Recognition: 1 theorem link
FLARE: Agentic Coverage-Guided Fuzzing for LLM-Based Multi-Agent Systems
Pith reviewed 2026-05-10 19:57 UTC · model grok-4.3
The pith
FLARE extracts specifications from multi-agent LLM source code to drive fuzzing that detects hidden failures.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
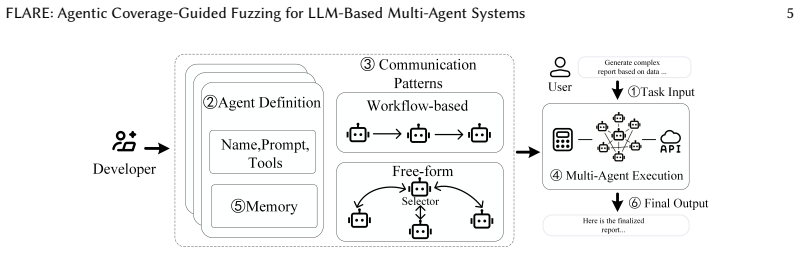
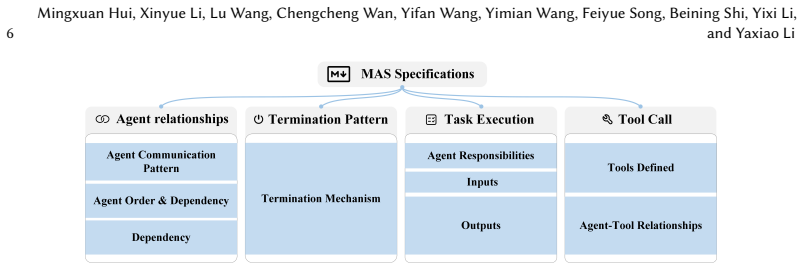
FLARE is a testing framework that takes the source code of a multi-agent LLM system, extracts specifications and behavioral spaces from agent definitions, builds test oracles, conducts coverage-guided fuzzing to expose failures, analyzes execution logs to judge semantic correctness, and generates failure reports. On 16 diverse open-source applications it reached 96.9 percent inter-agent coverage and 91.1 percent intra-agent coverage while uncovering 56 previously unknown failures unique to these systems.
What carries the argument
Coverage-guided fuzzing driven by inter-agent and intra-agent specifications extracted from agent source code definitions.
If this is right
- FLARE reaches 96.9 percent inter-agent coverage and 91.1 percent intra-agent coverage on 16 diverse open-source applications.
- It outperforms baselines by 9.5 percent in inter-agent coverage and 1.0 percent in intra-agent coverage.
- The method identifies 56 previously unknown failures that are specific to multi-agent LLM setups.
- It detects issues such as infinite loops and failed tool invocations that standard techniques miss because of missing specifications and semantic requirements.
Where Pith is reading between the lines
- Teams building multi-agent applications could embed similar code-based extraction steps into routine testing pipelines.
- The extraction-plus-fuzzing pattern might apply to single-agent LLM tools or other non-deterministic AI components with large interaction spaces.
- Coverage numbers for agent interactions could serve as a practical benchmark when validating reliability before release.
- Combining the log-analysis oracle with other verification methods might further reduce undetected coordination errors.
Load-bearing premise
Specifications and behavioral spaces can be reliably extracted from agent definitions in source code, and automated log analysis can judge semantic correctness without significant errors.
What would settle it
An application where FLARE reports high coverage yet misses a documented failure such as an infinite loop, or where its log-based pass-or-fail decisions conflict with human review on a substantial number of cases.
Figures





read the original abstract
Multi-Agent LLM Systems (MAS) have been adopted to automate complex human workflows by breaking down tasks into subtasks. However, due to the non-deterministic behavior of LLM agents and the intricate interactions between agents, MAS applications frequently encounter failures, including infinite loops and failed tool invocations. Traditional software testing techniques are ineffective in detecting such failures due to the lack of LLM agent specification, the large behavioral space of MAS, and semantic-based correctness judgment. This paper presents FLARE, a novel testing framework tailored for MAS. FLARE takes the source code of MAS as input and extracts specifications and behavioral spaces from agent definitions. Based on these specifications, FLARE builds test oracles and conducts coverage-guided fuzzing to expose failures. It then analyzes execution logs to judge whether each test has passed and generates failure reports. Our evaluation on 16 diverse open-source applications demonstrates that FLARE achieves 96.9% inter-agent coverage and 91.1% intra-agent coverage, outperforming baselines by 9.5% and 1.0%. FLARE also uncovers 56 previously unknown failures unique to MAS.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents FLARE, a testing framework for LLM-based Multi-Agent Systems (MAS). It takes MAS source code as input, extracts specifications and behavioral spaces from agent definitions, constructs test oracles, performs coverage-guided fuzzing to expose failures such as infinite loops and failed tool invocations, and analyzes execution logs to judge test outcomes and generate failure reports. Evaluation on 16 diverse open-source applications reports 96.9% inter-agent coverage and 91.1% intra-agent coverage (outperforming baselines by 9.5% and 1.0%), along with discovery of 56 previously unknown MAS-specific failures.
Significance. If the results hold after addressing validation gaps, FLARE would represent a meaningful advance in automated testing for non-deterministic MAS applications, which are increasingly deployed for complex workflows. By tailoring coverage-guided fuzzing to inter- and intra-agent behavioral spaces and providing empirical evidence on real open-source systems, the work addresses a practical gap where traditional techniques fail due to lack of specifications and semantic judgment challenges.
major comments (3)
- [Abstract and Evaluation] Abstract and Evaluation section: The headline claim of 56 previously unknown MAS-specific failures rests entirely on the correctness of the automated log analyzer for semantic pass/fail judgments (e.g., detecting incorrect inter-agent coordination or infinite loops). The manuscript provides no description of the judgment procedure (rule-based, LLM-as-judge, or hybrid), no ground-truth dataset, and no precision/recall metrics against human labels. This directly undermines both the failure count and the uniqueness claim, as any systematic misclassification would inflate the reported results.
- [Evaluation] Evaluation section: The reported coverage percentages (96.9% inter-agent, 91.1% intra-agent) and baseline outperformance (9.5% and 1.0%) lack details on exact measurement definitions, baseline implementations, statistical significance testing, or potential confounds such as variability in LLM non-determinism. Without these, the robustness of the empirical claims cannot be assessed.
- [Approach] Approach section (specification extraction): The central premise that specifications and behavioral spaces can be reliably extracted from agent definitions in source code is stated but not accompanied by any validation (e.g., manual inspection of extracted spaces on a subset of the 16 applications or error rates). This assumption is load-bearing for both the fuzzing guidance and oracle construction.
minor comments (2)
- [Abstract] The abstract states that FLARE 'analyzes execution logs to judge whether each test has passed' without any elaboration on the method or its limitations.
- [Evaluation] No mention of how the 16 applications were selected or their diversity characteristics beyond 'open-source,' which would help contextualize generalizability.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback, which identifies key areas where additional rigor and transparency will strengthen the manuscript. We address each major comment below and commit to revisions that directly respond to the concerns raised.
read point-by-point responses
-
Referee: [Abstract and Evaluation] Abstract and Evaluation section: The headline claim of 56 previously unknown MAS-specific failures rests entirely on the correctness of the automated log analyzer for semantic pass/fail judgments (e.g., detecting incorrect inter-agent coordination or infinite loops). The manuscript provides no description of the judgment procedure (rule-based, LLM-as-judge, or hybrid), no ground-truth dataset, and no precision/recall metrics against human labels. This directly undermines both the failure count and the uniqueness claim, as any systematic misclassification would inflate the reported results.
Authors: We agree that the current description of the log analyzer is insufficient to support the failure discovery claims. The analyzer combines deterministic rule-based checks (e.g., detecting repeated states for infinite loops or missing tool responses) with targeted LLM-assisted semantic judgment for coordination issues, but these details and their reliability are not adequately documented. In the revised manuscript we will add a dedicated subsection describing the full judgment procedure, include a human-annotated ground-truth set derived from a random sample of 200 test executions across the 16 applications, and report precision/recall/F1 metrics against those labels. We will also qualify the 'previously unknown' claim by noting that uniqueness was established via manual inspection of a subset of reports rather than solely by the analyzer. revision: yes
-
Referee: [Evaluation] Evaluation section: The reported coverage percentages (96.9% inter-agent, 91.1% intra-agent) and baseline outperformance (9.5% and 1.0%) lack details on exact measurement definitions, baseline implementations, statistical significance testing, or potential confounds such as variability in LLM non-determinism. Without these, the robustness of the empirical claims cannot be assessed.
Authors: We acknowledge that the Evaluation section is missing several methodological details required for reproducibility and assessment of robustness. Coverage is measured as the fraction of states and transitions in the extracted inter-agent and intra-agent behavioral spaces that are exercised at least once across fuzzing runs; baselines were constructed by porting AFL-style mutation to the MAS input space while keeping the same oracle. To mitigate LLM non-determinism we already executed each configuration five times with distinct seeds, but we did not report variance or conduct significance tests. In the revision we will expand the section with precise metric definitions, links to baseline implementations, per-application coverage tables with standard deviations, and paired t-test results comparing FLARE against baselines. revision: yes
-
Referee: [Approach] Approach section (specification extraction): The central premise that specifications and behavioral spaces can be reliably extracted from agent definitions in source code is stated but not accompanied by any validation (e.g., manual inspection of extracted spaces on a subset of the 16 applications or error rates). This assumption is load-bearing for both the fuzzing guidance and oracle construction.
Authors: The extraction step uses static parsing of agent class definitions, prompt templates, and tool signatures to construct finite-state representations of intra- and inter-agent behavior. While development involved informal manual checks confirming that all primary agent roles and transitions were captured in the 16 applications, no quantitative validation or error-rate analysis appears in the submitted manuscript. We will add an appendix containing (i) a manual audit of extracted specifications for three representative applications, (ii) the observed extraction error rate (false positives/negatives on states and transitions), and (iii) a discussion of limitations when source code lacks explicit type annotations or uses dynamic prompt construction. revision: yes
Circularity Check
No circularity: empirical results on external applications
full rationale
The paper describes an empirical testing framework applied to 16 independent open-source MAS applications. Coverage metrics and failure counts are measured outcomes from running FLARE on these external codebases, not quantities derived by construction from the framework's own parameters or definitions. No equations, fitted predictions, self-definitional loops, or load-bearing self-citations appear in the abstract or evaluation claims. The log-based oracle is an implementation detail whose accuracy is an external validation question rather than a circular reduction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Agent definitions in source code contain extractable specifications and behavioral spaces sufficient for oracle construction
- domain assumption Execution logs contain sufficient information for automated judgment of semantic correctness
Reference graph
Works this paper leans on
-
[1]
Hüseyin Oktay Altun, Hüseyin Furkan Ceran, Korkut Kutay Metin, Tolga Erol, and Emre Fisne. 2025. Strategic Imple- mentation of Super-Agents in Heterogeneous Multi-Agent Training for Advanced Military Simulation Adaptability. IEEE Access13 (2025), 96544–96563. doi:10.1109/ACCESS.2025.3573419
-
[2]
CAMEL-AI. 2025. CAMEL-AI: Finding the Scaling Laws of Agents. https://www.camel-ai.org/
2025
-
[3]
Junming Cao, Bihuan Chen, Longjie Hu, Jie Gao, Kaifeng Huang, Xuezhi Song, and Xin Peng. 2023. Characterizing the Complexity and Its Impact on Testing in ML-Enabled Systems : A Case Sutdy on Rasa. InIEEE International Conference on Software Maintenance and Evolution, ICSME 2023, Bogotá, Colombia, October 1-6, 2023. IEEE, 258–270. doi:10.1109/ICSME58846.2023.00034
-
[4]
Antonio Castaldo. 2024. AI-Recruitment-Agent: A Multi-Agent Recruitment Assistant with AutoGen. https://github. com/Ancastal/AI-Recruitment-Agent. Accessed: 2025-12-22
2024
-
[5]
Joachim de Curtò and Irene de Zarzà. 2025. LLM-Driven Social Influence for Cooperative Behavior in Multi-Agent Systems.IEEE Access13 (2025), 44330–44342. doi:10.1109/ACCESS.2025.3548451
-
[6]
Zhichen Dong, Zhanhui Zhou, Chao Yang, Jing Shao, and Yu Qiao. 2024. Attacks, Defenses and Evaluations for LLM Conversation Safety: A Survey. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), NAACL 2024, Mexico City, Mexico, June 16-21, ...
-
[7]
Yao Fehlis, Charles Crain, Aidan Jensen, Michael Watson, James Juhasz, Paul Mandel, Betty Liu, Shawn Mahon, Daren Wilson, Nick Lynch-Jonely, Ben Leedom, and David Fuller. 2025. Accelerating Drug Discovery Through Agentic AI: A 1https://anonymous.4open.science/r/ISSTA-FLARE-TEST2026123 , Vol. 1, No. 1, Article . Publication date: April 2026. 20 Mingxuan Hu...
-
[8]
Yao Fehlis, Charles Crain, Aidan Jensen, Michael Watson, James Juhasz, Paul Mandel, Betty Liu, Shawn Mahon, Daren Wilson, Nick Lynch-Jonely, Ben Leedom, and David Fuller. 2025. Technical Implementation of Tippy: Multi- Agent Architecture and System Design for Drug Discovery Laboratory Automation.CoRRabs/2507.17852 (2025). arXiv:2507.17852 doi:10.48550/ARX...
-
[9]
fuzzitdev. 2018. pythonfuzz: coverage-guided fuzz testing for Python. https://github.com/fuzzitdev/pythonfuzz. Accessed: 2025-12-11
2018
- [10]
-
[11]
Google DeepMind. 2025. Gemini 1.5 Pro: Next-generation model optimizing performance, cost, and latency. https: //deepmind.google/models/gemini/pro/. Accessed: 2026-01-12
2025
-
[12]
Kivanc Gordu. 2024. AutoGen Multiagent: Workflow Automation with AI Agents. https://github.com/kivanc57/ autogen_multiagent. Accessed: 2025-12-22
2024
-
[13]
gswithjeff. 2024. AutoGen Multi-Agent Workflow: AI-powered YouTube Shorts Creation. https://github.com/gswithjeff/ autogen-multi-agent-workflow. Accessed: 2025-12-22
2024
-
[14]
Jeff (gswithjeff). 2025. autogen-multi-agent-workflow: AI-powered YouTube Shorts creation with AutoGen 0.4. https://github.com/gswithjeff/autogen-multi-agent-workflow. Accessed: 2025-08-06
2025
-
[15]
Junda He, Christoph Treude, and David Lo. 2025. LLM-Based Multi-Agent Systems for Software Engineering: Literature Review, Vision, and the Road Ahead.ACM Trans. Softw. Eng. Methodol.34, 5 (2025), 124:1–124:30. doi:10.1145/3712003
-
[16]
Sirui Hong, Mingchen Zhuge, Jonathan Chen, Xiawu Zheng, Yuheng Cheng, Jinlin Wang, Ceyao Zhang, Zili Wang, Steven Ka Shing Yau, Zijuan Lin, Liyang Zhou, Chenyu Ran, Lingfeng Xiao, Chenglin Wu, and Jürgen Schmidhuber. 2024. MetaGPT: Meta Programming for A Multi-Agent Collaborative Framework. InThe Twelfth International Conference on Learning Representation...
2024
-
[17]
Sirui Hong, Mingchen Zhuge, Jonathan Chen, Xiawu Zheng, Yuheng Cheng, Jinlin Wang, Ceyao Zhang, Zili Wang, Steven Ka Shing Yau, Zijuan Lin, Liyang Zhou, Chenyu Ran, Lingfeng Xiao, Chenglin Wu, and Jürgen Schmidhuber. 2024. MetaGPT: Meta Programming for A Multi-Agent Collaborative Framework. InThe Twelfth International Conference on Learning Representation...
2024
-
[18]
Soneya Binta Hossain, Raygan Taylor, and Matthew Dwyer. 2025. Doc2OracLL: Investigating the Impact of Doc- umentation on LLM-Based Test Oracle Generation.Proceedings of the ACM on Software Engineering2, FSE (2025), 1870–1891
2025
-
[19]
CrewAI Inc. 2025. CrewAI: The Leading Multi-Agent Platform. https://www.crewai.com/
2025
-
[20]
Bo Jiang, Zhenyu Zhang, Wing Kwong Chan, and TH Tse. 2009. Adaptive random test case prioritization. In2009 IEEE/ACM International Conference on Automated Software Engineering. IEEE, 233–244
2009
-
[21]
Josephrp. 2024. EasyRealEstate: Multi-Agent Team for Real Estate Investment Analysis. https://github.com/Josephrp/ EasyRealEstate. Accessed: 2025-12-22
2024
-
[22]
kingglory. 2024. AI Agentic Design Patterns with AutoGen. https://github.com/kingglory/AI-Agentic-Design-Patterns- with-AutoGen. Accessed: 2025-12-22
2024
-
[23]
Stefano Lambiase, Gemma Catolino, Fabio Palomba, and Filomena Ferrucci. 2025. Motivations, Challenges, Best Practices, and Benefits for Bots and Conversational Agents in Software Engineering: A Multivocal Literature Review. ACM Comput. Surv.57, 4 (2025), 93:1–93:37. doi:10.1145/3704806
-
[24]
lewisExternal. 2024. AI-Grant-Writer-Tool: Open-source AI Tool for Writing Grant Applications. https://github.com/ lewisExternal/AI-Grant-Writer-Tool. Accessed: 2025-12-22
2024
-
[25]
Guohao Li, Hasan Hammoud, Hani Itani, Dmitrii Khizbullin, and Bernard Ghanem. 2023. CAMEL: Communicative Agents for "Mind" Exploration of Large Language Model Society. InAdvances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023, Alice Oh...
2023
-
[26]
Xiangyu Li, Yawen Zeng, Xiaofen Xing, Jin Xu, and Xiangmin Xu. 2025. HedgeAgents: A Balanced-aware Multi-agent Financial Trading System. InCompanion Proceedings of the ACM on Web Conference 2025, WWW 2025, Sydney, NSW, Australia, 28 April 2025 - 2 May 2025, Guodong Long, Michale Blumestein, Yi Chang, Liane Lewin-Eytan, Zi Helen Huang, and Elad Yom-Tov (Ed...
-
[27]
Hongliang Liang, Xiaoxiao Pei, Xiaodong Jia, Wuwei Shen, and Jian Zhang. 2018. Fuzzing: State of the art.IEEE Transactions on Reliability67, 3 (2018), 1199–1218
2018
-
[28]
Junwei Liu, Kaixin Wang, Yixuan Chen, Xin Peng, Zhenpeng Chen, Lingming Zhang, and Yiling Lou. 2024. Large Language Model-Based Agents for Software Engineering: A Survey.CoRRabs/2409.02977 (2024). arXiv:2409.02977 , Vol. 1, No. 1, Article . Publication date: April 2026. FLARE: Agentic Coverage-Guided Fuzzing for LLM-Based Multi-Agent Systems 21 doi:10.485...
-
[29]
Lyzr AI. 2025. The State of AI Agents in Enterprise: H1 2025. https://www.lyzr.ai/state-of-ai-agents/ Accessed: 2025-06-02
2025
-
[30]
Forsyth, and Dan Hendrycks
Mantas Mazeika, Long Phan, Xuwang Yin, Andy Zou, Zifan Wang, Norman Mu, Elham Sakhaee, Nathaniel Li, Steven Basart, Bo Li, David A. Forsyth, and Dan Hendrycks. 2024. HarmBench: A Standardized Evaluation Framework for Automated Red Teaming and Robust Refusal. InForty-first International Conference on Machine Learning, ICML 2024, Vienna, Austria, July 21-27...
2024
-
[31]
Mary L McHugh. 2012. Interrater reliability: the kappa statistic.Biochemia medica22, 3 (2012), 276–282
2012
-
[32]
Microsoft. 2023. AutoGen: A Programming Framework for Agentic AI. https://github.com/microsoft/autogen. Accessed: 2025-12-11
2023
-
[33]
Microsoft. 2024. AutoGen User Guide: AgentChat. https://microsoft.github.io/autogen/stable/user-guide/agentchat- user-guide/index.html. Accessed: 2025-12-22
2024
-
[34]
Microsoft Research. 2023. AutoGen: Building AI-Generated Autonomous Agents. https://www.microsoft.com/en- us/research/project/autogen/
2023
-
[35]
Neelofar Neelofar, Kate Smith-Miles, Mario Andrés Muñoz, and Aldeida Aleti. 2022. Instance space analysis of search-based software testing.IEEE Transactions on Software Engineering49, 4 (2022), 2642–2660
2022
-
[36]
Ðurica Nikolić and Fausto Spoto. 2014. Reachability analysis of program variables.ACM Transactions on Programming Languages and Systems (TOPLAS)35, 4 (2014), 1–68
2014
-
[37]
OpenAI. 2025. GPT-4.1. https://openai.com/index/gpt-4-1/. Accessed: 2026-01-12
2025
-
[38]
Gonzalez, Matei Zaharia, and Ion Stoica
Melissa Z Pan, Mert Cemri, Lakshya A Agrawal, Shuyi Yang, Bhavya Chopra, Rishabh Tiwari, Kurt Keutzer, Aditya Parameswaran, Kannan Ramchandran, Dan Klein, Joseph E. Gonzalez, Matei Zaharia, and Ion Stoica. 2025. Why Do Multiagent Systems Fail?. InICLR 2025 Workshop on Building Trust in Language Models and Applications. https: //openreview.net/forum?id=wM521FqPvI
2025
-
[39]
O’Brien, Carrie Jun Cai, Meredith Ringel Morris, Percy Liang, and Michael S
Joon Sung Park, Joseph C. O’Brien, Carrie Jun Cai, Meredith Ringel Morris, Percy Liang, and Michael S. Bernstein
-
[40]
Generative Agents: Interactive Simulacra of Human Behavior. InProceedings of the 36th Annual ACM Symposium on User Interface Software and Technology, UIST 2023, San Francisco, CA, USA, 29 October 2023- 1 November 2023, Sean Follmer, Jeff Han, Jürgen Steimle, and Nathalie Henry Riche (Eds.). ACM, 2:1–2:22. doi:10.1145/3586183.3606763
-
[41]
PraisonAI. 2025. PraisonAI Documentation. https://docs.praison.ai/
2025
-
[42]
pratyushkr9420. 2024. AI Agents Financial Report Generator Application. https://github.com/pratyushkr9420/AI_ agents_financial_report_generator_application. Accessed: 2025-12-22
2024
-
[43]
Chen Qian, Yufan Dang, Jiahao Li, Wei Liu, Zihao Xie, Yifei Wang, Weize Chen, Cheng Yang, Xin Cong, Xiaoyin Che, Zhiyuan Liu, and Maosong Sun. 2024. Experiential Co-Learning of Software-Developing Agents. InACL (1). 5628–5640. https://doi.org/10.18653/v1/2024.acl-long.305
-
[44]
Sandra Rapps and Elaine J. Weyuker. 1985. Selecting Software Test Data Using Data Flow Information.IEEE Trans. Softw. Eng.11, 4 (April 1985), 367âĂŞ375. doi:10.1109/TSE.1985.232226
-
[45]
Shaina Raza, Ranjan Sapkota, Manoj Karkee, and Christos Emmanouilidis. 2025. TRiSM for Agentic AI: A Review of Trust, Risk, and Security Management in LLM-based Agentic Multi-Agent Systems.CoRRabs/2506.04133 (2025). arXiv:2506.04133 doi:10.48550/ARXIV.2506.04133
-
[46]
Rog3rSm1th. 2020. Frelatage: coverage-based fuzzer for Python applications. https://github.com/Rog3rSm1th/Frelatage. Accessed: 2025-12-11
2020
-
[47]
Gregg Rothermel and Mary Jean Harrold. 1997. A safe, efficient regression test selection technique.ACM Transactions on Software Engineering and Methodology (TOSEM)6, 2 (1997), 173–210
1997
-
[48]
Caio Santos, Abdelrahmane Moawad, Behnam Shariati, Robert Emmerich, Pooyan Safari, Colja Schubert, and Jo- hannes K. Fischer. 2024. Experimental dataset for developing and testing ML models in optical communication systems. J. Opt. Commun. Netw.16, 11 (2024), 1. doi:10.1364/JOCN.531788
-
[49]
Ranjan Sapkota, Konstantinos I. Roumeliotis, and Manoj Karkee. 2026. AI Agents vs. Agentic AI: A Conceptual taxonomy, applications and challenges.Inf. Fusion126 (2026), 103599. doi:10.1016/J.INFFUS.2025.103599
-
[50]
SCTY-Inc. 2024. Agentcy 2.0: Multi-Agent Creative Collaboration Platform. https://github.com/SCTY-Inc/agentcy. Accessed: 2025-12-09
2024
-
[51]
SCTY-Inc. 2024. Agentcy: Multi-Agent Creative Collaboration with AutoGen. https://github.com/SCTY-Inc/agentcy. Accessed: 2025-12-22
2024
-
[52]
Rana Muhammad Shahroz, Zhen Tan, Sukwon Yun, Charles Fleming, and Tianlong Chen. 2025. Agents Under Siege: Breaking Pragmatic Multi-Agent LLM Systems with Optimized Prompt Attacks. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2025, Vienna, Austria, July 27 - August 1, 2025, Wanxiang...
2025
-
[53]
Yuchen Shao, Yuheng Huang, Jiawei Shen, Lei Ma, Ting Su, and Chengcheng Wan. 2025. Are LLMs Correctly Integrated into Software Systems?(ICSE ’25). IEEE Press, 1178âĂŞ1190. doi:10.1109/ICSE55347.2025.00204
-
[54]
Ezekiel Soremekun, Lukas Kirschner, Marcel Böhme, and Andreas Zeller. 2021. Locating faults with program slicing: an empirical analysis.Empirical Software Engineering26, 3 (2021), 51
2021
-
[55]
Antonio Tupek, Mladen Zrinjski, Marko Svaco, and Duro Barkovic. 2023. GNSS Receiver Antenna Absolute Field Calibration System Development: Testing and Preliminary Results.Remote. Sens.15, 18 (2023), 4622. doi:10.3390/ RS15184622
2023
-
[56]
Chengcheng Wan, Shicheng Liu, Sophie Xie, Yifan Liu, Henry Hoffmann, Michael Maire, and Shan Lu. 2022. Automated testing of software that uses machine learning apis. InProceedings of the 44th International Conference on Software Engineering. 212–224
2022
-
[57]
Chengcheng Wan, Shicheng Liu, Sophie Xie, Yifan Liu, Henry Hoffmann, Michael Maire, and Shan Lu. 2022. Automated Testing of Software that Uses Machine Learning APIs. In44th IEEE/ACM 44th International Conference on Software Engineering, ICSE 2022, Pittsburgh, PA, USA, May 25-27, 2022. ACM, 212–224. doi:10.1145/3510003.3510068
-
[58]
Qing Xie and Atif M. Memon. 2007. Designing and comparing automated test oracles for GUI-based software applications.ACM Trans. Softw. Eng. Methodol.16, 1 (Feb. 2007), 4âĂŞes. https://doi.org/10.1145/1189748.1189752
-
[59]
Xiaoyuan Xie, Ying Duan, Songqiang Chen, and Jifeng Xuan. 2022. Towards the robustness of multiple object tracking systems. In2022 IEEE 33rd International Symposium on Software Reliability Engineering (ISSRE). IEEE, 402–413
2022
-
[60]
Rui Ye, Shuo Tang, Rui Ge, Yaxin Du, Zhenfei Yin, Siheng Chen, and Jing Shao. 2025. MAS-GPT: Training LLMs to Build LLM-based Multi-Agent Systems. InForty-second International Conference on Machine Learning. https: //openreview.net/forum?id=3CiSpY3QdZ
2025
-
[61]
Jiahao Yu, Xingwei Lin, Zheng Yu, and Xinyu Xing. 2024. LLM-Fuzzer: Scaling Assessment of Large Language Model Jailbreaks. In33rd USENIX Security Symposium (USENIX Security 24). USENIX Association, Philadelphia, PA, 4657–4674. https://www.usenix.org/conference/usenixsecurity24/presentation/yu-jiahao
2024
-
[62]
Yanwei Yue, Guibin Zhang, Boyang Liu, Guancheng Wan, Kun Wang, Dawei Cheng, and Yiyan Qi. 2025. MasRouter: Learning to Route LLMs for Multi-Agent Systems. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2025, Vienna, Austria, July 27 - August 1, 2025, Wanxiang Che, Joyce Nabende, Ekate...
2025
-
[63]
Michal Zalewski and Google. 2013. American Fuzzy Lop (AFL): a security-oriented fuzzer. https://github.com/google/ AFL. Accessed: 2025-12-11
2013
-
[64]
Qiusi Zhan, Zhixiang Liang, Zifan Ying, and Daniel Kang. 2024. Injecagent: Benchmarking indirect prompt injections in tool-integrated large language model agents.arXiv preprint arXiv:2403.02691(2024)
work page internal anchor Pith review arXiv 2024
-
[65]
Guibin Zhang, Yanwei Yue, Zhixun Li, Sukwon Yun, Guancheng Wan, Kun Wang, Dawei Cheng, Jeffrey Xu Yu, and Tianlong Chen. 2025. Cut the Crap: An Economical Communication Pipeline for LLM-based Multi-Agent Systems. InThe Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025. OpenReview.net. https://openrevi...
2025
-
[66]
Mengshi Zhang, Yuqun Zhang, Lingming Zhang, Cong Liu, and Sarfraz Khurshid. 2018. Deeproad: Gan-based metamorphic testing and input validation framework for autonomous driving systems. InProceedings of the 33rd ACM/IEEE international conference on automated software engineering. 132–142
2018
-
[67]
Wentao Zhang, Lingxuan Zhao, Haochong Xia, Shuo Sun, Jiaze Sun, Molei Qin, Xinyi Li, Yuqing Zhao, Yilei Zhao, Xinyu Cai, Longtao Zheng, Xinrun Wang, and Bo An. 2024. A Multimodal Foundation Agent for Financial Trading: Tool- Augmented, Diversified, and Generalist. InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, KDD ...
-
[68]
Xiaodong Zhang, Zijiang Yang, Qinghua Zheng, Pei Liu, Jialiang Chang, Yu Hao, and Ting Liu. 2017. Automated testing of definition-use data flow for multithreaded programs. In2017 IEEE International Conference on Software Testing, Verification and Validation (ICST). IEEE, 172–183
2017
-
[69]
Zhexin Zhang, Shiyao Cui, Yida Lu, Jingzhuo Zhou, Junxiao Yang, Hongning Wang, and Minlie Huang. 2024. Agent- SafetyBench: Evaluating the Safety of LLM Agents.CoRRabs/2412.14470 (2024). arXiv:2412.14470 doi:10.48550/ARXIV. 2412.14470
work page internal anchor Pith review doi:10.48550/arxiv 2024
-
[70]
Zhexin Zhang, Shiyao Cui, Yida Lu, Jingzhuo Zhou, Junxiao Yang, Hongning Wang, and Minlie Huang. 2024. Agent- safetybench: Evaluating the safety of llm agents.arXiv preprint arXiv:2412.14470(2024)
work page internal anchor Pith review arXiv 2024
-
[71]
Poskitt, Yang Liu, and Zijiang Yang
Yuan Zhou, Yang Sun, Yun Tang, Yuqi Chen, Jun Sun, Christopher M. Poskitt, Yang Liu, and Zijiang Yang. 2023. Specification-Based Autonomous Driving System Testing.IEEE Transactions on Software Engineering49, 6 (2023), 3391–3410. doi:10.1109/TSE.2023.3254142 , Vol. 1, No. 1, Article . Publication date: April 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.