Recognition: no theorem link
Semantic Reality: Interactive Context-Aware Visualization of Inter-Object Relationships in Augmented Reality
Pith reviewed 2026-05-10 18:36 UTC · model grok-4.3
The pith
An AR system that builds a live model of relationships between multiple objects improves user understanding and engagement in planning and assembly tasks without raising workload.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Semantic Reality contributes a connectivity-centered interaction paradigm and a system architecture that couples anchor tracking, action sensing, and model inference to construct a live connectivity graph. Connections are visualized in-situ to highlight compatibility, reveal next steps, and reduce ambiguity during tasks. In an exploratory study comparing Semantic Reality to a single-object baseline, participants reported clearer inter-object understanding and higher engagement and satisfaction, without increased workload.
What carries the argument
The live connectivity graph built by coupling anchor tracking, action sensing, and model inference to maintain relationships among objects in the user's environment.
If this is right
- Users receive in-situ cues about which objects are compatible for a given step.
- The system surfaces suggested sequences to guide assembly or planning without requiring users to recall all relations mentally.
- Ambiguities in dynamic scenes are reduced by highlighting relevant connections on the fly.
- Task performance improves in engagement and comprehension metrics while mental workload stays comparable to simpler AR views.
Where Pith is reading between the lines
- The same live-graph approach could be tested in collaborative settings where multiple users share and edit the same set of object relationships.
- Integration with automated planning tools might allow the system to propose optimal assembly orders derived directly from the detected connections.
- Longer-term deployments in variable lighting or crowded spaces would show whether inference accuracy degrades and how often manual corrections become necessary.
Load-bearing premise
Multimodal reasoning together with spatial anchoring and action recognition can reliably detect accurate inter-object relationships in real, changing environments without frequent mistakes or user fixes.
What would settle it
A follow-up study in which participants complete the same assembly or planning tasks faster or with fewer errors using only the single-object baseline, or in which the system repeatedly misidentifies relationships during live use, would indicate the core benefits do not hold.
Figures



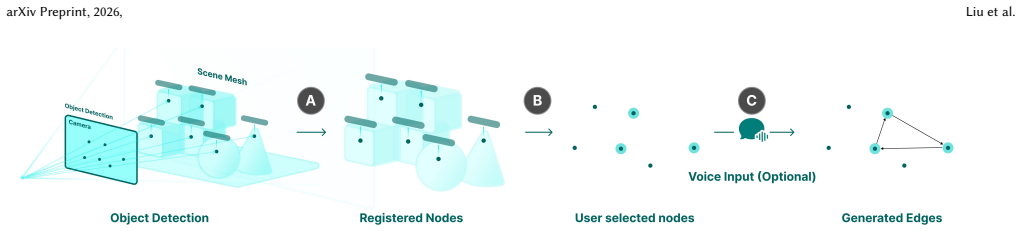
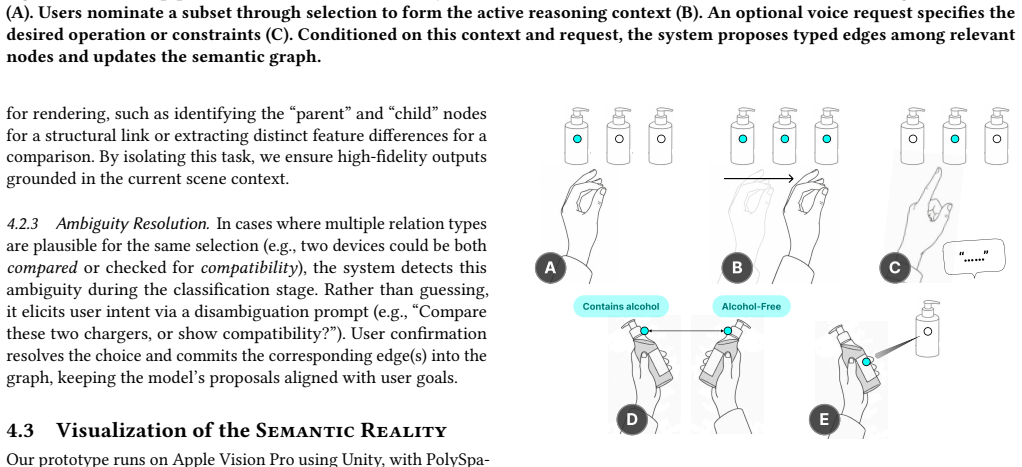








read the original abstract
Bridging the physical and digital world through interaction remains a core challenge in augmented reality (AR). Existing systems target single objects, limiting support for planning, comparison, and assembly tasks that depend on relationships among multiple items. We present Semantic Reality, an AR system focused on surfacing inter-object connectivity and making it interactive. Leveraging multimodal reasoning, spatial anchoring, and physical action recognition, Semantic Reality maintains a persistent model of objects around the user and their relationships. Connections are visualized in-situ to highlight compatibility, reveal next steps, and reduce ambiguity during tasks. We contribute a connectivity-centered interaction paradigm and a system architecture that couples anchor tracking, action sensing, and model inference to construct a live connectivity graph. In an exploratory study comparing Semantic Reality to a single-object baseline, participants reported clearer inter-object understanding and higher engagement and satisfaction, without increased workload. A scenario study illustrates where connectivity aids planning, sequencing, and disambiguation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Semantic Reality, an AR system that uses multimodal reasoning, spatial anchoring, and physical action recognition to maintain a persistent model of objects and their inter-relationships as a live connectivity graph. Connections are visualized in-situ to highlight compatibility, next steps, and reduce ambiguity. The authors contribute a connectivity-centered interaction paradigm and coupled system architecture. An exploratory study comparing the system to a single-object baseline reports that participants experienced clearer inter-object understanding, higher engagement and satisfaction, without increased workload. A scenario study illustrates utility for planning, sequencing, and disambiguation tasks.
Significance. If the exploratory findings are substantiated, the work could meaningfully advance AR interfaces by moving beyond single-object support to relational, context-aware visualizations. This has potential value for domains involving multi-object physical tasks such as assembly, planning, and education, where reducing ambiguity through interactive connectivity could improve user performance and experience.
major comments (2)
- [Abstract] The abstract reports positive outcomes from an exploratory study comparing Semantic Reality to a single-object baseline (clearer inter-object understanding, higher engagement/satisfaction, no workload increase), but supplies no details on participant count, statistical methods, task design, or potential confounds. This omission makes it impossible to verify whether the data supports the claims.
- [System Architecture / Inference Pipeline] The central claim that the system enables reliable interactive visualization of inter-object relationships rests on the multimodal reasoning + spatial anchoring + action recognition pipeline producing accurate inferences in dynamic environments. No quantitative metrics on inference accuracy, precision/recall, error rates, or manual correction frequency are reported, leaving the connection between the architecture and user-reported benefits untested.
minor comments (1)
- [Abstract] The abstract could briefly specify the types of relationships supported (e.g., compatibility, sequencing) to better scope the contribution.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our paper. We address each of the major comments below.
read point-by-point responses
-
Referee: [Abstract] The abstract reports positive outcomes from an exploratory study comparing Semantic Reality to a single-object baseline (clearer inter-object understanding, higher engagement/satisfaction, no workload increase), but supplies no details on participant count, statistical methods, task design, or potential confounds. This omission makes it impossible to verify whether the data supports the claims.
Authors: The abstract is intentionally concise to fit within typical length constraints. The full manuscript provides the complete details on the exploratory study, including the study design, participant information, tasks, and analysis approach. Since the study is exploratory and primarily qualitative, no formal statistical methods were used. We will revise the abstract to briefly note the exploratory qualitative evaluation to improve verifiability. revision: yes
-
Referee: [System Architecture / Inference Pipeline] The central claim that the system enables reliable interactive visualization of inter-object relationships rests on the multimodal reasoning + spatial anchoring + action recognition pipeline producing accurate inferences in dynamic environments. No quantitative metrics on inference accuracy, precision/recall, error rates, or manual correction frequency are reported, leaving the connection between the architecture and user-reported benefits untested.
Authors: We acknowledge that the paper does not include quantitative evaluation of the inference pipeline's accuracy. The contribution centers on the connectivity-centered interaction paradigm and the coupled system architecture, with the user study providing evidence of the benefits through participant experiences. The connection is supported by the observed improvements in understanding and engagement. However, we agree that reporting on inference reliability would strengthen the work. We will add a section discussing the limitations of the current inference approach and potential error rates based on observed user interactions, though comprehensive precision/recall metrics would require additional controlled experiments. revision: partial
Circularity Check
No circularity: system description and user study are self-contained
full rationale
The paper presents a system architecture for AR inter-object relationship visualization based on multimodal reasoning, spatial anchoring, and action recognition, followed by an exploratory user study comparing it to a baseline. No equations, mathematical derivations, fitted parameters, or predictive models are described anywhere in the text. Claims rest on the independent implementation details and participant-reported outcomes from the study, with no self-referential definitions, renamed known results, or load-bearing self-citations that reduce the central contribution to its own inputs. The derivation chain is therefore non-circular and externally grounded in the described implementation and empirical feedback.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
GPT-4V(ision) System Card
2023. GPT-4V(ision) System Card. https://www.semanticscholar.org/paper/GPT- 4V(ision)-System-Card/7a29f47f6509011fe5b19462abf6607867b68373
2023
-
[2]
Karan Ahuja, Sujeath Pareddy, Robert Xiao, Mayank Goel, and Chris Harrison
-
[3]
InProceedings of the 32nd Annual ACM Symposium on User Interface Software and Technology
Lightanchors: Appropriating point lights for spatially-anchored augmented reality interfaces. InProceedings of the 32nd Annual ACM Symposium on User Interface Software and Technology. 189–196
-
[4]
Apple Inc. 2024. RealityKit. Developer documentation. https://developer.apple. com/documentation/realitykit Used for world anchoring, scene reconstruction, raycasting, and rendering on visionOS
2024
-
[5]
Blaine Bell, Steven Feiner, and Tobias Höllerer. 2001. View management for virtual and augmented reality. InProceedings of the 14th annual ACM symposium on User interface software and technology. 101–110
2001
-
[6]
Gonzalez, Li-Te Cheng, and Mar Gonzalez-Franco
Riccardo Bovo, Steven Abreu, Karan Ahuja, Eric J. Gonzalez, Li-Te Cheng, and Mar Gonzalez-Franco. [n. d.]. EmBARDiment: an Embodied AI Agent for Productivity in XR. https://www.computer.org/csdl/proceedings-article/vr/2025/364500a708/ 25s63iZDQpa
2025
- [7]
-
[8]
Chen Chen, Cuong Nguyen, Jane Hoffswell, Jennifer Healey, Trung Bui, and Nadir Weibel. 2023. PaperToPlace: Transforming Instruction Documents into Spatialized and Context-Aware Mixed Reality Experiences. InProceedings of the 36th Annual ACM Symposium on User Interface Software and Technology (UIST ’23). Association for Computing Machinery, New York, NY, U...
-
[9]
Yifei Cheng, Yukang Yan, Xin Yi, Yuanchun Shi, and David Lindlbauer. 2021. Se- manticAdapt: Optimization-based Adaptation of Mixed Reality Layouts Leverag- ing Virtual-Physical Semantic Connections. InThe 34th Annual ACM Symposium on User Interface Software and Technology. ACM, Virtual Event USA, 282–297. doi:10.1145/3472749.3474750
-
[10]
Mustafa Doga Dogan, Eric J Gonzalez, Karan Ahuja, Ruofei Du, Andrea Colaço, Johnny Lee, Mar Gonzalez-Franco, and David Kim. 2024. Augmented Object Intelligence with XR-Objects. InProceedings of the 37th Annual ACM Symposium on User Interface Software and Technology (UIST ’24). Association for Computing Machinery, New York, NY, USA, 1–15. doi:10.1145/36547...
-
[11]
Ruofei Du, Alex Olwal, Mathieu Le Goc, Shengzhi Wu, Danhang Tang, Yinda Zhang, Jun Zhang, David Joseph Tan, Federico Tombari, and David Kim. 2022. Opportunistic interfaces for augmented reality: Transforming everyday objects into tangible 6dof interfaces using ad hoc ui. InCHI Conference on Human Factors in Computing Systems Extended Abstracts. 1–4
2022
-
[12]
Ruofei Du, Eric Lee Turner, Maksym Dzitsiuk, Luca Prasso, Ivo Duarte, Ja- son Dourgarian, Joao Afonso, Jose Pascoal, Josh Gladstone, Nuno Moura e Silva Cruces, Shahram Izadi, Adarsh Kowdle, Konstantine Nicholas John Tsotsos, and David Kim. 2020. DepthLab: Real-time 3D Interaction with Depth Maps for Mobile Augmented Reality. InProceedings of the 33rd Annu...
2020
-
[13]
Florian Echtler, Manuel Huber, Daniel Pustka, Peter Keitler, and Gudrun Klinker
-
[14]
InGRAPP 2008-3rd International Conference on Computer Graphics Theory and Applications
Splitting the scene graph-using spatial relationship graphs instead of scene graphs in augmented reality. InGRAPP 2008-3rd International Conference on Computer Graphics Theory and Applications. 456–459
2008
-
[15]
Andreas Fender, Philipp Herholz, Marc Alexa, and Jörg Müller. 2018. OptiSpace: Automated Placement of Interactive 3D Projection Mapping Content. InProc. of CHI. ACM, New York, 269. doi:10.1145/3173574.3173843
-
[16]
Andreas Fender, David Lindlbauer, Philipp Herholz, Marc Alexa, and Jörg Müller
-
[17]
HeatSpace: Automatic Placement of Displays by Empirical Analysis of User Behavior. InProc. of UIST. ACM, New York, 611–621. doi:10.1145/3126594.3126621
-
[18]
Ran Gal, Lior Shapira, Eyal Ofek, and Pushmeet Kohli. 2014. FLARE: Fast layout for augmented reality applications. In2014 IEEE international symposium on mixed and augmented reality (ISMAR). IEEE, 207–212
2014
- [19]
-
[20]
Dedre Gentner. 1983. Structure-mapping: A theoretical framework for analogy. Cognitive Science7, 2 (1983), 155–170. doi:10.1016/S0364-0213(83)80009-3
-
[21]
Mar Gonzalez-Franco and Andrea Colaco. 2024. Guidelines for productivity in virtual reality.Interactions31, 3 (2024), 46–53
2024
-
[22]
Google DeepMind. 2024. Gemini 2.5 Flash. Model documentation. https: //ai.google.dev/gemini-api/docs/models/gemini-v2-5 Multimodal LLM used for open-vocabulary perception and constrained relation inference
2024
-
[23]
Raphael Grasset, Tobias Langlotz, Denis Kalkofen, Markus Tatzgern, and Di- eter Schmalstieg. 2012. Image-driven view management for augmented reality browsers. In2012 IEEE International Symposium on Mixed and Augmented Reality (ISMAR). IEEE, 177–186
2012
-
[24]
Jens Grubert, Tobias Langlotz, Stefanie Zollmann, and Holger Regenbrecht. 2017. Towards Pervasive Augmented Reality: Context-Awareness in Augmented Reality. IEEE Trans. Vis. Comput. Graph.23, 6 (2017), 1706–1724. doi:10.1109/TVCG.2016. 2543720
-
[25]
Aditya Gunturu, Shivesh Jadon, Nandi Zhang, Morteza Faraji, Jarin Thundathil, Tafreed Ahmad, Wesley Willett, and Ryo Suzuki. 2024. RealitySummary: Explor- ing On-Demand Mixed Reality Text Summarization and Question Answering using Large Language Models.arXiv preprint arXiv:2405.18620(2024)
-
[26]
Violet Yinuo Han, Hyunsung Cho, Kiyosu Maeda, Alexandra Ion, and David Lindlbauer. 2023. BlendMR: A Computational Method to Create Ambient Mixed Reality Interfaces.Proceedings of the ACM on Human-Computer Interaction7, ISS (Oct. 2023), 217–241. doi:10.1145/3626472
-
[27]
Jeremy Hartmann, Christian Holz, Eyal Ofek, and Andrew D Wilson. 2019. Real- itycheck: Blending virtual environments with situated physical reality. InPro- ceedings of the 2019 CHI Conference on Human Factors in Computing Systems. 1–12
2019
-
[28]
Fengming He, Xiyun Hu, Xun Qian, Zhengzhe Zhu, and Karthik Ramani. 2024. AdapTUI: Adaptation of Geometric-Feature-Based Tangible User Interfaces in Augmented Reality.Proceedings of the ACM on Human-Computer Interaction8, ISS (Oct. 2024), 44–69. doi:10.1145/3698127
-
[29]
Kaiming He, Georgia Gkioxari, Piotr Dollár, and Ross Girshick. 2018. Mask R-CNN. doi:10.48550/arXiv.1703.06870 arXiv:1703.06870 [cs]
-
[30]
Anuruddha Hettiarachchi and Daniel Wigdor. 2016. Annexing Reality: Enabling Opportunistic Use of Everyday Objects as Tangible Proxies in Augmented Reality. InProceedings of the 2016 CHI Conference on Human Factors in Computing Systems. ACM, San Jose California USA, 1957–1967. doi:10.1145/2858036.2858134
-
[31]
Valentin Heun, James Hobin, and Pattie Maes. 2013. Reality editor: programming smarter objects. InProceedings of the 2013 ACM conference on Pervasive and ubiquitous computing adjunct publication. 307–310
2013
-
[32]
Gaoping Huang, Xun Qian, Tianyi Wang, Fagun Patel, Maitreya Sreeram, Yuanzhi Cao, Karthik Ramani, and Alexander J. Quinn. 2021. AdapTutAR: An Adaptive Tutoring System for Machine Tasks in Augmented Reality. InProc. of CHI. ACM, New York, 417:1–417:15. doi:10.1145/3411764.3445283
-
[33]
Lars Baunegaard Jensen, Emre Baseski, Sinan Kalkan, Nicolas Pugeault, Florentin Wörgötter, and Norbert Krüger. 2009. Semantic Reasoning for Scene Interpreta- tion.Lecture Notes in Computer Science(2009). doi:10.1007/978-3-540-92781-5_10
-
[34]
Denis Kalkofen, Erick Mendez, and Dieter Schmalstieg. 2008. Comprehensible vi- sualization for augmented reality.IEEE transactions on visualization and computer graphics15, 2 (2008), 193–204
2008
-
[35]
Yining Lang, Wei Liang, and Lap-Fai Yu. 2019. Virtual Agent Positioning Driven by Scene Semantics in Mixed Reality. In2019 IEEE Conference on Virtual Reality and 3D User Interfaces (VR). IEEE, Osaka, Japan, 767–775. doi:10.1109/VR.2019.8798018
-
[36]
Eagan, and Peter van Hardenberg
Jaewook Lee, Andrew D. Tjahjadi, Jiho Kim, Junpu Yu, Minji Park, Jiawen Zhang, Jon E. Froehlich, Yapeng Tian, and Yuhang Zhao. 2024. CookAR: Affordance Aug- mentations in Wearable AR to Support Kitchen Tool Interactions for People with Low Vision. InProceedings of the 37th Annual ACM Symposium on User Interface Software and Technology (UIST ’24). Associat...
-
[37]
Evaluating human-language model interaction
Mina Lee, Megha Srivastava, Amelia Hardy, John Thickstun, Esin Durmus, Ash- win Paranjape, Ines Gerard-Ursin, Xiang Lisa Li, Faisal Ladhak, Frieda Rong, Rose E. Wang, Minae Kwon, Joon Sung Park, Hancheng Cao, Tony Lee, Rishi Bommasani, Michael Bernstein, and Percy Liang. 2024. Evaluating Human- Language Model Interaction. doi:10.48550/arXiv.2212.09746 arX...
-
[38]
David Lindlbauer, Anna Maria Feit, and Otmar Hilliges. 2019. Context-Aware Online Adaptation of Mixed Reality Interfaces. InProceedings of the 32nd Annual ACM Symposium on User Interface Software and Technology. ACM, New Orleans LA USA, 147–160. doi:10.1145/3332165.3347945
-
[39]
David Lindlbauer and Andy D Wilson. 2018. Remixed reality: Manipulating space and time in augmented reality. InProceedings of the 2018 CHI Conference on Human Factors in Computing Systems. 1–13
2018
-
[40]
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. 2023. Visual In- struction Tuning. InProceedings of the 37th International Conference on Neural Information Processing Systems (NIPS ’23). Curran Associates Inc., Red Hook, NY, USA, 34892–34916
2023
- [41]
-
[42]
Xingyu Bruce Liu, Jiahao Nick Li, David Kim, Xiang ’Anthony’ Chen, and Ruofei Du. 2024. Human I/O: Towards a Unified Approach to Detecting Situational Impairments. InProceedings of the 2024 CHI Conference on Human Factors in Computing Systems (CHI ’24). Association for Computing Machinery, New York, NY, USA, 1–18. doi:10.1145/3613904.3642065
-
[43]
Yuan Liu, Haodong Duan, Yuanhan Zhang, Bo Li, Songyang Zhang, Wangbo Zhao, Yike Yuan, Jiaqi Wang, Conghui He, Ziwei Liu, Kai Chen, and Dahua Lin
-
[44]
MMBench: Is Your Multi-modal Model an All-around Player? doi:10.48550/ arXiv.2307.06281 arXiv:2307.06281 [cs]
work page internal anchor Pith review arXiv
-
[45]
Wendy E Mackay and Michel Beaudouin-Lafon. 2025. Interaction substrates: combining power and simplicity in interactive systems. InProceedings of the 2025 CHI Conference on Human Factors in Computing Systems. 1–16
2025
-
[46]
Benjamin Nuernberger, Eyal Ofek, Hrvoje Benko, and Andrew D. Wilson. 2016. SnapToReality: Aligning Augmented Reality to the Real World. InProc. of CHI. ACM, New York, 1233–1244. doi:10.1145/2858036.2858250
-
[47]
Nels Numan, Shwetha Rajaram, Balasaravanan Thoravi Kumaravel, Nicolai Mar- quardt, and Andrew D Wilson. 2024. SpaceBlender: Creating Context-Rich Collaborative Spaces Through Generative 3D Scene Blending. InProceedings of the 37th Annual ACM Symposium on User Interface Software and Technol- ogy (UIST ’24). Association for Computing Machinery, New York, NY...
-
[48]
Nels Numan, Jessica Van Brummelen, Ziwen Lu, and Anthony Steed. 2025. Adjus- tAR: AI-Driven In-Situ Adjustment of Site-Specific Augmented Reality Content. InAdjunct Proceedings of the 38th Annual ACM Symposium on User Interface Soft- ware and Technology (UIST Adjunct ’25). Association for Computing Machinery, New York, NY, USA, 1–4. doi:10.1145/3746058.3758362
-
[49]
Joseph Redmon and Ali Farhadi. 2018. YOLOv3: An Incremental Improvement. doi:10.48550/arXiv.1804.02767 arXiv:1804.02767 [cs]
work page internal anchor Pith review doi:10.48550/arxiv.1804.02767 2018
-
[50]
Sruti Srinidhi, Edward Lu, and Anthony Rowe. 2024. XaiR: An XR Platform that Integrates Large Language Models with the Physical World. IEEE Computer Society, 759–767. doi:10.1109/ISMAR62088.2024.00091
-
[51]
Ryo Suzuki, Parastoo Abtahi, Cheng Zhu-Tian, Mustafa Doga Dogan, Andrea Colaco, Eric J Gonzalez, Karan Ahuja, and Mar Gonzalez-Franco. [n. d.]. Pro- grammable Reality.Frontiers in Virtual Reality6 ([n. d.]), 1649785
-
[52]
Ryo Suzuki, Mar Gonzalez-Franco, Misha Sra, and David Lindlbauer. 2024. Every- day AR through AI-in-the-Loop. doi:10.1145/3706599.3706741 arXiv:2412.12681 [cs]
-
[53]
Ryo Suzuki, Eyal Ofek, Mike Sinclair, Daniel Leithinger, and Mar Gonzalez- Franco. 2021. Hapticbots: Distributed encountered-type haptics for vr with multiple shape-changing mobile robots. InThe 34th Annual ACM Symposium on User Interface Software and Technology. 1269–1281
2021
-
[54]
Tomu Tahara, Takashi Seno, Gaku Narita, and Tomoya Ishikawa. 2020. Retar- getable AR: Context-aware Augmented Reality in Indoor Scenes based on 3D Scene Graph. InProc. of ISMAR. IEEE Computer Society, Los Alamitos, 249–255. doi:10.1109/ISMAR-Adjunct51615.2020.00072
-
[55]
Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, Katie Millican, et al. 2023. Gemini: a family of highly capable multimodal models.arXiv preprint arXiv:2312.11805(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[56]
Wai Tong, Chen Zhu-Tian, Meng Xia, Leo Yu-Ho Lo, Linping Yuan, Benjamin Bach, and Huamin Qu. 2022. Exploring interactions with printed data visual- izations in augmented reality.IEEE transactions on visualization and computer graphics29, 1 (2022), 418–428
2022
-
[57]
Unity Technologies. 2024. Unity PolySpatial for visionOS. Product documentation. https://docs.unity3d.com/Packages/com.unity.polyspatial@latest Used to bridge Unity world-anchored content to RealityKit
2024
-
[58]
Eduardo Veas, Raphael Grasset, Ernst Kruijff, and Dieter Schmalstieg. 2012. Ex- tended overview techniques for outdoor augmented reality.IEEE transactions on visualization and computer graphics18, 4 (2012), 565–572
2012
-
[59]
Chen Zhu-Tian, Daniele Chiappalupi, Tica Lin, Yalong Yang, Johanna Beyer, and Hanspeter Pfister. 2024. RL-L: A Deep Reinforcement Learning Approach Intended for AR Label Placement in Dynamic Scenarios.IEEE Trans. Vis. Comput. Graph.30, 1 (2024), 1347–1357. doi:10.1109/TVCG.2023.3326568
- [60]
-
[61]
Chen Zhu-Tian, Wai Tong, Qianwen Wang, Benjamin Bach, and Huamin Qu
-
[62]
Augmenting Static Visualizations with PapARVis Designer. InProceedings of the 2020 CHI Conference on Human Factors in Computing Systems(Honolulu, HI, USA)(CHI ’20). Association for Computing Machinery, New York, NY, USA, 1–12. doi:10.1145/3313831.3376436 A System Prompts To facilitate reproducibility, we provide the core system prompts used to drive the M...
-
[63]
I found this systemhelpfulfor completing my tasks
-
[64]
It waseasy to learn and interactwith this system, requiring little effort on my part
-
[65]
The system respondedpromptly and accuratelyto my se- lections or queries
-
[66]
It was clear howone object related to other objectsin the scene, making multi-object tasks easier
-
[67]
The systemunderstood the overall contextof my tasks or environment and offered relevant suggestions or information
-
[68]
I was able tocomplete the tasks more quickly or effec- tivelyusing this system than I would have otherwise
-
[69]
I feltengaged or enjoyedusing this system during my tasks
-
[70]
I amsatisfied with howthis system provided answers or instructions for my tasks
-
[71]
Thefrequency of suggestionsor overlays felt appropriate (neither too few nor too many)
-
[72]
Table 3: HALIE Questionnaire Statements, Adapted from [34]
I could see myself using this system forreal-world, every- day scenariosif it were available. Table 3: HALIE Questionnaire Statements, Adapted from [34]
-
[73]
What stood out to you about each one? Were there any specific features or behaviors that you particularly liked or disliked?
You tried two different systems. What stood out to you about each one? Were there any specific features or behaviors that you particularly liked or disliked?
-
[74]
How did the two systems compare in supporting the tasks you were doing? Were there differences in how easy or natural each one felt to use?
-
[75]
How did you experience these environment-level interactions? Can you give examples?
One of the systems supported interacting with groups of related objects and their relationships. How did you experience these environment-level interactions? Can you give examples?
-
[76]
How did you experience these different types of actions?
In one system, your physical actions–like pointing, picking up, or arranging objects–affected how it responded. How did you experience these different types of actions?
-
[77]
Did either system feel aware of what you were doing or what was around you? Can you think of any examples where it re- sponded in a way that matched–or did not match–your context?
-
[78]
If you could improve one or both systems, what would you change or add? Are there any physical actions or interactions you wish the system had supported?
-
[79]
Bauhaus Design
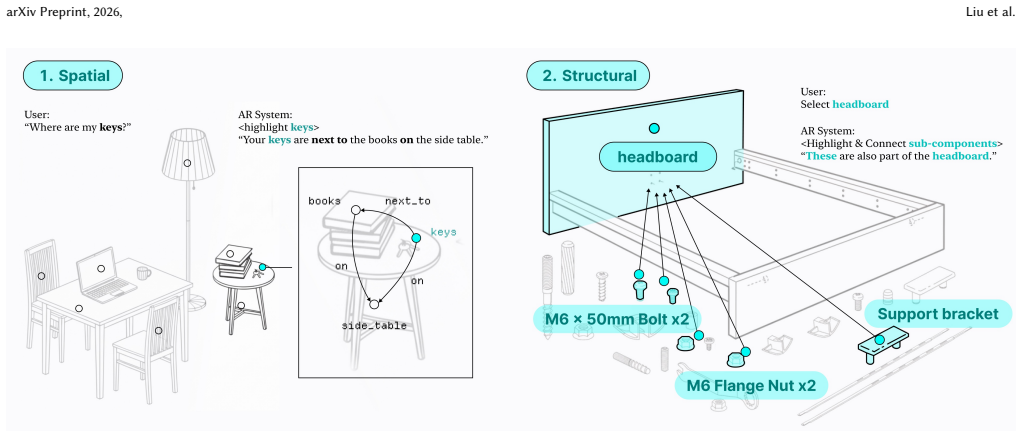
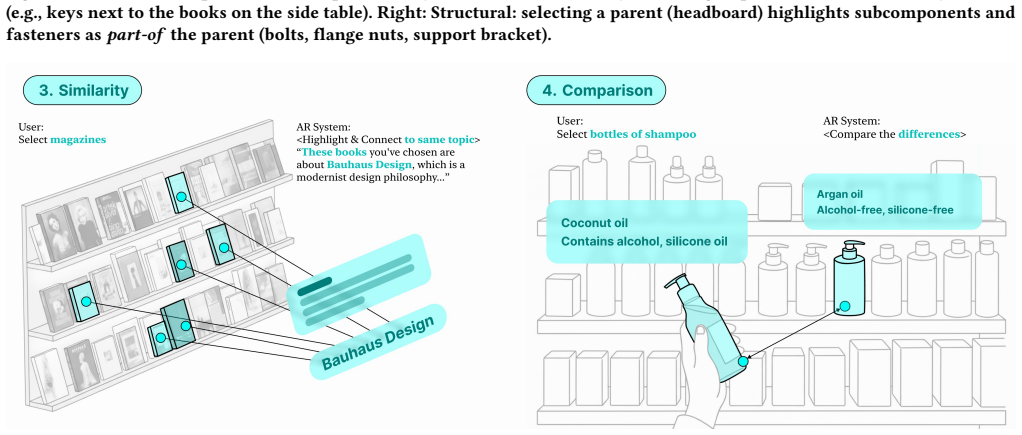
Can you think of situations in your daily life–whether everyday or occasional–where a system like this might or might not be useful? Table 4: Semi-structured interview. C Relation Example Figures arXiv Preprint, 2026, Liu et al. Figure 12: Relation examples (1–2). Left: Spatial: the system localizes an item by describing its position relative to nearby an...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.