Recognition: no theorem link
GESS: Multi-cue Guided Local Feature Learning via Geometric and Semantic Synergy
Pith reviewed 2026-05-10 20:08 UTC · model grok-4.3
The pith
A multi-cue framework couples semantic and geometric signals via a shared 3D vector field to produce stabler keypoints and more discriminative descriptors.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
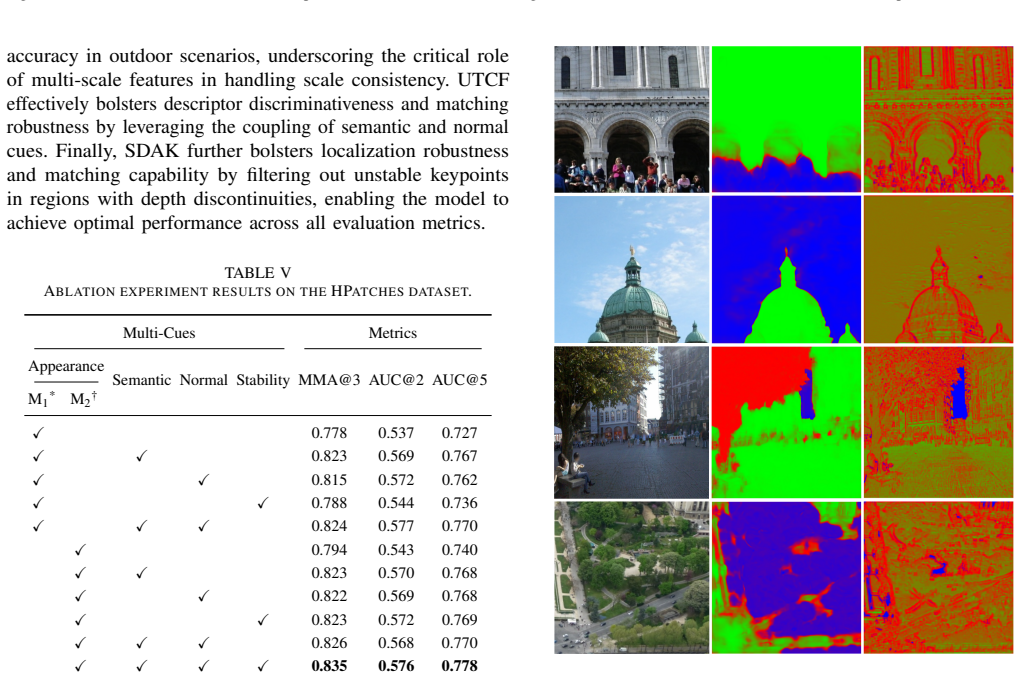
The paper claims that a joint semantic-normal prediction head using a shared 3D vector field resolves optimization interference between heterogeneous cues, while a depth stability prediction head supplies geometric reliability scores. These predictions power the Semantic-Depth Aware Keypoint mechanism, which reweights responses to suppress unreliable features, and the Unified Triple-Cue Fusion module, which uses semantic-scheduled gating to adaptively combine attributes into stronger descriptors. Experiments on four standard benchmarks are presented as evidence that the combined framework improves both detection robustness and descriptor discriminability over single-cue baselines.
What carries the argument
The joint semantic-normal prediction head that shares a single 3D vector field to couple semantic class predictions with surface normal estimation, together with the Semantic-Depth Aware Keypoint reweighting and Unified Triple-Cue Fusion gating modules.
If this is right
- Keypoint selection becomes more reliable because responses are down-weighted in regions that lack consistent semantic labels or depth stability.
- Descriptor vectors gain discriminability by receiving adaptively gated injections of semantic, geometric, and appearance information.
- The pipeline remains efficient because both the prediction heads and fusion modules sit atop a lightweight backbone.
- The same cues provide deterministic guidance for suppressing spurious features that single-cue detectors would accept.
Where Pith is reading between the lines
- The same stability signal could help filter moving objects in video sequences, improving feature utility for visual odometry without extra motion estimation.
- The modular design makes it straightforward to swap the backbone for a different encoder if higher capacity is needed for a specific domain.
- Because the method outputs both semantic and geometric predictions alongside features, it could serve as a drop-in prior for joint semantic mapping pipelines.
Load-bearing premise
The shared 3D vector field will eliminate optimization conflicts between semantic and normal cues, and the SDAK and UTCF modules will deliver consistent gains without introducing new failure modes or needing heavy per-dataset tuning.
What would settle it
If ablation or full evaluations on the four benchmarks show no measurable rise in keypoint repeatability, matching score, or descriptor precision relative to single-cue baselines, the claimed synergistic benefit would be refuted.
Figures






read the original abstract
Robust local feature detection and description are foundational tasks in computer vision. Existing methods primarily rely on single appearance cues for modeling, leading to unstable keypoints and insufficient descriptor discriminability. In this paper, we propose a multi-cue guided local feature learning framework that leverages semantic and geometric cues to synergistically enhance detection robustness and descriptor discriminability. Specifically, we construct a joint semantic-normal prediction head and a depth stability prediction head atop a lightweight backbone. The former leverages a shared 3D vector field to deeply couple semantic and normal cues, thereby resolving optimization interference from heterogeneous inconsistencies. The latter quantifies the reliability of local regions from a geometric consistency perspective, providing deterministic guidance for robust keypoint selection. Based on these predictions, we introduce the Semantic-Depth Aware Keypoint (SDAK) mechanism for feature detection. By coupling semantic reliability with depth stability, SDAK reweights keypoint responses to suppress spurious features in unreliable regions. For descriptor construction, we design a Unified Triple-Cue Fusion (UTCF) module, which employs a semantic-scheduled gating mechanism to adaptively inject multi-attribute features, improving descriptor discriminability. Extensive experiments on four benchmarks validate the effectiveness of the proposed framework. The source code and pre-trained model will be available at: https://github.com/yiyscut/GESS.git.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes GESS, a multi-cue guided local feature learning framework for robust detection and description. It introduces a joint semantic-normal prediction head atop a lightweight backbone that uses a shared 3D vector field to couple semantic and normal cues and resolve optimization interference, a separate depth stability prediction head, the SDAK mechanism that reweights keypoints by coupling semantic reliability with depth stability, and the UTCF module with semantic-scheduled gating for adaptive multi-attribute descriptor fusion. The work claims these components synergistically improve detection robustness and descriptor discriminability, with validation asserted on four benchmarks and code to be released.
Significance. If the claimed synergy holds under rigorous testing, the approach could meaningfully advance local feature methods by addressing limitations of single-cue appearance modeling, with potential benefits for downstream tasks such as matching, SLAM, and 3D reconstruction. The planned code and model release would support reproducibility and adoption.
major comments (2)
- [Abstract and §3] Abstract and §3 (method): The central claim that the shared 3D vector field in the joint semantic-normal prediction head resolves optimization interference from heterogeneous cues lacks supporting evidence such as explicit loss formulation, gradient analysis, or ablation isolating the shared field versus separate heads; without this, the asserted synergy for detection robustness and descriptor discriminability remains unverified.
- [Abstract and experiments] Abstract and experiments section: The abstract asserts validation on four benchmarks yet provides no quantitative results, baseline comparisons, ablation studies, or error analysis; this leaves the empirical effectiveness of SDAK and UTCF unexamined and load-bearing for the overall contribution.
minor comments (1)
- [Abstract] Abstract: The description of the depth stability prediction head as providing 'deterministic guidance' would benefit from clarification on how determinism is achieved given learned predictions.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below, providing the strongest honest defense of the manuscript while agreeing to revisions that strengthen the presentation of evidence.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (method): The central claim that the shared 3D vector field in the joint semantic-normal prediction head resolves optimization interference from heterogeneous cues lacks supporting evidence such as explicit loss formulation, gradient analysis, or ablation isolating the shared field versus separate heads; without this, the asserted synergy for detection robustness and descriptor discriminability remains unverified.
Authors: We agree that additional evidence would strengthen the claim. Section 3 describes the joint head architecture and the shared 3D vector field for coupling semantic and normal cues, along with the overall training objective. However, we did not provide an explicit side-by-side loss formulation or an ablation isolating the shared field. In the revision we will (i) state the joint loss explicitly, (ii) add an ablation comparing the shared 3D vector field against independent heads, and (iii) report the resulting changes in keypoint stability and descriptor discriminability. This will directly verify the claimed resolution of optimization interference. revision: yes
-
Referee: [Abstract and experiments] Abstract and experiments section: The abstract asserts validation on four benchmarks yet provides no quantitative results, baseline comparisons, ablation studies, or error analysis; this leaves the empirical effectiveness of SDAK and UTCF unexamined and load-bearing for the overall contribution.
Authors: The abstract follows the conventional format of summarizing the validation scope without numerical tables. The experiments section already reports results on the four benchmarks together with baseline comparisons and component ablations. To address the concern that the effectiveness of SDAK and UTCF remains insufficiently examined, we will (i) insert concise quantitative highlights into the abstract and (ii) expand the experiments section with dedicated ablations and error analysis focused on SDAK and UTCF. These additions will make the empirical support for the two modules more explicit. revision: partial
Circularity Check
No significant circularity; architectural proposal is self-contained
full rationale
The paper presents a new multi-cue framework (joint semantic-normal head with shared 3D vector field, depth stability head, SDAK reweighting, and UTCF gating) whose performance claims rest on empirical results across four benchmarks rather than any closed-form derivation or parameter fit that reduces the output to the input by construction. No equations are shown that equate a claimed improvement to a quantity fitted from the same data; the shared-vector-field coupling is an architectural choice whose benefit is asserted and then validated experimentally, not presupposed. No self-citations appear in the provided text, and the method does not rename a known result or import a uniqueness theorem from prior author work. The derivation chain therefore remains open to external falsification.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption A shared 3D vector field can deeply couple semantic and normal cues while resolving optimization interference from heterogeneous inconsistencies.
- domain assumption Depth stability quantified from a geometric consistency perspective supplies deterministic guidance for robust keypoint selection.
invented entities (2)
-
SDAK (Semantic-Depth Aware Keypoint) mechanism
no independent evidence
-
UTCF (Unified Triple-Cue Fusion) module
no independent evidence
Reference graph
Works this paper leans on
-
[1]
HPatches: A benchmark and evaluation of handcrafted and learned local descriptors,
V . Balntas, K. Lenc, A. Vedaldi, and K. Mikolajczyk, “HPatches: A benchmark and evaluation of handcrafted and learned local descriptors,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017, pp. 5173–5182
2017
-
[2]
Maximum-likelihood image matching,
C. Olson, “Maximum-likelihood image matching,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 24, no. 6, pp. 853–857, 2002
2002
-
[3]
Benchmarking 6dof outdoor visual localization in changing conditions,
T. Sattler, W. Maddern, C. Toft, A. Torii, L. Hammarstrand, E. Stenborg, D. Safari, M. Okutomi, M. Pollefeys, J. Sivicet al., “Benchmarking 6dof outdoor visual localization in changing conditions,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018, pp. 8601–8610
2018
-
[4]
Accurate, dense, and robust multiview stere- opsis,
Y . Furukawa and J. Ponce, “Accurate, dense, and robust multiview stere- opsis,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 32, no. 8, pp. 1362–1376, 2010
2010
-
[5]
Semantic visual localization,
J. L. Sch ¨onberger, M. Pollefeys, A. Geiger, and T. Sattler, “Semantic visual localization,” 2018
2018
-
[6]
Orb-slam2: An open-source slam system for monocular, stereo, and rgb-d cameras,
R. Mur-Artal and J. D. Tardos, “Orb-slam2: An open-source slam system for monocular, stereo, and rgb-d cameras,”IEEE Transactions on Robotics, vol. 33, no. 5, p. 1255–1262, Oct. 2017
2017
-
[7]
Kpdepth-vo: Self- supervised learning of scale-consistent visual odometry and depth with keypoint features from monocular video,
C. Wang, G. Zhang, Z. Cheng, and W. Zhou, “Kpdepth-vo: Self- supervised learning of scale-consistent visual odometry and depth with keypoint features from monocular video,”IEEE Transactions on Circuits and Systems for Video Technology, vol. 35, no. 6, pp. 5762–5775, 2025
2025
-
[8]
R2D2: Repeatable and Reliable Detector and Descriptor,
J. Revaud, P. Weinzaepfel, C. D. Souza, N. Pion, G. Csurka, Y . Cabon, and M. Humenberger, “R2D2: Repeatable and Reliable Detector and Descriptor,” inNeurIPS, 2019, p. 12
2019
-
[9]
Distinctive image features from scale-invariant keypoints,
D. G. Lowe, “Distinctive image features from scale-invariant keypoints,” International journal of computer vision, vol. 60, no. 2, pp. 91–110, 2004
2004
-
[10]
Orb: An efficient alternative to sift or surf,
E. Rublee, V . Rabaud, K. Konolige, and G. Bradski, “Orb: An efficient alternative to sift or surf,” in2011 International conference on computer vision. Ieee, 2011, pp. 2564–2571
2011
-
[11]
Surf: Speeded up robust features,
H. Bay, T. Tuytelaars, and L. Van Gool, “Surf: Speeded up robust features,” inEuropean conference on computer vision. Springer, 2006, pp. 404–417
2006
-
[12]
Features combined binary descriptor based on voted ring-sampling pattern,
H. Liu, Q. Zhang, B. Fan, Z. Wang, and J. Han, “Features combined binary descriptor based on voted ring-sampling pattern,”IEEE Transactions on Circuits and Systems for Video Technology, vol. 30, no. 10, pp. 3675–3687, 2020
2020
-
[13]
SuperPoint: Self- Supervised Interest Point Detection and Description,
D. DeTone, T. Malisiewicz, and A. Rabinovich, “SuperPoint: Self- Supervised Interest Point Detection and Description,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, 2018, pp. 224–236
2018
-
[14]
ASLFeat: Learning Local Features of Accurate Shape and Localization,
Z. Luo, L. Zhou, X. Bai, H. Chen, J. Zhang, Y . Yao, S. Li, T. Fang, and L. Quan, “ASLFeat: Learning Local Features of Accurate Shape and Localization,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Apr. 2020
2020
-
[15]
D2-Net: A Trainable CNN for Joint Description and Detection of Local Features,
M. Dusmanu, I. Rocco, T. Pajdla, M. Pollefeys, J. Sivic, A. Torii, and T. Sattler, “D2-Net: A Trainable CNN for Joint Description and Detection of Local Features,” in2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, Jun. 2019, pp. 8084– 8093
2019
-
[16]
DISK: Learning local features with policy gradient,
M. J. Tyszkiewicz, P. Fua, and E. Trulls, “DISK: Learning local features with policy gradient,” inNeural IPS, Jun. 2020
2020
-
[17]
Alike: Accurate and lightweight keypoint detection and descriptor extraction,
X. Zhao, X. Wu, J. Miao, W. Chen, P. C. Chen, and Z. Li, “Alike: Accurate and lightweight keypoint detection and descriptor extraction,” IEEE Transactions on Multimedia, 2022
2022
-
[18]
Attention weighted local descriptors,
C. Wang, R. Xu, K. Lu, S. Xu, W. Meng, Y . Zhang, B. Fan, and X. Zhang, “Attention weighted local descriptors,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 45, no. 9, pp. 10 632–10 649, 2023
2023
-
[19]
Cdbin: Compact discriminative binary descriptor learned with efficient neural network,
J. Ye, S. Zhang, T. Huang, and Y . Rui, “Cdbin: Compact discriminative binary descriptor learned with efficient neural network,”IEEE Transac- tions on Circuits and Systems for Video Technology, vol. 30, no. 3, pp. 862–874, 2020. 13
2020
-
[20]
Llfeat: Noise-aware feature matching under various low- light conditions,
L. Zeng, Z. Zhu, M. Lu, B. Zheng, R. Lu, T. Wang, Z. Zheng, Y . Sun, and C. Yan, “Llfeat: Noise-aware feature matching under various low- light conditions,”IEEE Transactions on Circuits and Systems for Video Technology, pp. 1–1, 2026
2026
-
[21]
Sfd2: Semantic-guided feature detection and description,
F. Xue, I. Budvytis, and R. Cipolla, “Sfd2: Semantic-guided feature detection and description,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 5206–5216
2023
-
[22]
Spadesc: Semantic and parallel attention with feature description,
H. Meng, H. Lu, B. Ding, and Q. Wang, “Spadesc: Semantic and parallel attention with feature description,”Neurocomputing, vol. 625, p. 129567, 2025
2025
-
[23]
Sde2d: Semantic-guided discriminability enhancement feature detector and descriptor,
J. Li, R. Zhang, G. Li, and T. H. Li, “Sde2d: Semantic-guided discriminability enhancement feature detector and descriptor,”IEEE Transactions on Multimedia, vol. 27, pp. 275–286, 2025
2025
-
[24]
Segment anything model is a good teacher for local feature learning,
J. Wu, R. Xu, Z. Wood-Doughty, C. Wang, S. Xu, and E. Y . Lam, “Segment anything model is a good teacher for local feature learning,” IEEE Transactions on Image Processing, 2025
2025
-
[25]
Learning local features by jointly semantic-guided and task rewards,
L. Wang, Y . Zhang, F. Ge, W. Bai, J. Zhang, and Y . Wang, “Learning local features by jointly semantic-guided and task rewards,”IEEE Transactions on Circuits and Systems for Video Technology, vol. 35, no. 3, pp. 2045– 2056, 2025
2045
-
[26]
Liftfeat: 3d geometry-aware local feature matching,
Y . Liu, W. Lai, Z. Zhao, Y . Xiong, J. Zhu, J. Cheng, and Y . Xu, “Liftfeat: 3d geometry-aware local feature matching,”arXiv preprint arXiv:2505.03422, 2025
-
[27]
Humans integrate visual and haptic information in a statistically optimal fashion,
M. O. Ernst and M. S. Banks, “Humans integrate visual and haptic information in a statistically optimal fashion,”Nature, vol. 415, no. 6870, pp. 429–433, 2002
2002
-
[28]
Multi-task learning using uncertainty to weigh losses for scene geometry and semantics,
R. Cipolla, Y . Gal, and A. Kendall, “Multi-task learning using uncertainty to weigh losses for scene geometry and semantics,” in2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018, pp. 7482–7491
2018
-
[29]
Lsnet: See large, focus small,
A. Wang, H. Chen, Z. Lin, J. Han, and G. Ding, “Lsnet: See large, focus small,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2025, pp. 9718–9729
2025
-
[30]
Faster and better: A machine learning approach to corner detection,
E. Rosten, R. Porter, and T. Drummond, “Faster and better: A machine learning approach to corner detection,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 32, no. 1, pp. 105–119, 2010
2010
-
[31]
Brief: Binary robust independent elementary features,
M. Calonder, V . Lepetit, C. Strecha, and P. Fua, “Brief: Binary robust independent elementary features,” inComputer Vision – ECCV 2010, K. Daniilidis, P. Maragos, and N. Paragios, Eds. Berlin, Heidelberg: Springer Berlin Heidelberg, 2010, pp. 778–792
2010
-
[32]
Lift: Learned invariant feature transform,
K. M. Yi, E. Trulls, V . Lepetit, and P. Fua, “Lift: Learned invariant feature transform,” 2016
2016
-
[33]
L2-net: Deep learning of discriminative patch descriptor in euclidean space,
Y . Tian, B. Fan, and F. Wu, “L2-net: Deep learning of discriminative patch descriptor in euclidean space,” in2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017, pp. 6128–6136
2017
-
[34]
Superpoint: Self- supervised interest point detection and description,
D. DeTone, T. Malisiewicz, and A. Rabinovich, “Superpoint: Self- supervised interest point detection and description,” inProceedings of the IEEE conference on computer vision and pattern recognition workshops, 2018, pp. 224–236
2018
-
[35]
Key.net: Keypoint detection by handcrafted and learned cnn filters,
A. Barroso-Laguna, E. Riba, D. Ponsa, and K. Mikolajczyk, “Key.net: Keypoint detection by handcrafted and learned cnn filters,” 2019
2019
-
[36]
Mtldesc: Looking wider to describe better,
C. Wang, R. Xu, Y . Zhang, S. Xu, W. Meng, B. Fan, and X. Zhang, “Mtldesc: Looking wider to describe better,” inAAAI. AAAI Press, 2022
2022
-
[37]
Contextdesc: Local descriptor augmentation with cross-modality context,
Z. Luo, T. Shen, L. Zhou, J. Zhang, Y . Yao, S. Li, T. Fang, and L. Quan, “Contextdesc: Local descriptor augmentation with cross-modality context,” Computer Vision and Pattern Recognition (CVPR), 2019
2019
-
[38]
Domainfeat: Learning local features with domain adaptation,
R. Xu, C. Wang, S. Xu, W. Meng, Y . Zhang, B. Fan, and X. Zhang, “Domainfeat: Learning local features with domain adaptation,”IEEE Transactions on Circuits and Systems for Video Technology, vol. 34, no. 1, pp. 46–59, 2024
2024
-
[39]
Contextmatcher: Detector-free feature matching with cross-modality context,
D. Li and S. Du, “Contextmatcher: Detector-free feature matching with cross-modality context,”IEEE Transactions on Circuits and Systems for Video Technology, vol. 34, no. 9, pp. 7922–7934, 2024
2024
-
[40]
A. Kirillov, E. Mintun, N. Ravi, H. Mao, C. Rolland, L. Gustafson, T. Xiao, S. Whitehead, A. C. Berg, W.-Y . Lo, P. Doll ´ar, and R. Girshick, “Segment anything,”arXiv:2304.02643, 2023
work page internal anchor Pith review arXiv 2023
-
[41]
Saga-feat: A semantic- and geometry-aware network for sparse local feature learning,
Y . Mo, M. Yin, G. Li, J. Liao, and Z. Liang, “Saga-feat: A semantic- and geometry-aware network for sparse local feature learning,”Neurocomput., vol. 655, no. C, Jan. 2026
2026
-
[42]
Decoupling makes weakly supervised local feature better,
K. Li, L. Wang, L. Liu, Q. Ran, K. Xu, and Y . Guo, “Decoupling makes weakly supervised local feature better,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 15 838–15 848
2022
-
[43]
Open- vocabulary panoptic segmentation with text-to-image diffusion models,
J. Xu, S. Liu, A. Vahdat, W. Byeon, X. Wang, and S. De Mello, “Open- vocabulary panoptic segmentation with text-to-image diffusion models,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023, pp. 2955–2966
2023
-
[44]
MoGe-2: Accurate Monocular Geometry with Metric Scale and Sharp Details
R. Wang, S. Xu, Y . Dong, Y . Deng, J. Xiang, Z. Lv, G. Sun, X. Tong, and J. Yang, “Moge-2: Accurate monocular geometry with metric scale and sharp details,”arXiv preprint arXiv:2507.02546, 2025
work page internal anchor Pith review arXiv 2025
-
[45]
Megadepth: Learning single-view depth prediction from internet photos,
Z. Li and N. Snavely, “Megadepth: Learning single-view depth prediction from internet photos,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018, pp. 2041–2050
2018
-
[46]
Microsoft coco: Common objects in context,
T.-Y . Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ramanan, P. Doll´ar, and C. L. Zitnick, “Microsoft coco: Common objects in context,” inComputer Vision – ECCV 2014, D. Fleet, T. Pajdla, B. Schiele, and T. Tuytelaars, Eds. Cham: Springer International Publishing, 2014, pp. 740–755
2014
-
[47]
A performance evaluation of local descriptors,
K. Mikolajczyk and C. Schmid, “A performance evaluation of local descriptors,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 27, no. 10, pp. 1615–1630, 2005
2005
-
[48]
Learning semantic-aware local features for long term visual localization,
B. Fan, J. Zhou, W. Feng, H. Pu, Y . Yang, Q. Kong, F. Wu, and H. Liu, “Learning semantic-aware local features for long term visual localization,” IEEE Transactions on Image Processing, vol. 31, pp. 4842–4855, 2022
2022
-
[49]
Efficient large- scale localization by global instance recognition,
F. Xue, I. Budvytis, D. O. Reino, and R. Cipolla, “Efficient large- scale localization by global instance recognition,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 17 348–17 357
2022
-
[50]
Aslfeat: Learning local features of accurate shape and localization,
Z. Luo, L. Zhou, X. Bai, H. Chen, J. Zhang, Y . Yao, S. Li, T. Fang, and L. Quan, “Aslfeat: Learning local features of accurate shape and localization,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 6589–6598
2020
-
[51]
Xfeat: Accelerated features for lightweight image matching,
G. Potje, F. Cadar, A. Araujo, R. Martins, and E. R. Nascimento, “Xfeat: Accelerated features for lightweight image matching,” in2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024, pp. 2682–2691
2024
-
[52]
Megadepth: Learning single-view depth prediction from internet photos,
Z. Li and N. Snavely, “Megadepth: Learning single-view depth prediction from internet photos,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 2041–2050
2018
-
[53]
Scannet: Richly-annotated 3d reconstructions of indoor scenes,
A. Dai, A. X. Chang, M. Savva, M. Halber, T. Funkhouser, and M. Nießner, “Scannet: Richly-annotated 3d reconstructions of indoor scenes,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 5828–5839
2017
-
[54]
LightGlue: Local Feature Matching at Light Speed,
P. Lindenberger, P.-E. Sarlin, and M. Pollefeys, “LightGlue: Local Feature Matching at Light Speed,” inInternational Conference on Computer Vision (ICCV), 2023
2023
-
[55]
Compara- tive evaluation of hand-crafted and learned local features,
J. L. Schonberger, H. Hardmeier, T. Sattler, and M. Pollefeys, “Compara- tive evaluation of hand-crafted and learned local features,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 1482–1491
2017
-
[56]
Structure-from-motion revisited,
J. L. Schonberger and J.-M. Frahm, “Structure-from-motion revisited,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 4104–4113
2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.