Recognition: 2 theorem links
· Lean TheoremPROMISE: Proof Automation as Structural Imitation of Human Reasoning
Pith reviewed 2026-05-10 19:03 UTC · model grok-4.3
The pith
Mining structural patterns from proof states and tactic transitions enables more reliable automated proof generation than single-shot or shallow methods.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that reframing proof generation as iterative search over proof-state transitions, supported by mining structural embeddings from states and tactic applications, allows retrieval and adaptation of valid proof fragments and thereby outperforms prior single-shot generation or shallow retrieval techniques on challenging formal verification problems.
What carries the argument
Structure-aware proof mining that extracts embeddings from sequences of proof states and tactic transitions to enable retrieval and composition of compatible fragments during iterative search.
If this is right
- Higher rates of successful proof completion on tasks with many interdependent steps.
- More stable performance when swapping the underlying language model used for adaptation.
- Improved ability to handle structural dependencies that cause earlier methods to fail.
- Greater overall scalability for verification projects that currently require years of manual work.
Where Pith is reading between the lines
- The emphasis on state transitions suggests that tracking proof history explicitly could improve other sequential reasoning tasks in AI.
- Patterns learned in one formal system might transfer to related logics if the structural embeddings capture general properties of proof construction.
- Combining the retrieval step with symbolic checking could further reduce the chance of unsound compositions.
Load-bearing premise
The mined structural patterns from proof states and tactic transitions will consistently produce logically sound fragments that compose correctly into complete proofs for large tasks.
What would settle it
A head-to-head evaluation on a large collection of interdependent theorems where the structure-mining approach completes no more proofs than baseline methods or produces many fragments that fail to compose into valid proofs.
Figures

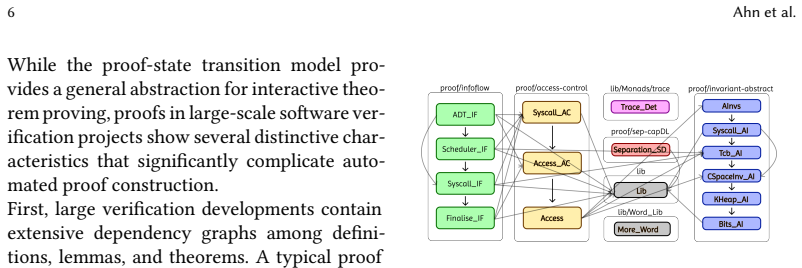
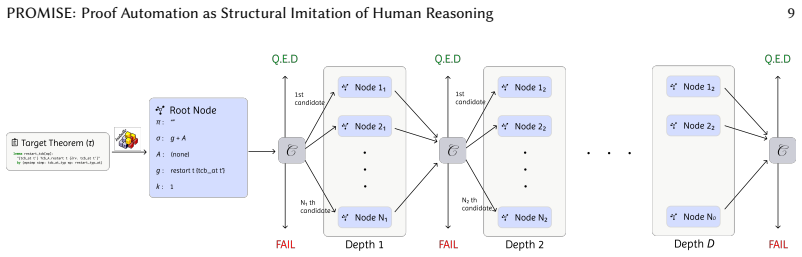


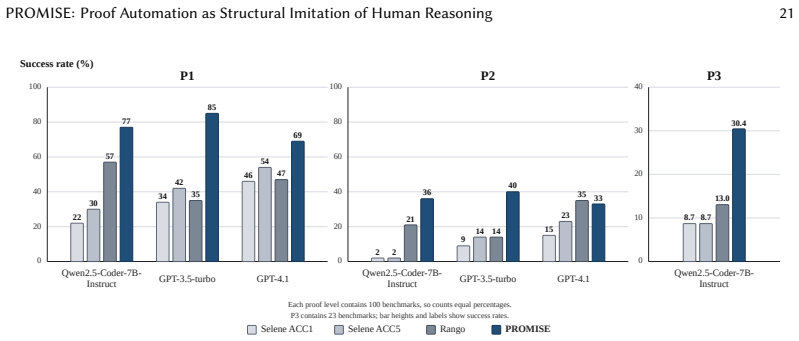
read the original abstract
Automated proof generation for formal software verification remains largely unresolved despite advances in large language models (LLMs). While LLMs perform well in NLP, vision, and code generation, formal verification still requires substantial human effort. Interactive theorem proving (ITP) demands manual proof construction under strict logical constraints, limiting scalability; for example, verifying the seL4 microkernel required decades of effort. Existing LLM-based approaches attempt to automate this process but remain limited. Most rely on single-shot generation or shallow retrieval, which may work for small proofs but fail to scale to large, interdependent verification tasks with deep structural dependencies. We present PROMISE (PROof MIning via Structural Embeddings), a structure-aware framework that reframes proof generation as a stateful search over proof-state transitions. Instead of surface-level retrieval, PROMISE mines structural patterns from proof states and tactic transitions, enabling retrieval and adaptation of compatible proof fragments during iterative search. We evaluate PROMISE on the seL4 benchmark across multiple LLM backends and compare it with prior systems such as Selene and Rango. PROMISE consistently outperforms prior methods, achieving up to +26 point improvements (186% relative gain) while maintaining robustness across models, demonstrating the effectiveness of structure-aware proof mining for scalable theorem proving.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PROMISE (PROof MIning via Structural Embeddings), a structure-aware framework that reframes automated proof generation for interactive theorem proving as stateful search over mined structural patterns from proof states and tactic transitions rather than single-shot or shallow retrieval. It evaluates the approach on the seL4 benchmark across multiple LLM backends, claiming consistent outperformance over prior systems such as Selene and Rango with gains of up to +26 points (186% relative improvement) and robustness across models.
Significance. If the experimental claims hold under rigorous scrutiny, the work could meaningfully advance scalable automation of formal verification by imitating human-like structural reasoning in proof construction, addressing a key bottleneck in large interdependent tasks like seL4 verification that have historically required decades of manual effort.
major comments (1)
- [Abstract] Abstract: The central claim of consistent outperformance with up to +26 point (186% relative) gains on the seL4 benchmark is asserted without any description of the evaluation protocol, statistical testing, baseline implementations, controls for data leakage, or how proof fragments are ensured to compose soundly. This information is load-bearing for verifying the reported improvements and is entirely absent from the provided manuscript text.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. We address the major comment point by point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim of consistent outperformance with up to +26 point (186% relative) gains on the seL4 benchmark is asserted without any description of the evaluation protocol, statistical testing, baseline implementations, controls for data leakage, or how proof fragments are ensured to compose soundly. This information is load-bearing for verifying the reported improvements and is entirely absent from the provided manuscript text.
Authors: We agree that the abstract, as currently written, does not provide sufficient detail on the evaluation protocol to support the reported gains. The full manuscript contains an Experiments section describing the seL4 benchmark, comparisons against Selene and Rango (with baseline re-implementations), use of multiple LLM backends, and our structural embedding approach for ensuring compatible proof fragment composition. However, explicit discussion of statistical testing procedures and data-leakage controls is not present at the level of detail the referee requests. We will revise the abstract to include a concise summary of the evaluation protocol, and we will expand the Experiments section to add the missing details on statistical testing, leakage controls, and soundness verification. revision: yes
Circularity Check
No circularity: framework and gains presented as empirical comparison to external baselines
full rationale
The abstract introduces PROMISE as a new structure-aware mining approach over proof states and tactic transitions, evaluated on the public seL4 benchmark against independent prior systems (Selene, Rango). No equations, fitted parameters renamed as predictions, self-citations, or derivation steps are supplied that reduce the claimed gains to the inputs by construction. The central claim rests on reported outperformance (+26 points) rather than any internal redefinition or uniqueness theorem imported from the authors' prior work. Full manuscript details are unavailable in the given text, but nothing in the provided content exhibits the enumerated circular patterns.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat ≃ Nat recovery unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We evaluate PROMISE on the seL4 benchmark across multiple LLM backends
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Tudor Achim, Alex Best, Alberto Bietti, Kevin Der, Mathïs Fédérico, Sergei Gukov, Daniel Halpern-Leistner, Kirsten Henningsgard, Yury Kudryashov, Alexander Meiburg, Martin Michelsen, Riley Patterson, Eric Rodriguez, Laura Scharff, Vikram Shanker, Vladmir Sicca, Hari Sowrirajan, Aidan Swope, Matyas Tamas, Vlad Tenev, Jonathan Thomm, Harold Williams, and La...
work page internal anchor Pith review arXiv 2025
-
[2]
Filippos Bellos, Yayuan Li, Wuao Liu, and Jason Corso. 2024. Can Large Language Models Reason About Goal-Oriented Tasks?. InProceedings of the First edition of the Workshop on the Scaling Behavior of Large Language Models (SCALE- LLM 2024). Association for Computational Linguistics, St. Julian’s, Malta, 24–34.doi:10.18653/v1/2024.scalellm-1.3
-
[3]
2010.Interactive Theorem Proving and Program Development: Coq ’Art The Calculus of Inductive Constructions (1st ed.)
Yves Bertot and Pierre Castran. 2010.Interactive Theorem Proving and Program Development: Coq ’Art The Calculus of Inductive Constructions (1st ed.). Springer Publishing Company, Incorporated
2010
-
[4]
Lasse Blaauwbroek, Mirek Olsák, Jason Rute, Fidel Ivan Schaposnik Massolo, Jelle Piepenbrock, and Vasily Pestun
-
[5]
InForty-first International Conference on Machine Learning, ICML 2024, Vienna, Austria, July 21-27, 2024
Graph2Tac: Online Representation Learning of Formal Math Concepts. InForty-first International Conference on Machine Learning, ICML 2024, Vienna, Austria, July 21-27, 2024 . OpenReview.net. https://openreview.net/forum? id=A7CtiozznN
2024
-
[6]
Sascha Böhme and Tobias Nipkow. 2010. Sledgehammer: Judgement Day. InAutomated Reasoning, 5th International Joint Conference, IJCAR 2010, Edinburgh, UK, July 16-19, 2010. Proceedings(Lecture Notes in Computer Science, Vol. 6173), Jürgen Giesl and Reiner Hähnle(Eds.). Springer, 107–121. doi:10.1007/978-3-642-14203-1_9
-
[7]
Haogang Chen, Daniel Ziegler, Tej Chajed, Adam Chlipala, Frans Kaashoek, and Nickolai Zeldovich. 2015. Using Crash Hoare logic for certifying the FSCQ file system. InProceedings of the 25th Symposium on Operating Systems Principles. ACM, 18–33. doi:10.1145/2815400.2815402
-
[8]
Xiang Cheng, Chengyan Pan, Minjun Zhao, Deyang Li, Fangchao Liu, Xinyu Zhang, Xiao Zhang, and Yong Liu. 2025. Revisiting Chain-of-Thought Prompting: Zero-shot Can Be Stronger than Few-shot. InFindings of the Association for Computational Linguistics: EMNLP 2025 . Association for Computational Linguistics, Suzhou, China, 13533–13554. doi:10.18653/v1/2025.f...
-
[9]
Lukasz Czajka and Cezary Kaliszyk. 2018. Hammer for Coq: Automation for Dependent Type Theory. J. Autom. Reason. 61, 1-4 (2018), 423–453. doi:10.1007/S10817-018-9458-4
-
[10]
In: Chandra, S., Blincoe, K., Tonella, P
Emily First, Markus N. Rabe, Talia Ringer, and Yuriy Brun. 2023. Baldur: Whole-Proof Generation and Repair with Large Language Models. InProceedings of the 31st ACM Joint European Software Engineering Conference and Sympo- sium on the Foundations of Software Engineering(San Francisco, CA, USA) (ESEC/FSE 2023). Association for Computing Machinery, New York...
-
[11]
2026.lf-lean: The frontier of verified software engineering.Theorem Blog (feb 2026)
Jason Gross, Vishesh Saraswat, Jeffrey Chang, Harshikaa Agrawal, Vaidehi Agarwalla, Robert Zhang, Twm Stone, Jacob Green, Shiki Vaahan, Lawrence Chan, and Rajashree Agrawal. 2026.lf-lean: The frontier of verified software engineering.Theorem Blog (feb 2026). https://theorem.dev/blog/lf-lean/
2026
-
[12]
Liang Gu, Alexander Vaynberg, Bryan Ford, Zhong Shao, and David Costanzo. 2011. CertiKOS: a certified kernel for secure cloud computing. InProceedings of the Second Asia-Pacific Workshop on Systems (Shanghai, China) (APSys ’11). Association for Computing Machinery, New York, NY, USA, Article 3, 5 pages.doi:10.1145/2103799.2103803
-
[13]
Binyuan Hui, Jian Yang, Zeyu Cui, Jiaxi Yang, Dayiheng Liu, Lei Zhang, Tianyu Liu, Jiajun Zhang, Bowen Yu, Keming Lu, Kai Dang, Yang Fan, Yichang Zhang, An Yang, Rui Men, Fei Huang, Bo Zheng, Yibo Miao, Shanghaoran Quan, Yunlong Feng, Xingzhang Ren, Xuancheng Ren, Jingren Zhou, and Junyang Lin. 2024. Qwen2.5-Coder Technical Report. arXiv:2409.12186 [cs.CL...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
Saketh Ram Kasibatla, Arpan Agarwal, Yuriy Brun, Sorin Lerner, Talia Ringer, and Emily First. 2025. Cobblestone: A Divide-and-Conquer Approach for Automating Formal Verification. arXiv:2410.19940 [cs.LO] https://arxiv.org/abs/ 2410.19940
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
Gerwin Klein, June Andronick, Kevin Elphinstone, Toby Murray, Thomas Sewell, Rafal Kolanski, and Gernot Heiser
-
[16]
Comprehensive Formal Verification of an OS Microkernel.ACM Transactions on Computer Systems 32, 1 (Feb. 2014), 2:1–2:70. doi:10.1145/2560537
- [17]
-
[18]
Gerwin Klein, Kevin Elphinstone, Gernot Heiser, June Andronick, David Cock, Philip Derrin, Dhammika Elkaduwe, Kai Engelen, Rafal Kolanski, Michael Norrish, Thomas Sewell, Harvey Tuch, and Simon Winwood. 2009. seL4: Formal Verification of an OS Kernel. InACM Symposium on Operating Systems Principles . Big Sky, MT, USA, 207–220. doi:10. 1145/1629575.1629596
-
[19]
Gerwin Klein, Kevin Elphinstone, Gernot Heiser, June Andronick, David Cock, Philip Derrin, Dhammika Elkaduwe, Kai Engelhardt, Rafal Kolanski, Michael Norrish, Thomas Sewell, Harvey Tuch, and Simon Winwood. 2009. seL4: For- mal Verification of an OS Kernel. InProceedings of the ACM SIGOPS 22nd Symposium on Operating Systems Principles . PROMISE: Proof Auto...
2009
-
[20]
Lorch, Oded Padon, and Bryan Parno
Andrea Lattuada, Travis Hance, Jay Bosamiya, Matthias Brun, Chanhee Cho, Hayley LeBlanc, Pranav Srinivasan, Reto Achermann, Tej Chajed, Chris Hawblitzel, Jon Howell, Jacob R. Lorch, Oded Padon, and Bryan Parno. 2024. Verus: A Practical Foundation for Systems Verification. InProceedings of the ACM SIGOPS 30th Symposium on Operating Systems Principles (Aust...
2024
-
[21]
doi:10.1145/3694715.3695952
-
[22]
Rustan M
K. Rustan M. Leino. 2010. Dafny: an automatic program verifier for functional correctness. InProceedings of the 16th International Conference on Logic for Programming, Artificial Intelligence, and Reasoning (Dakar, Senegal) (LPAR’10). Springer-Verlag, Berlin, Heidelberg, 348–370
2010
-
[23]
Xavier Leroy. 2009. A formally verified compiler back-end.Journal of Automated Reasoning 43, 4 (2009), 363–446. http://xavierleroy.org/publi/compcert-backend.pdf
2009
-
[24]
Aman Madaan, Katherine Hermann, and Amir Yazdanbakhsh. 2023. What Makes Chain-of-Thought Prompting Effec- tive? A Counterfactual Study. InFindings of the Association for Computational Linguistics: EMNLP 2023 . Association for Computational Linguistics, Singapore, 1448–1535.doi:10.18653/v1/2023.findings-emnlp.101
-
[25]
Jiang, Jin Peng Zhou, Christian Szegedy, Lukasz Kucinski, Piotr Milos, and Yuhuai Wu
Maciej Mikula, Szymon Tworkowski, Szymon Antoniak, Bartosz Piotrowski, Albert Q. Jiang, Jin Peng Zhou, Christian Szegedy, Lukasz Kucinski, Piotr Milos, and Yuhuai Wu. 2024. Magnushammer: A Transformer-Based Approach to Premise Selection. InThe Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenRev...
2024
-
[26]
Leonardo de Moura and Sebastian Ullrich. 2021. The Lean 4 Theorem Prover and Programming Language. InAuto- mated Deduction – CADE 28: 28th International Conference on Automated Deduction, Virtual Event, July 12–15, 2021, Proceedings. Springer-Verlag, Berlin, Heidelberg, 625–635.doi:10.1007/978-3-030-79876-5_37
-
[27]
Toby Murray, Daniel Matichuk, Matthew Brassil, Peter Gammie, Timothy Bourke, Sean Seefried, Corey Lewis, Xin Gao, and Gerwin Klein. 2013. seL4: from General Purpose to a Proof of Information Flow Enforcement. In2013 IEEE Symposium on Security and Privacy . IEEE, San Francisco, CA, USA, 415–429.doi:10.1109/SP.2013.35
-
[28]
Tobias Nipkow, Markus Wenzel, and Lawrence C. Paulson. 2002.Isabelle/HOL: a proof assistant for higher-order logic . Springer-Verlag, Berlin, Heidelberg
2002
-
[29]
OpenAI. 2025. Introducing GPT-4.1 in the API.https://openai.com/index/gpt-4-1/. Published April 14, 2025
2025
-
[30]
Zoe Paraskevopoulou, John M. Li, and Andrew W. Appel. 2021. Compositional optimizations for CertiCoq.Proc. ACM Program. Lang. 5, ICFP, Article 86(Aug. 2021), 30 pages. doi:10.1145/3473591
-
[31]
Jianxing Qin, Alexander Du, Danfeng Zhang, Matthew Lentz, and Danyang Zhuo. 2025. Can Large Language Models Verify System Software? A Case Study Using FSCQ as a Benchmark. InProceedings of the 2025 Workshop on Hot Topics in Operating Systems (Banff, AB, Canada) (HotOS ’25). Association for Computing Machinery, New York, NY, USA, 34–41. doi:10.1145/3713082.3730382
-
[32]
Z. Z. Ren, Zhihong Shao, Junxiao Song, Huajian Xin, Haocheng Wang, Wanjia Zhao, Liyue Zhang, Zhe Fu, Qihao Zhu, Dejian Yang, Z. F. Wu, Zhibin Gou, Shirong Ma, Hongxuan Tang, Yuxuan Liu, Wenjun Gao, Daya Guo, and Chong Ruan. 2025. DeepSeek-Prover-V2: Advancing Formal Mathematical Reasoning via Reinforcement Learning for Subgoal Decomposition. arXiv:2504.21...
work page internal anchor Pith review arXiv 2025
-
[33]
Talia Ringer, Karl Palmskog, Ilya Sergey, Milos Gligoric, and Zachary Tatlock. 2019. QED at Large: A Survey of Engineering of Formally Verified Software.Found. Trends Program. Lang. 5, 2–3 (Sept. 2019), 102–281. doi:10.1561/ 2500000045
2019
-
[34]
seL4 Foundation. 2026. Fact Sheet.https://sel4.systems/About/fact-sheet.html. Accessed 2026-03-17
2026
-
[35]
seL4 Foundation. 2026. seL4 White Paper.https://sel4.systems/About/whitepaper.html. Accessed 2026-03-17
2026
-
[36]
seL4 Foundation. 2026. Verification.https://sel4.systems/Verification/. Accessed 2026-03-17
2026
-
[37]
seL4 Project. 2026. The L4.verified Proofs.https://github.com/seL4/l4v. GitHub repository, accessed 2026-03-17
2026
-
[38]
Chenming Tang, Zhixiang Wang, Hao Sun, and Yunfang Wu. 2025. Large Language Models Might Not Care What You Are Saying: Prompt Format Beats Descriptions. InFindings of the Association for Computational Linguistics: EMNLP
2025
-
[39]
Association for Computational Linguistics, Suzhou, China, 26–48.doi:10.18653/v1/2025.findings-emnlp.3
-
[40]
Kyle Thompson, Nuno Saavedra, Pedro Carrott, Kevin Fisher, Alex Sanchez-Stern, Yuriy Brun, João F. Ferreira, Sorin Lerner, and Emily First. 2025. Rango: Adaptive Retrieval-Augmented Proving for Automated Software Verification. In Proceedings of the IEEE/ACM 47th International Conference on Software Engineering (Ottawa, Ontario, Canada) (ICSE ’25). IEEE Pr...
-
[41]
Yixiao Wang, Keith E. Green, and Ian D. Walker. 2016. CoPRA: a Design Exemplar for Habitable, Cyber-physical Environment. InProceedings of the 2016 CHI Conference Extended Abstracts on Human Factors in Computing Systems (San Jose, California, USA) ( CHI EA ’16). Association for Computing Machinery, New York, NY, USA, 1407–1414. doi:10.1145/2851581.2892333
-
[42]
Goodman, Qiaochu Chen, and Işıl Dillig
Yutong Xin, Jimmy Xin, Gabriel Poesia, Noah D. Goodman, Qiaochu Chen, and Işıl Dillig. 2025.TacMiner: Automated Discovery of Tactic Libraries for Interactive Theorem Proving . https://doi.org/10.5281/zenodo.15761151 26 Ahn et al
-
[43]
Lorch, Shuai Lu, Fan Yang, Ziqiao Zhou, and Shan Lu
Chenyuan Yang, Xuheng Li, Md Rakib Hossain Misu, Jianan Yao, Weidong Cui, Yeyun Gong, Chris Hawblitzel, Shu- vendu Lahiri, Jacob R. Lorch, Shuai Lu, Fan Yang, Ziqiao Zhou, and Shan Lu. 2025. AutoVerus: Automated Proof Gen- eration for Rust Code.Proc. ACM Program. Lang. 9, OOPSLA2, Article 396(Oct. 2025), 29 pages. doi:10.1145/3763174
-
[44]
Kaiyu Yang, Aidan Swope, Alex Gu, Rahul Chalamala, Peiyang Song, Shixing Yu, Saad Godil, Ryan J Prenger, and An- imashree Anandkumar. 2023. LeanDojo: Theorem Proving with Retrieval-Augmented Language Models. InAdvances in Neural Information Processing Systems , A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine (Eds.), Vol. 36. Curran Ass...
2023
-
[45]
Lichen Zhang, Shuai Lu, and Nan Duan. 2024. Selene: Pioneering Automated Proof in Software Verification. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Lun- Wei Ku, Andre Martins, and Vivek Srikumar(Eds.). Association for Computational Linguistics, Bangkok, Thailand, 1776–1789. doi:10.18...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.