Recognition: 2 theorem links
· Lean TheoremMulti-Drafter Speculative Decoding with Alignment Feedback
Pith reviewed 2026-05-10 19:27 UTC · model grok-4.3
The pith
MetaSD improves speculative decoding by dynamically allocating compute across multiple drafters using alignment feedback framed as a multi-armed bandit problem.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
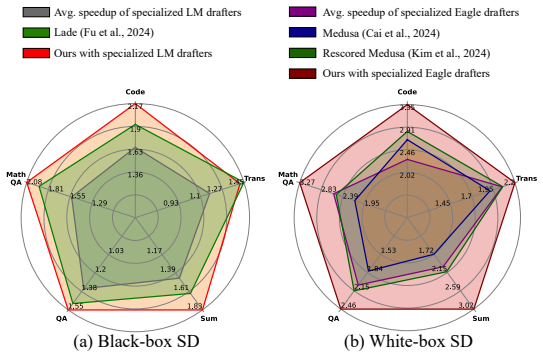
MetaSD integrates multiple heterogeneous drafters into the speculative decoding pipeline and treats drafter selection as a multi-armed bandit problem whose reward is alignment feedback between each drafter's tokens and the target LLM's verification. By solving this bandit instance at each step, the method allocates computational resources to the currently most effective drafter, yielding higher throughput than any fixed single-drafter baseline while preserving output quality.
What carries the argument
MetaSD framework that uses alignment feedback as the reward signal in a multi-armed bandit formulation to select among multiple drafters at inference time.
If this is right
- Speculative decoding can maintain high speedup even when no single drafter matches the target domain or task.
- Compute is shifted away from poorly aligned drafters without requiring offline profiling or retraining.
- The same target model can be paired with a changing pool of drafters while the bandit mechanism adapts on the fly.
- Quality guarantees remain intact because only tokens verified by the target LLM are kept, regardless of which drafter proposed them.
Where Pith is reading between the lines
- The bandit framing could be reused in other adaptive inference settings where several lightweight predictors compete for compute.
- If alignment feedback correlates with downstream task performance, the method might generalize to domains beyond text generation such as code or multimodal outputs.
- Replacing the current bandit algorithm with variants that incorporate context or longer-term rewards could further reduce selection regret.
Load-bearing premise
Alignment feedback reliably signals which drafter will produce the most useful tokens without introducing extra latency or systematic bias that cancels out the speedup.
What would settle it
A controlled run in which the bandit-selected drafter produces lower overall tokens-per-second than the best fixed single drafter, or in which measuring alignment feedback itself adds measurable wall-clock time that exceeds the observed gains.
Figures





read the original abstract
Speculative decoding (SD) accelerates large language model (LLM) inference by using a smaller model to draft future tokens, which are then verified by the target LLM. This preserves generation quality by accepting only aligned tokens. However, individual drafters, often trained for specific tasks or domains, exhibit limited effectiveness across diverse applications. To address this, we introduce \textsc{MetaSD}, a unified framework that integrates multiple drafters into the SD process. MetaSD dynamically allocates computational resources to heterogeneous drafters by leveraging alignment feedback and framing drafter selection as a multi-armed bandit problem. Extensive experiments show MetaSD consistently outperforms single-drafter approaches.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MetaSD, a unified framework for speculative decoding that integrates multiple heterogeneous drafters. It dynamically allocates compute by treating drafter selection as a multi-armed bandit problem driven by alignment feedback (how well a drafter's tokens match the target LLM), and claims that extensive experiments demonstrate consistent outperformance over single-drafter baselines.
Significance. If the empirical results hold with proper controls, the work could offer a practical advance in LLM inference acceleration by enabling adaptive use of multiple task- or domain-specialized drafters without manual intervention or fixed allocation, potentially improving speedup across diverse applications while preserving generation quality.
major comments (1)
- [Abstract] Abstract: The central claim that 'extensive experiments show MetaSD consistently outperforms single-drafter approaches' supplies no metrics (e.g., tokens/s, acceptance rate, wall-clock latency), baselines, datasets, statistical tests, or ablation results. This is load-bearing for an empirical framework whose value rests on demonstrating that the alignment-feedback bandit signal yields net gains without negating the speedup.
minor comments (1)
- The abstract introduces 'alignment feedback' and the multi-armed bandit framing but does not define the reward signal, arm selection policy, or overhead of the feedback mechanism.
Simulated Author's Rebuttal
We thank the referee for their thoughtful review and for highlighting the need for greater specificity in the abstract. We agree that the abstract's high-level claim would be strengthened by including key empirical metrics, and we will revise it accordingly in the next version. Our point-by-point response to the major comment follows.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that 'extensive experiments show MetaSD consistently outperforms single-drafter approaches' supplies no metrics (e.g., tokens/s, acceptance rate, wall-clock latency), baselines, datasets, statistical tests, or ablation results. This is load-bearing for an empirical framework whose value rests on demonstrating that the alignment-feedback bandit signal yields net gains without negating the speedup.
Authors: We agree that the abstract is currently too high-level and does not convey the concrete empirical support for the central claim. The full manuscript reports results on multiple datasets and tasks, using single-drafter baselines (including task-specific and general drafters), with metrics such as tokens per second, acceptance rate, and wall-clock latency. It also includes ablations isolating the alignment-feedback bandit component and basic statistical comparisons. We will revise the abstract to concisely incorporate representative quantitative results (e.g., average speedup gains and acceptance-rate improvements) while respecting length constraints, thereby making the load-bearing empirical contribution explicit. revision: yes
Circularity Check
No significant circularity
full rationale
The paper presents MetaSD as an empirical framework that integrates multiple drafters via alignment feedback and a multi-armed bandit formulation for dynamic allocation. No mathematical derivation chain, fitted parameters renamed as predictions, self-definitional equations, or load-bearing self-citations appear in the provided text. The central claim rests on experimental outperformance rather than any closed-form reduction to inputs, making the approach self-contained against external benchmarks with no evident circular steps.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
MetaSD dynamically allocates computational resources to heterogeneous drafters by leveraging alignment feedback and framing drafter selection as a multi-armed bandit problem.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
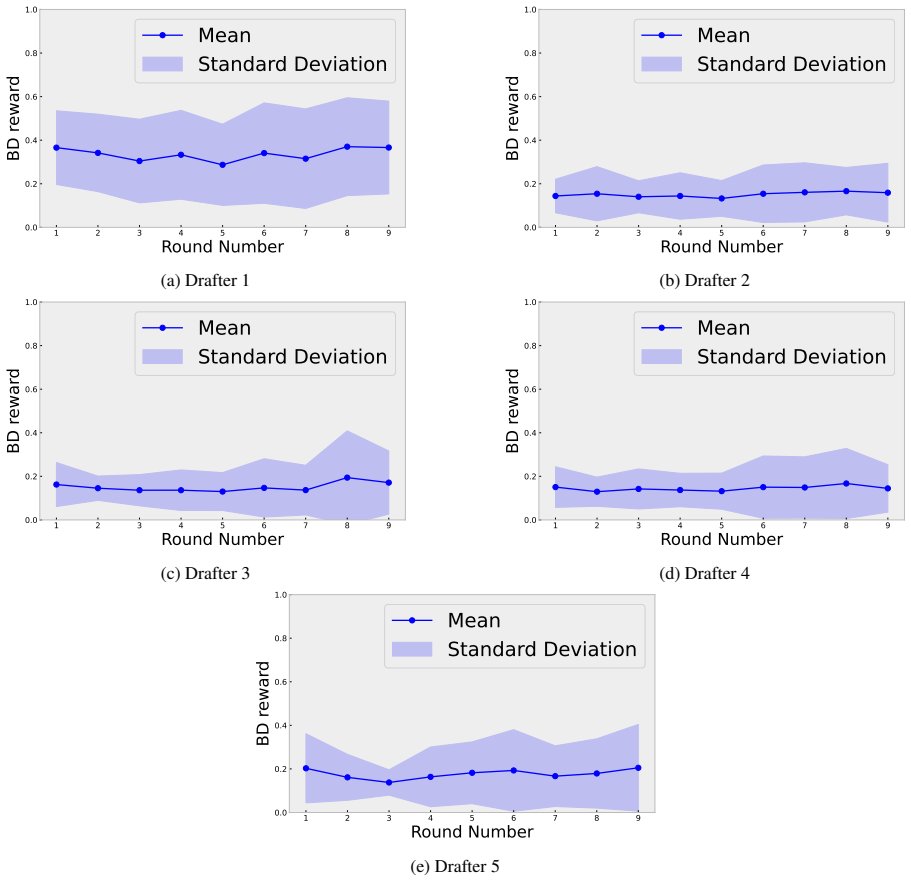
We define the BD reward as r_BD_i,t = 1/Nmax ∑ (1 - d_TV(p_{l+j}, q_{l+j}^i))
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Advances in neural information processing systems, 35:15800–15810
Better best of both worlds bounds for ban- dits with switching costs. Advances in neural information processing systems, 35:15800–15810. Jean-Yves Audibert and Sébastien Bubeck. 2010. Best arm identification in multi-armed bandits. In COLT-23th Conference on learning theory-2010, pages 13–p. Jean-Yves Audibert, Rémi Munos, and Csaba Szepesvári. 2007. Tuni...
-
[2]
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Bandits with switching costs: T 2/3 re- gret. In Proceedings of the forty-sixth annual ACM symposium on Theory of computing, pages 459– 467. Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2018. BERT: pre-training of deep bidirectional transformers for language under- standing. CoRR, abs/1810.04805. Wenkui Ding, Tao Qin, Xu-Dong Zhang, a...
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[3]
arXiv preprint arXiv:2404.02649 , year=
Pac bounds for multi-armed bandit and markov decision processes. In Computational Learning Theory: 15th Annual Conference on Computational Learning Theory, COLT 2002 Sydney, Australia, July 8–10, 2002 Proceedings 15, pages 255–270. Springer. Eyal Even-Dar, Shie Mannor, Yishay Mansour, and Sridhar Mahadevan. 2006. Action elimination and stopping conditions...
-
[4]
Break the sequential dependency of llm in- ference using lookahead decoding. arXiv preprint arXiv:2402.02057. Zijun Gao, Yanjun Han, Zhimei Ren, and Zhengqing Zhou. 2019. Batched multi-armed bandits prob- lem. Advances in Neural Information Processing Systems, 32. Aurélien Garivier and Emilie Kaufmann. 2016. Optimal best arm identification with fixed conf...
-
[5]
Gemini: A Family of Highly Capable Multimodal Models
Multi-armed bandit allocation indices. John Wiley & Sons. Google, Gemini Team, Rohan Anil, Sebastian Borgeaud, Yonghui Wu, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, and 1 others. 2023. Gemini: a family of highly capable multimodal models. arXiv preprint arXiv:2312.11805. Dan Hendrycks, Collin Burns, Steven ...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
In International Conference on Machine Learning, pages 19274–19286
Fast inference from transformers via spec- ulative decoding. In International Conference on Machine Learning, pages 19274–19286. PMLR. Guohao Li, Hasan Abed Al Kader Hammoud, Hani Itani, Dmitrii Khizbullin, and Bernard Ghanem
-
[7]
CAMEL: Communicative Agents for "Mind" Exploration of Large Language Model Society
Camel: Communicative agents for "mind" exploration of large scale language model society. Preprint, arXiv:2303.17760. Lihong Li, Wei Chu, John Langford, and Robert E Schapire. 2010. A contextual-bandit approach to personalized news article recommendation. In Proceedings of the 19th international conference on World wide web, pages 661–670. Yuhui Li, Fangy...
work page internal anchor Pith review arXiv 2010
-
[8]
Online speculative decoding. arXiv preprint arXiv:2310.07177. Shie Mannor and John N Tsitsiklis. 2004. The sample complexity of exploration in the multi-armed ban- dit problem. Journal of Machine Learning Research, 5(Jun):623–648. Xupeng Miao, Gabriele Oliaro, Zhihao Zhang, Xinhao Cheng, Zeyu Wang, Zhengxin Zhang, Rae Ying Yee Wong, Alan Zhu, Lijie Yang, ...
-
[9]
Spectr: Fast speculative decoding via optimal transport,
Blockwise parallel decoding for deep autore- gressive models. Advances in Neural Information Processing Systems, 31. Ziteng Sun, Ananda Theertha Suresh, Jae Hun Ro, Ah- mad Beirami, Himanshu Jain, and Felix Yu. 2023. Spectr: Fast speculative decoding via optimal trans- port. arXiv preprint arXiv:2310.15141. Hugo Touvron, Thibaut Lavril, Gautier Izacard, X...
-
[10]
In Proceedings of the AAAI Conference on Artificial Intelligence, volume 24, pages 1211–1216
Epsilon–first policies for budget–limited multi-armed bandits. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 24, pages 1211–1216. Long Tran-Thanh, Archie Chapman, Alex Rogers, and Nicholas Jennings. 2012. Knapsack based optimal policies for budget–limited multi–armed bandits. In Proceedings of the AAAI Conference on Artificial I...
-
[11]
Yang, S., Huang, S., Dai, X., and Chen, J
Multi-candidate speculative decoding. arXiv preprint arXiv:2401.06706. Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Ben- gio, William W. Cohen, Ruslan Salakhutdinov, and Christopher D. Manning. 2018. HotpotQA: A dataset for diverse, explainable multi-hop question answer- ing. In Conference on Empirical Methods in Natural Language Processing (EMNLP). Euiin...
-
[12]
Budgeted banditThe budgeted MAB problem address a bandit scenario where each arm pull yields both a reward and a cost drawn from indi- vidual distributions
proves the optimal regret bound in adversar- ial environment where reward distribution of each arm can change by adversary in every round. Budgeted banditThe budgeted MAB problem address a bandit scenario where each arm pull yields both a reward and a cost drawn from indi- vidual distributions. Here, the goal is to maximize the cumulative reward until sum...
2010
-
[13]
Pretraining drafters on a portion of C4 dataset (Raffel et al., 2019) and ShareGPT dataset (ShareGPT, 2023)
2019
-
[14]
Finetuning the models with self distilled data having the target task with templates. Self-distilled dataFollowing prior work (Kim and Rush, 2016; Zhou et al., 2023; Cai et al., 2024; Yi et al., 2024), we generate the training data for specialized drafters through self-distillation from the target LLM. To capture the full spectrum of its output variabilit...
-
[15]
Since in eq. 4, rBD i,t is constructed by empirical mean of Nmax numbers of samples under stationary assumption, following holds: Var[ri,t] = Var 1 Nmax Nmax−1X j=0 (1−d T V (pl(t)+j, ql(t)+j i ) ≤ 1 4Nmax , and this concludes the proof. Relationship between expectations of two re- wards.Combining above lemmas, one can show that the expectation of...
2023
-
[16]
is based on using fixed value of β= 1 , following works (Audibert et al., 2009; Bubeck,
2009
-
[17]
We provide a gen- eral results which includes a hyperparameter β in 36 MetaSD-UCB algorithm
show the regret can indeed be dependent on the exploration parameter β. We provide a gen- eral results which includes a hyperparameter β in 36 MetaSD-UCB algorithm. In the following, we bor- row the analysis of (Bubeck, 2010) for the general version of Theorem 2 that includesβ. Theorem 7(Regret upper bound containing β). For β >0.5 and with Assumption 2, ...
2010
-
[18]
Translate French and German to En- glish, respectively,
often define L to quantify the number of times the reward distributions change over T 38 rounds. Another line of work (Slivkins and Up- fal, 2008; Besbes et al., 2014) quantifies the non- stationarity using V , the total variation of the means. In both cases, the regret (which is often called as dynamic regret) is defined as the cumula- tive expected diff...
2008
-
[19]
It achieves this by maintaining a probability distribution over the arms and exponentially weighting the rewards based on their recent performance
is designed to handle adversarial changes of reward distributions by continuously updating its estimates of the arm rewards and adjusting its exploration strategy accordingly. It achieves this by maintaining a probability distribution over the arms and exponentially weighting the rewards based on their recent performance. By incorporating EXP3 into our fr...
2024
-
[20]
and RAG (Xia et al., 2024b), which fall out- side the training domains of specialized drafters. As shown in Table 11 (in Section F.8), MetaSD outperforms OFA and most specialized drafters, demonstrating its ability to generalize without re- lying on predefined domain similarities. Unlike similarity-based selection, which incurs high infer- ence costs for ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.