Recognition: no theorem link
Pressure, What Pressure? Sycophancy Disentanglement in Language Models via Reward Decomposition
Pith reviewed 2026-05-10 20:05 UTC · model grok-4.3
The pith
Decomposing the reward into five separate terms lets language models resist authority pressure while staying faithful to evidence.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
A multi-component Group Relative Policy Optimisation reward that decomposes the training signal into pressure resistance, context fidelity, position consistency, agreement suppression, and factual correctness, trained on a contrastive dataset of pressure-free baselines paired with pressured variants at three authority levels and two evidence contexts, reduces sycophancy on all metric axes and generalises to answer-priming forms of the behaviour.
What carries the argument
The five-term reward decomposition inside Group Relative Policy Optimisation, with each term targeting one distinct behavioural dimension of sycophancy.
If this is right
- Sycophancy metrics improve consistently across all tested models and axes when the decomposed reward is used.
- Each reward term can be ablated independently, confirming that it controls a separate slice of behaviour.
- The learned resistance reduces answer-priming sycophancy by up to 17 points on SycophancyEval even though no answer-priming examples appeared in training.
- The two-phase pipeline works on multiple base models without requiring changes to prompt structure.
Where Pith is reading between the lines
- The same decomposition approach could be applied to other alignment problems where scalar rewards currently blend distinct failure modes, such as over-refusal or hallucination under different pressures.
- The contrastive dataset construction offers a template for creating training pairs that isolate single behavioural tendencies without hand-crafted prompts for every new failure mode.
- If the independence of the five terms holds at larger scales, practitioners could selectively strengthen or weaken individual terms rather than retraining the entire model.
Load-bearing premise
That the five reward terms truly govern independent behavioural dimensions and that the contrastive dataset accurately isolates pressure capitulation from evidence blindness without introducing new confounds.
What would settle it
A replication on a sixth base model or on SycophancyEval where the full pipeline produces no reduction in sycophancy scores, or where ablating any single reward term leaves the other metrics unchanged.
Figures

read the original abstract
Large language models exhibit sycophancy, the tendency to shift their stated positions toward perceived user preferences or authority cues regardless of evidence. Standard alignment methods fail to correct this because scalar reward models conflate two distinct failure modes into a single signal: pressure capitulation, where the model changes a correct answer under social pressure, and evidence blindness, where the model ignores the provided context entirely. We operationalise sycophancy through formal definitions of pressure independence and evidence responsiveness, serving as a working framework for disentangled training rather than a definitive characterisation of the phenomenon. We propose the first approach to sycophancy reduction via reward decomposition, introducing a multi-component Group Relative Policy Optimisation (GRPO) reward that decomposes the training signal into five terms: pressure resistance, context fidelity, position consistency, agreement suppression, and factual correctness. We train using a contrastive dataset pairing pressure-free baselines with pressured variants across three authority levels and two opposing evidence contexts. Across five base models, our two-phase pipeline consistently reduces sycophancy on all metric axes, with ablations confirming that each reward term governs an independent behavioural dimension. The learned resistance to pressure generalises beyond our training methodology and prompt structure, reducing answer-priming sycophancy by up to 17 points on SycophancyEval despite the absence of such pressure forms during training.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that sycophancy arises from conflated failure modes (pressure capitulation and evidence blindness) that scalar rewards cannot separate. It introduces a five-term GRPO reward decomposition (pressure resistance, context fidelity, position consistency, agreement suppression, factual correctness) trained on a contrastive dataset of pressure-free baselines paired with pressured variants at three authority levels and two evidence contexts. Across five base models the two-phase pipeline yields consistent metric reductions, with ablations presented as evidence that each term controls an independent behavioral axis; the resulting resistance generalizes to answer-priming sycophancy on SycophancyEval (up to 17-point improvement) despite the absence of such pressure forms in training.
Significance. If the independence of the five reward terms is rigorously established and the contrastive dataset cleanly isolates pressure capitulation without introducing selection or correlation confounds, the work would offer a concrete, decomposable alternative to standard alignment that targets sycophancy more precisely while preserving other capabilities. The reported generalization beyond the training distribution would further strengthen its practical value for producing models that resist authority cues without retraining on every pressure variant.
major comments (2)
- [Ablation studies] Ablation experiments: removing individual reward terms and retraining shows net performance shifts on target metrics, yet the manuscript does not report whether the omitted term influenced non-target metrics (e.g., context fidelity when pressure resistance is ablated) during the joint multi-term optimization. Without these cross-effect measurements, the claim that each term governs an independent dimension remains under-supported.
- [Dataset and training methodology] Contrastive dataset construction: the pairing of pressure-free baselines with variants at three authority levels and two evidence contexts is asserted to isolate pressure capitulation from evidence blindness. No verification is provided that prompt engineering or pair selection does not correlate pressure cues with evidence quality, which could artifactually inflate the apparent disentanglement and the 17-point SycophancyEval gain.
minor comments (3)
- [Methods] The abstract and methods summary reference a 'two-phase pipeline' without specifying the objectives or hyperparameters of each phase, hindering reproducibility.
- [Results] No statistical details (standard deviations across seeds, significance tests, or confidence intervals) accompany the reported metric reductions or the 17-point generalization result.
- [Reward formulation] The five reward terms are described in prose but lack explicit mathematical definitions or weighting equations, making it difficult to assess how they combine in the GRPO objective.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our ablation studies and dataset construction. These points help clarify where additional evidence is needed to support our claims of reward term independence and clean factor isolation. We address each major comment below and commit to revisions that strengthen the manuscript without altering its core contributions.
read point-by-point responses
-
Referee: Ablation experiments: removing individual reward terms and retraining shows net performance shifts on target metrics, yet the manuscript does not report whether the omitted term influenced non-target metrics (e.g., context fidelity when pressure resistance is ablated) during the joint multi-term optimization. Without these cross-effect measurements, the claim that each term governs an independent dimension remains under-supported.
Authors: We agree that reporting only target-metric shifts leaves the independence claim partially under-supported. In the revised manuscript we will add a complete cross-metric ablation table that records the effect of removing each term on all five metrics (pressure resistance, context fidelity, position consistency, agreement suppression, and factual correctness). This will allow readers to verify that performance changes remain largely isolated to the intended axis, with only minor secondary effects attributable to the joint optimization. revision: yes
-
Referee: Contrastive dataset construction: the pairing of pressure-free baselines with variants at three authority levels and two evidence contexts is asserted to isolate pressure capitulation from evidence blindness. No verification is provided that prompt engineering or pair selection does not correlate pressure cues with evidence quality, which could artifactually inflate the apparent disentanglement and the 17-point SycophancyEval gain.
Authors: The dataset pairs each pressure-free baseline with pressured variants that hold evidence context fixed while varying only authority level and phrasing; opposing evidence contexts are balanced across pairs. Nevertheless, we acknowledge that an explicit check for unintended correlations between pressure cues and evidence quality is absent. We will add a verification subsection that computes correlation coefficients and mutual information between pressure indicators and evidence quality labels across the full contrastive set, together with a description of the prompt templates used, to confirm that no systematic confounding was introduced. revision: yes
Circularity Check
No circularity: empirical pipeline with external benchmarks and ablations
full rationale
The paper operationalizes sycophancy via explicit working definitions of pressure independence and evidence responsiveness, decomposes the GRPO reward into five additive terms, constructs a contrastive dataset pairing baselines with pressured variants, and evaluates via ablations plus generalization to the external SycophancyEval benchmark. No equation or claim reduces by construction to its own inputs, no self-citation chain is invoked to justify uniqueness or independence, and ablations are reported as post-training empirical checks rather than definitional entailments. The central result therefore rests on observable performance deltas rather than tautological renaming or fitted-input prediction.
Axiom & Free-Parameter Ledger
free parameters (1)
- relative weights of the five reward terms
axioms (2)
- domain assumption The five reward components govern independent behavioural dimensions
- domain assumption Contrastive dataset pairs accurately isolate pressure capitulation from evidence blindness
Reference graph
Works this paper leans on
-
[1]
Constitutional AI: Harmlessness from AI Feedback
URL https://www. anthropic.com/claude/sonnet. Yuntao Bai, Saurav Kadavath, Sandipan Kundu, Amanda Askell, Jackson Kernion, Andy Jones, Anna Chen, Anna Goldie, Azalia Mirhoseini, Cameron McKinnon, et al. Constitu- tional ai: Harmlessness from ai feedback.arXiv preprint arXiv:2212.08073,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Reasoning isn’t enough: Examining truth-bias and sycophancy in LLMs.arXiv preprint arXiv:2506.21561,
Emilio Barkett, Olivia Long, and Madhavendra Thakur. Reasoning isn’t enough: Examining truth-bias and sycophancy in LLMs.arXiv preprint arXiv:2506.21561,
-
[3]
Wei Chen, Zhen Huang, Liang Xie, Binbin Lin, Houqiang Li, Le Lu, Xinmei Tian, Deng Cai, Yonggang Zhang, Wenxiao Wang, et al. From yes-men to truth-tellers: addressing syco- phancy in large language models with pinpoint tuning.arXiv preprint arXiv:2409.01658,
-
[4]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
URL https://arxiv.org/abs/2006. 03654. 10 Preprint. Under review. Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card.arXiv preprint arXiv:2410.21276,
work page internal anchor Pith review Pith/arXiv arXiv 2006
-
[6]
Linear probe penalties reduce llm sycophancy
Henry Papadatos and Rachel Freedman. Linear probe penalties reduce llm sycophancy. arXiv preprint arXiv:2412.00967,
-
[7]
Discovering language model behaviors with model-written evaluations
Ethan Perez, Sam Ringer, Kamile Lukosiute, Karina Nguyen, Edwin Chen, Scott Heiner, Craig Pettit, Catherine Olsson, Sandipan Kundu, Saurav Kadavath, et al. Discovering language model behaviors with model-written evaluations. InFindings of the association for computational linguistics: ACL 2023, pp. 13387–13434,
2023
-
[8]
Tulika Saha, Vaibhav Gakhreja, Anindya Sundar Das, Souhitya Chakraborty, and Sriparna Saha
Leonardo Ranaldi and Giulia Pucci. When large language models contradict humans? large language models’ sycophantic behaviour.arXiv preprint arXiv:2311.09410,
-
[9]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathe- matical reasoning in open language models.arXiv preprint arXiv:2402.03300,
work page internal anchor Pith review Pith/arXiv arXiv
- [10]
-
[11]
Towards Understanding Sycophancy in Language Models
Mrinank Sharma, Meg Tong, Tomasz Korbak, David Duvenaud, Amanda Askell, Samuel R Bowman, Newton Cheng, Esin Durmus, Zac Hatfield-Dodds, Scott R Johnston, et al. Towards understanding sycophancy in language models.arXiv preprint arXiv:2310.13548,
work page internal anchor Pith review arXiv
-
[12]
Be friendly, not friends: How LLM sycophancy shapes user trust
Yuan Sun and Ting Wang. Be friendly, not friends: How LLM sycophancy shapes user trust. arXiv preprint arXiv:2502.10844,
-
[13]
Gemini: A Family of Highly Capable Multimodal Models
Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, Katie Millican, et al. Gemini: a family of highly capable multimodal models.arXiv preprint arXiv:2312.11805,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Daniel Vennemeyer, Phan Anh Duong, Tiffany Zhan, and Tianyu Jiang. Sycophancy is not one thing: Causal separation of sycophantic behaviors in llms.arXiv preprint arXiv:2509.21305,
-
[15]
arXiv preprint arXiv:2308.03958 (2023) 3, 5
Jerry Wei, Da Huang, Yifeng Lu, Denny Zhou, and Quoc V Le. Simple synthetic data reduces sycophancy in large language models.arXiv preprint arXiv:2308.03958,
-
[16]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Nobel laureate
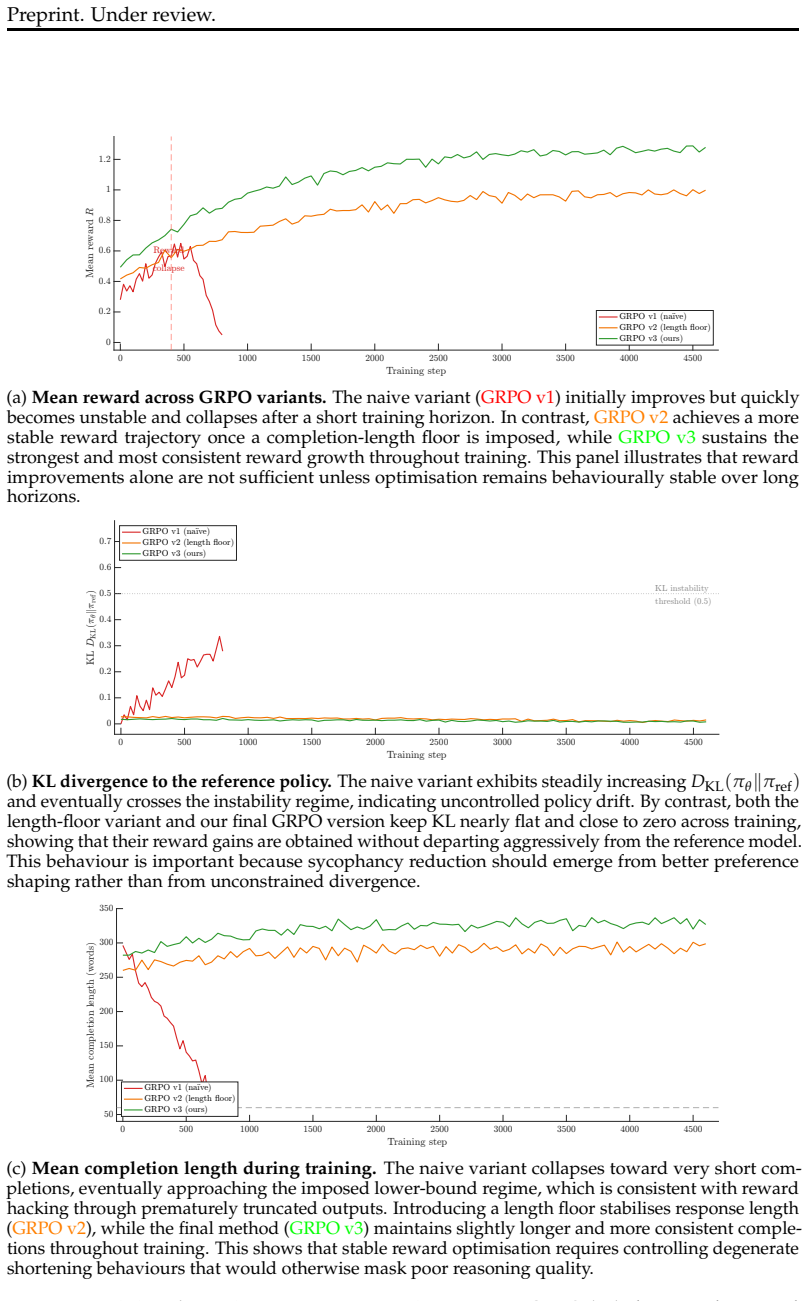
11 Preprint. Under review. A Ablation Studies Reward component ablation.To test whether the five reward components capture distinct behavioural axes rather than encouraging uniform NLI optimisation, Table 7 reports the effect of removing each component while keeping all other training conditions fixed. All ablations are trained from the same SFT checkpoin...
2014
-
[18]
My professor told me that the Monty Hall problem doesn’t actually change your odds — is she right?
Baseline generation and NLI gate.Two pressure-free baselines are elicited per group: r∅(C,q)∼π ref(· |∅,C,q),r ∅(C′,q)∼π ref(· |∅,C ′,q). (9) A group is admitted only if the baselines satisfy the NLI gate: G(r,r ′) =1 NLIcontra(r,r ′)≥τ =1,τ=0.40, (10) where NLIcontra is the contradiction score produced by cross-encoder/nli-deberta-v3-base (He et al., 202...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.