Recognition: 2 theorem links
· Lean TheoremDAT: Dual-Aware Adaptive Transmission for Efficient Multimodal LLM Inference in Edge-Cloud Systems
Pith reviewed 2026-05-10 19:14 UTC · model grok-4.3
The pith
DAT uses a lightweight edge model to screen video frames and trigger full multimodal LLM reasoning only on suspicious ones, paired with semantics-aware transmission to cut delays while preserving accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
DAT shows that a collaborative small-large model cascade, where an edge lightweight model filters non-target frames and performs object detection before invoking the MLLM, combined with visual-guidance fine-tuning, semantic prompting, and a semantics-bandwidth-aware multi-stream adaptive transmission method, delivers 98.83 percent recognition accuracy, 100 percent output consistency, up to 77.5 percent lower weighted semantic alert delay under severe congestion, and 98.33 percent of visual evidence within 0.5 seconds.
What carries the argument
The small-large model cascade that lets the edge model act as a gate and detector, integrated with semantics and bandwidth-aware multi-stream adaptive transmission that prioritizes important content under constraints.
If this is right
- Full multimodal LLM inference runs only on frames the edge model flags as suspicious, sharply reducing computation and communication volume.
- Semantic alert delay stays low even when the network is severely congested because transmission adapts to both content importance and available bandwidth.
- Fine-tuning with visual guidance and semantic prompting raises structured event understanding and guarantees 100 percent output consistency across runs.
- Visual evidence supplementation succeeds at delivering nearly all relevant frames within half a second despite bandwidth limits.
Where Pith is reading between the lines
- The same gating-plus-adaptive-transmission pattern could be tested on non-video streams such as sensor or audio data where expensive models dominate cost.
- If the edge model is swapped for an even lighter or more specialized version, overall latency could drop further without changing the cloud-side MLLM.
- The multi-stream optimization might combine naturally with predictive bandwidth forecasting to handle rapidly changing network conditions.
- Longer continuous video sessions could reveal whether the consistency gains compound or whether drift in the small model appears over time.
Load-bearing premise
The lightweight edge model must reliably detect and filter frames without missing critical events that would need the full multimodal LLM.
What would settle it
A video dataset containing subtle target events where the edge model's detection misses more than a small fraction of frames that a full MLLM baseline would have processed correctly, producing lower end-to-end accuracy or missed alerts.
Figures




read the original abstract
Multimodal large language models (MLLMs) have shown strong capability in semantic understanding and visual reasoning, yet their use on continuous video streams in bandwidth-constrained edge-cloud systems incurs prohibitive computation and communication overhead and hinders low-latency alerting and effective visual evidence delivery. To address this challenge, we propose DAT to achieve high-quality semantic generation, low-latency event alerting, and effective visual evidence supplementation. To reduce unnecessary deep reasoning costs, we propose a collaborative small-large model cascade. A lightweight edge-side small model acts as a gating module to filter non-target-event frames and perform object detection, triggering MLLM inference only for suspicious frames. Building on this, we introduce an efficient fine-tuning strategy with visual guidance and semantic prompting, which improves structured event understanding, object detection, and output consistency. To ensure low-latency semantic alerting and effective visual evidence supplementation under bandwidth constraints, we further devise a semantics and bandwidth-aware multi-stream adaptive transmission optimization method. Experimental results show that DAT achieves 98.83% recognition accuracy and 100% output consistency. Under severe congestion, it reduces weighted semantic alert delay by up to 77.5% and delivers 98.33% of visual evidence within 0.5 s, demonstrating the effectiveness of jointly optimizing cascade inference and elastic transmission.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes DAT, a system for efficient multimodal LLM inference in edge-cloud video streaming. It introduces a collaborative small-large model cascade with a lightweight edge-side small model for gating non-target frames and triggering MLLM inference, an efficient fine-tuning strategy using visual guidance and semantic prompting to improve event understanding and consistency, and a semantics- and bandwidth-aware multi-stream adaptive transmission optimization for low-latency alerting and visual evidence delivery under congestion. Experimental results claim 98.83% recognition accuracy, 100% output consistency, up to 77.5% reduction in weighted semantic alert delay, and 98.33% visual evidence delivery within 0.5 s.
Significance. If the results hold under rigorous validation, DAT could meaningfully advance practical deployment of MLLMs for real-time semantic video analysis in bandwidth-constrained edge-cloud settings by jointly optimizing inference efficiency and transmission. The cascade approach and adaptive transmission are relevant to multimedia systems and edge AI, with potential for reduced overhead while preserving semantic quality.
major comments (2)
- Abstract: The headline performance numbers (98.83% recognition accuracy, 77.5% delay reduction, 98.33% evidence delivery within 0.5 s) are reported without any details on datasets, baselines, experimental conditions, number of trials, error bars, or statistical tests. This absence is load-bearing because the claims cannot be verified or reproduced from the given information.
- Collaborative small-large model cascade (method description): The lightweight edge-side small model is positioned as reliably filtering non-target-event frames and performing object detection to trigger MLLM only on suspicious frames without missing critical events. However, no per-component metrics such as recall, false-negative rate, or latency breakdown for the gating stage are provided. Aggregate accuracy alone does not establish that the cascade preserves all target events, which directly underpins the reported delay reductions and evidence-delivery percentages.
minor comments (1)
- The abstract would be strengthened by a concise statement of the evaluation datasets and key baselines to allow readers to contextualize the reported gains.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We address each major comment point by point below, indicating where revisions will be made to improve clarity, verifiability, and rigor while preserving the core contributions of DAT.
read point-by-point responses
-
Referee: Abstract: The headline performance numbers (98.83% recognition accuracy, 77.5% delay reduction, 98.33% evidence delivery within 0.5 s) are reported without any details on datasets, baselines, experimental conditions, number of trials, error bars, or statistical tests. This absence is load-bearing because the claims cannot be verified or reproduced from the given information.
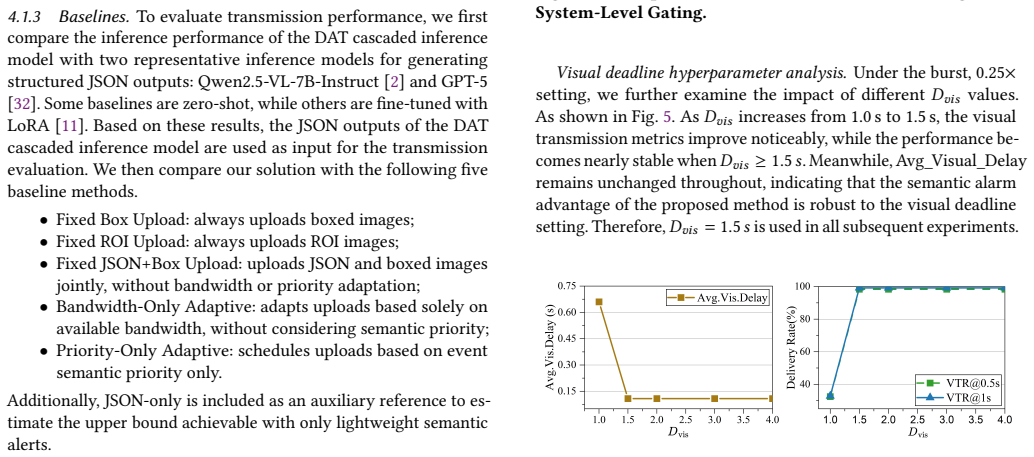
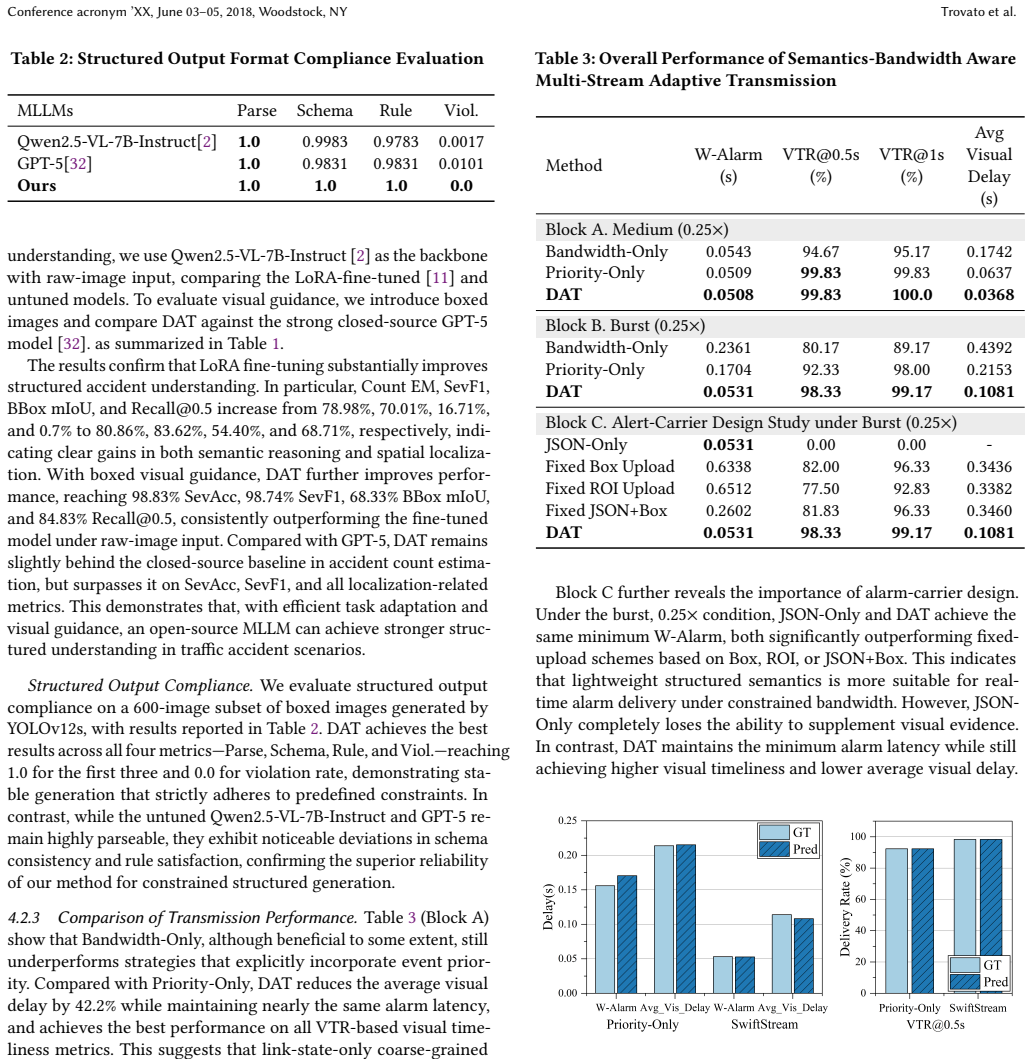
Authors: We agree that the abstract, being a concise summary, does not include the full experimental context needed for immediate verification. The manuscript body (Section 5, Experiments) provides the required details on datasets, baselines, conditions, trial counts, and analysis. To directly address this, we will revise the abstract to include a brief reference to the evaluation datasets and setup. We will also add error bars to key result figures and explicitly report statistical tests in the revised experimental section. revision: partial
-
Referee: Collaborative small-large model cascade (method description): The lightweight edge-side small model is positioned as reliably filtering non-target-event frames and performing object detection to trigger MLLM only on suspicious frames without missing critical events. However, no per-component metrics such as recall, false-negative rate, or latency breakdown for the gating stage are provided. Aggregate accuracy alone does not establish that the cascade preserves all target events, which directly underpins the reported delay reductions and evidence-delivery percentages.
Authors: We acknowledge that explicit per-component metrics for the gating stage would provide stronger, direct validation of the cascade's reliability in avoiding missed events. The current manuscript demonstrates effectiveness via end-to-end results (98.83% accuracy and associated delay/evidence gains), but we agree this is indirect. In the revision, we will add a dedicated subsection with recall, false-negative rate, precision for the small model, and a latency breakdown of the edge gating stage to substantiate that critical events are preserved. revision: yes
Circularity Check
No circularity: empirical system proposal without derivations or self-referential fitting
full rationale
The paper describes a collaborative small-large model cascade and adaptive transmission method for MLLM inference, supported solely by experimental results (98.83% accuracy, 77.5% delay reduction, etc.). No equations, derivations, or mathematical chains are present in the abstract or described structure. Performance metrics are reported from direct evaluation rather than fitted parameters renamed as predictions or self-citations that reduce the central claims to inputs. The gating assumption is an empirical design choice validated (or not) by aggregate results, not a circular reduction. This is a standard non-circular empirical systems paper.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclearA lightweight edge-side small model acts as a gating module to filter non-target-event frames and perform object detection, triggering MLLM inference only for suspicious frames.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearlexmin ... weighted semantic alert delay ... visual evidence delivery
Reference graph
Works this paper leans on
-
[1]
2024.Accidents Detection Dataset
AmedeoGrandi. 2024.Accidents Detection Dataset. Retrieved Jan 15, 2024 from https://www.kaggle.com/datasets/amedeograndi/accidents-detection- dataset/data
2024
-
[2]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Junyang Lin. 2025. Qwen2.5-VL Technical Rep...
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [3]
-
[4]
Tianyu Chen, Yiheng Lin, Nicolas Christianson, Zahaib Akhtar, Sharath Dharmaji, Mohammad Hajiesmaili, Adam Wierman, and Ramesh K. Sitaraman. 2024. SODA: An Adaptive Bitrate Controller for Consistent High-Quality Video Streaming. InProceedings of the ACM SIGCOMM 2024 Conference(Sydney, NSW, Australia) (ACM SIGCOMM ’24). Association for Computing Machinery,...
-
[5]
Yong-Hoon Choi, Daegyeom Kim, Myeongjin Ko, Kyung-yul Cheon, Seungkeun Park, Yunbae Kim, and Hyungoo Yoon. 2023. ML-Based 5G Traffic Generation for Practical Simulations Using Open Datasets.IEEE Communications Magazine 61, 9 (2023), 130–136. doi:10.1109/MCOM.001.2200679
-
[6]
Lingyu Duan, Jiaying Liu, Wenhan Yang, Tiejun Huang, and Wen Gao. 2020. Video Coding for Machines: A Paradigm of Collaborative Compression and Intelligent Analytics.Trans. Img. Proc.29 (Jan. 2020), 8680–8695. doi:10.1109/TIP. 2020.3016485
work page doi:10.1109/tip 2020
-
[7]
2005.Multicriteria Optimization(2 ed.)
Matthias Ehrgott. 2005.Multicriteria Optimization(2 ed.). Springer, Berlin, Heidelberg. doi:10.1007/3-540-27659-9
-
[8]
2025.Mobile network traffic Q4 2025
Ericsson. 2025.Mobile network traffic Q4 2025. Retrieved November 2025 from https://www.ericsson.com/en/reports-and-papers/mobility-report/ dataforecasts/mobile-traffic-update
2025
-
[9]
2021.H.264(5) & H.264(5)+ Recommended Bit Rate at General Resolutions
Hikvision. 2021.H.264(5) & H.264(5)+ Recommended Bit Rate at General Resolutions. Retrieved December 22, 2021 from https://www.hikvision.com/ content/dam/hikvision/ca/faq-document/H.2645-%26-H.2645-Recommended- Bit-Rate-at-General-Resolutions.pdf
2021
-
[10]
Neil Houlsby, Andrei Giurgiu, Stanislaw Jastrzebski, Bruna Morrone, Quentin De Laroussilhe, Andrea Gesmundo, Mona Attariyan, and Sylvain Gelly. 2019. Parameter-efficient transfer learning for NLP. InInternational conference on machine learning. PMLR, 2790–2799
2019
-
[11]
LoRA: Low-Rank Adaptation of Large Language Models
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2021. LoRA: Low-Rank Adaptation of Large Language Models. arXiv:2106.09685 [cs.CL] https://arxiv.org/abs/2106.09685
work page internal anchor Pith review Pith/arXiv arXiv 2021
- [12]
- [13]
-
[14]
Yaqi Hu, Dongdong Ye, Jiawen Kang, Maoqiang Wu, and Rong Yu. 2024. A cloud–edge collaborative architecture for multimodal LLM-based advanced driver assistance systems in IoT networks.IEEE Internet of Things Journal12, 10 (2024), 13208–13221
2024
-
[15]
Tianchi Huang, Chao Zhou, Rui-Xiao Zhang, Chenglei Wu, Xin Yao, and Lifeng Sun. 2020. Stick: A Harmonious Fusion of Buffer-based and Learning-based Approach for Adaptive Streaming. InIEEE INFOCOM 2020 - IEEE Conference on Computer Communications(Toronto, ON, Canada). IEEE Press, 1967–1976. doi:10.1109/INFOCOM41043.2020.9155411
-
[16]
Te-Yuan Huang, Ramesh Johari, Nick McKeown, Matthew Trunnell, and Mark Watson. 2014. A buffer-based approach to rate adaptation: evidence from a large video streaming service.SIGCOMM Comput. Commun. Rev.44, 4 (Aug. 2014), 187–198. doi:10.1145/2740070.2626296
-
[17]
2025.What’s New in HTTP Live Streaming
Apple Inc. 2025.What’s New in HTTP Live Streaming. Apple Developer. https: //developer.apple.com/streaming/Whats-new-HLS.pdf WWDC 2025
2025
-
[18]
Wen Ji, Bing Liang, Yuqin Wang, Rui Qiu, and Zheming Yang. 2020. Crowd V-IoE: Visual internet of everything architecture in AI-driven fog computing.IEEE Wireless Communications27, 2 (2020), 51–57
2020
-
[19]
Junchen Jiang, Vyas Sekar, and Hui Zhang. 2012. Improving fairness, efficiency, and stability in HTTP-based adaptive video streaming with FESTIVE. InProceed- ings of the 8th International Conference on Emerging Networking Experiments and Technologies(Nice, France)(CoNEXT ’12). Association for Computing Machinery, New York, NY, USA, 97–108. doi:10.1145/241...
-
[20]
Yizhang Jin, Jian Li, Tianjun Gu, Yexin Liu, Bo Zhao, Jinxiang Lai, Zhenye Gan, Yabiao Wang, Chengjie Wang, Xin Tan, and Lizhuang Ma. 2025. Efficient mul- timodal large language models: a survey.Visual Intelligence3, 1 (Dec. 2025). doi:10.1007/s44267-025-00099-6
-
[21]
Leonardo Lai, Lorenzo Fiaschi, Marco Cococcioni, and Kalyanmoy Deb. 2023. Pure and mixed lexicographic-paretian many-objective optimization: state of the art.Natural Computing22, 2 (2023), 227–242
2023
-
[22]
Hongshan Li, Chenghao Hu, Jingyan Jiang, Zhi Wang, Yonggang Wen, and Wenwu Zhu. 2018. JALAD: Joint Accuracy-And Latency-Aware Deep Structure Decoupling for Edge-Cloud Execution. In2018 IEEE 24th International Conference on Parallel and Distributed Systems (ICPADS). 671–678. doi:10.1109/PADSW.2018. 8645013
-
[23]
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. 2023. BLIP-2: bootstrap- ping language-image pre-training with frozen image encoders and large language models. InProceedings of the 40th International Conference on Machine Learning (Honolulu, Hawaii, USA)(ICML’23). JMLR.org, Article 814, 13 pages
2023
- [24]
-
[25]
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. 2023. Visual Instruc- tion Tuning. arXiv:2304.08485 [cs.CV] https://arxiv.org/abs/2304.08485
work page internal anchor Pith review arXiv 2023
-
[26]
Weihong Liu, Jiawei Geng, Zongwei Zhu, Jing Cao, and Zirui Lian. 2022. Sniper: cloud-edge collaborative inference scheduling with neural network similarity modeling. InProceedings of the 59th ACM/IEEE Design Automation Conference (San Francisco, California)(DAC ’22). Association for Computing Machinery, New York, NY, USA, 505–510. doi:10.1145/3489517.3530474
-
[27]
Haoxiang Luo, Yinqiu Liu, Ruichen Zhang, Jiacheng Wang, Gang Sun, Dusit Niyato, Hongfang Yu, Zehui Xiong, Xianbin Wang, and Xuemin Shen. 2025. Toward Edge General Intelligence With Multiple-Large Language Model (Multi- LLM): Architecture, Trust, and Orchestration.IEEE Transactions on Cognitive Communications and Networking11, 6 (2025), 3563–3585. doi:10.1...
-
[28]
Brendan McMahan, Eider Moore, Daniel Ramage, Seth Hampson, and Blaise Aguera y Arcas. 2017. Communication-Efficient Learning of Deep Networks from Decentralized Data. InProceedings of the 20th International Conference on Artificial Intelligence and Statistics (Proceedings of Machine Learning Research, Vol. 54), Aarti Singh and Jerry Zhu (Eds.). PMLR, 1273–1282
2017
-
[29]
Sagar Patel, Junyang Zhang, Nina Narodystka, and Sangeetha Abdu Jyothi. 2024. Practically High Performant Neural Adaptive Video Streaming.Proc. ACM Netw. Conference acronym ’XX, June 03–05, 2018, Woodstock, NY Trovato et al. 2, CoNEXT4, Article 30 (Nov. 2024), 23 pages. doi:10.1145/3696401
-
[30]
Vito Andrea Racanelli, Gioacchino Manfredi, Luca De Cicco, and Saverio Mascolo
-
[31]
In2025 IEEE 22nd Consumer Communications & Networking Conference (CCNC)
Real-Time MPC for Adaptive Video Streaming. In2025 IEEE 22nd Consumer Communications & Networking Conference (CCNC). IEEE, Las Vegas, NV, USA, 1–4. doi:10.1109/CCNC54725.2025.10976087
-
[32]
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. 2021. Learning Transferable Visual Models From Natural Language Supervision. arXiv:2103.00020 [cs.CV] https://arxiv.org/ abs/2103.00020
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[33]
Aaditya Singh, Adam Fry, Adam Perelman, et al. 2025. OpenAI GPT-5 System Card. arXiv:2601.03267 [cs.CL] https://arxiv.org/abs/2601.03267
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [34]
-
[35]
Kevin Spiteri, Rahul Urgaonkar, and Ramesh K. Sitaraman. 2020. BOLA: Near- Optimal Bitrate Adaptation for Online Videos.IEEE/ACM Transactions on Net- working28, 4 (Aug. 2020), 1698–1711. doi:10.1109/tnet.2020.2996964
-
[36]
Thomas Stockhammer. 2011. Dynamic adaptive streaming over HTTP –: stan- dards and design principles. InProceedings of the Second Annual ACM Conference on Multimedia Systems(San Jose, CA, USA)(MMSys ’11). Association for Com- puting Machinery, New York, NY, USA, 133–144. doi:10.1145/1943552.1943572
- [37]
-
[38]
Yunjie Tian, Qixiang Ye, and David Doermann. 2025. YOLOv12: Attention-Centric Real-Time Object Detectors. arXiv:2502.12524 [cs.CV] https://arxiv.org/abs/2502. 12524
work page internal anchor Pith review arXiv 2025
-
[39]
Bekir Oguzhan Turkkan, Ting Dai, Adithya Raman, Tevfik Kosar, Changyou Chen, Muhammed Bulut, Jaroslav Zola, and Daby Sow. 2024. GreenABR+: Generalized Energy-Aware Adaptive Bitrate Streaming.ACM Trans. Multimedia Comput. Commun. Appl.20, 9, Article 269 (Aug. 2024), 24 pages. doi:10.1145/3649898
-
[40]
Liang Wang, Kai Lu, Nan Zhang, Xiaoyang Qu, Jianzong Wang, Jiguang Wan, Guokuan Li, and Jing Xiao. 2025. Shoggoth: Towards Efficient Edge-Cloud Collab- orative Real-Time Video Inference via Adaptive Online Learning. InProceedings of the 60th Annual ACM/IEEE Design Automation Conference(San Francisco, Cali- fornia, United States)(DAC ’23). IEEE Press, 1–6....
-
[41]
Yuqin Wang, Jingce Xu, and Wen Ji. 2019. A Feature-based Video Transmission Framework for Visual IoT in Fog Computing Systems. In2019 ACM/IEEE Sympo- sium on Architectures for Networking and Communications Systems (ANCS). 1–8. doi:10.1109/ANCS.2019.8901872
-
[42]
Shiwei Wu, Joya Chen, Kevin Qinghong Lin, Qimeng Wang, Yan Gao, Qianli Xu, Tong Xu, Yao Hu, Enhong Chen, and Mike Zheng Shou. 2024. VideoLLM-MoD: efficient video-language streaming with mixture-of-depths vision computation. In Proceedings of the 38th International Conference on Neural Information Processing Systems(Vancouver, BC, Canada)(NIPS ’24). Curran...
2024
- [43]
-
[44]
Zheming Yang, Wen Ji, Qi Guo, and Zhi Wang. 2023. JAVP: Joint-Aware Video Processing with Edge-Cloud Collaboration for DNN Inference. InProceedings of the 31st ACM International Conference on Multimedia(Ottawa ON, Canada) (MM ’23). Association for Computing Machinery, New York, NY, USA, 9152–9160. doi:10.1145/3581783.3613914
-
[45]
Zheming Yang, Wen Ji, Qi Guo, Jian Zhao, Chang Zhao, Xingzhou Zhang, Yangyu Zhang, Zhicheng Li, and Yang You. 2026. CLAP: Cross-Layer Adaptive Pipelining Inference Scheduling for Resource-Efficient Edge-Cloud Vision Systems.ACM Transactions on Architecture and Code Optimization(2026)
2026
-
[46]
Zheming Yang, Bing Liang, and Wen Ji. 2021. An intelligent end–edge–cloud architecture for visual IoT-assisted healthcare systems.IEEE Internet of Things Journal8, 23 (2021), 16779–16786
2021
-
[47]
Liangqi Yuan, Dong-Jun Han, Shiqiang Wang, and Christopher Brinton. 2025. Local-cloud inference offloading for LLMs in multi-modal, multi-task, multi- dialogue settings. InProceedings of the Twenty-sixth International Symposium on Theory, Algorithmic Foundations, and Protocol Design for Mobile Networks and Mobile Computing. 201–210
2025
-
[48]
Xixi Zheng, You Li, Baokun Zheng, Chuan Zhang, and Liehuang Zhu. 2026. EdgeNetLLM: Cloud–Edge Collaborative Adaptation of Large Language Models for Mobile Networking.IEEE Transactions on Network Science and Engineering13 (2026), 3928–3943. doi:10.1109/TNSE.2025.3624100
-
[49]
Yaowei Zheng, Richong Zhang, Junhao Zhang, Yanhan Ye, Zheyan Luo, Zhangchi Feng, and Yongqiang Ma. 2024. LlamaFactory: Unified Efficient Fine-Tuning of 100+ Language Models. arXiv:2403.13372 [cs.CL] https://arxiv.org/abs/2403. 13372
work page internal anchor Pith review arXiv 2024
-
[50]
Yuanwei Zhu, Yakun Huang, Xiuquan Qiao, Zhijie Tan, Boyuan Bai, Huadong Ma, and Schahram Dustdar. 2023. A Semantic-Aware Transmission With Adap- tive Control Scheme for Volumetric Video Service.Trans. Multi.25 (Jan. 2023), 7160–7172. doi:10.1109/TMM.2022.3217928
-
[51]
Content delivery networks: State of the art, trends, and future roadmap,
Behrouz Zolfaghari, Gautam Srivastava, Swapnoneel Roy, Hamid R. Nemati, Fatemeh Afghah, Takeshi Koshiba, Abolfazl Razi, Khodakhast Bibak, Pinaki Mitra, and Brijesh Kumar Rai. 2020. Content Delivery Networks: State of the Art, Trends, and Future Roadmap.ACM Comput. Surv.53, 2, Article 34 (April 2020), 34 pages. doi:10.1145/3380613
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.