methods for Estimation, Testing, and Prediction. Cambridge University Press, Cambridge, 2010
work page 2010
- [10]
-
[11]
Regularization paths for generalized linear models via coordinate descent
Jerome Friedman, Trevor Hastie, and Robert Tibshirani. Regularization paths for generalized linear models via coordinate descent. Journal of Statistical Software, 33 0 (1): 0 1--22, 2010
work page 2010
-
[12]
S. Ghosal, J.K. Ghosh, and A. van der Vaart. Convergence rates of posterior distributions. The Annals of Statistics, 28 0 (2): 0 500--531, 2000. doi:10.1214/aos/1016218228
-
[13]
J. Johndrow, P. Orenstein, and A. Bhattacharya. Scalable approximate mcmc algorithms for the horseshoe prior. Journal of Machine Learning Research, 21 0 (73): 0 1--61, 2020
work page 2020
-
[14]
M. Kang and K. Lee. Mhorseshoe: Approximate Algorithm for Horseshoe Prior, 2025. R package version 0.1.5
work page 2025
-
[15]
Longitudinal prediction of dna methylation to forecast epigenetic outcomes
Leroy et al. Longitudinal prediction of dna methylation to forecast epigenetic outcomes. eBioMedicine, 115: 0 105709, 2025
work page 2025
-
[16]
Microbiome, metagenomics, and high-dimensional compositional data analysis
Hongzhe Li. Microbiome, metagenomics, and high-dimensional compositional data analysis. Annual Review of Statistics and Its Application, 2: 0 73--94, 2015. doi:10.1146/annurev-statistics-010814-020351
-
[17]
Enes Makalic and Daniel F. Schmidt. BayesReg: Flexible Bayesian Penalized Regression Modelling . https://www.mathworks.com/matlabcentral/fileexchange/60823-flexible-bayesian-penalized-regression-modelling, 2020
work page 2020
-
[18]
R. Neal. Slice sampling. Annals of Statistics, 31 0 (3): 0 705--767, 2003
work page 2003
-
[19]
T. Park and G. Casella. The bayesian lasso. Journal of the American Statistical Association, 103 0 (482): 0 681--686, 2008. doi:10.1198/016214508000000337
-
[20]
Sparsity information and regularization in the horseshoe and other shrinkage priors
Juho Piironen and Aki Vehtari. Sparsity information and regularization in the horseshoe and other shrinkage priors. Electronic Journal of Statistics, 11 0 (2): 0 5018--5051, 2017
work page 2017
-
[21]
N. Polson and J. Scott. Shrink globally, act locally: Sparse bayesian regularization and prediction. In J. M. Bernardo, M. J. Bayarri, J. O. Berger, A. P. Dawid, D. Heckerman, A. F. M. Smith, and M. West, editors, Bayesian Statistics 9, pages 501--538. Oxford University Press, 2011
work page 2011
-
[22]
H. Robbins. An empirical bayes approach to statistics. Proceedings of the Third Berkeley Symposium on Mathematical Statistics and Probability, 1: 0 157--163, 1956
work page 1956
-
[23]
V. Rockova and E. George. The spike-and-slab LASSO . Journal of the American Statistical Association, 113 0 (521): 0 431--444, 2018. doi:10.1080/01621459.2016.1260469
-
[24]
Next-generation sequencing technologies for environmental dna research
Shokralla et al. Next-generation sequencing technologies for environmental dna research. Molecular Ecology, 21 0 (8): 0 1794--1805, 2012. doi:10.1111/j.1365-294X.2012.05538.x
-
[25]
R. Tibshirani. Regression shrinkage and selection via the L asso. Journal of the Royal Statistical Society: Series B, 58 0 (1): 0 267--288, 1996
work page 1996
-
[26]
S. van der Pas, B. Kleijn, and A. van der Vaart. The horseshoe estimator: Posterior concentration around nearly black vectors. Electronic Journal of Statistics, 8 0 (2): 0 2585--2618, 2014
work page 2014
-
[27]
S. van der Pas, B. Szab \'o , and A. van der Vaart. Adaptive posterior contraction rates for the horseshoe. Electronic Journal of Statistics, 11 0 (2): 0 3196--3225, 2017
work page 2017
-
[28]
Bayesian regression using a prior on the model fit: The R2-D2 shrinkage prior
Zhang et al. Bayesian regression using a prior on the model fit: The R2-D2 shrinkage prior. Journal of the American Statistical Association, 117 0 (538): 0 862--874, 2022
work page 2022
-
[29]
H. Zou. The adaptive lasso and its oracle properties. Journal of the American Statistical Association, 101 0 (476): 0 1418--1429, 2006. doi:10.1198/016214506000000735
-
[30]
Journal of the Royal Statistical Society Series B: Statistical Methodology , author =
H. Zou and T. Hastie. Regularization and variable selection via the elastic net. Journal of the Royal Statistical Society: Series B, 67 0 (2): 0 301--320, 2005. doi:10.1111/j.1467-9868.2005.00503.x
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.