Recognition: no theorem link
MIRAGE: Benchmarking and Aligning Multi-Instance Image Editing
Pith reviewed 2026-05-10 19:33 UTC · model grok-4.3
The pith
MIRAGE enables precise instance-level edits in scenes with multiple similar objects by parsing instructions regionally and applying targeted parallel denoising.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that decomposing composite instructions into regional subsets with a vision-language model, then executing multi-branch parallel denoising that injects target latents while maintaining a reference trajectory for background integrity, produces accurate instance-specific modifications and outperforms existing approaches on dedicated multi-instance benchmarks.
What carries the argument
The MIRAGE framework, which uses a vision-language model to parse instructions into regional subsets and a multi-branch parallel denoising strategy with a reference trajectory to inject target latents selectively.
If this is right
- Existing diffusion-based editors can handle repeated objects without extra training or manual masks.
- Background elements remain stable even when multiple foreground instances receive independent modifications.
- Composite instructions with several similar targets become reliably executable.
- Standardized benchmarks now exist to compare fine-grained consistency across methods.
Where Pith is reading between the lines
- The same regional parsing plus reference-trajectory approach could be tested on video sequences where multiple objects must be edited across frames.
- Design software could adopt this branching pattern so users can change one item in a group without selecting masks manually.
- Fine-tuning future models on the new benchmarks might reduce the need for the training-free workaround.
Load-bearing premise
The vision-language model correctly divides complex multi-instance instructions into the right regional subsets without misassigning which object receives which edit.
What would settle it
Apply MIRAGE to a new set of images containing several nearly identical objects and instructions that demand distinct changes to each; check whether only the instructed objects are altered while all other instances and the background stay unchanged.
Figures

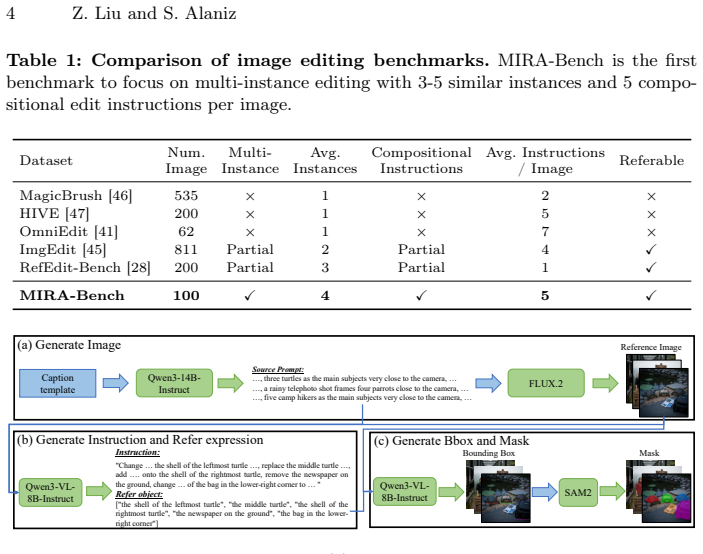




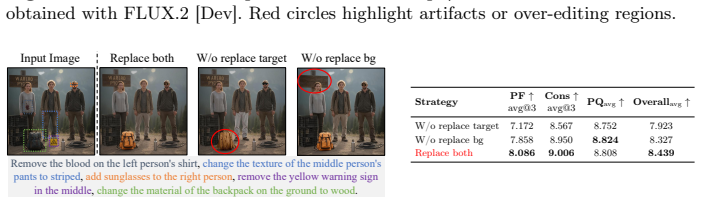

read the original abstract
Instruction-guided image editing has seen remarkable progress with models like FLUX.2 and Qwen-Image-Edit, yet they still struggle with complex scenarios with multiple similar instances each requiring individual edits. We observe that state-of-the-art models suffer from severe over-editing and spatial misalignment when faced with multiple identical instances and composite instructions. To this end, we introduce a comprehensive benchmark specifically designed to evaluate fine-grained consistency in multi-instance and multi-instruction settings. To address the failures of existing methods observed in our benchmark, we propose Multi-Instance Regional Alignment via Guided Editing (MIRAGE), a training-free framework that enables precise, localized editing. By leveraging a vision-language model to parse complex instructions into regional subsets, MIRAGE employs a multi-branch parallel denoising strategy. This approach injects latent representations of target regions into the global representation space while maintaining background integrity through a reference trajectory. Extensive evaluations on MIRA-Bench and RefEdit-Bench demonstrate that our framework significantly outperforms existing methods in achieving precise instance-level modifications while preserving background consistency. Our benchmark and code are available at https://github.com/ZiqianLiu666/MIRAGE.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MIRA-Bench, a new benchmark for evaluating fine-grained consistency in multi-instance and multi-instruction image editing scenarios, and proposes MIRAGE, a training-free framework. MIRAGE uses a vision-language model to parse composite instructions into regional subsets, then applies multi-branch parallel denoising to inject target latents while using a reference trajectory to preserve background integrity. The central claim is that MIRAGE significantly outperforms existing methods like FLUX.2 and Qwen-Image-Edit on MIRA-Bench and RefEdit-Bench in achieving precise instance-level edits without over-editing or spatial misalignment.
Significance. If the results and ablations hold, the work would be significant for the computer vision community by filling a gap in handling multi-instance editing with identical objects, a known failure mode of current diffusion-based editors. The provision of a dedicated benchmark and open code would enable reproducible progress on localized, instruction-guided editing.
major comments (2)
- [Abstract and Method] Abstract and Method section: The framework's success hinges on the VLM reliably decomposing composite instructions into correct per-instance regional masks, especially for visually identical instances, yet no quantitative parsing accuracy metrics, confusion matrices, or oracle-parsing ablations are reported on MIRA-Bench subsets. Without these, it is impossible to determine whether the claimed outperformance stems from the multi-branch denoising and reference trajectory or from reliable upstream parsing.
- [Experiments] Experiments section: The headline claim of significant outperformance on MIRA-Bench and RefEdit-Bench in precise instance-level modifications and background consistency lacks reported quantitative numbers, error bars, statistical significance tests, or detailed failure-case analysis on the hardest subsets (e.g., identical instances with ambiguous spatial references). This omission is load-bearing for validating that the reference trajectory successfully avoids new artifacts.
minor comments (2)
- [Method] The manuscript would benefit from an explicit diagram or pseudocode clarifying the multi-branch parallel denoising process and how target latents are injected into the global representation space.
- [Experiments] Ensure all baseline implementations (e.g., FLUX.2, Qwen-Image-Edit) are described with exact prompting and inference settings used for fair comparison.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments, which help clarify how to strengthen the presentation of our contributions. We address each major comment below and commit to revisions that improve the rigor and transparency of the work.
read point-by-point responses
-
Referee: [Abstract and Method] Abstract and Method section: The framework's success hinges on the VLM reliably decomposing composite instructions into correct per-instance regional masks, especially for visually identical instances, yet no quantitative parsing accuracy metrics, confusion matrices, or oracle-parsing ablations are reported on MIRA-Bench subsets. Without these, it is impossible to determine whether the claimed outperformance stems from the multi-branch denoising and reference trajectory or from reliable upstream parsing.
Authors: We agree this is a valid point and that quantitative isolation of the parsing component would strengthen the analysis. While our end-to-end results on MIRA-Bench and RefEdit-Bench demonstrate the full framework's effectiveness, we will add in the revised manuscript: parsing accuracy metrics and confusion matrices evaluated on MIRA-Bench subsets (including identical-instance cases), plus an oracle-parsing ablation that supplies ground-truth regional masks to the multi-branch denoising stage. This will directly show the independent contribution of the denoising and reference trajectory. revision: yes
-
Referee: [Experiments] Experiments section: The headline claim of significant outperformance on MIRA-Bench and RefEdit-Bench in precise instance-level modifications and background consistency lacks reported quantitative numbers, error bars, statistical significance tests, or detailed failure-case analysis on the hardest subsets (e.g., identical instances with ambiguous spatial references). This omission is load-bearing for validating that the reference trajectory successfully avoids new artifacts.
Authors: Quantitative comparisons are already present in the Experiments section via tables on both benchmarks. However, we acknowledge that error bars, statistical tests, and focused failure analysis on the hardest subsets would provide stronger validation. In the revision we will add: error bars computed over multiple runs, paired statistical significance tests, and a dedicated failure-case subsection with quantitative breakdowns and examples specifically for identical instances and ambiguous spatial references, illustrating the reference trajectory's role in artifact reduction. revision: yes
Circularity Check
No circularity: training-free composition of external VLM and diffusion components with independent benchmark validation.
full rationale
The paper describes MIRAGE as a training-free method that parses instructions via an off-the-shelf vision-language model and applies multi-branch parallel denoising plus reference trajectories within existing diffusion pipelines. No equations, fitted parameters, self-citations, or ansatzes are presented as load-bearing for the core claims. The benchmark results on MIRA-Bench and RefEdit-Bench are reported as external evaluations rather than derived quantities. The derivation chain therefore remains self-contained against external components and does not reduce to its own inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Agrawal, P., et al.: Pixtral 12b. arXiv preprint arXiv:2410.07073 (2024)
work page internal anchor Pith review arXiv 2024
-
[2]
Bai, S., Cai, Y., Chen, R., Chen, K., Chen, X., Cheng, Z., Deng, L., Ding, W., Gao, C., Ge, C., et al.: Qwen3-vl technical report. arXiv preprint arXiv:2511.21631 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
FLUX.1 Kontext: Flow Matching for In-Context Image Generation and Editing in Latent Space
Batifol, S., Blattmann, A., Boesel, F., Consul, S., Diagne, C., Dockhorn, T., En- glish, J., English, Z., Esser, P., et al.: Flux. 1 kontext: Flow matching for in-context image generation and editing in latent space. arXiv preprint arXiv:2506.15742 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Black Forest Labs: FLUX.2: Analyzing and enhancing the latent space of FLUX – representation comparison (2025),https://bfl.ai/research/representation- comparison
2025
-
[5]
Bradbury, R., Zhong, D.: Your latent mask is wrong: Pixel-equivalent latent com- positing for diffusion models. arXiv preprint arXiv:2512.05198 (2025)
-
[6]
In: CVPR (2023)
Brooks, T., Holynski, A., Efros, A.A.: Instructpix2pix: Learning to follow image editing instructions. In: CVPR (2023)
2023
-
[7]
Chen, J., Zhang, Y., Qian, X., Li, Z., Fermuller, C., Chen, C., Aloimonos, Y.: From inpainting to layer decomposition: Repurposing generative inpainting models for image layer decomposition. arXiv preprint arXiv:2511.20996 (2025)
-
[8]
In: ICLR (2023)
Couairon, G., Verbeek, J., Schwenk, H., Cord, M.: Diffedit: Diffusion-based seman- tic image editing with mask guidance. In: ICLR (2023)
2023
-
[9]
In: AAAI (2025)
Feng, K., Ma, Y., Wang, B., Qi, C., Chen, H., Chen, Q., Wang, Z.: Dit4edit: Diffusion transformer for image editing. In: AAAI (2025)
2025
-
[10]
In: CVPR (2024)
Guo, Q., Lin, T.: Focus on your instruction: Fine-grained and multi-instruction image editing by attention modulation. In: CVPR (2024)
2024
-
[11]
In: ICLR (2023)
Hertz, A., Mokady, R., Tenenbaum, J., Aberman, K., Pritch, Y., Cohen-Or, D.: Prompt-to-prompt image editing with cross-attention control. In: ICLR (2023)
2023
-
[12]
In: NeurIPS (2020)
Ho, J., Jain, A., Abbeel, P.: Denoising diffusion probabilistic models. In: NeurIPS (2020)
2020
-
[13]
Cogvlm2: Visual language models for image and video un- derstanding
Hong, W., Wang, W., Ding, M., Yu, W., Lv, Q., Wang, Y., Cheng, Y., Huang, S., Ji, J., Xue, Z., et al.: Cogvlm2: Visual language models for image and video understanding. arXiv preprint arXiv:2408.16500 (2024)
-
[14]
IEEE TCSVT (2025)
Huang, T., Cao, P., Yang, L., Liu, C., Hu, M., Liu, Z., Song, Q.: E4c: Enhance editability for text-based image editing by harnessing efficient CLIP guidance. IEEE TCSVT (2025)
2025
-
[15]
In: ICCV (2025)
Kim, J., Lee, Z., Cho, D., Jo, S., Jung, Y., Kim, K., Yang, E.: Early timestep zero- shot candidate selection for instruction-guided image editing. In: ICCV (2025)
2025
-
[16]
In: ECCV (2024)
Koo, G., Yoon, S., Hong, J.W., Yoo, C.D.: FlexiEdit: Frequency-aware latent re- finement for enhanced non-rigid editing. In: ECCV (2024)
2024
-
[17]
In: ACL (2024)
Ku, M., Jiang, D., Wei, C., Yue, X., Chen, W.: Viescore: Towards explainable metrics for conditional image synthesis evaluation. In: ACL (2024)
2024
-
[18]
In: CVPR (2024)
Li, S., Zeng, B., Feng, Y., Gao, S., Liu, X., Liu, J., Li, L., Tang, X., Hu, Y., Liu, J., et al.: Zone: Zero-shot instruction-guided local editing. In: CVPR (2024)
2024
-
[19]
In: CVPR (2024) 16 Z
Liu, C., Li, X., Ding, H.: Referring image editing: Object-level image editing via referring expressions. In: CVPR (2024) 16 Z. Liu and S. Alaniz
2024
-
[20]
In: ICLR (2026)
Luo, X., Wang, J., Wu, C., Xiao, S., Jiang, X., Lian, D., Zhang, J., Liu, D., Liu, Z.: Editscore: Unlocking online RL for image editing via high-fidelity reward modeling. In: ICLR (2026)
2026
-
[21]
In: ECCV (2024)
Mirzaei, A., Aumentado-Armstrong, T., Brubaker, M.A., Kelly, J., Levinshtein, A., Derpanis, K.G., Gilitschenski, I.: Watch your steps: Local image and scene editing by text instructions. In: ECCV (2024)
2024
-
[22]
Mistral AI: Mistral large 3 (2025),https://mistral.ai/news/mistral-3
2025
-
[23]
In: CVPR (2023)
Mokady, R., Hertz, A., Aberman, K., Pritch, Y., Cohen-Or, D.: Null-text inversion for editing real images using guided diffusion models. In: CVPR (2023)
2023
-
[24]
In: ECCV (2024)
Nitzan, Y., Wu, Z., Zhang, R., Shechtman, E., Cohen-Or, D., Park, T., Gharbi, M.: Lazy diffusion transformer for interactive image editing. In: ECCV (2024)
2024
-
[25]
OpenAI: The new ChatGPT Images is here (2025),https://openai.com/index/ new-chatgpt-images-is-here/
2025
-
[26]
In: ICCV (2023)
Patashnik, O., Garibi, D., Azuri, I., Averbuch-Elor, H., Cohen-Or, D.: Localizing object-level shape variations with text-to-image diffusion models. In: ICCV (2023)
2023
-
[27]
In: ICCV (2021)
Patashnik, O., Wu, Z., Shechtman, E., Cohen-Or, D., Lischinski, D.: StyleCLIP: Text-driven manipulation of StyleGAN imagery. In: ICCV (2021)
2021
-
[28]
In: ICCV (2025)
Pathiraja, B., Patel, M., Singh, S., Yang, Y., Baral, C.: Refedit: A benchmark and method for improving instruction-based image editing model on referring expres- sions. In: ICCV (2025)
2025
-
[29]
In: ICCV (2023)
Peebles, W., Xie, S.: Scalable diffusion models with transformers. In: ICCV (2023)
2023
-
[30]
In: ICLR (2024)
Podell, D., English, Z., Lacey, K., Blattmann, A., Dockhorn, T., Müller, J., Penna, J., Rombach, R.: SDXL: Improving latent diffusion models for high-resolution im- age synthesis. In: ICLR (2024)
2024
-
[31]
Hierarchical Text-Conditional Image Generation with CLIP Latents
Ramesh, A., Dhariwal, P., Nichol, A., Chu, C., Chen, M.: Hierarchical text- conditional image generation with clip latents. arXiv preprint arXiv:2204.06125 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[32]
In: ICLR (2025)
Ravi, N., Gabeur, V., Hu, Y.T., Hu, R., Ryali, C., Ma, T., Khedr, H., Rädle, R., Rolland, C., Gustafson, L., et al.: SAM 2: Segment anything in images and videos. In: ICLR (2025)
2025
-
[33]
Grounding dino 1.5: Advance the” edge” of open-set object detection
Ren, T., Jiang, Q., Liu, S., Zeng, Z., Liu, W., Gao, H., Huang, H., Ma, Z., Jiang, X., Chen, Y., et al.: Grounding DINO 1.5: Advance the Edge of open-set object detection. arXiv preprint arXiv:2405.10300 (2024)
-
[34]
In: CVPR (2022)
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-resolution image synthesis with latent diffusion models. In: CVPR (2022)
2022
-
[35]
In: ICASSP (2024)
Shagidanov, A., Poghosyan, H., Gong, X., Wang, Z., Navasardyan, S., Shi, H.: Grounded-instruct-pix2pix: Improving instruction based image editing with auto- matic target grounding. In: ICASSP (2024)
2024
-
[36]
In: WACV (2025)
Simsar, E., Tonioni, A., Xian, Y., Hofmann, T., Tombari, F.: LIME: Localized image editing via attention regularization in diffusion models. In: WACV (2025)
2025
-
[37]
In: ICLR (2026)
Sun, W., Chen, H., Du, Y., Zheng, Y., Snoek, C.G.M.: Regionreasoner: Region- grounded multi-round visual reasoning. In: ICLR (2026)
2026
-
[38]
Wang, J., Wu, Z., Huang, D., Zheng, Y., Wang, H.: Unlocking the potential of mllms in referring expression segmentation via a light-weight mask decoder. arXiv preprint arXiv:2508.04107 (2025)
-
[39]
Instructedit: Improving automatic masks for diffusion-based image editing with user instructions
Wang, Q., Zhang, B., Birsak, M., Wonka, P.: Instructedit: Improving automatic masks for diffusion-based image editing with user instructions. arXiv preprint arXiv:2305.18047 (2023)
-
[40]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Wang, W., Gao, Z., Gu, L., Pu, H., Cui, L., Wei, X., Liu, Z., Jing, L., Ye, S., Shao, J., et al.: Internvl3. 5: Advancing open-source multimodal models in versatility, reasoning, and efficiency. arXiv preprint arXiv:2508.18265 (2025) MIRAGE: Benchmarking and Aligning Multi-Instance Image Editing 17
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[41]
In: ICLR (2025)
Wei, C., Xiong, Z., Ren, W., Du, X., Zhang, G., Chen, W.: Omniedit: Building image editing generalist models through specialist supervision. In: ICLR (2025)
2025
-
[42]
Wu, C., Li, J., Zhou, J., Lin, J., Gao, K., Yan, K., Yin, S.m., Bai, S., Xu, X., Chen, Y., et al.: Qwen-image technical report. arXiv preprint arXiv:2508.02324 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[43]
Yang, A., Li, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Gao, C., Huang, C., Lv, C., et al.: Qwen3 technical report. arXiv preprint arXiv:2505.09388 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[44]
In: ICLR (2024)
Yang, Z., Ding, G., Wang, W., Chen, H., Zhuang, B., Shen, C.: Object-aware inversion and reassembly for image editing. In: ICLR (2024)
2024
-
[45]
In: NeurIPS (2025)
Ye, Y., He, X., Li, Z., Lin, B., Yuan, S., Yan, Z., Hou, B., Yuan, L.: Imgedit: A unified image editing dataset and benchmark. In: NeurIPS (2025)
2025
-
[46]
In: NeurIPS (2023)
Zhang, K., Mo, L., Chen, W., Sun, H., Su, Y.: Magicbrush: A manually annotated dataset for instruction-guided image editing. In: NeurIPS (2023)
2023
-
[47]
In: CVPR (2024)
Zhang, S., Yang, X., Feng, Y., Qin, C., Chen, C.C., Yu, N., Chen, Z., Wang, H., Savarese, S., Ermon, S., et al.: Hive: Harnessing human feedback for instructional visual editing. In: CVPR (2024)
2024
-
[48]
Zhang, Z., Xie, J., Lu, Y., Yang, Z., Yang, Y.: Enabling instructional image editing with in-context generation in large scale diffusion transformer. In: NeurIPS (2025) 18 Z. Liu and S. Alaniz MIRAGE: Benchmarking and Aligning Multi-Instance Image Editing - Supplementary Material A Implementation Details of MIRA-Bench Construction In this section we detai...
-
[49]
change the handle to red
A slot plan derived from the source prompt Your task is to generate exactly 5 edit instructions. Output exactly ONE SINGLE-LINE valid JSON object. No markdown. No extra text. CORE REQUIREMENTS AUTHORITATIVEINPUTS - The slot plan is authoritative for: * repeated instance count * repeated object identity * repeated-instance left-to-right assignment - The im...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.