Recognition: no theorem link
Decision-Oriented Programming with Aporia
Pith reviewed 2026-05-10 18:47 UTC · model grok-4.3
The pith
Explicit decision tracking in AI-assisted programming keeps programmers engaged and forms more accurate mental models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Decision-oriented programming treats decisions as the primary interface between the programmer and the AI agent. Decisions are made explicit and structured, co-authored through interactive elicitation, and each one is traceable back to the resulting code. Aporia realizes this by maintaining a Decision Bank of persistent, editable decisions; proactively asking programmers design questions; and encoding decisions as executable test suites that validate the implementation. In a user study, this approach increased engagement in the design process, supported exploration and validation, and led to significantly more accurate programmer understanding of the code.
What carries the argument
The Decision Bank, which stores persistent, editable decisions that the agent elicits through questions and encodes as executable test suites linking intent directly to implementation.
Load-bearing premise
The observed gains in engagement and mental model accuracy from the 14-participant study will generalize and stem specifically from explicit decision tracking rather than other differences in the interface or agent behavior.
What would settle it
A controlled follow-up study with a larger group of programmers where a baseline agent asks similar design questions but omits the structured Decision Bank and test encoding, then measures whether mental model accuracy and engagement differences disappear.
Figures


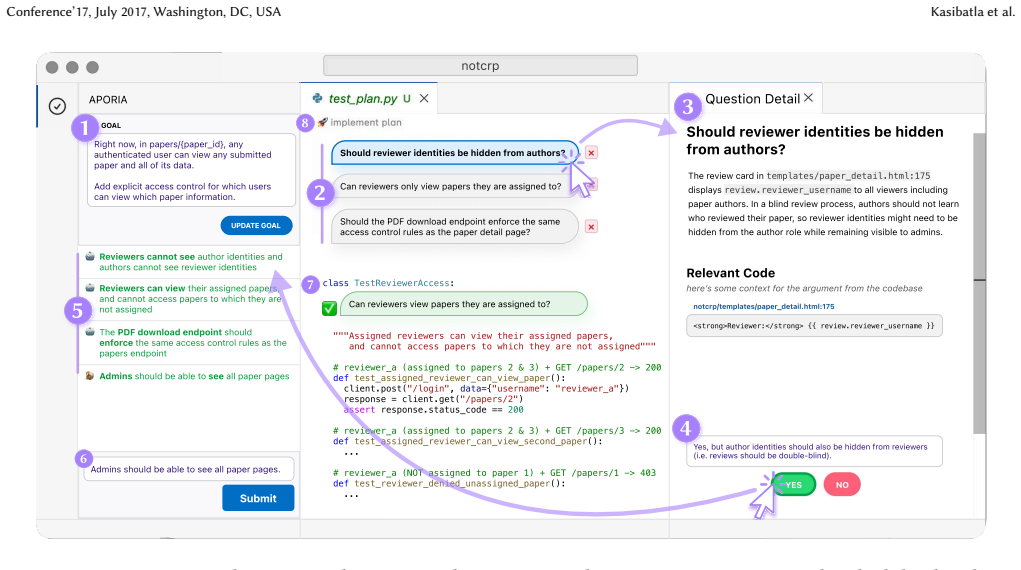
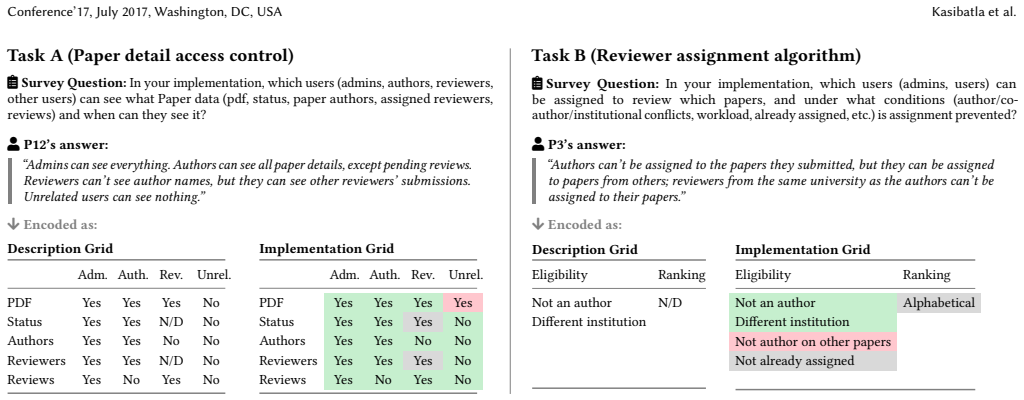



read the original abstract
AI agents allow developers to express computational intent abstractly, reducing cognitive effort and helping achieve flow during programming. Increased abstraction, however, comes at a cost: developers cede decision-making authority to agents, often without realizing that important design decisions are being made without them. We aim to bring these decisions to the foreground in a paradigm we dub decision-oriented programming. In DOP, (1) decisions are explicit and structured, serving as the shared medium between the programmer and the agent; (2) decisions are co-authored interactively, with the agent proactively eliciting them from the programmer; and (3) each decision is traceable to code. As a step towards this vision, we have built Aporia, a design probe that tracks decisions in a persistent, editable Decision Bank; elicits them by asking programmers design questions; and encodes each decision as an executable test suite that can be used to validate the implementation. In a user study of 14 programmers, Aporia increased engagement in the design process and scaffolded both exploration and validation. Participants also gained a more accurate understanding of their implementations, with their mental models 5x less likely to disagree with the code than a baseline coding agent.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces decision-oriented programming (DOP) as a paradigm in which design decisions are explicit and structured as the shared medium between programmer and AI agent, co-authored interactively, and traceable to code. It presents Aporia, a design probe implementing DOP via a persistent editable Decision Bank, proactive elicitation through design questions, and encoding of each decision as an executable test suite for validation. A user study with 14 programmers reports that Aporia increases engagement in the design process, scaffolds exploration and validation, and produces mental models 5x less likely to disagree with the code than a baseline coding agent.
Significance. If the user-study results hold after methodological clarification, the work could meaningfully advance human-AI collaboration in programming by foregrounding decision authority rather than abstracting it away. The design-probe approach and quantitative outcome on mental-model accuracy provide a concrete, falsifiable starting point for tools that aim to preserve developer understanding and agency.
major comments (2)
- [Abstract and User Study] Abstract and User Study section: the central empirical claim of a '5x' reduction in mental-model disagreement with the code is load-bearing for the paper's contribution, yet the manuscript supplies no description of how mental models were elicited or measured, how disagreement was operationalized or scored, the exact baseline agent implementation, participant selection or demographics, task details, session length, or any statistical analysis supporting the 5x factor. These omissions prevent evaluation of the result's validity.
- [User Study] User Study section: the comparison to the baseline coding agent must demonstrate that the baseline was matched on all interface and capability dimensions except explicit decision tracking; without this, it is impossible to isolate the effect of the Decision Bank and elicitation features from other differences that could drive the observed engagement and accuracy gains.
minor comments (2)
- [Introduction] The three DOP principles are listed in the abstract but would benefit from a concise table or enumerated list in the introduction to make their distinctions from related ideas (e.g., test-driven development) immediately clear.
- [Abstract] The phrase '5x less likely' should be accompanied by the raw rates or probabilities (e.g., baseline disagreement rate vs. Aporia rate) so readers can assess the practical magnitude.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed review. The comments correctly identify gaps in methodological reporting that limit evaluability of the user-study claims. We have revised the manuscript to supply the requested details and clarifications. Our point-by-point responses follow.
read point-by-point responses
-
Referee: [Abstract and User Study] Abstract and User Study section: the central empirical claim of a '5x' reduction in mental-model disagreement with the code is load-bearing for the paper's contribution, yet the manuscript supplies no description of how mental models were elicited or measured, how disagreement was operationalized or scored, the exact baseline agent implementation, participant selection or demographics, task details, session length, or any statistical analysis supporting the 5x factor. These omissions prevent evaluation of the result's validity.
Authors: We agree that the original manuscript omitted critical methodological details required to assess the 5x claim. This was a reporting oversight. The revised User Study section now provides: (1) the exact protocol for eliciting mental models (post-task structured interviews plus code-behavior prediction tasks), (2) the operationalization and scoring of disagreement (binary mismatch between participant prediction and observed execution trace, aggregated across tasks), (3) the baseline agent specification (identical underlying LLM and chat interface, differing only in the absence of the Decision Bank and proactive elicitation), (4) participant recruitment, demographics, and screening criteria, (5) task descriptions and session durations, and (6) the descriptive frequency analysis underlying the 5x ratio together with its limitations. These additions enable readers to evaluate internal validity. revision: yes
-
Referee: [User Study] User Study section: the comparison to the baseline coding agent must demonstrate that the baseline was matched on all interface and capability dimensions except explicit decision tracking; without this, it is impossible to isolate the effect of the Decision Bank and elicitation features from other differences that could drive the observed engagement and accuracy gains.
Authors: We concur that isolating the contribution of explicit decision tracking requires the baseline to be matched on all other interface and capability dimensions. The revised manuscript now includes a dedicated subsection describing the baseline implementation and the controls used to equate it with Aporia on chat latency, code-generation quality, UI layout, and available commands. We also added a limitations paragraph discussing residual confounds and the rationale for the chosen between-subjects design. These changes make the attribution argument explicit and falsifiable. revision: yes
Circularity Check
No circularity: empirical user study with no derivation chain
full rationale
This paper presents an empirical design-probe study of the Aporia system rather than any mathematical derivation, first-principles result, or fitted model. The central claims rest on a 14-participant user study measuring engagement, scaffolding, and mental-model accuracy; these outcomes are reported directly from participant data and do not reduce by construction to prior definitions, self-citations, or fitted parameters. No equations, ansatzes, uniqueness theorems, or self-referential predictions appear in the provided abstract or study description. The work is therefore self-contained against external benchmarks (the study itself) with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Making design decisions explicit and interactive improves programmer engagement and mental model accuracy
- ad hoc to paper Encoding each decision as an executable test suite provides effective validation
invented entities (2)
-
Decision Bank
no independent evidence
-
Aporia design probe
no independent evidence
Reference graph
Works this paper leans on
-
[1]
[n. d.]. Agent Context Protocol. https://zed.dev/acp
-
[2]
[n. d.]. Model Context Protocol. https://modelcontextprotocol.io/
-
[3]
[n. d.]. Visual Studio Code. https://code.visualstudio.com
-
[4]
2026.Claude Code CLI
Anthropic. 2026.Claude Code CLI. https://code.claude.com/docs/en/cli-reference
2026
-
[5]
2026.Introducing Claude Sonnet 4.6
Anthropic. 2026.Introducing Claude Sonnet 4.6. https://www.anthropic.com/ news/claude-sonnet-4-6
2026
-
[6]
James, and Nadia Polikarpova
Shraddha Barke, Michael B. James, and Nadia Polikarpova. 2023. Grounded Copilot: How Programmers Interact with Code-Generating Models.Proceedings of the ACM on Programming Languages7, OOPSLA1 (April 2023), 85–111. doi:10. 1145/3586030
2023
-
[7]
2002.Test Driven Development
Kent Beck. 2002.Test Driven Development. By Example. Addison-Wesley Longman, Amsterdam
2002
-
[8]
2015.Test-driven development: by example(20
Kent Beck. 2015.Test-driven development: by example(20. printing ed.). Addison- Wesley, Boston
2015
-
[9]
Markus Borg, Dave Hewett, Nadim Hagatulah, Noric Couderc, Emma Söderberg, Donald Graham, Uttam Kini, and Dave Farley. 2026. Echoes of AI: Investi- gating the Downstream Effects of AI Assistants on Software Maintainability. arXiv:2507.00788 [cs.SE] https://arxiv.org/abs/2507.00788
-
[10]
Dibyendu Brinto Bose. 2025. From prompts to properties: Rethinking llm code generation with property-based testing. InProceedings of the 33rd ACM Interna- tional Conference on the Foundations of Software Engineering. 1660–1665
2025
-
[11]
Virginia Braun and Victoria Clarke. 2006. Using thematic analysis in psychology. Qualitative research in psychology3, 2 (2006), 77–101
2006
-
[12]
Ruijia Cheng, Titus Barik, Alan Leung, Fred Hohman, and Jeffrey Nichols. 2024. BISCUIT: Scaffolding LLM-Generated Code with Ephemeral UIs in Computational Notebooks. In2024 IEEE Symposium on Visual Languages and Human-Centric Computing (VL/HCC). 13–23. doi:10.1109/VL/HCC60511.2024.00012
-
[13]
Koen Claessen and John Hughes. 2000. QuickCheck: a lightweight tool for random testing of Haskell programs. InProceedings of the Fifth ACM SIGPLAN International Conference on Functional Programming (ICFP ’00), Montreal, Canada, September 18-21, 2000, Martin Odersky and Philip Wadler (Eds.). ACM, 268–279. doi:10.1145/351240.351266
-
[14]
2026.code-server: VS Code in the browser
Coder. 2026.code-server: VS Code in the browser. https://github.com/coder/code- server
2026
-
[15]
Cursor. 2023. Cursor. https://cursor.com
2023
-
[16]
Sarah Fakhoury, Aaditya Naik, Georgios Sakkas, Saikat Chakraborty, and Shu- vendu K. Lahiri. 2024. LLM-Based Test-Driven Interactive Code Generation: User Study and Empirical Evaluation.IEEE Transactions on Software Engineering50, 9 (2024), 2254–2268. doi:10.1109/TSE.2024.3428972
- [17]
- [18]
- [19]
-
[20]
Katy Ilonka Gero, Chelse Swoopes, Ziwei Gu, Jonathan K. Kummerfeld, and Elena L. Glassman. 2024. Supporting Sensemaking of Large Language Model Outputs at Scale. InProceedings of the CHI Conference on Human Factors in Computing Systems, CHI 2024, Honolulu, HI, USA, May 11-16, 2024, Florian ’Floyd’ Mueller, Penny Kyburz, Julie R. Williamson, Corina Sas, Ma...
-
[21]
Emmanuel Anaya González, Raven Rothkopf, Sorin Lerner, and Nadia Polikar- pova. 2025. HiLDE: Intentional Code Generation via Human-in-the-Loop Decod- ing. In2025 IEEE Symposium on Visual Languages and Human-Centric Computing (VL/HCC). 222–233. doi:10.1109/VL-HCC65237.2025.00032
-
[22]
Kevin Han, Siddharth Maddikayala, Tim Knappe, Om Patel, Austen Liao, and Amir Barati Farimani. 2026. TDFlow: Agentic Workflows for Test Driven Development. InProceedings of the 19th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers), Vera Demberg, Kentaro Inui, and Lluís Marquez (Eds.). Association ...
-
[23]
Sandra G Hart and Lowell E Staveland. 1988. Development of NASA-TLX (Task Load Index): Results of empirical and theoretical research. InAdvances in psy- chology. Vol. 52. Elsevier, 139–183
1988
- [24]
-
[25]
Grace Murray Hopper. 1969. Standardization of high-level languages. InPro- ceedings of the May 14-16, 1969, Spring Joint Computer Conference(Boston, Mas- sachusetts)(AFIPS ’69 (Spring)). Association for Computing Machinery, New York, NY, USA, 608–609. doi:10.1145/1476793.1476890
- [26]
-
[27]
Ruanqianqian Huang, Avery Reyna, Sorin Lerner, Haijun Xia, and Brian Hempel
-
[28]
Professional Software Developers Don’t Vibe, They Control: AI Agent Use for Coding in 2025. arXiv:2512.14012 [cs.SE] https://arxiv.org/abs/2512.14012
-
[29]
GitHub Inc. 2022. GitHub Copilot. https://github.com/features/copilot
2022
-
[30]
Stack Exchange Inc. [n. d.]. 2025 Stack Overflow Developer Survey. https: //survey.stackoverflow.co/2025
2025
-
[31]
Windsurf Inc. 2024. Windsurf. https://windsurf.com
2024
-
[32]
Eshin Jolly. 2018. Pymer4: Connecting R and Python for linear mixed modeling. Journal of Open Source Software3, 31 (2018), 862
2018
-
[33]
Hen- ley, Carina Negreanu, and Advait Sarkar
Majeed Kazemitabaar, Jack Williams, Ian Drosos, Tovi Grossman, Austin Z. Hen- ley, Carina Negreanu, and Advait Sarkar. 2024. Improving Steering and Veri- fication in AI-Assisted Data Analysis with Interactive Task Decomposition. In Proceedings of the 37th Annual ACM Symposium on User Interface Software and Technology (UIST ’24). ACM. doi:10.1145/3654777.3...
-
[34]
Maurice George Kendall and Jean Dickinson Gibbons. 1962. Rank correlation methods. (1962)
1962
-
[35]
Werner Kunz and Horst W. J. Rittel. 1970.Issues as Elements of Information Systems. Technical Report 131. Institute of Urban and Regional Development, University of California, Berkeley, California
1970
-
[36]
LaToza, Maryam Arab, Dastyni Loksa, and Amy J
Thomas D. LaToza, Maryam Arab, Dastyni Loksa, and Amy J. Ko. 2020. Explicit programming strategies.Empir. Softw. Eng.25, 4 (2020), 2416–2449. doi:10.1007/ S10664-020-09810-1
2020
- [37]
-
[38]
Wendy E. Mackay and Joanna McGrenere. 2025. Comparative Structured Obser- vation.ACM Trans. Comput.-Hum. Interact.32, 2, Article 14 (April 2025), 27 pages. doi:10.1145/3711838
-
[39]
Young, Victoria Bellotti, and Thomas P
Allan MacLean, Richard M. Young, Victoria Bellotti, and Thomas P. Moran. 1991. Questions, Options, and Criteria: Elements of Design Space Analysis.Hum. Comput. Interact.6, 3-4 (1991), 201–250. doi:10.1080/07370024.1991.9667168
-
[40]
2018.Statistical rethinking: A Bayesian course with examples in R and Stan
Richard McElreath. 2018.Statistical rethinking: A Bayesian course with examples in R and Stan. Chapman and Hall/CRC
2018
-
[41]
Dirk Merkel. 2014. Docker: lightweight linux containers for consistent develop- ment and deployment.Linux journal2014, 239 (2014), 2
2014
-
[42]
2026.Visual Studio Code
Microsoft Corporation. 2026.Visual Studio Code. https://visualstudio.com Version 1.109
2026
-
[43]
1996.Design rationale: Concepts, techniques, and use
Thomas P Moran and John M Carroll. 1996.Design rationale: Concepts, techniques, and use. CRC Press
1996
-
[44]
1994.Heuristic Evaluation
Jakob Neilsen. 1994.Heuristic Evaluation. John Wiley & Sons, Inc., USA. 25–62 pages
1994
-
[45]
Anthropic PBC. 2025. Claude Code. https://claude.com/product/claude-code
2025
- [46]
-
[47]
Kevin Pu, Daniel Lazaro, Ian Arawjo, Haijun Xia, Ziang Xiao, Tovi Grossman, and Yan Chen. 2025. Assistance or disruption? exploring and evaluating the design and trade-offs of proactive ai programming support. InProceedings of the 2025 CHI conference on human factors in computing systems. 1–21
2025
- [48]
-
[49]
Margaret-Anne Storey. 2026. From Technical Debt to Cognitive and Intent Debt: Rethinking Software Health in the Age of AI. arXiv:2603.22106 [cs.SE] https://arxiv.org/abs/2603.22106
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[50]
Sangho Suh, Meng Chen, Bryan Min, Toby Jia-Jun Li, and Haijun Xia. 2024. Luminate: Structured Generation and Exploration of Design Space with Large Language Models for Human-AI Co-Creation. InProceedings of the CHI Conference on Human Factors in Computing Systems, CHI 2024, Honolulu, HI, USA, May 11- 16, 2024, Florian ’Floyd’ Mueller, Penny Kyburz, Julie ...
-
[51]
Mojtaba Vaismoradi, Hannele Turunen, and Terese Bondas. 2013. Content analy- sis and thematic analysis: Implications for conducting a qualitative descriptive study.Nursing & health sciences15, 3 (2013), 398–405
2013
-
[52]
Glassman, Jeevana Priya Inala, and Chenglong Wang
Priyan Vaithilingam, Elena L. Glassman, Jeevana Priya Inala, and Chenglong Wang. 2024. DynaVis: Dynamically Synthesized UI Widgets for Visualization Editing. InProceedings of the 2024 CHI Conference on Human Factors in Computing Systems(Honolulu, HI, USA)(CHI ’24). Association for Computing Machinery, New York, NY, USA, Article 985, 17 pages. doi:10.1145/...
-
[53]
Priyan Vaithilingam, Munyeong Kim, Frida-Cecilia Acosta-Parenteau, Daniel Lee, Amine Mhedhbi, Elena L. Glassman, and Ian Arawjo. 2025. Semantic Commit: Helping Users Update Intent Specifications for AI Memory at Scale. InProceedings of the 38th Annual ACM Symposium on User Interface Software and Technology, UIST 2025, Busan, Korea, 28 September 2025 - 1 O...
-
[54]
Experience: Evaluating the Usability of Code Generation Tools Powered by Large Language Models
Priyan Vaithilingam, Tianyi Zhang, and Elena L. Glassman. 2022. Expectation vs. Experience: Evaluating the Usability of Code Generation Tools Powered by Large Language Models. InCHI Conference on Human Factors in Computing Systems Ex- tended Abstracts. ACM, New Orleans LA USA, 1–7. doi:10.1145/3491101.3519665
- [55]
-
[56]
1992.Individual Comparisons by Ranking Methods
Frank Wilcoxon. 1992.Individual Comparisons by Ranking Methods. Springer New York, New York, NY, 196–202. doi:10.1007/978-1-4612-4380-9_16
-
[57]
Ryan Yen, Jiawen Stefanie Zhu, Sangho Suh, Haijun Xia, and Jian Zhao. 2024. CoLadder: Manipulating Code Generation via Multi-Level Blocks. InProceedings of the 37th Annual ACM Symposium on User Interface Software and Technology, UIST 2024, Pittsburgh, PA, USA, October 13-16, 2024, Lining Yao, Mayank Goel, Alexandra Ion, and Pedro Lopes (Eds.). ACM, 11:1–1...
-
[58]
J. D. Zamfirescu-Pereira, Eunice Jun, Michael Terry, Qian Yang, and Bjoern Hartmann. 2025. Beyond Code Generation: LLM-supported Exploration of the Program Design Space. InProceedings of the 2025 CHI Conference on Human Factors in Computing Systems, CHI 2025, YokohamaJapan, 26 April 2025- 1 May 2025, Naomi Yamashita, Vanessa Evers, Koji Yatani, Sharon Xia...
-
[59]
Wenshuo Zhang, Leixian Shen, Shuchang Xu, Jindu Wang, Jian Zhao, Huamin Qu, and Linping Yuan. 2025. NeuroSync: Intent-Aware Code-Based Problem Solving via Direct LLM Understanding Modification. InProceedings of the 38th Annual ACM Symposium on User Interface Software and Technology, UIST 2025, Busan, Korea, 28 September 2025 - 1 October 2025, Andrea Bianc...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.