Recognition: 1 theorem link
· Lean TheoremPre-Execution Safety Gate & Task Safety Contracts for LLM-Controlled Robot Systems
Pith reviewed 2026-05-10 19:34 UTC · model grok-4.3
The pith
SafeGate extracts safety properties from natural language commands to block defective instructions before they reach LLM-controlled robots.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
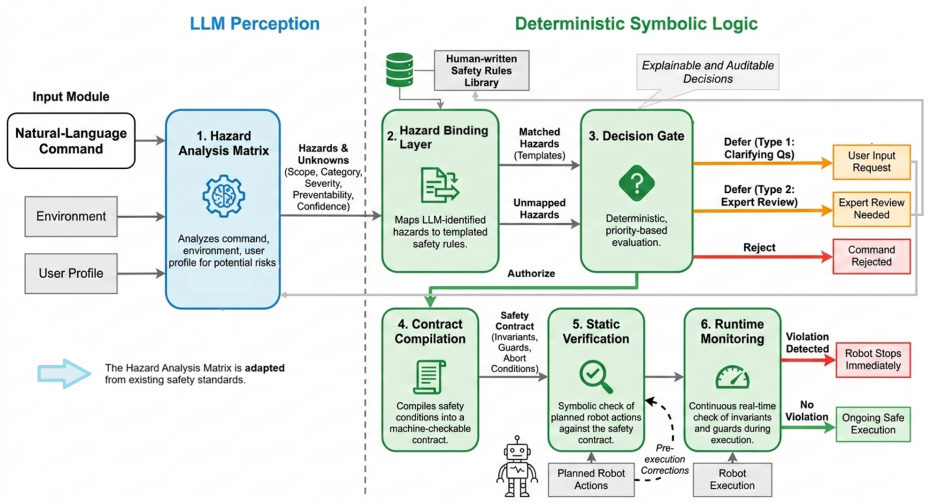
SafeGate is a neurosymbolic safety architecture that extracts structured safety-relevant properties from natural language task commands and applies a deterministic decision gate to authorize or reject execution before translation to robot code. Task Safety Contracts decompose commands that pass the gate into invariants, guards, and abort conditions to prevent unsafe state transitions during execution, with Z3 SMT solving used to enforce the derived constraints.
What carries the argument
SafeGate, a pre-execution neurosymbolic gate that extracts safety properties from natural language and pairs them with Task Safety Contracts enforced by SMT solving.
If this is right
- Defective commands reach robot execution at significantly lower rates than in baseline LLM systems or existing safety frameworks.
- Benign tasks continue to be accepted at high rates.
- Task Safety Contracts with SMT solving block unsafe state transitions even when a command appears acceptable at the start.
- Pre-execution gates drawn from safety standards improve overall reliability for LLM-controlled robot systems.
Where Pith is reading between the lines
- The approach could be adapted to other AI agents that control physical devices beyond robots.
- Larger or more adversarial command sets outside the current benchmarks would be needed to confirm broad coverage of unsafe inputs.
- Layering the gate with additional runtime monitors might address edge cases the contracts do not fully capture.
- The method supplies a concrete pattern for embedding deterministic checks into otherwise flexible LLM pipelines.
Load-bearing premise
Safety-relevant properties can be reliably extracted from arbitrary natural language commands and the 230 benchmark tasks plus 30 simulation scenarios adequately represent the space of unsafe real-world commands.
What would settle it
A test set of additional real-world commands where a substantial fraction of defective instructions still pass the gate or where many clearly benign tasks are rejected would show the extraction and decision process does not work as described.
Figures

read the original abstract
Large Language Models (LLMs) are increasingly used to convert task commands into robot-executable code, however this pipeline lacks validation gates to detect unsafe and defective commands before they are translated into robot code. Furthermore, even commands that appear safe at the outset can produce unsafe state transitions during execution in the absence of continuous constraint monitoring. In this research, we introduce SafeGate, a neurosymbolic safety architecture that prevents unsafe natural language task commands from reaching robot execution. Drawing from ISO 13482 safety standard, SafeGate extracts structured safety-relevant properties from natural language commands and applies a deterministic decision gate to authorize or reject execution. In addition, we introduce Task Safety Contracts, which decomposes commands that pass through the gate into invariants, guards, and abort conditions to prevent unsafe state transitions during execution. We further incorporate Z3 SMT solving to enforce constraint checking derived from the Task Safety Contracts. We evaluate SafeGate against existing LLM-based robot safety frameworks and baseline LLMs across 230 benchmark tasks, 30 AI2-THOR simulation scenarios, and real-world robot experiments. Results show that SafeGate significantly reduces the acceptance of defective commands while maintaining a high acceptance of benign tasks, demonstrating the importance of pre-execution safety gates for LLM-controlled robot systems
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SafeGate, a neurosymbolic pre-execution safety gate for LLM-controlled robot systems that extracts structured safety properties from natural language commands per ISO 13482 and applies a deterministic authorization decision. It further introduces Task Safety Contracts that decompose approved commands into invariants, guards, and abort conditions, enforced at runtime via Z3 SMT solving to prevent unsafe state transitions. The central claim is that this architecture significantly reduces acceptance of defective commands while preserving high acceptance rates for benign tasks, as demonstrated through comparisons against existing LLM-robot safety frameworks and baseline LLMs on 230 benchmark tasks, 30 AI2-THOR simulation scenarios, and real-robot experiments.
Significance. If the quantitative results and benchmark construction hold, the work would offer a concrete, standards-derived neurosymbolic bridge between LLM task generation and formal safety enforcement, addressing a recognized gap in deployable LLM-robot pipelines. The combination of static command filtering with dynamic contract monitoring via SMT is a practical contribution that could inform future safety layers; however, the absence of reported metrics, baseline details, and task-generation provenance in the provided text limits assessment of whether the gains are robust or merely artifactual.
major comments (3)
- [Abstract / Evaluation] Abstract and Evaluation section: The manuscript asserts that SafeGate 'significantly reduces the acceptance of defective commands while maintaining a high acceptance of benign tasks' across 230 benchmark tasks, yet supplies no numerical acceptance rates, false-positive/false-negative counts, baseline comparisons, error bars, or statistical tests. Without these data the headline claim cannot be verified and the comparison to 'existing LLM-based robot safety frameworks' remains unquantified.
- [Evaluation / Benchmark Tasks] Benchmark construction (230 tasks): The skeptic concern is material—the defective subset must be shown to reflect the distribution of unsafe or ambiguous commands actually produced by the LLMs used in the robot pipeline. The text provides no evidence that the 230 tasks (or the defective subset) were generated by prompting the same or comparable LLMs; if they are expert-written or template-based, the measured safety improvement may not transfer to live LLM outputs containing novel phrasing or implicit hazards.
- [Task Safety Contracts] Task Safety Contracts and Z3 integration: The paper states that commands passing the gate are decomposed into invariants, guards, and abort conditions enforced by Z3, but does not specify the extraction procedure, the completeness of the resulting contracts, or failure modes when natural-language ambiguity prevents a sound contract. This is load-bearing for the runtime-safety claim.
minor comments (2)
- [Abstract] The abstract mentions 'real-world robot experiments' but gives no hardware details, number of trials, or failure modes observed on the physical platform.
- [SafeGate Architecture] Notation for safety properties extracted from natural language is introduced without a formal grammar or example derivation trace, making reproducibility of the neurosymbolic extraction step difficult.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point-by-point below, clarifying aspects of the work and indicating revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract / Evaluation] Abstract and Evaluation section: The manuscript asserts that SafeGate 'significantly reduces the acceptance of defective commands while maintaining a high acceptance of benign tasks' across 230 benchmark tasks, yet supplies no numerical acceptance rates, false-positive/false-negative counts, baseline comparisons, error bars, or statistical tests. Without these data the headline claim cannot be verified and the comparison to 'existing LLM-based robot safety frameworks' remains unquantified.
Authors: We agree that the abstract and high-level evaluation summary do not include explicit numerical values. The detailed evaluation section reports comparisons to baselines on the 230 tasks, but to ensure verifiability we will revise the abstract to report key acceptance rates for defective and benign tasks and add a table in the evaluation section with FP/FN counts, baseline results, and statistical tests. revision: yes
-
Referee: [Evaluation / Benchmark Tasks] Benchmark construction (230 tasks): The skeptic concern is material—the defective subset must be shown to reflect the distribution of unsafe or ambiguous commands actually produced by the LLMs used in the robot pipeline. The text provides no evidence that the 230 tasks (or the defective subset) were generated by prompting the same or comparable LLMs; if they are expert-written or template-based, the measured safety improvement may not transfer to live LLM outputs containing novel phrasing or implicit hazards.
Authors: The 230 tasks were generated by prompting the same LLMs used in the robot pipeline (GPT-4 and comparable models) with scenarios intended to produce both safe and defective commands, followed by classification against ISO 13482 properties. We will add a dedicated subsection describing the exact prompts, LLM models employed for generation, and the curation/validation process to demonstrate alignment with realistic LLM outputs. revision: yes
-
Referee: [Task Safety Contracts] Task Safety Contracts and Z3 integration: The paper states that commands passing the gate are decomposed into invariants, guards, and abort conditions enforced by Z3, but does not specify the extraction procedure, the completeness of the resulting contracts, or failure modes when natural-language ambiguity prevents a sound contract. This is load-bearing for the runtime-safety claim.
Authors: We agree that additional detail is required. The revised manuscript will expand the Task Safety Contracts section with the precise neurosymbolic extraction procedure that maps natural-language commands to invariants, guards, and abort conditions using ISO 13482-derived properties. We will also address contract completeness and discuss failure modes for ambiguous language, noting that such cases trigger conservative rejection at the pre-execution gate. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper introduces SafeGate as a neurosymbolic architecture that extracts safety properties from natural language commands, applies a deterministic gate, decomposes tasks into contracts, and uses Z3 for enforcement. All load-bearing claims rest on empirical evaluation over independently defined benchmark tasks and simulation scenarios rather than any equations, fitted parameters, or self-citations that reduce the result to its own inputs by construction. No self-definitional steps, renamed known results, or ansatzes smuggled via prior work appear; the derivation is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption ISO 13482 safety standard defines relevant safety properties that can be extracted from natural language task commands
invented entities (2)
-
SafeGate
no independent evidence
-
Task Safety Contracts
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.lean; IndisputableMonolith/Cost/FunctionalEquation.leanreality_from_one_distinction; washburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
SafeGate extracts structured safety-relevant properties from natural language commands and applies a deterministic decision gate... Task Safety Contracts... invariants, guards, and abort conditions... Z3 SMT solving
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
LLM-Guided Safety Agent for Edge Robotics with an ISO-Compliant Perception-Compute-Control Architecture
An LLM-guided safety agent on dual-modular redundant edge hardware demonstrates a practical path to ISO 13849 Category 3 and PL d compliance for human-robot interaction using cost-effective platforms.
Reference graph
Works this paper leans on
-
[1]
Progprompt: Generating situated robot task plans using large language models,
I. Singh, V . Blukis, A. Mousavian, A. Goyal, D. Xu, J. Tremblay, D. Fox, J. Thomason, and A. Garg, “Progprompt: Generating situated robot task plans using large language models,” in2023 IEEE Interna- tional Conference on Robotics and Automation (ICRA). IEEE, 2023, pp. 11 523–11 530
2023
-
[2]
Do As I Can, Not As I Say: Grounding Language in Robotic Affordances
M. Ahn, A. Brohan, N. Brown, Y . Chebotar, O. Cortes, B. David, C. Finn, C. Fu, K. Gopalakrishnan, K. Hausmanet al., “Do as i can, not as i say: Grounding language in robotic affordances,”arXiv preprint arXiv:2204.01691, 2022
work page internal anchor Pith review arXiv 2022
-
[3]
Smart-llm: Smart multi-agent robot task planning using large language models,
S. S. Kannan, V . L. Venkatesh, and B.-C. Min, “Smart-llm: Smart multi-agent robot task planning using large language models,” in2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2024, pp. 12 140–12 147
2024
-
[4]
Prefclm: Enhanc- ing preference-based reinforcement learning with crowdsourced large language models,
R. Wang, D. Zhao, Z. Yuan, I. Obi, and B.-C. Min, “Prefclm: Enhanc- ing preference-based reinforcement learning with crowdsourced large language models,”IEEE Robotics and Automation Letters, vol. 10, no. 3, pp. 2486–2493, 2025
2025
-
[5]
Investigating the Impact of Trust in Multi-human Multi-Robot Task Allocation,
I. Obi, R. Wang, W. Jo, and B.-C. Min, “Investigating the Impact of Trust in Multi-human Multi-Robot Task Allocation,”arXiv preprint arXiv:2409.16009, 2024
-
[6]
Inner Monologue: Embodied Reasoning through Planning with Language Models
W. Huang, F. Xia, T. Xiao, H. Chan, J. Liang, P. Florence, A. Zeng, J. Tompson, I. Mordatch, Y . Chebotaret al., “Inner monologue: Embodied reasoning through planning with language models,”arXiv preprint arXiv:2207.05608, 2022
work page internal anchor Pith review arXiv 2022
-
[7]
Chatgpt for robotics: Design principles and model abilities,
S. H. Vemprala, R. Bonatti, A. Bucker, and A. Kapoor, “Chatgpt for robotics: Design principles and model abilities,”Ieee Access, vol. 12, pp. 55 682–55 696, 2024
2024
-
[8]
RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, X. Chen, K. Choro- manski, T. Ding, D. Driess, A. Dubey, C. Finnet al., “Rt-2: Vision- language-action models transfer web knowledge to robotic control,” arXiv preprint arXiv:2307.15818, 2023
work page internal anchor Pith review arXiv 2023
-
[9]
Plug in the safety chip: Enforcing constraints for llm-driven robot agents,
Z. Yang, S. S. Raman, A. Shah, and S. Tellex, “Plug in the safety chip: Enforcing constraints for llm-driven robot agents,” in2024 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2024, pp. 14 435–14 442
2024
-
[10]
Primt: Preference-based reinforcement learning with multimodal feedback and trajectory synthesis from foundation mod- els,
R. Wang, D. Zhao, Z. Yuan, T. Shao, G. Chen, D. Kao, S. Hong, and B.-C. Min, “Primt: Preference-based reinforcement learning with multimodal feedback and trajectory synthesis from foundation mod- els,” inThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[11]
Selp: Generating Safe and Efficient Task Plans for Robot Agents with Large Language Models,
Y . Wu, Z. Xiong, Y . Hu, S. S. Iyengar, N. Jiang, A. Bera, L. Tan, and S. Jagannathan, “Selp: Generating Safe and Efficient Task Plans for Robot Agents with Large Language Models,”arXiv preprint arXiv:2409.19471, 2024. [12]Robots and robotic devices—Safety requirements for personal care robots, International Organization for Standardization Std. ISO 13 4...
-
[12]
Safety guardrails for llm-enabled robots,
Z. Ravichandran, A. Robey, V . Kumar, G. J. Pappas, and H. Hassani, “Safety guardrails for llm-enabled robots,” inRSS 2025 Workshop on Reliable Robotics: Safety and Security in the Face of Generative AI
2025
-
[13]
AI2-THOR: An Interactive 3D Environment for Visual AI
E. Kolve, R. Mottaghi, W. Han, E. VanderBilt, L. Weihs, A. Herrasti, M. Deitke, K. Ehsani, D. Gordon, Y . Zhuet al., “Ai2-thor: An interac- tive 3d environment for visual ai,”arXiv preprint arXiv:1712.05474, 2017
work page internal anchor Pith review arXiv 2017
-
[14]
On the safety concerns of deploy- ing llms/vlms in robotics: Highlighting the risks and vulnerabilities,
X. Wu, R. Xian, T. Guan, J. Liang, S. Chakraborty, F. Liu, B. M. Sadler, D. Manocha, and A. Bedi, “On the safety concerns of deploy- ing llms/vlms in robotics: Highlighting the risks and vulnerabilities,” inFirst Vision and Language for Autonomous Driving and Robotics Workshop, 2024
2024
-
[15]
Llm-driven robots risk enacting discrimination, violence, and unlawful actions,
R. Azeem, A. Hundt, M. Mansouri, and M. Brandão, “Llm-driven robots risk enacting discrimination, violence, and unlawful actions,” arXiv preprint arXiv:2406.08824, 2024
-
[16]
Robots enact malignant stereotypes,
A. Hundt, W. Agnew, V . Zeng, S. Kacianka, and M. Gombolay, “Robots enact malignant stereotypes,” inProceedings of the 2022 ACM Conference on Fairness, Accountability, and Transparency, 2022, pp. 743–756
2022
-
[17]
How can llms and knowledge graphs con- tribute to robot safety? a few-shot learning approach,
A. Althobaiti, A. Ayala, J. Gao, A. Almutairi, M. Deghat, I. Raz- zak, and F. Cruz, “How can llms and knowledge graphs con- tribute to robot safety? a few-shot learning approach,”arXiv preprint arXiv:2412.11387, 2024
-
[18]
Plancol- labnl: Leveraging large language models for adaptive plan generation in human-robot collaboration,
S. Izquierdo-Badiola, G. Canal, C. Rizzo, and G. Alenyà, “Plancol- labnl: Leveraging large language models for adaptive plan generation in human-robot collaboration,” in2024 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2024, pp. 17 344–17 350
2024
-
[19]
Value Imprint: A Technique for Auditing the Human Values Embedded in RLHF Datasets,
I. Obi, R. Pant, S. S. Agrawal, M. Ghazanfar, and A. Basiletti, “Value Imprint: A Technique for Auditing the Human Values Embedded in RLHF Datasets,” inThe Thirty-eight Conference on Neural Informa- tion Processing Systems Datasets and Benchmarks Track
-
[20]
Venkatesh, Weizheng Wang, Ruiqi Wang, Dayoon Suh, Temitope I
I. Obi, V . L. Venkatesh, W. Wang, R. Wang, D. Suh, T. I. Amosa, W. Jo, and B.-C. Min, “Safeplan: Leveraging formal logic and chain- of-thought reasoning for enhanced safety in llm-based robotic task planning,”arXiv preprint arXiv:2503.06892, 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.