Recognition: 2 theorem links
· Lean TheoremRetrieve-then-Adapt: Retrieval-Augmented Test-Time Adaptation for Sequential Recommendation
Pith reviewed 2026-05-10 19:26 UTC · model grok-4.3
The pith
ReAd adapts pre-trained sequential recommendation models at test time by retrieving collaborative items and fusing them to refine predictions for shifting user preferences.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
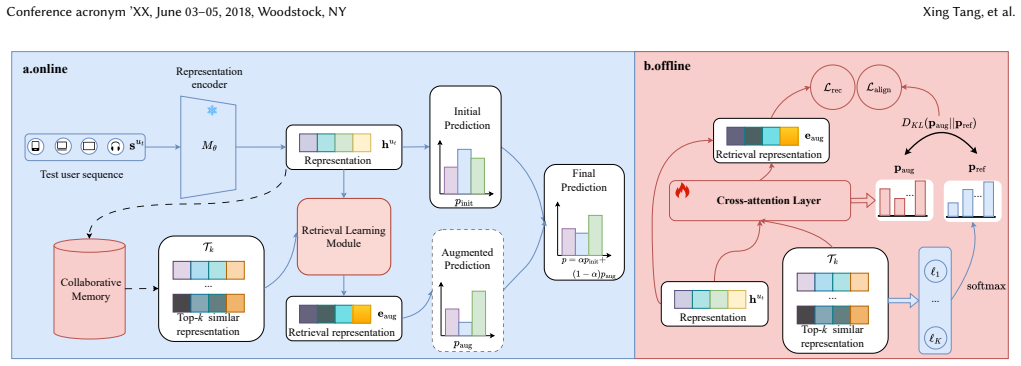
ReAd first retrieves collaboratively similar items for a test user from a constructed collaborative memory database. A lightweight retrieval learning module then integrates these items into an informative augmentation embedding that captures both collaborative signals and prediction-refinement cues. Finally, the initial SR prediction is refined via a fusion mechanism that incorporates this embedding, and experiments across five benchmark datasets show consistent outperformance over existing sequential recommendation methods.
What carries the argument
The ReAd pipeline of collaborative memory retrieval followed by a lightweight module that builds an augmentation embedding and a final fusion step to update the base model's output.
If this is right
- Existing deployed sequential models can be updated at inference without a full two-stage retraining process.
- Test-time adaptation becomes more efficient than methods that require extensive computation or random data changes.
- The method directly tackles distributional shifts between training history and current user sequences.
- Performance gains hold across multiple public datasets when the retrieval and fusion steps are added.
Where Pith is reading between the lines
- Production systems could maintain an evolving memory database to support ongoing adaptation without periodic full model updates.
- The same retrieve-and-fuse pattern might apply to other sequential prediction tasks where preference drift occurs.
- Ablation checks on the fusion weight could reveal how much the retrieved signal contributes versus the base model.
Load-bearing premise
Retrieved items from the memory database supply useful collaborative signals that improve the prediction rather than introduce noise.
What would settle it
Running the five benchmark evaluations with the retrieval component disabled or replaced by random items and finding that performance matches or falls below the unmodified base sequential recommender.
Figures




read the original abstract
The sequential recommendation (SR) task aims to predict the next item based on users' historical interaction sequences. Typically trained on historical data, SR models often struggle to adapt to real-time preference shifts during inference due to challenges posed by distributional divergence and parameterized constraints. Existing approaches to address this issue include test-time training, test-time augmentation, and retrieval-augmented fine-tuning. However, these methods either introduce significant computational overhead, rely on random augmentation strategies, or require a carefully designed two-stage training paradigm. In this paper, we argue that the key to effective test-time adaptation lies in achieving both effective augmentation and efficient adaptation. To this end, we propose Retrieve-then-Adapt (ReAd), a novel framework that dynamically adapts a deployed SR model to the test distribution through retrieved user preference signals. Specifically, given a trained SR model, ReAd first retrieves collaboratively similar items for a test user from a constructed collaborative memory database. A lightweight retrieval learning module then integrates these items into an informative augmentation embedding that captures both collaborative signals and prediction-refinement cues. Finally, the initial SR prediction is refined via a fusion mechanism that incorporates this embedding. Extensive experiments across five benchmark datasets demonstrate that ReAd consistently outperforms existing SR methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Retrieve-then-Adapt (ReAd), a test-time adaptation framework for sequential recommendation. Given a trained SR model, ReAd constructs a collaborative memory database from training interactions, retrieves collaboratively similar items for each test user, processes them via a lightweight retrieval learning module to produce an augmentation embedding, and fuses this embedding with the base model's initial prediction to refine outputs under preference shifts. The central claim is that ReAd consistently outperforms existing SR methods across five benchmark datasets while remaining computationally efficient.
Significance. If the empirical results hold under rigorous validation, ReAd would represent a practical advance in handling distributional shifts in sequential recommendation without the overhead of test-time training or two-stage fine-tuning. The retrieval-plus-lightweight-module design is a strength for efficiency, and the approach could generalize to other online adaptation settings if the net-positive signal extraction is shown to be robust.
major comments (2)
- [§4 and Table 2] §4 (Experiments) and Table 2: the central claim of 'consistent outperformance' across five datasets is load-bearing, yet the reported results lack error bars, standard deviations, or statistical significance tests (e.g., paired t-tests or Wilcoxon tests) comparing ReAd to the strongest baselines. Without these, it is impossible to determine whether the observed gains are reliable or could be explained by variance.
- [§3.2 and §3.3] §3.2 (Retrieval Learning Module) and §3.3 (Fusion Mechanism): the method assumes that similarity-based retrieval from a training-derived memory database will yield net-positive adaptation signals even under test-time preference shifts. No ablation or controlled experiment varies the degree of distributional shift (e.g., by subsampling recent vs. historical interactions or injecting synthetic drift) to test whether the lightweight module and fusion step amplify noise rather than correct it; this directly tests the weakest assumption underlying the outperformance claim.
minor comments (2)
- [§3] The notation for the augmentation embedding and fusion weights is introduced without an explicit equation reference in the method section; adding a single numbered equation would improve clarity.
- [Figure 3] Figure 3 (or equivalent ablation figure) would benefit from clearer axis labels and a legend distinguishing the contribution of retrieval versus the fusion step.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We address each major comment point by point below and will revise the paper accordingly to improve empirical rigor and robustness analysis.
read point-by-point responses
-
Referee: [§4 and Table 2] §4 (Experiments) and Table 2: the central claim of 'consistent outperformance' across five datasets is load-bearing, yet the reported results lack error bars, standard deviations, or statistical significance tests (e.g., paired t-tests or Wilcoxon tests) comparing ReAd to the strongest baselines. Without these, it is impossible to determine whether the observed gains are reliable or could be explained by variance.
Authors: We agree that the absence of error bars, standard deviations, and statistical significance tests weakens the presentation of our empirical results. Although the gains appear consistent across the five datasets in our current reporting, we will revise the experiments section and Table 2 to include standard deviations computed over multiple random seeds (e.g., five runs) and error bars. We will also add paired t-tests or Wilcoxon signed-rank tests comparing ReAd against the strongest baseline on each dataset to establish statistical significance of the improvements. revision: yes
-
Referee: [§3.2 and §3.3] §3.2 (Retrieval Learning Module) and §3.3 (Fusion Mechanism): the method assumes that similarity-based retrieval from a training-derived memory database will yield net-positive adaptation signals even under test-time preference shifts. No ablation or controlled experiment varies the degree of distributional shift (e.g., by subsampling recent vs. historical interactions or injecting synthetic drift) to test whether the lightweight module and fusion step amplify noise rather than correct it; this directly tests the weakest assumption underlying the outperformance claim.
Authors: We acknowledge that a controlled ablation varying the degree of distributional shift would more directly validate the core assumption that our retrieval and fusion steps extract net-positive signals. The five benchmark datasets do exhibit natural differences in temporal preference shifts, but we did not include synthetic drift or subsampling experiments. In the revision, we will add such an ablation study (e.g., by restricting the memory database to recent interactions or injecting controlled preference noise) to demonstrate that the lightweight module and fusion mechanism remain beneficial rather than amplifying noise under increasing shift severity. revision: yes
Circularity Check
No circularity: ReAd is a constructive retrieval-augmented framework validated by external benchmarks.
full rationale
The paper presents ReAd as a novel test-time adaptation method that retrieves collaborative signals from a memory database (built on historical interactions), processes them via a lightweight module into an augmentation embedding, and fuses the result with the base SR model's output. This is a standard engineering pipeline with no mathematical derivation chain that reduces to its own inputs by construction. No self-definitional steps, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided description. The outperformance claim rests on empirical results across five datasets rather than tautological definitions or ansatzes smuggled via prior work. The method is self-contained against external benchmarks and does not invoke uniqueness theorems or renamings of known results.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
ReAd first retrieves collaboratively similar items for a test user from a constructed collaborative memory database. A lightweight retrieval learning module then integrates these items into an informative augmentation embedding...
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
the fusion weight α is computed as: α = exp(1/(1+H_init_top)) / (exp(1/(1+H_init_top)) + exp(1/(1+H_aug_top)))
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Shuqing Bian, Wayne Xin Zhao, Jinpeng Wang, and Ji-Rong Wen. 2022. A relevant and diverse retrieval-enhanced data augmentation framework for sequential recommendation. InProceedings of the 31st ACM International Conference on Information & Knowledge Management. 2923–2932
2022
-
[2]
Zheng Chai, Qin Ren, Xijun Xiao, Huizhi Yang, Bo Han, Sijun Zhang, Di Chen, Hui Lu, Wenlin Zhao, Lele Yu, et al . 2025. Longer: Scaling up long sequence modeling in industrial recommenders. InProceedings of the Nineteenth ACM Conference on Recommender Systems. 247–256
2025
-
[3]
Yongjun Chen, Zhiwei Liu, Jia Li, Julian McAuley, and Caiming Xiong. 2022. Intent contrastive learning for sequential recommendation. InProceedings of the ACM Web Conference 2022. 2172–2182
2022
- [4]
-
[5]
Ziqiang Cui, Haolun Wu, Bowei He, Ji Cheng, and Chen Ma. 2024. Context Matters: Enhancing Sequential Recommendation with Context-aware Diffusion- based Contrastive Learning. InProceedings of the 33rd ACM International Con- ference on Information and Knowledge Management(Boise, ID, USA)(CIKM ’24). Association for Computing Machinery, New York, NY, USA, 404–414
2024
-
[6]
Yizhou Dang, Yuting Liu, Enneng Yang, Minhan Huang, Guibing Guo, Jianzhe Zhao, and Xingwei Wang. 2025. Data augmentation as free lunch: Exploring the test-time augmentation for sequential recommendation. InProceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval. 1466–1475
2025
-
[7]
Matthijs Douze, Alexandr Guzhva, Chengqi Deng, Jeff Johnson, Gergely Szilvasy, Pierre-Emmanuel Mazaré, Maria Lomeli, Lucas Hosseini, and Hervé Jégou. 2024. The Faiss library. (2024). arXiv:2401.08281 [cs.LG]
work page internal anchor Pith review arXiv 2024
-
[8]
Wenqi Fan, Yujuan Ding, Liangbo Ning, Shijie Wang, Hengyun Li, Dawei Yin, Tat-Seng Chua, and Qing Li. 2024. A survey on rag meeting LLMs: Towards retrieval-augmented large language models. InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 6491–6501
2024
-
[9]
Xinqi Fan, Xueli Chen, Luoxiao Yang, Chuin Hong Yap, Rizwan Qureshi, Qi Dou, Moi Hoon Yap, and Mubarak Shah. 2025. Test-Time Retrieval-Augmented Adap- tation for Vision-Language Models. InProceedings of the IEEE/CVF International Conference on Computer Vision. 8810–8819
2025
-
[10]
Yunfan Gao, Yun Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Yuxi Bi, Yixin Dai, Jiawei Sun, Haofen Wang, and Haofen Wang. 2023. Retrieval-augmented generation for large language models: A survey.arXiv preprint arXiv:2312.10997 2, 1 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[11]
Ruining He and Julian McAuley. 2016. Fusing similarity models with markov chains for sparse sequential recommendation. In2016 IEEE 16th international conference on data mining (ICDM). IEEE, 191–200
2016
-
[12]
Balázs Hidasi and Alexandros Karatzoglou. 2018. Recurrent Neural Networks with Top-k Gains for Session-based Recommendations. InProceedings of the 27th ACM International Conference on Information and Knowledge Management (Torino, Italy)(CIKM ’18). Association for Computing Machinery, New York, NY, USA, 843–852
2018
-
[13]
Wei Jin, Tong Zhao, Jiayuan Ding, Yozen Liu, Jiliang Tang, and Neil Shah. 2023. Empowering Graph Representation Learning with Test-Time Graph Transforma- tion. InICLR
2023
-
[14]
Wang-Cheng Kang and Julian McAuley. 2018. Self-Attentive Sequential Rec- ommendation . In2018 IEEE International Conference on Data Mining (ICDM). IEEE Computer Society, Los Alamitos, CA, USA, 197–206. doi:10.1109/ICDM. 2018.00035
-
[15]
Diederik P Kingma. 2014. Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980(2014)
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[16]
Youngjun Lee, Doyoung Kim, Junhyeok Kang, Jihwan Bang, Hwanjun Song, and Jae-Gil Lee. 2025. RA-TTA: Retrieval-Augmented Test-Time Adaptation for Vision-Language Models. InThe Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025. OpenReview.net
2025
-
[17]
Siyi Liu and Yujia Zheng. 2020. Long-tail Session-based Recommendation. In Proceedings of the 14th ACM Conference on Recommender Systems(Virtual Event, Brazil)(RecSys ’20). Association for Computing Machinery, New York, NY, USA, 509–514
2020
-
[18]
Yuejiang Liu, Parth Kothari, Bastien van Delft, Baptiste Bellot-Gurlet, Taylor Mordan, and Alexandre Alahi. 2021. TTT++: when does self-supervised test-time training fail or thrive?. InProceedings of the 35th International Conference on Neural Information Processing Systems (NIPS ’21). Curran Associates Inc., Red Hook, NY, USA, Article 1669, 13 pages
2021
- [19]
-
[20]
Aleksandr Petrov and Craig Macdonald. 2022. A Systematic Review and Replica- bility Study of BERT4Rec for Sequential Recommendation. InProceedings of the 16th ACM Conference on Recommender Systems(Seattle, WA, USA)(RecSys ’22). Association for Computing Machinery, New York, NY, USA, 436–447
2022
-
[22]
Xiuyuan Qin, Huanhuan Yuan, Pengpeng Zhao, Junhua Fang, Fuzhen Zhuang, Guanfeng Liu, Yanchi Liu, and Victor Sheng. 2023. Meta-optimized Contrastive Learning for Sequential Recommendation. InProceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval. 89–98
2023
-
[23]
Xiuyuan Qin, Huanhuan Yuan, Pengpeng Zhao, Guanfeng Liu, Fuzhen Zhuang, and Victor S. Sheng. 2024. Intent Contrastive Learning with Cross Subsequences for Sequential Recommendation. InProceedings of the 17th ACM International Con- ference on Web Search and Data Mining(Merida, Mexico)(WSDM ’24). Association for Computing Machinery, New York, NY, USA, 548–556
2024
-
[24]
Ruihong Qiu, Zi Huang, Hongzhi Yin, and Zijian Wang. 2022. Contrastive learning for representation degeneration problem in sequential recommendation. InProceedings of the fifteenth ACM international conference on web search and data mining. 813–823
2022
-
[25]
Steffen Rendle, Christoph Freudenthaler, and Lars Schmidt-Thieme. 2010. Factor- izing personalized Markov chains for next-basket recommendation. InProceedings of the 19th International Conference on World Wide Web(Raleigh, North Carolina, USA)(WWW ’10). Association for Computing Machinery, New York, NY, USA, 811–820
2010
-
[26]
Divya Shanmugam, Davis Blalock, Guha Balakrishnan, and John Guttag. 2021. Better aggregation in test-time augmentation. InProceedings of the IEEE/CVF international conference on computer vision. 1214–1223
2021
-
[27]
Fei Sun, Jun Liu, Jian Wu, Changhua Pei, Xiao Lin, Wenwu Ou, and Peng Jiang
-
[28]
InProceedings of the 28th ACM International Conference on Information and Knowledge Management(Beijing, China)(CIKM ’19)
BERT4Rec: Sequential Recommendation with Bidirectional Encoder Rep- resentations from Transformer. InProceedings of the 28th ACM International Conference on Information and Knowledge Management(Beijing, China)(CIKM ’19). Association for Computing Machinery, New York, NY, USA, 1441–1450
-
[29]
Jiaxi Tang and Ke Wang. 2018. Personalized Top-N Sequential Recommendation via Convolutional Sequence Embedding. InProceedings of the Eleventh ACM International Conference on Web Search and Data Mining(Marina Del Rey, CA, USA)(WSDM ’18). Association for Computing Machinery, New York, NY, USA, 565–573
2018
-
[30]
Xing Tang, Chaohua Yang, Yuwen Fu, Dongyang Ao, Shiwei Li, Fuyuan Lyu, Dugang Liu, and Xiuqiang He. 2025. Retrieval Augmented Cross-Domain Life- Long Behavior Modeling for Enhancing Click-through Rate Prediction. InPro- ceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 2. 4891–4900
2025
-
[31]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need.Advances in neural information processing systems30 (2017)
2017
-
[32]
Junda Wu, Cheng-Chun Chang, Tong Yu, Zhankui He, Jianing Wang, Yupeng Hou, and Julian McAuley. 2024. CoRAL: Collaborative Retrieval-Augmented Large Language Models Improve Long-tail Recommendation. InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (Barcelona, Spain)(KDD ’24). Association for Computing Machinery, New Yo...
2024
-
[33]
Shu Wu, Yuyuan Tang, Yanqiao Zhu, Liang Wang, Xing Xie, and Tieniu Tan
-
[34]
Session-based recommendation with graph neural networks. InProceedings of the Thirty-Third AAAI Conference on Artificial Intelligence and Thirty-First Innovative Applications of Artificial Intelligence Conference and Ninth AAAI Sym- posium on Educational Advances in Artificial Intelligence(Honolulu, Hawaii, USA) (AAAI’19/IAAI’19/EAAI’19). AAAI Press, Arti...
-
[35]
Zihao Wu, Xin Wang, Hong Chen, Kaidong Li, Yi Han, Lifeng Sun, and Wenwu Zhu. 2023. Diff4Rec: Sequential Recommendation with Curriculum-scheduled Diffusion Augmentation. InProceedings of the 31st ACM International Confer- ence on Multimedia(Ottawa ON, Canada)(MM ’23). Association for Computing Machinery, New York, NY, USA, 9329–9335
2023
-
[36]
Wenjia Xie, Hao Wang, Minghao Fang, Ruize Yu, Wei Guo, Yong Liu, Defu Lian, and Enhong Chen. 2025. Breaking the Bottleneck: User-Specific Optimization and Real-Time Inference Integration for Sequential Recommendation. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V
2025
-
[37]
Xu Xie, Fei Sun, Zhaoyang Liu, Shiwen Wu, Jinyang Gao, Jiandong Zhang, Bolin Ding, and Bin Cui. 2022. Contrastive learning for sequential recommendation. In 2022 IEEE 38th international conference on data engineering (ICDE). IEEE, 1259– 1273
2022
-
[38]
Jian Xu, Sichun Luo, Xiangyu Chen, Haoming Huang, Hanxu Hou, and Linqi Song. 2025. RALLRec: Improving Retrieval Augmented Large Language Model Recommendation with Representation Learning. InCompanion Proceedings of the ACM on Web Conference 2025(Sydney NSW, Australia)(WWW ’25). Association for Computing Machinery, New York, NY, USA, 1436–1440. Conference ...
2025
-
[39]
Lanling Xu, Zhen Tian, Gaowei Zhang, Junjie Zhang, Lei Wang, Bowen Zheng, Yifan Li, Jiakai Tang, Zeyu Zhang, Yupeng Hou, Xingyu Pan, Wayne Xin Zhao, Xu Chen, and Ji-Rong Wen. 2023. Towards a More User-Friendly and Easy-to-Use Benchmark Library for Recommender Systems. InSIGIR. ACM, 2837–2847
2023
-
[40]
Xihong Yang, Yiqi Wang, Jin Chen, Wenqi Fan, Xiangyu Zhao, En Zhu, Xinwang Liu, and Defu Lian. 2025. Dual Test-Time Training for Out-of-Distribution Recommender System.IEEE Trans. on Knowl. and Data Eng.37, 6 (March 2025), 3312–3326
2025
- [41]
-
[42]
Yufei Ye, Wei Guo, Jin Yao Chin, Hao Wang, Hong Zhu, Xi Lin, Yuyang Ye, Yong Liu, Ruiming Tang, Defu Lian, and Enhong Chen. 2025. FuXi-𝛼: Scaling Recom- mendation Model with Feature Interaction Enhanced Transformer. InCompanion Proceedings of the ACM on Web Conference 2025(Sydney NSW, Australia)(WWW ’25). Association for Computing Machinery, New York, NY,...
2025
-
[43]
Jose, and Xiangnan He
Fajie Yuan, Alexandros Karatzoglou, Ioannis Arapakis, Joemon M. Jose, and Xiangnan He. 2019. A Simple Convolutional Generative Network for Next Item Recommendation. InProceedings of the Twelfth ACM International Conference on Web Search and Data Mining(Melbourne VIC, Australia)(WSDM ’19). Association for Computing Machinery, New York, NY, USA, 582–590
2019
-
[44]
Jiaqi Zhai, Lucy Liao, Xing Liu, Yueming Wang, Rui Li, Xuan Cao, Leon Gao, Zhaojie Gong, Fangda Gu, Jiayuan He, et al . 2024. Actions speak louder than words: trillion-parameter sequential transducers for generative recommendations. InProceedings of the 41st International Conference on Machine Learning. 58484– 58509
2024
-
[45]
Changshuo Zhang, Xiao Zhang, Teng Shi, Jun Xu, and Ji-Rong Wen. 2025. Test- Time Alignment with State Space Model for Tracking User Interest Shifts in Sequential Recommendation. InProceedings of the Nineteenth ACM Conference on Recommender Systems (RecSys ’25). Association for Computing Machinery, New York, NY, USA, 461–471
2025
- [46]
- [47]
-
[48]
Kun Zhou, Hui Wang, Wayne Xin Zhao, Yutao Zhu, Sirui Wang, Fuzheng Zhang, Zhongyuan Wang, and Ji-Rong Wen. 2020. S3-rec: Self-supervised learning for se- quential recommendation with mutual information maximization. InProceedings of the 29th ACM international conference on information & knowledge management. 1893–1902
2020
-
[49]
Kun Zhou, Hui Yu, Wayne Xin Zhao, and Ji-Rong Wen. 2022. Filter-enhanced MLP is All You Need for Sequential Recommendation. InProceedings of the ACM Web Conference 2022(Virtual Event, Lyon, France)(WWW ’22). Association for Computing Machinery, New York, NY, USA, 2388–2399
2022
-
[50]
Peilin Zhou, Jingqi Gao, Yueqi Xie, Qichen Ye, Yining Hua, Jaeboum Kim, Shoujin Wang, and Sunghun Kim. 2023. Equivariant contrastive learning for sequential recommendation. InProceedings of the 17th ACM Conference on Recommender Systems. 129–140
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.