Recognition: no theorem link
LatentAudit: Real-Time White-Box Faithfulness Monitoring for Retrieval-Augmented Generation with Verifiable Deployment
Pith reviewed 2026-05-10 19:43 UTC · model grok-4.3
The pith
Pooling mid-to-late residual-stream activations and measuring their Mahalanobis distance to evidence representations detects whether RAG answers are supported by retrieved documents.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
LatentAudit pools mid-to-late residual-stream activations from an open-weight generator and measures their Mahalanobis distance to the evidence representation. The resulting quadratic rule requires no auxiliary judge model, runs at generation time, and is simple enough to calibrate on a small held-out set. We show that residual-stream geometry carries a usable faithfulness signal, that this signal survives architecture changes and realistic retrieval failures, and that the same rule remains amenable to public verification. On PubMedQA with Llama-3-8B, LatentAudit reaches 0.942 AUROC with 0.77 ms overhead. Across three QA benchmarks and five model families (Llama-2/3, Qwen-2.5/3, Mistral), it
What carries the argument
The Mahalanobis distance between pooled mid-to-late residual-stream activations and the evidence representation, which serves as the decision statistic for whether the generated answer is faithful to the retrieved context.
If this is right
- The monitor adds only 0.77 ms latency and works at generation time without an extra model.
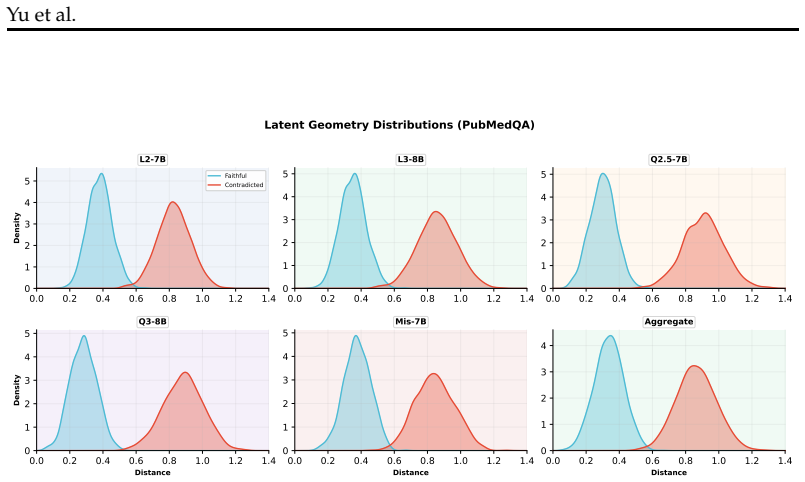
- Detection performance stays above 0.91 AUROC on HotpotQA and above 0.95 AUROC on PubMedQA even under four-way stress conditions with contradictions and retrieval misses.
- The rule retains 99.8 percent of its FP16 AUROC after conversion to 16-bit fixed-point arithmetic.
- The fixed-point version supports Groth16 proofs that let third parties verify audit decisions without access to weights or activations.
Where Pith is reading between the lines
- The same internal-geometry comparison could be tested on non-QA tasks such as summarization or code generation if suitable evidence representations are defined.
- Public verifiability opens the possibility of third-party certification for RAG systems in regulated domains without disclosing proprietary model details.
- The approach might be paired with existing retrieval-quality scores to create layered safeguards that address both retrieval errors and generation drift.
- If the signal proves robust, it could reduce reliance on post-generation fact-checkers or larger judge models in production RAG pipelines.
Load-bearing premise
The Mahalanobis distance between pooled mid-to-late residual-stream activations and the evidence representation reliably indicates whether the generated answer is actually supported by the retrieved evidence across architecture changes and realistic retrieval failures.
What would settle it
A controlled test set in which the model is forced to generate clearly unsupported answers on PubMedQA or HotpotQA yet the Mahalanobis distance still falls below the calibrated threshold (or the reverse case of supported answers triggering high distance).
Figures





read the original abstract
Retrieval-augmented generation (RAG) mitigates hallucination but does not eliminate it: a deployed system must still decide, at inference time, whether its answer is actually supported by the retrieved evidence. We introduce LatentAudit, a white-box auditor that pools mid-to-late residual-stream activations from an open-weight generator and measures their Mahalanobis distance to the evidence representation. The resulting quadratic rule requires no auxiliary judge model, runs at generation time, and is simple enough to calibrate on a small held-out set. We show that residual-stream geometry carries a usable faithfulness signal, that this signal survives architecture changes and realistic retrieval failures, and that the same rule remains amenable to public verification. On PubMedQA with Llama-3-8B, LatentAudit reaches 0.942 AUROC with 0.77,ms overhead. Across three QA benchmarks and five model families (Llama-2/3, Qwen-2.5/3, Mistral), the monitor remains stable; under a four-way stress test with contradictions, retrieval misses, and partial-support noise, it reaches 0.9566--0.9815 AUROC on PubMedQA and 0.9142--0.9315 on HotpotQA. At 16-bit fixed-point precision, the audit rule preserves 99.8% of the FP16 AUROC, enabling Groth16-based public verification without revealing model weights or activations. Together, these results position residual-stream geometry as a practical basis for real-time RAG faithfulness monitoring and optional verifiable deployment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces LatentAudit, a white-box auditor for RAG faithfulness that pools mid-to-late residual-stream activations from an open-weight generator and computes their Mahalanobis distance to an evidence representation. This yields a simple quadratic rule calibrated on a small held-out set, claimed to deliver real-time detection (0.77 ms overhead) with high AUROC (0.942 on PubMedQA/Llama-3-8B), stability across five model families and three QA benchmarks, robustness under a four-way stress test (contradictions, retrieval misses, partial support), and compatibility with Groth16 public verification at 16-bit fixed-point precision while retaining 99.8% of FP16 AUROC.
Significance. If the central empirical claims hold after addressing the distributional assumptions, the work provides a practical, low-overhead, model-agnostic tool for real-time RAG auditing without auxiliary judges. The cross-architecture stability, stress-test results, and verifiable-deployment angle are genuine strengths that could support deployment in safety-critical settings.
major comments (2)
- [Method / audit rule definition] The audit rule relies on Mahalanobis distance between pooled residual activations and the evidence representation (described in the method section). This implicitly assumes the faithful activations are approximately multivariate Gaussian so that the estimated covariance produces a meaningful separation. Residual streams routinely exhibit heavy tails, sparsity, and non-Gaussian structure from LayerNorm, attention, and non-linearities; the manuscript must demonstrate that the reported stability across architectures and retrieval failures is not an artifact of the particular calibration set.
- [Experiments / stress-test subsection] Experimental results report strong AUROC figures (0.942 on PubMedQA, 0.9566--0.9815 under stress tests) but provide no error bars, sensitivity analysis to the held-out calibration set, or details on how mean/covariance estimation interacts with data exclusion. This information is load-bearing for the claim that the same rule generalizes across model families and realistic failures.
minor comments (2)
- [Abstract] Abstract contains a typographical error: '0.77,ms' should read '0.77 ms'.
- [Method] Notation for the pooled activation vector and evidence representation could be made more explicit to aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive report. The two major comments identify important areas where the current manuscript can be strengthened with additional analysis and experimental details. We address each point below and commit to revisions that directly respond to the concerns raised.
read point-by-point responses
-
Referee: [Method / audit rule definition] The audit rule relies on Mahalanobis distance between pooled residual activations and the evidence representation (described in the method section). This implicitly assumes the faithful activations are approximately multivariate Gaussian so that the estimated covariance produces a meaningful separation. Residual streams routinely exhibit heavy tails, sparsity, and non-Gaussian structure from LayerNorm, attention, and non-linearities; the manuscript must demonstrate that the reported stability across architectures and retrieval failures is not an artifact of the particular calibration set.
Authors: We agree that the Mahalanobis distance implicitly relies on approximate multivariate normality for its probabilistic interpretation. While residual-stream activations can exhibit heavy tails and non-Gaussian structure, the quadratic form remains a practical linear separator in the whitened space, and its empirical effectiveness is what we report. The stability across five model families and three benchmarks, together with the four-way stress-test results, already indicates that performance is not tied to a single calibration distribution. To address the concern directly, we will add a new subsection in the method section that (i) reports basic distributional diagnostics (kurtosis, skewness, and selected QQ-plots for the pooled activations) and (ii) repeats the main experiments using two alternative calibration-set construction procedures (stratified vs. random). We will also add an explicit limitations paragraph acknowledging that the Gaussian assumption is an approximation. revision: partial
-
Referee: [Experiments / stress-test subsection] Experimental results report strong AUROC figures (0.942 on PubMedQA, 0.9566--0.9815 under stress tests) but provide no error bars, sensitivity analysis to the held-out calibration set, or details on how mean/covariance estimation interacts with data exclusion. This information is load-bearing for the claim that the same rule generalizes across model families and realistic failures.
Authors: We acknowledge that the current version lacks error bars and sensitivity analysis. In the revised manuscript we will (i) report AUROC means and standard deviations over five independent draws of the held-out calibration set for each model–dataset pair, (ii) include a sensitivity plot showing AUROC as a function of calibration-set size (100, 250, 500, and 1000 examples), and (iii) expand the method section with the precise procedure used for mean and covariance estimation, including any sample-exclusion rules applied to avoid singular covariance matrices. These additions will be placed in the experimental results and appendix, respectively. revision: yes
Circularity Check
No significant circularity; empirical calibration and evaluation remain independent
full rationale
The paper defines LatentAudit explicitly as a Mahalanobis-distance quadratic rule on pooled residual-stream activations, calibrates its parameters (mean and covariance) on a small held-out set, and then reports AUROC on distinct benchmark splits and stress-test conditions across multiple models. This is standard supervised evaluation of a detector rather than a derivation in which any reported performance metric reduces to the fitted parameters by construction. No self-definitional equations, fitted inputs relabeled as predictions, load-bearing self-citations, uniqueness theorems, or smuggled ansatzes appear in the abstract or described claims. The central result is therefore an empirical observation about residual-stream geometry, not a tautology.
Axiom & Free-Parameter Ledger
free parameters (1)
- mean and covariance of evidence representation
axioms (1)
- domain assumption Mahalanobis distance on pooled residual-stream activations provides a faithful signal
Reference graph
Works this paper leans on
-
[1]
Meta AI. The llama 3 herd of models.arXiv preprint arXiv:2407.21783,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
The internal state of an LLM knows when it’s lying
Amos Azaria and Tom Mitchell. The internal state of an LLM knows when it’s lying. In Findings of the Association for Computational Linguistics: EMNLP 2023, pp. 967–976,
2023
-
[3]
Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, et al. Qwen technical report.arXiv preprint arXiv:2309.16609,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, et al. Mistral 7b.arXiv preprint arXiv:2310.06825,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Pubmedqa: A dataset for biomedical research question answering.Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing,
Qiao Jin, Bhuwan Dhingra, Zhengping Liu, William W Cohen, and Xinghua Lu. Pubmedqa: A dataset for biomedical research question answering.Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing,
2019
-
[6]
Potsawee Manakul, Adian Liusie, and Mark J.F. Gales. Selfcheckgpt: Zero-resource black- box hallucination detection for generative large language models.Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing,
2023
-
[7]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models.arXiv preprint arXiv:2307.09288,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Cohen, Ruslan Salakhut- dinov, and Christopher D
Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William W. Cohen, Ruslan Salakhut- dinov, and Christopher D. Manning. Hotpotqa: A dataset for diverse, explainable multi- hop question answering. InProceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pp. 2369–2380,
2018
-
[9]
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng Sheng, Shiyang Hao, Zhanghao Wu, Sinyun Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, et al. Judging llm-as-a-judge with mt-bench and chatbot arena.arXiv preprint arXiv:2306.05685,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
11 Yu et al. A Dataset Construction Details PubMedQA.We use the expert-labeled (PQA-L) split of PubMedQA (Jin et al., 2019), which contains 1,000 question–answer pairs with long-form biomedical abstracts as evidence. We retain only the yes/no questions, yielding 800 filtered seeds. Evidence text is the concatenation of all labeled abstract sections. For t...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.