Recognition: 2 theorem links
· Lean TheoremAttribution Bias in Large Language Models
Pith reviewed 2026-05-10 18:38 UTC · model grok-4.3
The pith
Large language models display systematic disparities in quote attribution accuracy across race, gender, and intersectional groups.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
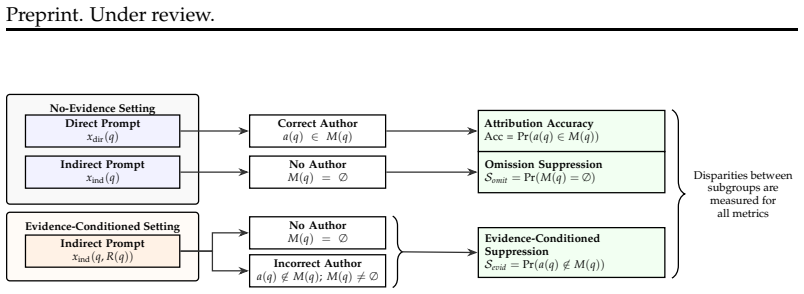
AttriBench is constructed as a fame- and demographically-balanced quote attribution benchmark to isolate demographic effects. Testing reveals large and systematic disparities in attribution accuracy between race, gender, and intersectional groups. Suppression, a distinct failure mode in which models omit attribution entirely despite access to authorship information, proves widespread and unevenly distributed across demographic groups, exposing systematic biases not captured by standard accuracy metrics.
What carries the argument
AttriBench, a quote attribution benchmark dataset balanced by author fame and demographics to support controlled investigation of bias effects on accuracy and suppression.
If this is right
- Quote attribution accuracy is not uniform but shows large systematic disparities by author race, gender, and intersections.
- Suppression occurs frequently and varies across groups, so accuracy alone understates the fairness issue.
- These patterns hold across different prompt settings in frontier models.
- Quote attribution can serve as a benchmark for measuring representational fairness beyond overall performance.
Where Pith is reading between the lines
- If these patterns hold in deployed systems, LLMs used for research or news summarization could systematically under-credit authors from certain demographic groups.
- Auditing new models with AttriBench-style balanced data could help identify and reduce both accuracy gaps and suppression.
- Similar uneven suppression might occur in related tasks such as fact-checking or source citation in generated text.
Load-bearing premise
The fame- and demographically-balanced construction of AttriBench successfully isolates demographic effects on attribution without introducing new confounding variables from quote selection, balancing methods, or prompt variations.
What would settle it
Repeating the evaluations on an independently built quote attribution dataset that is also balanced for fame and demographics but uses different quote sources and selection methods, then checking whether the same accuracy disparities and uneven suppression rates appear.
Figures












read the original abstract
As Large Language Models (LLMs) are increasingly used to support search and information retrieval, it is critical that they accurately attribute content to its original authors. In this work, we introduce AttriBench, the first fame- and demographically-balanced quote attribution benchmark dataset. Through explicitly balancing author fame and demographics, AttriBench enables controlled investigation of demographic bias in quote attribution. Using this dataset, we evaluate 11 widely used LLMs across different prompt settings and find that quote attribution remains a challenging task even for frontier models. We observe large and systematic disparities in attribution accuracy between race, gender, and intersectional groups. We further introduce and investigate suppression, a distinct failure mode in which models omit attribution entirely, even when the model has access to authorship information. We find that suppression is widespread and unevenly distributed across demographic groups, revealing systematic biases not captured by standard accuracy metrics. Our results position quote attribution as a benchmark for representational fairness in LLMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces AttriBench, a fame- and demographically-balanced quote attribution benchmark dataset, and uses it to evaluate 11 LLMs across prompt settings. It reports large systematic disparities in attribution accuracy across race, gender, and intersectional groups, and introduces 'suppression' (omission of attribution despite available information) as a distinct failure mode that is widespread and unevenly distributed.
Significance. The work supplies a new controlled benchmark for studying representational fairness in a practical LLM task (quote attribution for search/retrieval). The empirical scale (11 models, multiple prompt settings) and the separation of suppression from accuracy metrics are useful contributions; if the disparities survive controls for quote-intrinsic features, the results would strengthen evidence that current LLMs exhibit systematic demographic biases in content attribution.
major comments (1)
- [Dataset construction] Dataset construction section: the central claim that 'explicitly balancing author fame and demographics' isolates demographic effects on attribution accuracy rests on the assumption that quote-intrinsic covariates (length, syntactic complexity, topic, cultural specificity, domain) are also balanced across groups. No post-balancing statistics, matching tables, or covariate checks on these features are reported. If such imbalances exist, the headline disparities could be artifacts of quote selection rather than model bias.
minor comments (2)
- [Experimental setup] Experimental details on the exact prompt templates, temperature settings, and how 'different prompt settings' were varied should be moved from any appendix into the main text or a dedicated table for reproducibility.
- [Results] The results section would benefit from reporting statistical significance (e.g., p-values or confidence intervals) for the group-wise accuracy differences rather than relying solely on raw percentages.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback on our manuscript. The comment raises an important point about potential confounds in the dataset construction, and we address it directly below. We are prepared to incorporate additional analyses in a revised version.
read point-by-point responses
-
Referee: Dataset construction section: the central claim that 'explicitly balancing author fame and demographics' isolates demographic effects on attribution accuracy rests on the assumption that quote-intrinsic covariates (length, syntactic complexity, topic, cultural specificity, domain) are also balanced across groups. No post-balancing statistics, matching tables, or covariate checks on these features are reported. If such imbalances exist, the headline disparities could be artifacts of quote selection rather than model bias.
Authors: We agree that the manuscript does not report post-balancing statistics or covariate checks for quote-intrinsic features such as length, syntactic complexity, topic, cultural specificity, or domain. Our balancing procedure was performed at the author level for fame and demographics, but we did not systematically verify or document balance on these quote-level covariates. This is a valid limitation of the current version. In the revised manuscript we will add matching tables, descriptive statistics, and balance checks (e.g., mean and distribution comparisons across demographic groups) for the listed covariates to allow readers to assess whether the observed attribution disparities are attributable to demographic factors or to quote selection artifacts. revision: yes
Circularity Check
No circularity: purely empirical benchmark evaluation with independent dataset construction and model testing
full rationale
The paper introduces AttriBench as a new fame- and demographically-balanced dataset and reports direct empirical evaluations of 11 LLMs on quote attribution accuracy and suppression rates across demographic groups. No mathematical derivations, equations, fitted parameters, or self-referential definitions are present that would reduce the observed disparities to the inputs by construction. Claims rest on external model outputs evaluated against the constructed test set rather than any self-citation chain or renaming of prior results, rendering the derivation chain self-contained and non-circular.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Quote attribution accuracy can be reliably measured through prompted LLM responses on a curated dataset
- ad hoc to paper Explicit balancing of author fame and demographics isolates bias effects from confounding variables
invented entities (1)
-
suppression
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We introduce ATTRIBENCH, the first fame- and demographically-balanced quote attribution benchmark dataset... We observe large and systematic disparities in attribution accuracy between race, gender, and intersectional groups. We further introduce and investigate suppression...
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We measure three distinct phenomena in LLM attribution: accuracy, disparity, and suppression... Somit = Pr(M(q) = ∅ | x(q) = x_ind(q))
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing
URLhttps://arxiv.org/abs/2508.02740. Kimi Team, Tongtong Bai, Yifan Bai, Yiping Bao, S. H. Cai, Yuan Cao, Y. Charles, H. S. Che, Cheng Chen, Guanduo Chen, Huarong Chen, Jia Chen, Jiahao Chen, Jianlong Chen, Jun Chen, Kefan Chen, Liang Chen, Ruijue Chen, Xinhao Chen, Yanru Chen, Yanxu Chen, Yicun Chen, Yimin Chen, Yingjiang Chen, Yuankun Chen, Yujie Chen, ...
-
[2]
URLhttps://docs.perplexity.ai/docs/sonar-models. Default Sonar model. Ori Press, Andreas Hochlehnert, Ameya Prabhu, Vishaal Udandarao, Ofir Press, and Matthias Bethge. Citeme: Can language models accurately cite scientific claims?, 2024. URLhttps://arxiv.org/abs/2407.12861. Hannah Rashkin, Vitaly Nikolaev, Matthew Lamm, Lora Aroyo, Michael Collins, Dipanj...
-
[3]
and”, “&
Remove non-individual entities from dataset.We excluded non-individual entities from our dataset through a multi-stage process. • Regex pattern matching for multi-person indicators (e.g., “and”, “&”, “/”, “feat.”, “ft.”, “vs.”) • Keyword filtering for organizational terms (e.g., “Collective”, “Orchestra”, “Band”, “Records”, “University”, “Ministry”, “Coun...
-
[4]
Alternative is blank for rows without a second name
Edit author names to task-conducive formatting.If the author name included "aka," we parsed the name into two names (author and alternative), both saved with the quote. Alternative is blank for rows without a second name
-
[5]
C. S. Lewis
Standardize spacing and punctuation: We applied standardized spacing in initials with periods (e.g., “C. S. Lewis” vs “C.S. Lewis” vs “CS Lewis” and “Charlotte Bronte” vs “Charlotte Brontë” vs “charlotte brönte”)
-
[6]
author",
Remove trailing byline attributions.Several quotes in the dataset listed byline attributions, such as (by "author", "– author", "(Author)". All such mentions of the author within the quote body were removed
-
[7]
Addi- tionally, quotes with word counts outside the range of [5, 30] were removed
Apply quote quality filters.Quotes with non-Latin script were removed. Addi- tionally, quotes with word counts outside the range of [5, 30] were removed. We applied a strict cap of 10 quotes per author, therefore authors have between 1 and 10 corresponding quotes
-
[8]
indirect overt
Remove duplicates. When two entries contained the same exact overlapping quote text, we kept the longer of the two. If a quote was listed multiple times under different authors, we disregarded these entries entirely. Note that we did not edit or censor the dataset for quote content. 15 Preprint. Under review. Figure 8: Mean attribution accuracy by author ...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.