Recognition: no theorem link
Faster Superword Tokenization
Pith reviewed 2026-05-10 18:48 UTC · model grok-4.3
The pith
Supermerge candidates can be counted by frequency like regular pairs to train superword tokenizers over 600 times faster with identical results.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that supermerge candidates can be aggregated by frequency in the same manner as regular pretokens. This aggregation reproduces the exact merge sequence and final vocabulary of the original memory-intensive implementations of BoundlessBPE and SuperBPE. A two-phase formulation first completes all regular merges and then performs supermerge learning, yielding identical results while enabling a dramatic reduction in training time. The same two-phase structure also reveals a near-equivalence to SuperBPE in which the manual hyperparameter of the latter is determined automatically during the second phase.
What carries the argument
Frequency aggregation of supermerge candidates, which treats eligible sequences of consecutive pretokens as countable units to determine merge order without retaining full documents in memory.
Load-bearing premise
That frequency counts of supermerge candidates collected across the full dataset will always reproduce the identical merge sequence and vocabulary as the original algorithm that processes complete documents, including any tie-breaking behavior.
What would settle it
Run both the original memory-intensive implementation and the new frequency-aggregation version on the same input corpus and check whether the final vocabularies and ordered merge lists match exactly; any difference would falsify the claim of identical results.
Figures





read the original abstract
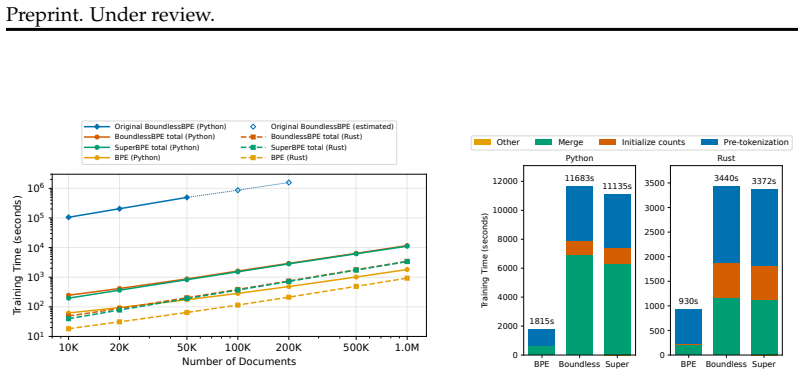
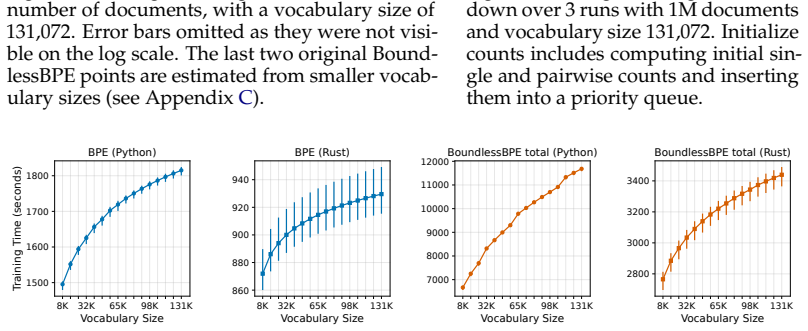
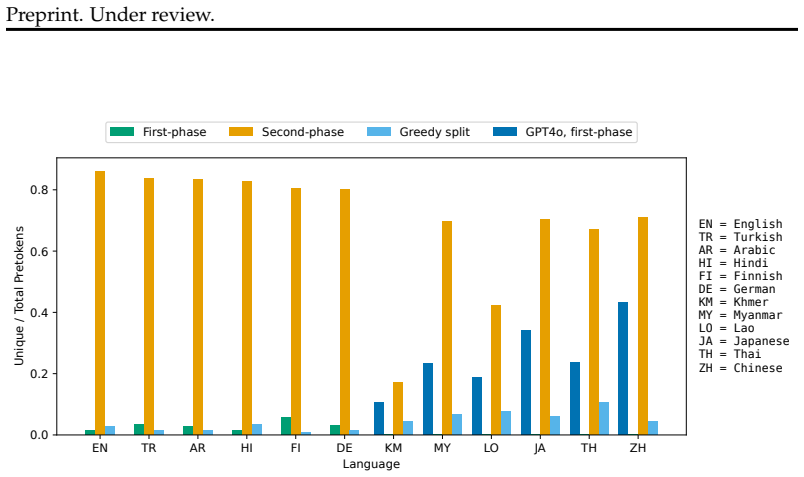
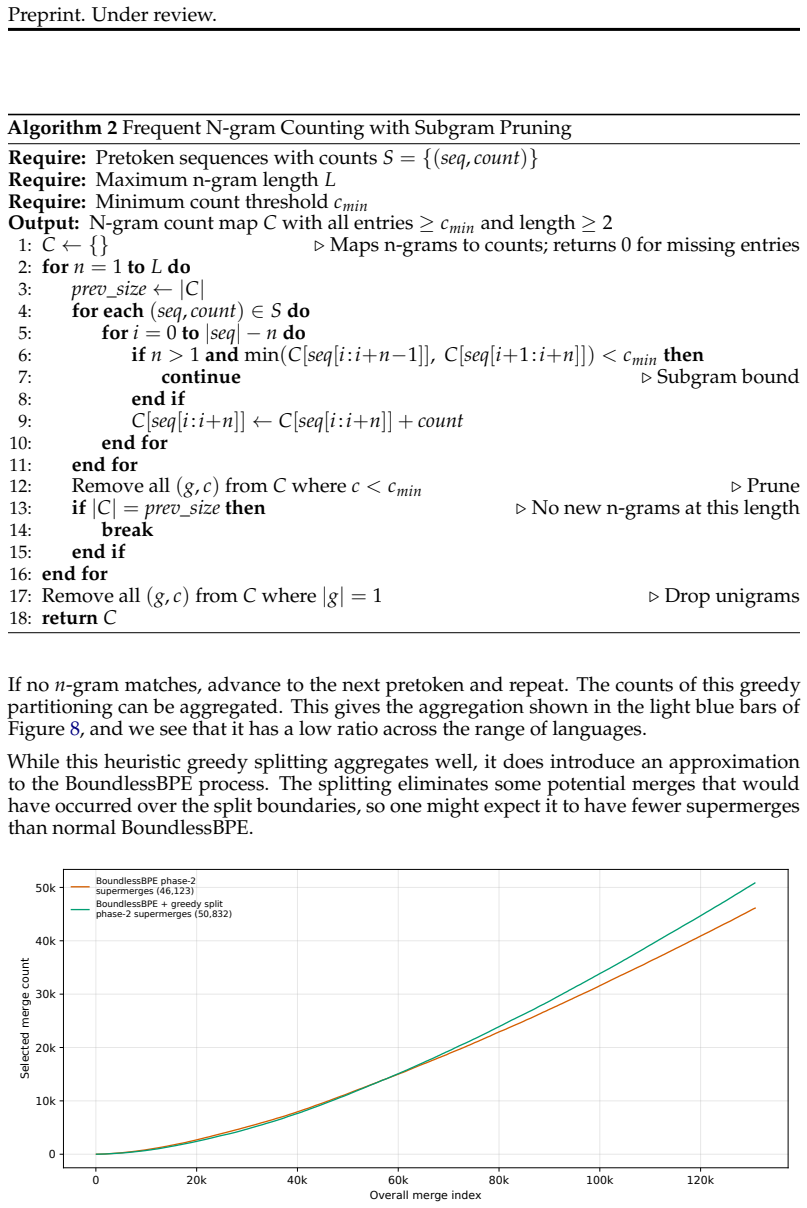
Byte Pair Encoding (BPE) is a widely used tokenization algorithm, whose tokens cannot extend across pre-tokenization boundaries, functionally limiting it to representing at most full words. The BoundlessBPE and SuperBPE algorithms extend and improve BPE by relaxing this limitation and allowing the formation of superwords, which are combinations of pretokens that form phrases. However, previous implementations were impractical to train: for example, BoundlessBPE took 4.7 CPU days to train on 1GB of data. We show that supermerge candidates, two or more consecutive pretokens eligible to form a supermerge, can be aggregated by frequency much like regular pretokens. This avoids keeping full documents in memory, as the original implementations of BoundlessBPE and SuperBPE required, leading to a significant training speedup. We present a two-phase formulation of BoundlessBPE that separates first-phase learning of regular merges from second-phase learning of supermerges, producing identical results to the original implementation. We also show a near-equivalence between two-phase BoundlessBPE and SuperBPE, with the difference being that a manually selected hyperparameter used in SuperBPE can be automatically determined in the second phase of BoundlessBPE. These changes enable a much faster implementation, allowing training on that same 1GB of data in 603 and 593 seconds for BoundlessBPE and SuperBPE, respectively, a more than 600x increase in speed. For each of BoundlessBPE, SuperBPE, and BPE, we open-source both a reference Python implementation and a fast Rust implementation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that supermerge candidates in BoundlessBPE and SuperBPE can be aggregated by global frequency counts (rather than document-by-document processing), enabling a two-phase formulation of BoundlessBPE that separates regular merges from supermerges. This produces identical results to the original memory-intensive implementations while achieving >600x training speedup on 1GB data (603s vs. 4.7 CPU days), with near-equivalence to SuperBPE where a manual hyperparameter becomes automatically determined. Open-source Python and Rust implementations are provided for verification.
Significance. If the equivalence holds, the work renders superword tokenization (extending BPE across pretoken boundaries) practical for realistic dataset sizes, removing a major barrier noted in prior implementations. Strengths include the parameter-free reformulation by construction, reproducible open-sourced code allowing direct verification, and the explicit speedup measurements; these elements support adoption in NLP tokenization pipelines.
major comments (1)
- [Abstract] Abstract and the two-phase BoundlessBPE description: the central claim of 'producing identical results to the original implementation' via frequency aggregation of supermerge candidates is load-bearing, yet the manuscript does not explicitly address tie-breaking. When multiple candidates share the maximum frequency, the original document-scanning order may select differently from pure global counts, potentially altering the merge sequence and final vocabulary; a concrete tie-breaker rule (e.g., lexical or first-seen) must be stated and shown to be consistent in both versions.
minor comments (2)
- [Abstract] Abstract: the statement of 'near-equivalence' between two-phase BoundlessBPE and SuperBPE would benefit from a one-sentence clarification of the exact difference (the automatically determined hyperparameter) to aid readers.
- The manuscript would be strengthened by adding a short table or paragraph comparing merge sequences on a toy corpus under both original and aggregated methods to illustrate equivalence in practice.
Simulated Author's Rebuttal
We thank the referee for the positive recommendation of minor revision and for highlighting the need to explicitly address tie-breaking to support our claim of identical results. We respond to the comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract and the two-phase BoundlessBPE description: the central claim of 'producing identical results to the original implementation' via frequency aggregation of supermerge candidates is load-bearing, yet the manuscript does not explicitly address tie-breaking. When multiple candidates share the maximum frequency, the original document-scanning order may select differently from pure global counts, potentially altering the merge sequence and final vocabulary; a concrete tie-breaker rule (e.g., lexical or first-seen) must be stated and shown to be consistent in both versions.
Authors: We agree that an explicit tie-breaker is required to rigorously substantiate the equivalence claim. The original document-scanning implementation processes documents in a fixed order and selects the first-encountered candidate among ties (implicit first-seen). Our global-frequency formulation uses a deterministic lexical tie-breaker on the string representation of the supermerge candidate (smallest in lexicographic order). We have verified through direct comparison on the same datasets that this rule yields identical merge sequences and vocabularies to the original. We will revise the manuscript to state this tie-breaker explicitly in the two-phase BoundlessBPE description, note its consistency with the original, and reference it briefly in the abstract. revision: yes
Circularity Check
No circularity: two-phase supermerge aggregation is an independent algorithmic reformulation
full rationale
The paper's central contribution is an explicit two-phase reformulation of BoundlessBPE that first learns regular merges then aggregates supermerge-candidate frequencies globally. This is presented as a direct, memory-efficient reimplementation of the original frequency-based merge process, with the claim of identical results resting on the construction of the aggregation step itself rather than any fitted parameter, self-citation chain, or imported uniqueness theorem. No load-bearing premise reduces to a prior result by the same authors; the equivalence is algorithmic and externally verifiable by running both implementations on the same data. The derivation chain therefore remains self-contained against the original BPE/BoundlessBPE specification and does not exhibit any of the enumerated circular patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Frequency counts of consecutive pretokens determine the correct merge order in BPE variants.
Reference graph
Works this paper leans on
-
[1]
Association for Computing Machinery . ISBN 9781450315975. doi: 10.1145/2452376.2452389. URL https://doi.org/10.1145/2452376. 2452389. Pavel Chizhov , Catherine Arnett, Elizaveta Korotkova, and Ivan P . Yamshchikov . BPE gets picky: Efficient vocabulary refinement during tokenizer training. In Yaser Al- Onaizan, Mohit Bansal, and Yun-Nung Chen (eds.), Procee...
-
[2]
Metacognitive Prompting Improves Understanding in Large Language Models
Association for Computational Linguistics. doi: 10.18653/v1/ 2024.emnlp-main.925. URL https://aclanthology.org/2024.emnlp-main.925/. Preston Firestone, Shubham Ugare, Gagandeep Singh, and Sasa Misailovic. UTF-8 plumb- ing: Byte-level tokenizers unavoidably enable LLMs to generate ill-formed UTF-8,
-
[3]
URLhttps://arxiv.org/abs/2511.05578. Philip Gage. A new algorithm for data compression. The C Users Journal , 12(2):23–38,
-
[4]
Yifan Hu, Frank Liang, Dachuan Zhao, Jonathan Geuter, Varshini Reddy , Craig W
URL https://arxiv.org/abs/ 2506.18639. Yifan Hu, Frank Liang, Dachuan Zhao, Jonathan Geuter, Varshini Reddy , Craig W. Schmidt, and Chris Tanner. Entropy-driven pre-tokenization for byte-pair encoding,
-
[5]
Eugene Jang, Kimin Lee, Jin-Woo Chung, Keuntae Park, and Seungwon Shin
URL https://arxiv.org/abs/2506.15889. Eugene Jang, Kimin Lee, Jin-Woo Chung, Keuntae Park, and Seungwon Shin. Improb- able bigrams expose vulnerabilities of incomplete tokens in byte-level tokenizers. In Christos Christodoulopoulos, Tanmoy Chakraborty , Carolyn Rose, and Violet Peng (eds.), Proceedings of the 2025 Conference on Empirical Methods in Natura...
-
[6]
Association for Computational Linguistics. ISBN 979-8-89176-332-6. doi: 10.18653/v1/2025.emnlp-main.919. URL https://aclanthology.org/2025.emnlp-main.919/. 10 Preprint. Under review. Jean Kaddour. The MiniPile challenge for data-efficient language models,
-
[7]
John D Lafferty, Andrew McCallum, and Fernando CN Pereira
URL https: //arxiv.org/abs/2304.08442. Sander Land and Catherine Arnett. BPE stays on SCRIPT: Structured encoding for robust multilingual pretokenization,
-
[8]
Alisa Liu, Jonathan Hayase, Valentin Hofmann, Sewoong Oh, Noah A
URL https://arxiv.org/abs/2505.24689. Alisa Liu, Jonathan Hayase, Valentin Hofmann, Sewoong Oh, Noah A. Smith, and Yejin Choi. SuperBPE: Space travel for language models,
-
[9]
URL https://arxiv.org/abs/ 2503.13423. Thuat Nguyen, Chien Van Nguyen, Viet Dac Lai, Hieu Man, Nghia Trung Ngo, Franck Dernoncourt, Ryan A. Rossi, and Thien Huu Nguyen. CulturaX: A cleaned, enormous, and multilingual dataset for large language models in 167 languages. In Nicoletta Calzo- lari, Min-Yen Kan, V eronique Hoste, Alessandro Lenci, Sakriani Sakt...
-
[10]
URL https://aclanthology.org/2024.lrec-main.377/
ELRA and ICCL. URL https://aclanthology.org/2024.lrec-main.377/. Artidoro Pagnoni, Ramakanth Pasunuru, Pedro Rodriguez, John Nguyen, Benjamin Muller, Margaret Li, Chunting Zhou, Lili Yu, Jason E Weston, Luke Zettlemoyer, Gargi Ghosh, Mike Lewis, Ari Holtzman, and Srini Iyer. Byte latent transformer: Patches scale better than tokens. In Wanxiang Che, Joyce...
2024
-
[11]
Association for Computational Linguistics. ISBN 979-8-89176-251-0. doi: 10.18653/v1/2025.acl-long.453. URL https://aclanthology.org/2025.acl-long.453/. Varshini Reddy , Craig W. Schmidt, Yuval Pinter, and Chris Tanner. How much is enough? the diminishing returns of tokenization training data,
- [12]
-
[13]
Rico Sennrich, Barry Haddow, and Alexandra Birch
URL https://arxiv.org/abs/ 2504.00178. Rico Sennrich, Barry Haddow, and Alexandra Birch. Improving neural machine translation models with monolingual data. In Katrin Erk and Noah A. Smith (eds.), Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pp. 86–96, Berlin, Germany , August
-
[14]
Association for Computational Linguistics. doi: 10.18653/v1/P16-1009. URL https://aclanthology.org/P16-1009/. Vilém Zouhar, Clara Meister, Juan Gastaldi, Li Du, Mrinmaya Sachan, and Ryan Cotterell. Tokenization and the noiseless channel. In Anna Rogers, Jordan Boyd-Graber, and Naoaki Okazaki (eds.), Proceedings of the 61st Annual Meeting of the Associatio...
-
[15]
Association for Computational Linguistics. doi: 10.18653/v1/2023.acl-long.284. URL https://aclanthology.org/2023.acl-long.284/. A Pre-tokenization Regular Expressions We use the modern GPT4O_REGEX of Listing 1 for pre-tokenization, originally introduced for GPT-4o.18 For non-space-delimited languages we use SCRIPT_SPECIFIC_GPT4O_REGEX, a modified version t...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.