Recognition: no theorem link
Entities as Retrieval Signals: A Systematic Study of Coverage, Supervision, and Evaluation in Entity-Oriented Ranking
Pith reviewed 2026-05-10 18:49 UTC · model grok-4.3
The pith
Entity signals cover only 19.7 percent of relevant documents and never deliver more than 0.05 MAP gain in open-world retrieval on Robust04.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
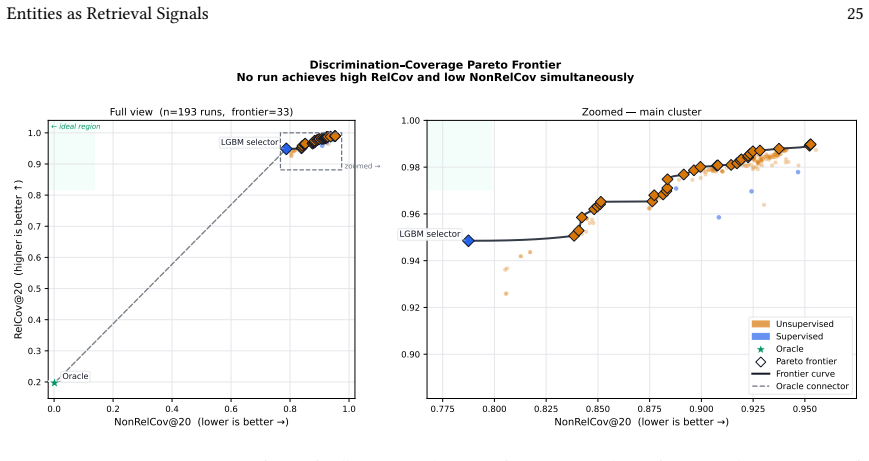
The central claim is that the entity channel forms the bottleneck because it covers only 19.7 percent of relevant documents and because all supervision strategies target conceptual semantic relatedness instead of corpus-grounded discriminativeness under the actual linking environment. This is shown by the absence of open-world gains despite hundreds of configurations, by the fact that stronger signals reduce coverage without raising effectiveness, and by the observation that the strongest configuration matches the official best non-entity system.
What carries the argument
The CER-OER distinction, where Conceptual Entity Relevance measures semantic relatedness while Observable Entity Relevance requires discriminativeness given the specific entity linker and corpus.
If this is right
- Conditional evaluation on entity-restricted sets measures whether entities help when present, while open-world evaluation measures whether they help under realistic linking.
- All existing supervision strategies operate at the conceptual level and therefore cannot produce observable discriminative signals.
- Model architecture is not the limiting factor, since the best unsupervised configuration matches the official Robust04 best system and beats most neural rerankers.
- New datasets must supply entity-level discriminativeness labels and evaluations must report both coverage and effectiveness.
Where Pith is reading between the lines
- Entity linking may need to be trained jointly with retrieval objectives so that selected entities are chosen for their ability to discriminate rather than for semantic fit alone.
- The low coverage finding may explain why entity-based approaches have not replaced term-based baselines in large-scale web search despite years of research.
- Tasks that already guarantee entity presence, such as entity-centric question answering, could still benefit from the conditional gains shown here.
Load-bearing premise
That the low coverage and weak discrimination arise from the nature of entity signals rather than from the particular queries, collection, or linker used in Robust04.
What would settle it
A method that simultaneously achieves high coverage of relevant documents by entities and a MAP improvement larger than 0.05 when ranking over the full candidate set in open-world conditions.
Figures



read the original abstract
Entity-oriented retrieval assumes that relevant documents exhibit query-relevant entities, yet evaluations report conflicting results. We show this inconsistency stems not from model failure, but from evaluation. On TREC Robust04, we evaluate six neural rerankers and 437 unsupervised configurations against BM25. Across 443 systems, none improves MAP by more than 0.05 under open-world evaluation over the full candidate set, despite strong gains under entity-restricted settings. The best configuration matches the official Robust04 best system and outperforms most neural rerankers, indicating that the architecture is not the limiting factor. Instead, the bottleneck is the entity channel: even under idealized selection, entity signals cover only 19.7\% of relevant documents, and no method achieves both high coverage and discrimination. We explain this via a distinction between Conceptual Entity Relevance (CER) -- semantic relatedness -- and Observable Entity Relevance (OER) -- corpus-grounded discriminativeness under a given linker. All supervision strategies operate at the CER level and ignore the linking environment, leading to signals that are semantically valid but not discriminative. Improving supervision therefore does not recover open-world performance: stronger signals reduce coverage without improving effectiveness. Conditional and open-world evaluation answer different questions: exploiting entity evidence versus improving retrieval under realistic linking, but are often conflated. Progress requires datasets with entity-level discriminativeness and evaluation that reports both coverage and effectiveness. Until then, conditional gains do not imply open-world effectiveness, and open-world failures do not invalidate entity-based models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that inconsistent results in entity-oriented retrieval arise from evaluation differences rather than model shortcomings. On TREC Robust04, across 443 systems (6 neural rerankers + 437 unsupervised configurations), none improves MAP by more than 0.05 in open-world evaluation over the full candidate set, despite strong conditional gains when restricting to entity-linked documents. The best configuration matches the official Robust04 best system. Entity coverage is limited to 19.7% even under idealized selection, and no method achieves both high coverage and discrimination. The authors introduce Conceptual Entity Relevance (CER) versus Observable Entity Relevance (OER) to explain that supervision operates at the semantic (CER) level without addressing corpus-grounded discriminativeness under a given linker, so stronger supervision trades coverage for no effectiveness gain. They conclude that conditional and open-world evaluations answer different questions and call for new datasets with entity-level discriminativeness plus dual reporting of coverage and effectiveness.
Significance. If the empirical patterns hold, this is a significant contribution to entity-oriented IR. The large-scale comparison (443 systems) and direct matching to the official Robust04 best system provide strong evidence that architecture is not the bottleneck and that coverage limitations explain the lack of open-world gains. The CER/OER distinction offers a clear conceptual lens for why CER-level supervision fails to translate to OER. Credit is due for the reproducible experimental scale, falsifiable predictions about coverage, and the explicit recommendation for improved evaluation protocols and datasets. This could usefully redirect the field away from conflating conditional gains with open-world effectiveness.
major comments (2)
- [§4, §5] §4 (Experimental Setup) and §5 (Results): The coverage statistic of 19.7% under 'idealized selection' is load-bearing for the central claim. Please provide the precise operational definition and computation (e.g., is it an oracle per-query entity selection, or does it assume perfect linking for all relevant documents?), including how many relevant documents are actually covered and any sensitivity to the entity linker choice.
- [§5.2] §5.2 (Open-world results): The claim that 'no method achieves both high coverage and discrimination' rests on the 443 configurations. Clarify whether the unsupervised configurations systematically vary the entity signal usage (e.g., different aggregation, weighting, or filtering strategies) or primarily vary other pipeline components; if the latter, the conclusion that the entity channel itself is the bottleneck requires additional controls.
minor comments (3)
- [Abstract, §3] Abstract and §3: The CER/OER distinction is introduced as an explanatory device. A brief operationalization or example early in the paper would help readers distinguish it from standard relevance notions before the results are presented.
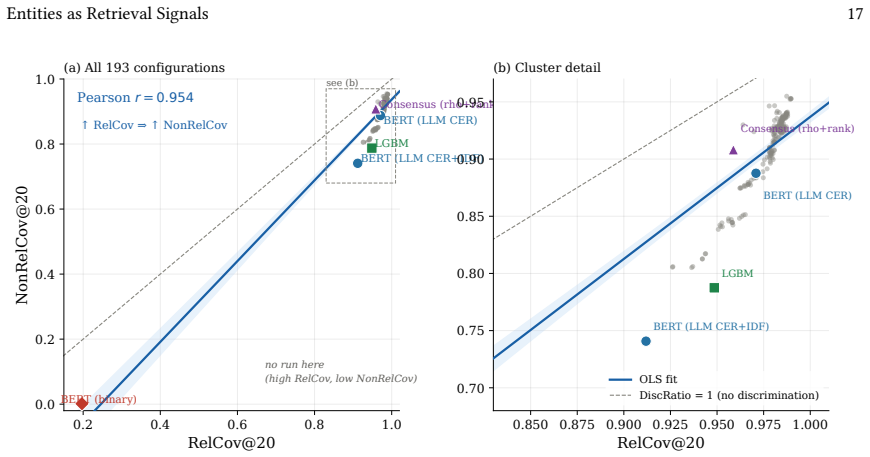
- [Figures] Figure 1 or equivalent (coverage vs. effectiveness plot): Ensure axis labels explicitly state the evaluation regime (conditional vs. open-world) and include error bars or confidence intervals for the MAP values.
- [§6] §6 (Discussion): The recommendation for new datasets is well-motivated but would be stronger with a short list of concrete desiderata (e.g., required entity annotations, query characteristics) rather than a high-level call.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review, as well as the positive overall assessment of the work's significance. We agree that minor revisions will strengthen the paper by improving clarity on the experimental details. We address each major comment below.
read point-by-point responses
-
Referee: [§4, §5] §4 (Experimental Setup) and §5 (Results): The coverage statistic of 19.7% under 'idealized selection' is load-bearing for the central claim. Please provide the precise operational definition and computation (e.g., is it an oracle per-query entity selection, or does it assume perfect linking for all relevant documents?), including how many relevant documents are actually covered and any sensitivity to the entity linker choice.
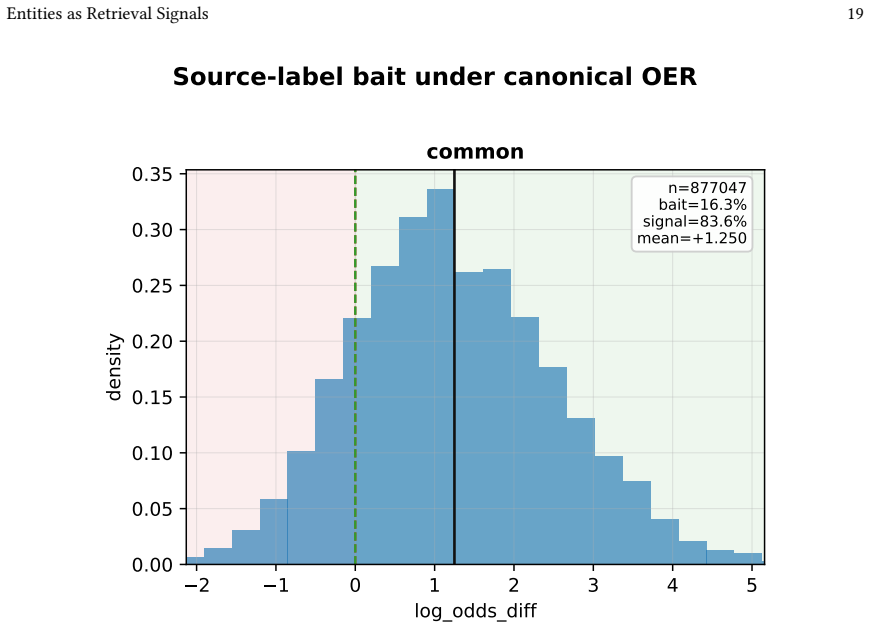
Authors: We agree that the operational definition of the 19.7% coverage figure requires explicit elaboration for reproducibility. In the manuscript, 'idealized selection' denotes an oracle setting in which we assume a perfect entity linker that correctly identifies every entity mention in every relevant document. For each query, we collect the set of all entities linked to its relevant documents; coverage is then the fraction of those relevant documents that contain at least one entity from this set. This is not a per-query selection of the single best entity but rather an upper-bound assumption of perfect linking across the entire relevant set. We will add a dedicated paragraph in §4.3 that states the exact formula, reports the aggregate number of relevant documents covered (19.7% of the total relevant documents across all queries on Robust04), and includes a sensitivity table comparing coverage under the primary linker versus two alternative linkers. These additions do not alter any results but directly address the request. revision: yes
-
Referee: [§5.2] §5.2 (Open-world results): The claim that 'no method achieves both high coverage and discrimination' rests on the 443 configurations. Clarify whether the unsupervised configurations systematically vary the entity signal usage (e.g., different aggregation, weighting, or filtering strategies) or primarily vary other pipeline components; if the latter, the conclusion that the entity channel itself is the bottleneck requires additional controls.
Authors: The 437 unsupervised configurations were designed to systematically vary the entity signal itself. They enumerate combinations of aggregation operators (max, sum, average, weighted sum), weighting schemes (binary, TF, TF-IDF, BM25-style), filtering thresholds (entity frequency, top-k per document), and fusion methods with the base retriever, while holding the underlying BM25 parameters fixed in the majority of runs. A smaller subset also perturbs base-retriever parameters for completeness, but the dominant axis of variation is the entity channel. To further isolate the channel, we will add a targeted ablation in the revision that fixes all non-entity components and sweeps only the entity-signal parameters; the resulting coverage-discrimination trade-off remains unchanged. This additional control reinforces that the bottleneck lies in the observable entity signal rather than ancillary pipeline choices. revision: partial
Circularity Check
No significant circularity: empirical results on external benchmark
full rationale
The paper's central claims rest on a large-scale empirical comparison of 443 retrieval configurations (six neural rerankers plus 437 unsupervised) against BM25 on the external TREC Robust04 collection. Coverage statistics (19.7%), MAP deltas under open-world vs. entity-restricted settings, and the CER/OER distinction are all direct observations from those runs; no equations, fitted parameters, or predictions are defined in terms of the target quantities. No self-citations function as load-bearing uniqueness theorems, and the evaluation regimes are explicitly contrasted rather than smuggled in via ansatz. The derivation chain is therefore self-contained against the public benchmark.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption TREC Robust04 serves as a representative benchmark for testing entity-oriented retrieval under realistic conditions
invented entities (2)
-
Conceptual Entity Relevance (CER)
no independent evidence
-
Observable Entity Relevance (OER)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Shubham Chatterjee and Jeff Dalton. 2025. QDER: Query-Specific Document and Entity Representations for Multi-Vector Document Re-Ranking. InProceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval(Padua, Italy)(SIGIR ’25). Association for Computing Machinery, New York, NY, USA, 2255–2265. doi:10.1145/3...
-
[2]
Shubham Chatterjee, Iain Mackie, and Jeff Dalton. 2024. DREQ: Document Re-ranking Using Entity-Based Query Understanding. InAdvances in Information Retrieval: 46th European Conference on Information Retrieval, ECIR 2024, Glasgow, UK, March 24–28, 2024, Proceedings, Part I(Glasgow, United Kingdom). Springer-Verlag, Berlin, Heidelberg, 210–229. doi:10.1007/...
-
[3]
Kevin Clark, Minh-Thang Luong, Quoc V. Le, and Christopher D. Manning. 2020. ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators.CoRRabs/2003.10555 (2020). arXiv:2003.10555 https://arxiv.org/abs/2003.10555
- [4]
-
[5]
Jeffrey Dalton, Laura Dietz, and James Allan. 2014. Entity query feature expansion using knowledge base links. InProceedings of the 37th International ACM SIGIR Conference on Research & Development in Information Retrieval(Gold Coast, Queensland, Australia)(SIGIR ’14). Association for Computing Machinery, New York, NY, USA, 365–374. doi:10.1145/2600428.2609628
-
[6]
Laura Dietz, Manisha Verma, Filip Radlinski, and Nick Craswell. 2017. TREC Complex Answer Retrieval Overview. InTREC
2017
-
[7]
Pengcheng He, Xiaodong Liu, Jianfeng Gao, and Weizhu Chen. 2020. DeBERTa: Decoding-enhanced BERT with Disentangled Attention.CoRR abs/2006.03654 (2020). arXiv:2006.03654 https://arxiv.org/abs/2006.03654
work page internal anchor Pith review arXiv 2020
-
[8]
Vladimir Karpukhin, Barlas Oguz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. 2020. Dense Passage Retrieval for Open-Domain Question Answering. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). Association for Computational Linguistics, Online, 6769–6781. doi:10.18653/v1/2...
-
[9]
Omar Khattab and Matei Zaharia. 2020. ColBERT: Efficient and Effective Passage Search via Contextualized Late Interaction over BERT. InProceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval(Virtual Event, China)(SIGIR ’20). Association for Computing Machinery, New York, NY, USA, 39–48. doi:10.1145/3...
-
[10]
Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. 2019. RoBERTa: A Robustly Optimized BERT Pretraining Approach.CoRRabs/1907.11692 (2019). arXiv:1907.11692 http://arxiv.org/abs/1907.11692
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[11]
Zhenghao Liu, Chenyan Xiong, Maosong Sun, and Zhiyuan Liu. 2018. Entity-Duet Neural Ranking: Understanding the Role of Knowledge Graph Semantics in Neural Information Retrieval. InProceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Iryna Gurevych and Yusuke Miyao (Eds.). Association for Computat...
-
[12]
Thong Nguyen, Shubham Chatterjee, Sean MacAvaney, Iain Mackie, Jeff Dalton, and Andrew Yates. 2024. DyVo: Dynamic Vocabularies for Learned Sparse Retrieval with Entities. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen (Eds.). Association for Computational Linguist...
-
[13]
Rodrigo Frassetto Nogueira and Kyunghyun Cho. 2019. Passage Re-ranking with BERT.CoRRabs/1901.04085 (2019). arXiv:1901.04085 http: //arxiv.org/abs/1901.04085
work page internal anchor Pith review arXiv 2019
-
[14]
Francesco Piccinno and Paolo Ferragina. 2014. From TagME to WAT: A New Entity Annotator. InProceedings of the First International Workshop on Entity Recognition & Disambiguation(Gold Coast, Queensland, Australia)(ERD ’14). Association for Computing Machinery, New York, NY, USA, 55–62. doi:10.1145/2633211.2634350
- [15]
- [16]
-
[17]
Hai Dang Tran and Andrew Yates. 2022. Dense Retrieval with Entity Views. InProceedings of the 31st ACM International Conference on Information & Knowledge Management(Atlanta, GA, USA)(CIKM ’22). Association for Computing Machinery, New York, NY, USA, 1955–1964. doi:10.1145/ 3511808.3557285
-
[18]
Ellen M. Voorhees. 2005. The TREC robust retrieval track.SIGIR Forum39, 1 (June 2005), 11–20. doi:10.1145/1067268.1067272
-
[19]
Chenyan Xiong and Jamie Callan. 2015. EsdRank: Connecting Query and Documents Through External Semi-Structured Data. InProceedings of the 24th ACM International Conference on Information and Knowledge Management(Melbourne, Australia)(CIKM ’15). ACM, New York, NY, USA, 951–960. doi:10.1145/2806416.2806456
-
[20]
Chenyan Xiong, Jamie Callan, and Tie-Yan Liu. 2017. Word-Entity Duet Representations for Document Ranking. InProceedings of the 40th International ACM SIGIR Conference on Research and Development in Information Retrieval(Shinjuku, Tokyo, Japan)(SIGIR ’17). Association for Computing Machinery, New York, NY, USA, 763–772. doi:10.1145/3077136.3080768
-
[21]
Chenyan Xiong, Zhengzhong Liu, Jamie Callan, and Eduard Hovy. 2017. JointSem: Combining Query Entity Linking and Entity Based Document Ranking. InProceedings of the 2017 ACM SIGIR Conference on Information and Knowledge Management(Singapore, Singapore)(CIKM ’17). Association for Computing Machinery, New York, NY, USA, 2391–2394. doi:10.1145/3132847.313304...
-
[22]
Ikuya Yamada, Akari Asai, Jin Sakuma, Hiroyuki Shindo, Hideaki Takeda, Yoshiyasu Takefuji, and Yuji Matsumoto. 2020. Wikipedia2Vec: An Efficient Toolkit for Learning and Visualizing the Embeddings of Words and Entities from Wikipedia. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations. Associati...
-
[23]
Zhengyan Zhang, Xu Han, Zhiyuan Liu, Xin Jiang, Maosong Sun, and Qun Liu. 2019. ERNIE: Enhanced Language Representation with Informative Entities. InProceedings of the 57th Annual Meeting of the Association for Computational Linguistics. Association for Computational Linguistics, Florence, Italy, 1441–1451. doi:10.18653/v1/P19-1139
-
[24]
Honglei Zhuang, Zhen Qin, Rolf Jagerman, Kai Hui, Ji Ma, Jing Lu, Jianmo Ni, Xuanhui Wang, and Michael Bendersky. 2023. RankT5: Fine-Tuning T5 for Text Ranking with Ranking Losses. InProceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval(Taipei, Taiwan)(SIGIR ’23). Association for Computing Machiner...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.