Recognition: no theorem link
Just Pass Twice: Efficient Token Classification with LLMs for Zero-Shot NER
Pith reviewed 2026-05-10 19:10 UTC · model grok-4.3
The pith
Concatenating the input sentence to itself gives causal LLMs full context for zero-shot named entity recognition.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
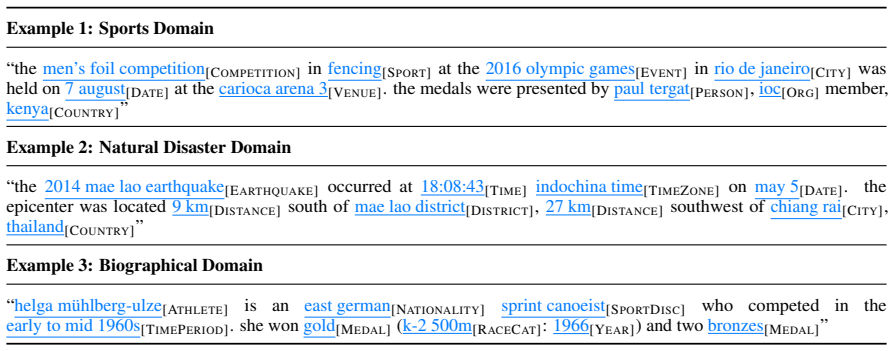
The central discovery is that concatenating an input sentence to itself within a single forward pass allows each token in the second instance to attend to the complete original sentence through causal attention. This provides bidirectional context for token-level classification without modifying the model architecture. When paired with entity type embeddings constructed from natural language definitions, the resulting representations support accurate zero-shot generalization to unseen domains and entity types.
What carries the argument
The Just Pass Twice concatenation, which duplicates the input sequence so that the second copy receives full preceding context from the first copy.
If this is right
- Delivers state-of-the-art performance on zero-shot NER tasks across multiple benchmarks.
- Outperforms prior methods by an average of 7.9 F1 points on CrossNER and MIT datasets.
- Runs over 20 times faster than generative LLM approaches for the same task.
- Reduces issues like hallucinated entities and output formatting errors common in generative methods.
Where Pith is reading between the lines
- This approach could extend to other sequence labeling tasks such as part-of-speech tagging where future context aids disambiguation.
- Combining it with lightweight fine-tuning on definitions might further improve domain adaptation without full retraining.
- Testing on very long documents would reveal if the doubled length causes attention dilution or context window issues.
Load-bearing premise
That simply concatenating the input sentence to itself lets tokens in the second pass reliably use future context for accurate classification without introducing artifacts, and that definition-guided entity embeddings suffice for flexible zero-shot generalization across domains.
What would settle it
Testing the method on a collection of sentences where correct entity labels depend on words appearing after the entity, and finding no accuracy gain over single-pass baselines or inconsistent labels between the two copies, would show the claim does not hold.
Figures







read the original abstract
Large language models encode extensive world knowledge valuable for zero-shot named entity recognition. However, their causal attention mechanism, where tokens attend only to preceding context, prevents effective token classification when disambiguation requires future context. Existing approaches use LLMs generatively, prompting them to list entities or produce structured outputs, but suffer from slow autoregressive decoding, hallucinated entities, and formatting errors. We propose Just Pass Twice (JPT), a simple yet effective method that enables causal LLMs to perform discriminative token classification with full bidirectional context. Our key insight is that concatenating the input to itself lets each token in the second pass attend to the complete sentence, requiring no architectural modifications. We combine these representations with definition-guided entity embeddings for flexible zero-shot generalization. Our approach achieves state-of-the-art results on zero-shot NER benchmarks, surpassing the previous best method by +7.9 F1 on average across CrossNER and MIT benchmarks, being over 20x faster than comparable generative methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Just Pass Twice (JPT), a method for zero-shot NER with causal LLMs. By concatenating each input sentence to itself, tokens in the second pass can attend to the full original sentence as context without architectural changes. These representations are combined with definition-guided entity embeddings for flexible zero-shot generalization. The approach is reported to achieve SOTA results, surpassing the prior best method by +7.9 F1 on average across CrossNER and MIT benchmarks while being over 20x faster than generative LLM baselines.
Significance. If the empirical gains hold under rigorous verification, JPT offers a lightweight way to repurpose causal LLMs for discriminative token-level tasks, avoiding the latency and hallucination issues of generative decoding. The reported speed-up and simplicity are practical strengths; the paper supplies benchmark results on standard zero-shot NER suites.
major comments (1)
- [§3] §3 (Method, S+S construction): The central claim that second-pass tokens obtain 'full bidirectional context' is load-bearing for the novelty and the +7.9 F1 result. Because attention remains strictly causal, hidden states for positions 1..L in the first copy contain only left-of-position information; a token at L+k attending to position j < L therefore receives a key/value that has never seen tokens after j. The manuscript must either (a) derive why this partial prefix still supplies the future-context disambiguation needed for NER or (b) supply an ablation (e.g., comparing against a true bidirectional encoder or against a non-duplicated causal baseline) that isolates the contribution of the duplicated prefix. Without this, the mechanism's sufficiency for the reported gains remains unverified.
minor comments (3)
- [Table 1, §4.2] Table 1 and §4.2: report per-benchmark F1 scores, standard deviations across runs, and the exact identity of the 'previous best method' that is surpassed by +7.9. Include statistical significance tests.
- [§4.3] §4.3 (Ablations): add a control that removes the definition-guided embeddings to quantify their isolated contribution versus the S+S construction alone.
- [Figure 2] Figure 2 (attention visualization): clarify whether the plotted attention heads are from the first or second pass and whether position embeddings are shared or reset at the concatenation point.
Simulated Author's Rebuttal
We thank the referee for their thorough review and for identifying this key subtlety in the S+S construction. We address the comment below and commit to revisions that clarify the mechanism and strengthen the empirical support.
read point-by-point responses
-
Referee: §3 (Method, S+S construction): The central claim that second-pass tokens obtain 'full bidirectional context' is load-bearing for the novelty and the +7.9 F1 result. Because attention remains strictly causal, hidden states for positions 1..L in the first copy contain only left-of-position information; a token at L+k attending to position j < L therefore receives a key/value that has never seen tokens after j. The manuscript must either (a) derive why this partial prefix still supplies the future-context disambiguation needed for NER or (b) supply an ablation (e.g., comparing against a true bidirectional encoder or against a non-duplicated causal baseline) that isolates the contribution of the duplicated prefix. Without this, the mechanism's sufficiency for the reported gains remains unverified.
Authors: We appreciate the referee's precise analysis of the causal attention constraints. We agree that the first-pass hidden states encode only left-of-position information, so second-pass tokens do not receive true future context from the first copy; the method does not achieve full bidirectionality equivalent to a bidirectional encoder. Instead, duplication supplies each second-pass token with the full sentence as prior context (causally encoded) plus its own left context within the second pass. This enables discriminative classification on unmodified causal LLMs. While we lack a formal derivation proving sufficiency for every NER disambiguation case, the observed +7.9 F1 gains over single-pass and generative baselines indicate practical effectiveness. In the revision we will (a) update §3 to describe the context as 'enhanced sentence-level context via duplication under causal constraints' rather than 'full bidirectional context' and (b) add an ablation comparing JPT to a non-duplicated causal baseline to isolate the duplicated prefix's contribution. revision: yes
Circularity Check
No significant circularity; empirical method without load-bearing derivations
full rationale
The paper presents an empirical technique (input concatenation for second-pass token classification) whose central claims are validated by benchmark results rather than any closed mathematical derivation. No equations, fitted parameters, or self-citation chains are used to derive the performance claims; the method is described as a simple insight requiring no architectural changes, and results are reported as experimental outcomes on CrossNER and MIT datasets. This is self-contained against external benchmarks with no reduction of predictions to inputs by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Causal LLMs can use a duplicated input sequence to give each token access to the full original sentence without introducing harmful artifacts.
- domain assumption Definition-guided entity embeddings enable reliable zero-shot generalization across different entity type sets.
Reference graph
Works this paper leans on
-
[1]
DeBERTa: Decoding-enhanced BERT with Disentangled Attention
NuNER: Entity recognition encoder pre- training via LLM-annotated data. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 11829–11841, Miami, Florida, USA. Association for Computational Linguistics. Zifeng Cheng, Zhaoling Chen, Zhiwei Jiang, Yafeng Yin, Cong Wang, Shiping Ge, and Qing Gu. 2025. Multi-prompting...
work page internal anchor Pith review arXiv 2024
-
[2]
Recent advances in named entity recogni- tion: A comprehensive survey and comparative study. Preprint, arXiv:2401.10825. Bo Li, Gexiang Fang, Yang Yang, Quansen Wang, Wei Ye, Wen Zhao, and Shikun Zhang. 2023. Evaluating chatgpt’s information extraction capabilities: An as- sessment of performance, explainability, calibration, and faithfulness.Preprint, ar...
-
[3]
agent,” “place
TELEClass: Taxonomy enrichment and llm- enhanced hierarchical text classification with mini- mal supervision. InWWW. GitHub repository. Wenxuan Zhou, Sheng Zhang, Yu Gu, Muhao Chen, and Hoifung Poon. 2024. UniversalNER: Targeted distil- lation from large language models for open named entity recognition. InThe Twelfth International Con- ference on Learnin...
2024
-
[4]
Athlete,
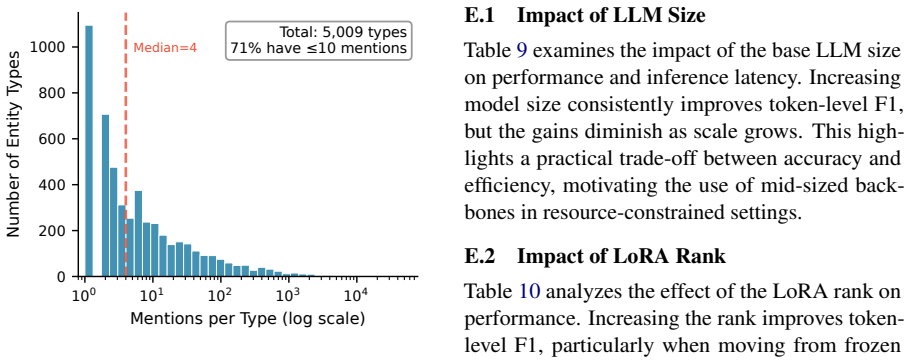
Type Generation: Given a passage and its topic hierarchy, the model proposes domain- appropriate entity types with definitions (e.g., “Athlete,” “Team,” “Stadium” for sports arti- cles). Statistic Value Total sentences 17,489 Total tokens 3,391,899 Total entity mentions 374,705 Unique entity types 5,009 Avg. sentence length 194.9 tokens Entity/non-entity ...
-
[5]
For quality validation, Claude Opus 4.5 assesses random samples across entity type appropriateness, definition actionability, and extraction accuracy
Entity Detection: The model identifies entity spans in the text, followed by a gap-detection pass to catch missed mentions. For quality validation, Claude Opus 4.5 assesses random samples across entity type appropriateness, definition actionability, and extraction accuracy. The resulting dataset comprises17,489training examples with5,009entity types and2,...
-
[6]
Specify inclusions and exclusions: What counts and what doesn’t
-
[7]
Provide concrete examples: Representative instances of the type
-
[8]
A geographical place
Address ambiguities: Clarify edge cases (e.g., does “nearby” count as location?) E Additional Ablations This section presents additional ablation stud- ies that analyze the effect of model scale and parameter-efficient adaptation onJPTperformance. These experiments help characterize the trade-offs between accuracy, model capacity, and inference efficiency...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.