Recognition: 2 theorem links
· Lean TheoremNext-Scale Generative Reranking: A Tree-based Generative Rerank Method at Meituan
Pith reviewed 2026-05-10 19:50 UTC · model grok-4.3
The pith
A tree-based next-scale generator builds recommendation lists from coarse user interests to fine details while aligning training signals at every scale.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
NSGR establishes that a next-scale generator which expands a recommendation list from user interests in a coarse-to-fine tree manner, guided by a multi-scale neighbor loss that supplies scale-specific signals from a tree-based multi-scale evaluator, overcomes the dual problems of missing local-global balance and generator-evaluator goal inconsistency that affect both autoregressive and non-autoregressive generative rerankers.
What carries the argument
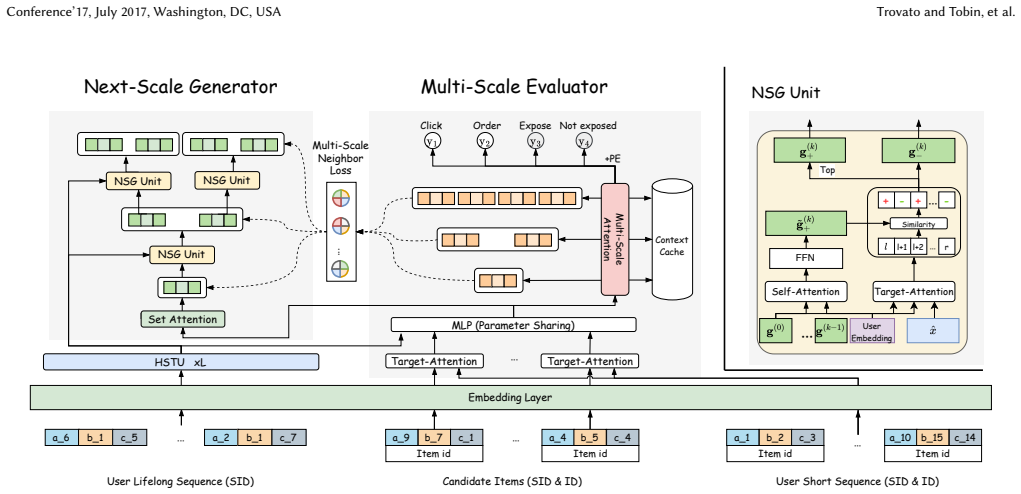
The next-scale generator (NSG) that progressively expands lists scale by scale together with the multi-scale neighbor loss drawn from the tree-based multi-scale evaluator (MSE) at each level.
If this is right
- The generator receives both local item interactions and global list coherence at every expansion step.
- Training guidance becomes consistent across scales instead of conflicting between generator and evaluator.
- The framework scales to industrial volumes as shown by live deployment on the Meituan food delivery platform.
- Effectiveness holds across both public benchmarks and private industrial data.
Where Pith is reading between the lines
- The same coarse-to-fine tree expansion could be tested on other list-generation tasks such as search result ordering or playlist creation where hierarchical context matters.
- If the scales naturally reflect user interest hierarchies, the method might reduce the need for separate context-modeling layers in rerankers.
- One could measure whether adding finer scales beyond the current design yields diminishing returns or requires more training data.
Load-bearing premise
The tree-based multi-scale structure and neighbor loss actually supply independent local and global signals without introducing new inconsistencies or requiring extensive post-hoc tuning.
What would settle it
An ablation that removes either the tree structure or the multi-scale neighbor loss and shows no measurable drop in ranking metrics such as NDCG or click-through rate on the same public and Meituan datasets would falsify the claim.
Figures





read the original abstract
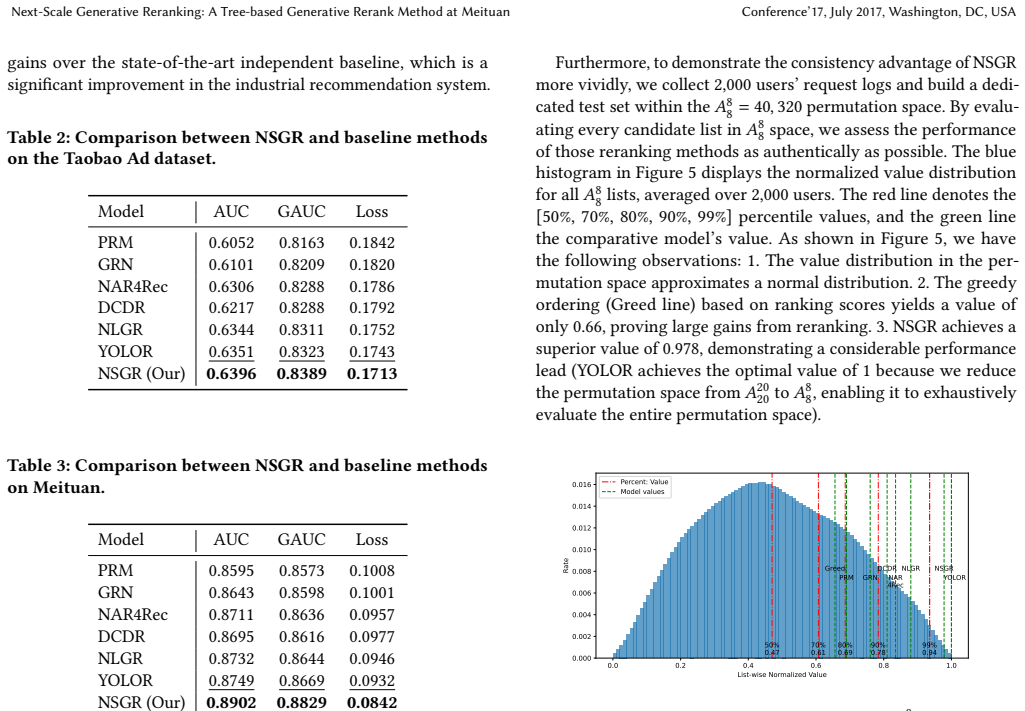
In modern multi-stage recommendation systems, reranking plays a critical role by modeling contextual information. Due to inherent challenges such as the combinatorial space complexity, an increasing number of methods adopt the generative paradigm: the generator produces the optimal list during inference, while an evaluator guides the generator's optimization during the training phase. However, these methods still face two problems. Firstly, these generators fail to produce optimal generation results due to the lack of both local and global perspectives, regardless of whether the generation strategy is autoregressive or non-autoregressive. Secondly, the goal inconsistency problem between the generator and the evaluator during training complicates the guidance signal and leading to suboptimal performance. To address these issues, we propose the \textbf{N}ext-\textbf{S}cale \textbf{G}eneration \textbf{R}eranking (NSGR), a tree-based generative framework. Specifically, we introduce a next-scale generator (NSG) that progressively expands a recommendation list from user interests in a coarse-to-fine manner, balancing global and local perspectives. Furthermore, we design a multi-scale neighbor loss, which leverages a tree-based multi-scale evaluator (MSE) to provide scale-specific guidance to the NSG at each scale. Extensive experiments on public and industrial datasets validate the effectiveness of NSGR. And NSGR has been successfully deployed on the Meituan food delivery platform.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Next-Scale Generative Reranking (NSGR), a tree-based generative reranking framework for multi-stage recommendation systems. It identifies two limitations in prior generative rerankers: generators that lack simultaneous local and global perspectives (autoregressive or non-autoregressive) and goal inconsistency between generator and evaluator during training. NSGR introduces a Next-Scale Generator (NSG) that expands lists in a coarse-to-fine tree traversal from user interests and a multi-scale neighbor loss that employs a tree-based Multi-Scale Evaluator (MSE) to supply scale-specific guidance. The authors state that extensive experiments on public and industrial datasets confirm effectiveness and that NSGR has been deployed on the Meituan food delivery platform.
Significance. If the empirical gains and the claimed independence of local/global signals are substantiated, the work would offer a concrete architectural pattern for incorporating multi-scale structure into generative reranking, potentially improving both optimization stability and list quality in contextual recommendation. The reported production deployment on a large-scale platform constitutes a practical strength that is uncommon in purely academic IR papers and would strengthen the case for real-world impact.
major comments (2)
- [Abstract] Abstract: the statement that 'extensive experiments validate the effectiveness' and that NSGR 'has been successfully deployed' is unsupported by any reported metrics, ablation tables, baseline comparisons, or error analysis, rendering the central effectiveness claim impossible to assess from the provided evidence.
- [§4] §4 (multi-scale neighbor loss): the claim that the tree-based MSE supplies independent local and global signals while eliminating goal inconsistency rests on the unproven assumption that scale-specific loss terms are orthogonal and produce no cross-scale gradient conflicts; no derivation, orthogonality argument, or bounded-interference analysis is supplied, which is load-bearing for the resolution of both stated problems.
minor comments (2)
- The first use of the acronyms NSG and MSE should be accompanied by explicit definitions rather than relying on the expanded forms alone.
- The description of the tree traversal in the NSG would benefit from a small illustrative diagram or pseudocode to clarify the coarse-to-fine expansion process.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive comments on our manuscript. We address each major comment below and have revised the manuscript to incorporate the feedback where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract: the statement that 'extensive experiments validate the effectiveness' and that NSGR 'has been successfully deployed' is unsupported by any reported metrics, ablation tables, baseline comparisons, or error analysis, rendering the central effectiveness claim impossible to assess from the provided evidence.
Authors: We agree that the abstract would benefit from greater specificity to allow readers to immediately assess the strength of the claims. The full manuscript contains detailed experimental results in Section 5 (including baseline comparisons, ablation studies, and error analysis on public and industrial datasets) and deployment details in Section 6. In the revised manuscript, we have updated the abstract to include key quantitative improvements (e.g., relative gains on public benchmarks and the industrial dataset) and a concise reference to the production deployment outcomes, while remaining within typical abstract length limits. revision: yes
-
Referee: [§4] §4 (multi-scale neighbor loss): the claim that the tree-based MSE supplies independent local and global signals while eliminating goal inconsistency rests on the unproven assumption that scale-specific loss terms are orthogonal and produce no cross-scale gradient conflicts; no derivation, orthogonality argument, or bounded-interference analysis is supplied, which is load-bearing for the resolution of both stated problems.
Authors: We acknowledge that the original manuscript does not contain a formal derivation proving orthogonality of the scale-specific loss terms or a bounded analysis of potential cross-scale gradient interference. The multi-scale neighbor loss is motivated by the hierarchical tree structure of NSG, where each scale operates on progressively refined candidate lists and the MSE provides guidance at the corresponding granularity; this design aims to align training signals without explicit cross-scale conflicts. We provide supporting empirical evidence via ablation studies showing stable convergence and additive gains from each scale term. In the revision, we have expanded §4 with a dedicated discussion paragraph explaining the rationale for scale independence based on the coarse-to-fine traversal and added further ablation results isolating the contribution of individual loss terms. A complete theoretical proof remains challenging given the non-convex optimization landscape, but the added material strengthens the justification for the claimed benefits. revision: partial
Circularity Check
NSGR presented as architectural proposal with no self-referential derivations or fitted predictions
full rationale
The paper proposes NSGR as a new tree-based generative reranking framework that uses a next-scale generator (NSG) for coarse-to-fine list expansion and a multi-scale neighbor loss with a tree-based multi-scale evaluator (MSE) to address local/global perspectives and generator-evaluator inconsistency. No equations, parameter-fitting procedures, or self-citations are described that reduce claimed improvements to quantities defined by the same evaluation data or by construction. The method is introduced at the level of architecture and loss design, with validation via experiments on public and industrial datasets plus real-world deployment. This qualifies as a self-contained proposal against external benchmarks, with no load-bearing steps that collapse to the inputs.
Axiom & Free-Parameter Ledger
free parameters (1)
- number of scales
axioms (1)
- domain assumption Combinatorial space complexity prevents direct optimization of the full list
invented entities (2)
-
next-scale generator (NSG)
no independent evidence
-
multi-scale evaluator (MSE)
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking (D=3 from 2^D=8) echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
next-scale generator (NSG) that progressively expands a recommendation list from user interests in a coarse-to-fine manner... 'one-generates-two, two-generate-four' pattern... K=log2 m steps
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel (J-cost uniqueness) unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
multi-scale neighbor loss... scale-specific guidance to the NSG at each scale
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[2]
Qingyao Ai, Keping Bi, Jiafeng Guo, and W Bruce Croft. 2018. Learning a deep listwise context model for ranking refinement. InThe 41st international ACM SIGIR conference on research & development in information retrieval. 135–144
2018
- [3]
- [4]
-
[5]
Christopher JC Burges. 2010. From ranknet to lambdarank to lambdamart: An overview.Learning11, 23-581 (2010), 81
2010
-
[6]
Zhe Cao, Tao Qin, Tie-Yan Liu, Ming-Feng Tsai, and Hang Li. 2007. Learning to rank: from pairwise approach to listwise approach. InProceedings of the 24th international conference on Machine learning. 129–136
2007
-
[7]
Moses S Charikar. 2002. Similarity estimation techniques from rounding algo- rithms. InProceedings of the thiry-fourth annual ACM symposium on Theory of computing. 380–388
2002
-
[8]
Chi Chen, Hui Chen, Kangzhi Zhao, Junsheng Zhou, Li He, Hongbo Deng, Jian Xu, Bo Zheng, Yong Zhang, and Chunxiao Xing. 2022. EXTR: Click-Through Rate Prediction with Externalities in E-Commerce Sponsored Search. InProceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 2732–2740
2022
-
[9]
Qiwei Chen, Changhua Pei, Shanshan Lv, Chao Li, Junfeng Ge, and Wenwu Ou
-
[10]
End-to-end user behavior retrieval in click-through rateprediction model. arXiv preprint arXiv:2108.04468(2021)
-
[11]
Heng-Tze Cheng, Levent Koc, Jeremiah Harmsen, Tal Shaked, Tushar Chandra, Hrishi Aradhye, Glen Anderson, Greg Corrado, Wei Chai, Mustafa Ispir, et al
-
[12]
InProceedings of the 1st workshop on deep learning for recommender systems
Wide & deep learning for recommender systems. InProceedings of the 1st workshop on deep learning for recommender systems. 7–10
- [13]
- [14]
- [15]
-
[16]
Yupeng Hou, Jiacheng Li, Ashley Shin, Jinsung Jeon, Abhishek Santhanam, Wei Shao, Kaveh Hassani, Ning Yao, and Julian McAuley. 2025. Generating long semantic IDs in parallel for recommendation. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 2. 956–966
2025
-
[17]
Yanhua Huang, Weikun Wang, Lei Zhang, and Ruiwen Xu. 2021. Sliding spectrum decomposition for diversified recommendation. InProceedings of the 27th ACM SIGKDD conference on knowledge discovery & data mining. 3041–3049
2021
- [18]
-
[19]
Jianxun Lian, Xiaohuan Zhou, Fuzheng Zhang, Zhongxia Chen, Xing Xie, and Guangzhong Sun. 2018. xdeepfm: Combining explicit and implicit feature in- teractions for recommender systems. InProceedings of the 24th ACM SIGKDD international conference on knowledge discovery & data mining. 1754–1763
2018
-
[20]
Xiao Lin, Xiaokai Chen, Chenyang Wang, Hantao Shu, Linfeng Song, Biao Li, and Peng Jiang. 2024. Discrete conditional diffusion for reranking in recommendation. InCompanion Proceedings of the ACM on Web Conference 2024. 161–169
2024
-
[21]
Zhijie Lin, Zhuofeng Li, Chenglei Dai, Wentian Bao, Shuai Lin, Enyun Yu, Haoxi- ang Zhang, and Liang Zhao. 2025. GReF: A Unified Generative Framework for Efficient Reranking via Ordered Multi-token Prediction. InProceedings of the 34th ACM International Conference on Information and Knowledge Management. 5879–5887
2025
-
[22]
Zihan Lin, Hui Wang, Jingshu Mao, Wayne Xin Zhao, Cheng Wang, Peng Jiang, and Ji-Rong Wen. 2022. Feature-aware diversified re-ranking with disentangled representations for relevant recommendation. InProceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 3327–3335
2022
-
[23]
Shuchang Liu, Qingpeng Cai, Zhankui He, Bowen Sun, Julian McAuley, Dong Zheng, Peng Jiang, and Kun Gai. 2023. Generative flow network for listwise rec- ommendation. InProceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 1524–1534
2023
-
[24]
Gurmeet Singh Manku, Arvind Jain, and Anish Das Sarma. 2007. Detecting near- duplicates for web crawling. InProceedings of the 16th international conference on World Wide Web. 141–150
2007
-
[25]
Liang Pang, Jun Xu, Qingyao Ai, Yanyan Lan, Xueqi Cheng, and Jirong Wen
-
[26]
InProceedings of the 43rd international ACM SIGIR conference on research and development in information retrieval
Setrank: Learning a permutation-invariant ranking model for information retrieval. InProceedings of the 43rd international ACM SIGIR conference on research and development in information retrieval. 499–508
-
[27]
Changhua Pei, Yi Zhang, Yongfeng Zhang, Fei Sun, Xiao Lin, Hanxiao Sun, Jian Wu, Peng Jiang, Junfeng Ge, Wenwu Ou, et al. 2019. Personalized re-ranking for recommendation. InProceedings of the 13th ACM conference on recommender systems. 3–11
2019
-
[28]
Qi Pi, Guorui Zhou, Yujing Zhang, Zhe Wang, Lejian Ren, Ying Fan, Xiaoqiang Zhu, and Kun Gai. 2020. Search-based user interest modeling with lifelong sequential behavior data for click-through rate prediction. InProceedings of the 29th ACM International Conference on Information & Knowledge Management. 2685–2692
2020
-
[29]
Shashank Rajput, Nikhil Mehta, Anima Singh, Raghunandan Hulikal Keshavan, Trung Vu, Lukasz Heldt, Lichan Hong, Yi Tay, Vinh Tran, Jonah Samost, et al
-
[30]
Information Processing Systems36 (2023), 10299–10315
Recommender systems with generative retrieval.Advances in Neural Conference’17, July 2017, Washington, DC, USA Trovato and Tobin, et al. Information Processing Systems36 (2023), 10299–10315
2017
-
[31]
Yuxin Ren, Qiya Yang, Yichun Wu, Wei Xu, Yalong Wang, and Zhiqiang Zhang
-
[32]
In Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining
Non-autoregressive generative models for reranking recommendation. In Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 5625–5634
-
[33]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. 2024. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[34]
Xiaowen Shi, Fan Yang, Ze Wang, Xiaoxu Wu, Muzhi Guan, Guogang Liao, Wang Yongkang, Xingxing Wang, and Dong Wang. 2023. PIER: Permutation-Level Interest-Based End-to-End Re-ranking Framework in E-commerce. InProceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 4823–4831
2023
-
[35]
A Vaswani. 2017. Attention is all you need.Advances in Neural Information Processing Systems(2017)
2017
- [36]
-
[37]
Shuli Wang, Xue Wei, Senjie Kou, Chi Wang, Wenshuai Chen, Qi Tang, Yinhua Zhu, Xiong Xiao, and Xingxing Wang. 2025. NLGR: Utilizing Neighbor Lists for Generative Rerank in Personalized Recommendation Systems. InCompanion Proceedings of the ACM on Web Conference 2025. 530–537
2025
- [38]
-
[39]
Yunjia Xi, Weiwen Liu, Jieming Zhu, Xilong Zhao, Xinyi Dai, Ruiming Tang, Weinan Zhang, Rui Zhang, and Yong Yu. 2022. Multi-Level Interaction Reranking with User Behavior History. InProceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval. 1336–1346
2022
-
[40]
Wencai Ye, Mingjie Sun, Shaoyun Shi, Peng Wang, Wenjin Wu, and Peng Jiang
- [41]
-
[42]
Jiaqi Zhai, Lucy Liao, Xing Liu, Yueming Wang, Rui Li, Xuan Cao, Leon Gao, Zhao- jie Gong, Fangda Gu, Michael He, et al. 2024. Actions speak louder than words: Trillion-parameter sequential transducers for generative recommendations.arXiv preprint arXiv:2402.17152(2024)
work page internal anchor Pith review arXiv 2024
-
[43]
Guorui Zhou, Na Mou, Ying Fan, Qi Pi, Weijie Bian, Chang Zhou, Xiaoqiang Zhu, and Kun Gai. 2019. Deep interest evolution network for click-through rate prediction. InProceedings of the AAAI conference on artificial intelligence, Vol. 33. 5941–5948
2019
-
[44]
Guorui Zhou, Xiaoqiang Zhu, Chenru Song, Ying Fan, Han Zhu, Xiao Ma, Yanghui Yan, Junqi Jin, Han Li, and Kun Gai. 2018. Deep interest network for click-through rate prediction. InProceedings of the 24th ACM SIGKDD international conference on knowledge discovery & data mining. 1059–1068
2018
- [46]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.