Recognition: 2 theorem links
· Lean TheoremIndoor Asset Detection in Large Scale 360{deg} Drone-Captured Imagery via 3D Gaussian Splatting
Pith reviewed 2026-05-10 18:34 UTC · model grok-4.3
The pith
A 3D object codebook merges multi-view 2D masks into coherent indoor asset detections within Gaussian Splatting scenes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
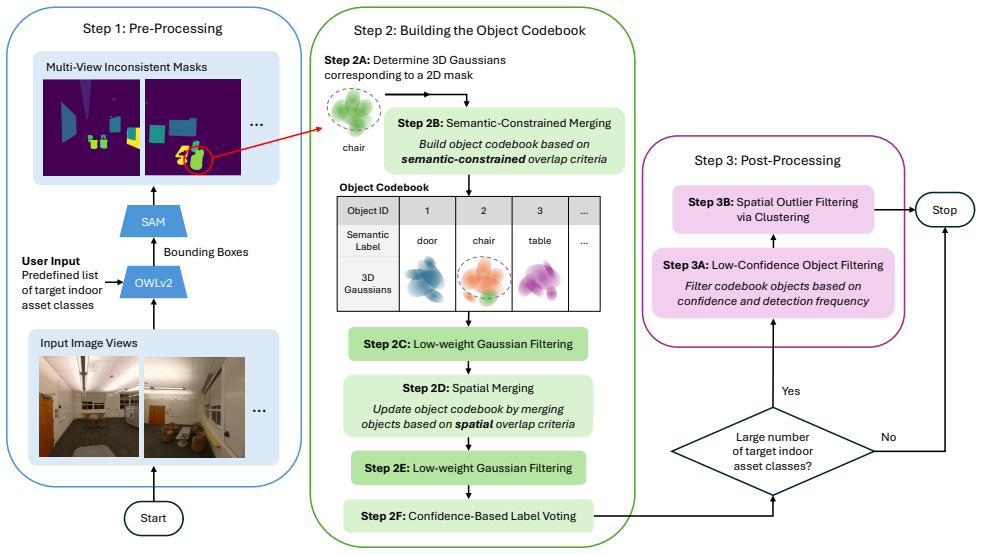
We present an approach for object-level detection and segmentation of target indoor assets in 3D Gaussian Splatting scenes, reconstructed from 360 degree drone-captured imagery. We introduce a 3D object codebook that jointly leverages mask semantics and spatial information of their corresponding Gaussian primitives to guide multi-view mask association and indoor asset detection. By integrating 2D object detection and segmentation models with semantically and spatially constrained merging procedures, our method aggregates masks from multiple views into coherent 3D object instances. Experiments on two large indoor scenes demonstrate reliable multi-view mask consistency, improving F1 score by
What carries the argument
The 3D object codebook, which jointly uses mask semantics and spatial locations of Gaussian primitives to associate and merge detections across multiple views into single 3D instances.
If this is right
- Multi-view mask consistency becomes reliable across large indoor environments.
- F1 score for mask association rises by 65 percent relative to prior baselines.
- Object-level 3D detection accuracy increases by 11 percent in mean average precision.
- Scattered 2D masks from different drone angles combine into single coherent 3D asset instances.
Where Pith is reading between the lines
- The same merging logic could be tested on outdoor scenes to check whether spatial constraints still reduce inconsistencies when lighting and backgrounds vary more.
- If the codebook is made incremental, the approach might support repeated drone flights over the same space to update asset locations over time.
- Neighbouring tasks such as semantic mapping for robot path planning could directly consume the produced 3D instances without extra post-processing.
Load-bearing premise
That 2D object detection and segmentation models can be integrated with semantically and spatially constrained merging procedures through the 3D object codebook to form coherent 3D instances without major inconsistencies in large-scale scenes.
What would settle it
Running the full pipeline on additional large indoor scenes and measuring whether the reported F1 score gains and mAP improvements hold, or whether many objects end up incorrectly split or merged in the final 3D output.
Figures





read the original abstract
We present an approach for object-level detection and segmentation of target indoor assets in 3D Gaussian Splatting (3DGS) scenes, reconstructed from 360{\deg} drone-captured imagery. We introduce a 3D object codebook that jointly leverages mask semantics and spatial information of their corresponding Gaussian primitives to guide multi-view mask association and indoor asset detection. By integrating 2D object detection and segmentation models with semantically and spatially constrained merging procedures, our method aggregates masks from multiple views into coherent 3D object instances. Experiments on two large indoor scenes demonstrate reliable multi-view mask consistency, improving F1 score by 65% over state-of-the-art baselines, and accurate object-level 3D indoor asset detection, achieving an 11% mAP gain over baseline methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a method for object-level detection and segmentation of indoor assets in 3D Gaussian Splatting (3DGS) scenes reconstructed from 360° drone-captured imagery. It introduces a 3D object codebook that integrates semantic mask information with spatial details from Gaussian primitives to facilitate multi-view mask association and merging. By combining 2D detection and segmentation models with constrained merging, the approach aggregates multi-view masks into consistent 3D object instances. Evaluation on two large indoor scenes shows a 65% improvement in F1 score for mask consistency and an 11% gain in mAP for 3D asset detection compared to state-of-the-art baselines.
Significance. If validated, this approach could advance 3D scene understanding and asset detection in large-scale indoor environments by exploiting the explicit 3D structure in Gaussian splatting representations. The use of a codebook for enforcing consistency across views addresses a key challenge in multi-view 3D object detection, potentially improving reliability over purely 2D methods. The quantitative gains suggest applicability to practical drone-based inspection tasks.
major comments (3)
- Section 3.2: The construction of the 3D object codebook is described at a conceptual level; specific details on how spatial Gaussian primitive information is encoded and used in the merging procedure are needed to assess whether the claimed multi-view consistency is achieved beyond what independent 2D models provide.
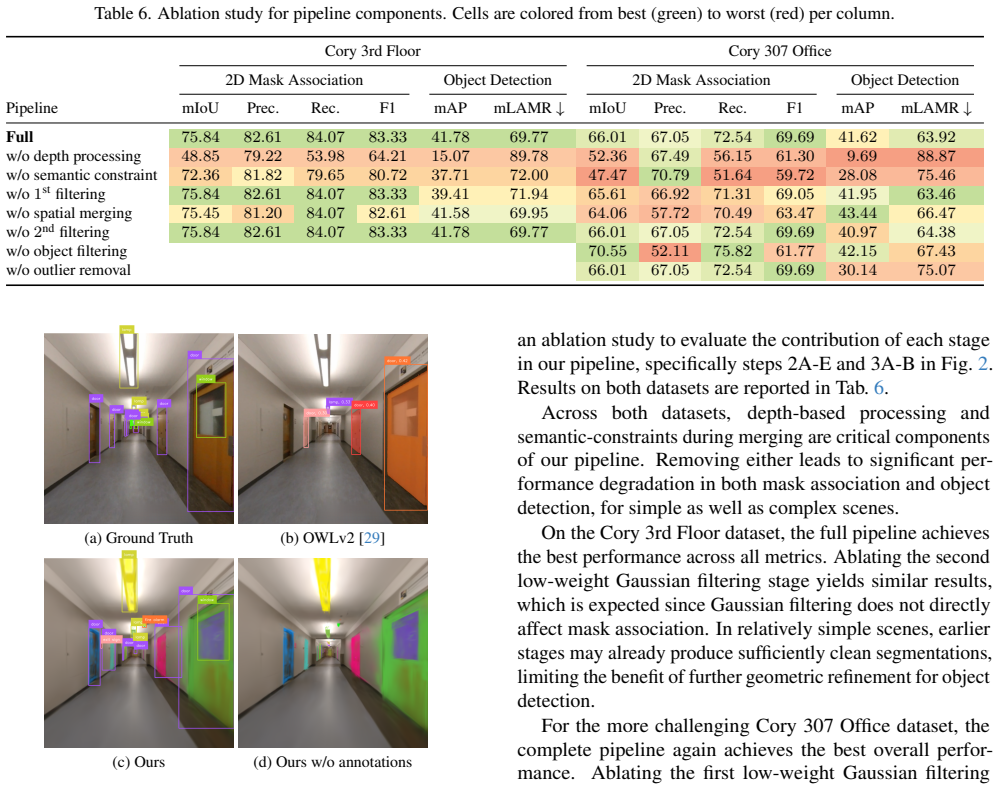
- Section 5: The experimental evaluation is limited to two scenes; while the reported 65% F1 and 11% mAP improvements are promising, additional ablation studies on the contribution of semantic vs. spatial constraints would strengthen the attribution of gains to the proposed codebook.
- Section 4.3: The merging procedures' handling of inconsistencies in large-scale scenes is not quantified with failure cases or error analysis, which is critical given the assumption that constrained merging produces coherent 3D instances without significant issues.
minor comments (2)
- Abstract: The abstract mentions 'state-of-the-art baselines' without naming them; specifying the baselines would improve clarity.
- Figure 3: Ensure that visualizations of 3D instances clearly distinguish between input 2D masks and final merged 3D objects.
Simulated Author's Rebuttal
We thank the referee for the positive recommendation of minor revision and the constructive comments. We address each major comment below and will incorporate the necessary clarifications and additions into the revised manuscript.
read point-by-point responses
-
Referee: Section 3.2: The construction of the 3D object codebook is described at a conceptual level; specific details on how spatial Gaussian primitive information is encoded and used in the merging procedure are needed to assess whether the claimed multi-view consistency is achieved beyond what independent 2D models provide.
Authors: We thank the referee for this observation. We acknowledge that Section 3.2 is presented at a conceptual level in the current manuscript. In the revision, we will expand this section with explicit details on the encoding process: Gaussian primitive attributes (3D means, covariance matrices, opacities, and view-dependent features) will be aggregated per mask into fixed-dimensional vectors for the codebook. We will also specify the merging procedure, including the combined semantic-spatial distance metric and the constrained association algorithm that enforces multi-view consistency. revision: yes
-
Referee: Section 5: The experimental evaluation is limited to two scenes; while the reported 65% F1 and 11% mAP improvements are promising, additional ablation studies on the contribution of semantic vs. spatial constraints would strengthen the attribution of gains to the proposed codebook.
Authors: We agree that targeted ablations would better isolate the contributions. In the revised manuscript, we will add ablation experiments in Section 5. These will evaluate the full codebook against variants using only semantic constraints and only spatial constraints, reporting the resulting F1 and mAP on both scenes to quantify the incremental benefit of each component. revision: yes
-
Referee: Section 4.3: The merging procedures' handling of inconsistencies in large-scale scenes is not quantified with failure cases or error analysis, which is critical given the assumption that constrained merging produces coherent 3D instances without significant issues.
Authors: This is a fair point. We will revise Section 4.3 to include a dedicated error analysis. The update will report quantitative measures of merging inconsistencies (e.g., over- and under-merging rates) across the two scenes, along with representative failure-case visualizations and a discussion of how the semantic and spatial constraints reduce such issues. revision: yes
Circularity Check
No significant circularity; purely empirical method
full rationale
The paper presents an empirical pipeline for 3D indoor asset detection that integrates off-the-shelf 2D detectors with a custom merging procedure based on a 3D object codebook. No equations, derivations, fitted parameters, or self-referential predictions appear in the abstract or described method. Performance claims (F1 and mAP gains) are reported as direct experimental outcomes on two external scenes against independent baselines, with no load-bearing step that reduces to a self-definition, self-citation chain, or input renaming. The work is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
invented entities (1)
-
3D object codebook
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We introduce a 3D object codebook that jointly leverages mask semantics and spatial information of their corresponding Gaussian primitives to guide multi-view mask association and indoor asset detection.
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanembed_injective unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Semantic-Constrained Merging... overlap between G(m) and Gi exceeds a predefined threshold τ_overlap
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
PyTorch 2: Faster Machine Learning Through Dynamic Python Bytecode Transformation and Graph Compilation
Jason Ansel, Edward Yang, Horace He, Natalia Gimelshein, Animesh Jain, Michael V oznesensky, Bin Bao, Peter Bell, David Berard, Evgeni Burovski, Geeta Chauhan, Anjali Chourdia, Will Constable, Alban Desmaison, Zachary DeVito, Elias Ellison, Will Feng, Jiong Gong, Michael Gschwind, Brian Hirsh, Sherlock Huang, Kshiteej Kalambarkar, Laurent Kirsch, Michael ...
2024
-
[2]
Kevin Arvai. kneed. https://github.com/arvkevi/ kneed, 2018. 5
2018
-
[3]
Barron, Ben Mildenhall, Matthew Tancik, Peter Hedman, Ricardo Martin-Brualla, and Pratul P
Jonathan T. Barron, Ben Mildenhall, Matthew Tancik, Peter Hedman, Ricardo Martin-Brualla, and Pratul P. Srinivasan. Mip-nerf: A multiscale representation for anti-aliasing neural radiance fields. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 5855–5864,
-
[4]
Barron, Ben Mildenhall, Dor Verbin, Pratul P
Jonathan T. Barron, Ben Mildenhall, Dor Verbin, Pratul P. Srinivasan, and Peter Hedman. Mip-nerf 360: Unbounded anti-aliased neural radiance fields. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 5470–5479, 2022. 1
2022
-
[5]
The devil is in the fine-grained details: Evaluating open-vocabulary object detectors for fine- grained understanding
Lorenzo Bianchi, Fabio Carrara, Nicola Messina, Claudio Gennaro, and Fabrizio Falchi. The devil is in the fine-grained details: Evaluating open-vocabulary object detectors for fine- grained understanding. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22520–22529, 2024. 2
2024
-
[6]
Nerf2real: Sim2real transfer of vision- guided bipedal motion skills using neural radiance fields,
Arunkumar Byravan, Jan Humplik, Leonard Hasenclever, Arthur Brussee, Francesco Nori, Tuomas Haarnoja, Ben Moran, Steven Bohez, Fereshteh Sadeghi, Bojan Vujatovic, and Nicolas Heess. Nerf2real: Sim2real transfer of vision- guided bipedal motion skills using neural radiance fields,
-
[7]
Jiazhong Cen, Jiemin Fang, Chen Yang, Lingxi Xie, Xiaopeng Zhang, Wei Shen, and Qi Tian. Segment any 3d gaussians. arXiv preprint arXiv:2312.00860, 2023. 2
-
[8]
Scalable indoor novel-view synthesis using drone-captured 360 imagery with 3d gaussian splatting
Yuanbo Chen, Chengyu Zhang, Jason Wang, Xuefan Gao, and Avideh Zakhor. Scalable indoor novel-view synthesis using drone-captured 360 imagery with 3d gaussian splatting. InEuropean Conference on Computer Vision, pages 51–67. Springer, 2024. 1, 5
2024
-
[9]
Tracking anything with de- coupled video segmentation
Ho Kei Cheng, Seoung Wug Oh, Brian Price, Alexander Schwing, and Joon-Young Lee. Tracking anything with de- coupled video segmentation. InICCV, 2023. 2
2023
-
[10]
Croce, G
V . Croce, G. Caroti, L. De Luca, A. Piemonte, and P. V´eron. Neural radiance fields (nerf): Review and potential applica- tions to digital cultural heritage.The International Archives of the Photogrammetry, Remote Sensing and Spatial Information Sciences, XLVIII-M-2-2023:453–460, 2023. 1
2023
-
[11]
Computer Vision Annotation Tool (CV AT), 2023
CV AT.ai Corporation. Computer Vision Annotation Tool (CV AT), 2023. 6
2023
-
[12]
Fov- nerf: Foveated neural radiance fields for virtual reality.IEEE Transactions on Visualization and Computer Graphics, 28 (11):3854–3864, 2022
Nianchen Deng, Zhenyi He, Jiannan Ye, Budmonde Duinkhar- jav, Praneeth Chakravarthula, Xubo Yang, and Qi Sun. Fov- nerf: Foveated neural radiance fields for virtual reality.IEEE Transactions on Visualization and Computer Graphics, 28 (11):3854–3864, 2022. 1
2022
-
[13]
A density-based algorithm for discovering clusters in large spatial databases with noise
Martin Ester, Hans-Peter Kriegel, J¨org Sander, Xiaowei Xu, et al. A density-based algorithm for discovering clusters in large spatial databases with noise. Inkdd, pages 226–231,
-
[14]
A bim- oriented model for supporting indoor navigation requirements
Umit Isikdag, Sisi Zlatanova, and Jason Underwood. A bim- oriented model for supporting indoor navigation requirements. Computers, Environment and Urban Systems, 41:112–123,
-
[15]
6: Simultaneous tracking, tagging and mapping for augmented reality
Yixiao Kang, Yiyang Xu, Chao Ping Chen, Gang Li, and Ziyao Cheng. 6: Simultaneous tracking, tagging and mapping for augmented reality. InSID Symposium Digest of Technical Papers, pages 31–33. Wiley Online Library, 2021. 1
2021
-
[16]
Micro and macro quadcopter drones for indoor mapping to support disaster management
S Karam, F Nex, O Karlsson, J Rydell, E Bilock, M Tulldahl, M Holmberg, and N Kerle. Micro and macro quadcopter drones for indoor mapping to support disaster management. ISPRS Annals of the Photogrammetry, Remote Sensing and Spatial Information Sciences, 1:203–210, 2022. 1
2022
-
[17]
3d gaussian splatting for real-time radiance field rendering.ACM Transactions on Graphics, 42(4), 2023
Bernhard Kerbl, Georgios Kopanas, Thomas Leimk¨uhler, and George Drettakis. 3d gaussian splatting for real-time radiance field rendering.ACM Transactions on Graphics, 42(4), 2023. 1, 2, 6
2023
-
[18]
Segment any- thing
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer White- head, Alexander C Berg, Wan-Yen Lo, et al. Segment any- thing. InProceedings of the IEEE/CVF international con- ference on computer vision, pages 4015–4026, 2023. 2, 5, 6
2023
-
[19]
Scal- able mav indoor reconstruction with neural implicit surfaces
Haoda Li, Puyuan Yi, Yunhao Liu, and Avideh Zakhor. Scal- able mav indoor reconstruction with neural implicit surfaces. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 1544–1552, 2023. 1
2023
-
[20]
Exploring plain vision transformer backbones for object de- tection, 2022
Yanghao Li, Hanzi Mao, Ross Girshick, and Kaiming He. Exploring plain vision transformer backbones for object de- tection, 2022. 6
2022
-
[21]
Yangze Liang, Yuhui Xia, Mina Merzouk, and Zhao Xu. From image to fire safety: An image-driven framework for as-is bim reconstruction and fire risk assessment of existing buildings via semantic guidance.Developments in the Built Environ- ment, page 100869, 2026. 1
2026
-
[22]
Op- timized language-embedded 3dgs for realistic modeling and information storage of historical buildings
Zhenyu Liang, Jeff Chak Fu Chan, Jiaying Zhang, Zhaolun Liang, Boyu Wang, Mingzhu Wang, and Jack CP Cheng. Op- timized language-embedded 3dgs for realistic modeling and information storage of historical buildings. InProceedings of The Sixth International Confer, pages 601–611, 2025. 1
2025
-
[23]
Semantic gaussian splatting-enhanced facility management within the framework of ifc-graph
Jiucai Liu, Haijiang Li, and Ali Khudhair. Semantic gaussian splatting-enhanced facility management within the framework of ifc-graph. 2025. 1
2025
-
[24]
Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection
Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Chunyuan Li, Jianwei Yang, Hang Su, Jun Zhu, et al. Grounding dino: Marrying dino with grounded pre-training for open-set object detection.arXiv preprint arXiv:2303.05499, 2023. 2
work page Pith review arXiv 2023
-
[25]
Differential gaussian rasterization with depth
Jonathan Luiten. Differential gaussian rasterization with depth. https://github.com/JonathonLuiten/ diff-gaussian-rasterization-w-depth , 2023. 3
2023
-
[26]
Dynamic 3d gaussians: Tracking by persistent dynamic view synthesis
Jonathon Luiten, Georgios Kopanas, Bastian Leibe, and Deva Ramanan. Dynamic 3d gaussians: Tracking by persistent dynamic view synthesis. In3DV, 2024. 3
2024
-
[27]
Gaga: Group any gaussians via 3d-aware memory bank, 2024
Weijie Lyu, Xueting Li, Abhijit Kundu, Yi-Hsuan Tsai, and Ming-Hsuan Yang. Gaga: Group any gaussians via 3d-aware memory bank, 2024. 1, 2, 3, 4, 6, 7
2024
-
[28]
A hybrid approach to hierarchical density-based cluster selection
Claudia Malzer and Marcus Baum. A hybrid approach to hierarchical density-based cluster selection. In2020 IEEE International Conference on Multisensor Fusion and Integra- tion for Intelligent Systems (MFI), page 223–228. IEEE, 2020. 5
2020
-
[29]
Scaling open-vocabulary object detection.NeurIPS, 2023
Neil Houlsby Matthias Minderer, Alexey Gritsenko. Scaling open-vocabulary object detection.NeurIPS, 2023. 2, 5, 6, 7, 8
2023
-
[30]
Mehraban, Shayan Mirzabeigi, Mudan Wang, Rui Liu, and Samad M
Mohammad H. Mehraban, Shayan Mirzabeigi, Mudan Wang, Rui Liu, and Samad M. E. Sepasgozar. Automated image-to- bim using neural radiance fields and vision-language semantic modeling.Buildings, 15(24), 2025. 1
2025
-
[31]
Srinivasan, Matthew Tancik, Jonathan T
Ben Mildenhall, Pratul P. Srinivasan, Matthew Tancik, Jonathan T. Barron, Ravi Ramamoorthi, and Ren Ng. Nerf: Representing scenes as neural radiance fields for view synthe- sis. InECCV, 2020. 1
2020
-
[32]
Ad- vancing extended reality with 3d gaussian splatting: Innova- tions and prospects
Shi Qiu, Binzhu Xie, Qixuan Liu, and Pheng-Ann Heng. Ad- vancing extended reality with 3d gaussian splatting: Innova- tions and prospects. In2025 IEEE International Conference on Artificial Intelligence and eXtended and Virtual Reality (AIxVR), pages 203–208. IEEE, 2025. 1
2025
-
[33]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. InProceedings of the 38th International Conference on Machine Learning, pages 8748–8763. PMLR, 2021. 6
2021
-
[34]
Grounded sam: Assembling open-world models for diverse visual tasks, 2024
Tianhe Ren, Shilong Liu, Ailing Zeng, Jing Lin, Kunchang Li, He Cao, Jiayu Chen, Xinyu Huang, Yukang Chen, Feng Yan, Zhaoyang Zeng, Hao Zhang, Feng Li, Jie Yang, Hongyang Li, Qing Jiang, and Lei Zhang. Grounded sam: Assembling open-world models for diverse visual tasks, 2024. 2
2024
-
[35]
Density-based clustering in spatial databases: The algo- rithm gdbscan and its applications.Data mining and knowl- edge discovery, 2(2):169–194, 1998
J¨org Sander, Martin Ester, Hans-Peter Kriegel, and Xiaowei Xu. Density-based clustering in spatial databases: The algo- rithm gdbscan and its applications.Data mining and knowl- edge discovery, 2(2):169–194, 1998. 5
1998
-
[36]
Finding a” kneedle” in a haystack: Detecting knee points in system behavior
Ville Satopaa, Jeannie Albrecht, David Irwin, and Barath Raghavan. Finding a” kneedle” in a haystack: Detecting knee points in system behavior. In2011 31st international con- ference on distributed computing systems workshops, pages 166–171. IEEE, 2011. 5
2011
-
[37]
Structure-from-Motion Revisited
Johannes Lutz Sch ¨onberger and Jan-Michael Frahm. Structure-from-Motion Revisited. InConference on Com- puter Vision and Pattern Recognition (CVPR), 2016. 5, 6
2016
-
[38]
Evaluating radiance field-inspired methods for 3d indoor re- construction: A comparative analysis.Buildings, 15(6), 2025
Shuyuan Xu, Jun Wang, Jingfeng Xia, and Wenchi Shou. Evaluating radiance field-inspired methods for 3d indoor re- construction: A comparative analysis.Buildings, 15(6), 2025. 1
2025
-
[39]
Review of image-based 3d reconstruction of building for automated con- struction progress monitoring.Applied Sciences, 11(17), 2021
Jingguo Xue, Xueliang Hou, and Ying Zeng. Review of image-based 3d reconstruction of building for automated con- struction progress monitoring.Applied Sciences, 11(17), 2021. 1
2021
-
[40]
Gaus- sian grouping: Segment and edit anything in 3d scenes
Mingqiao Ye, Martin Danelljan, Fisher Yu, and Lei Ke. Gaus- sian grouping: Segment and edit anything in 3d scenes. In European conference on computer vision, pages 162–179. Springer, 2024. 2
2024
-
[41]
3d gaussian splatting in robotics: A survey,
Siting Zhu, Guangming Wang, Xin Kong, Dezhi Kong, and Hesheng Wang. 3d gaussian splatting in robotics: A survey. arXiv preprint arXiv:2410.12262, 2024. 1
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.