Recognition: 1 theorem link
· Lean TheoremCross-Stage Attention Propagation for Efficient Semantic Segmentation
Pith reviewed 2026-05-10 19:02 UTC · model grok-4.3
The pith
Computing attention only at the deepest feature scale and propagating the maps upward cuts decoder computation while retaining multi-scale context.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that attention distributions across scales are strongly correlated, allowing a decoder to compute attention exclusively at the deepest feature scale and then propagate the resulting maps to shallower stages. This bypasses independent query-key computations at every level, preserves multi-scale contextual reasoning, and reduces overall computational cost.
What carries the argument
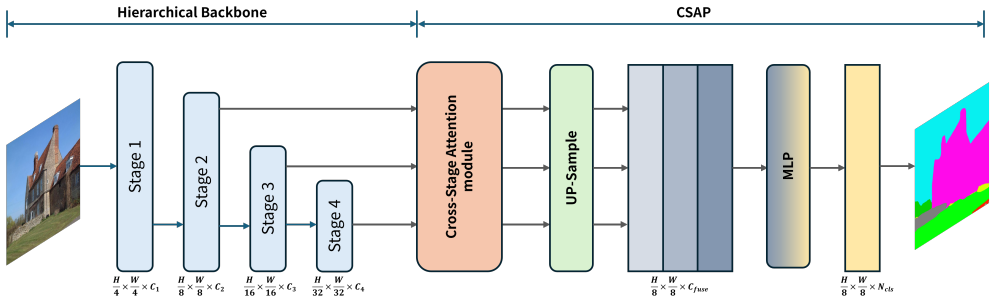
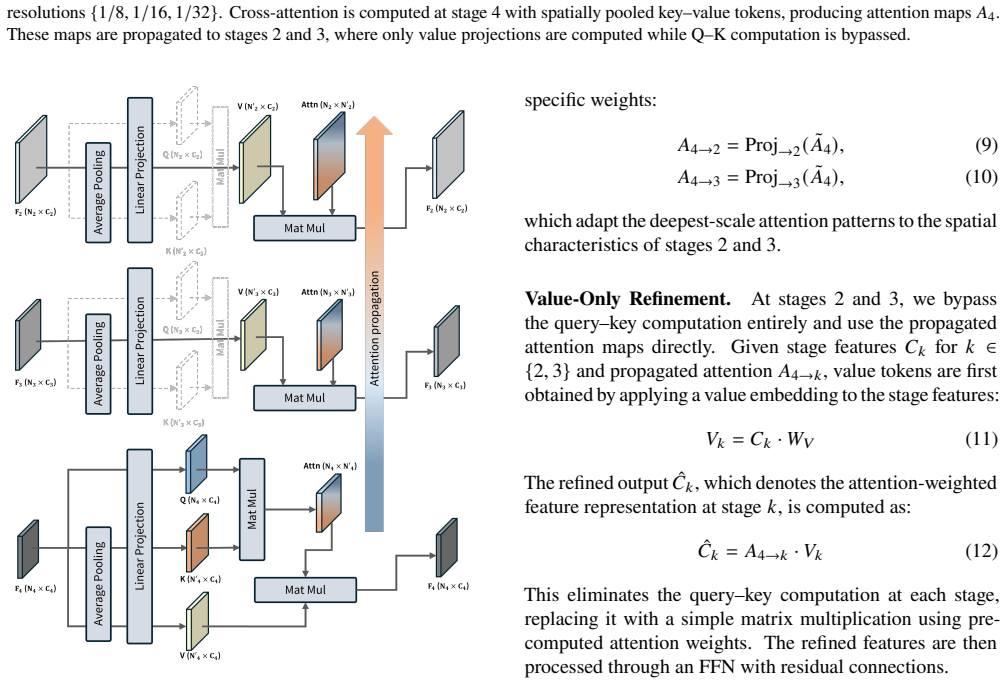
Cross-Stage Attention Propagation (CSAP), which computes attention maps at the deepest scale and reuses them at shallower scales to replace per-stage attention calculations.
If this is right
- Decoder floating-point operations decrease because query-key computations are performed only once at the deepest scale.
- Multi-scale context remains available through the propagated maps rather than independent calculations.
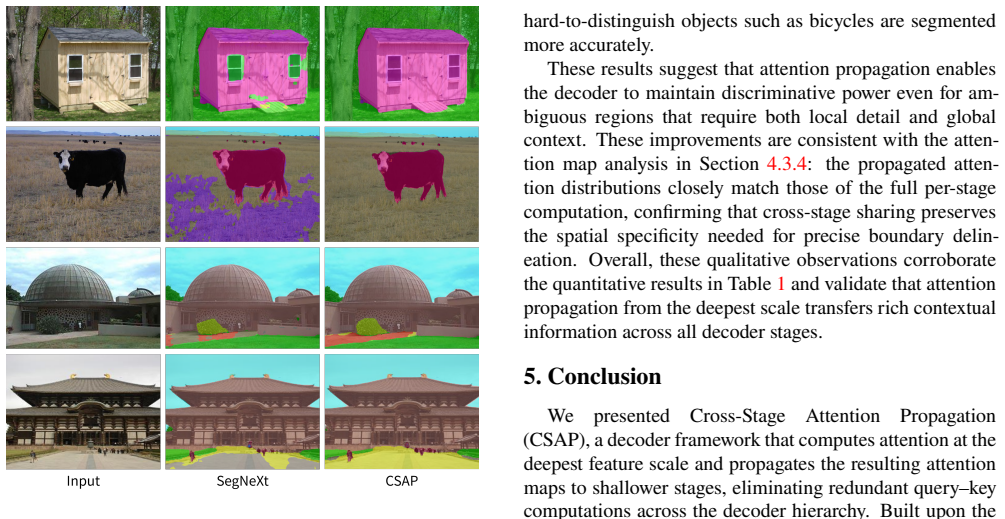
- Models achieve higher mIoU at lower compute budgets than baselines such as SegNeXt on ADE20K, Cityscapes, and COCO-Stuff.
- The design pairs with compact backbones to produce lightweight segmentation networks suitable for constrained environments.
Where Pith is reading between the lines
- The same propagation idea could reduce cost in other multi-scale attention models used for object detection or instance segmentation.
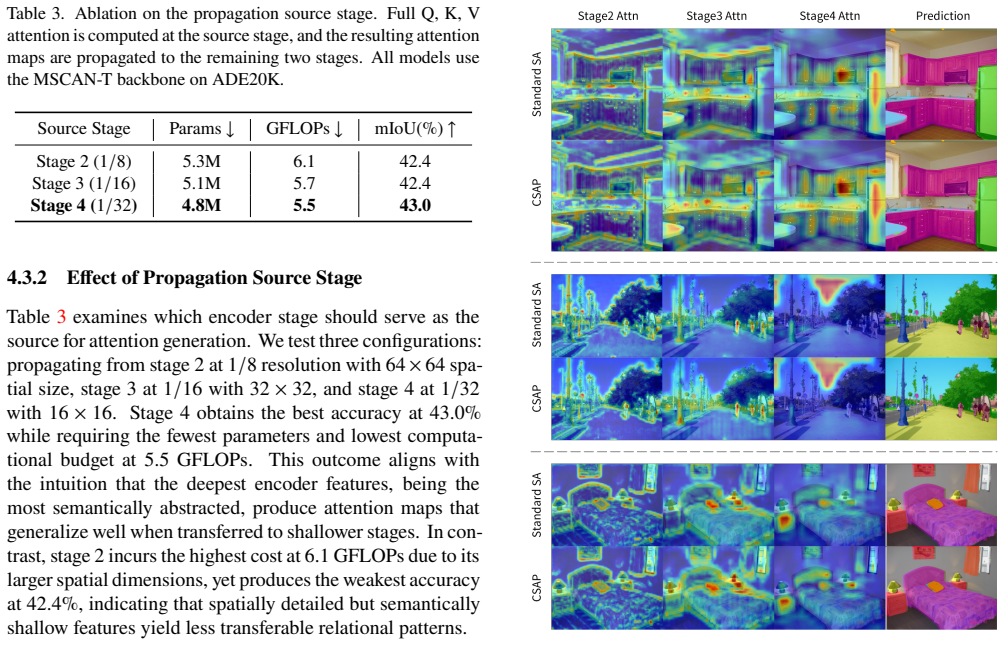
- Correlation strength between scales may depend on backbone depth, so testing with varied architectures would clarify the method's range.
- If cross-scale similarity holds for temporal or 3D data, the approach could extend to efficient video or volumetric segmentation.
Load-bearing premise
Attention maps produced independently at different feature scales are sufficiently similar that maps from the deepest scale can substitute for the others without substantial loss of information.
What would settle it
If independently computed attention maps at shallow scales show large spatial or class-specific differences from the propagated deep-scale maps, then accuracy would drop when using propagation alone.
Figures


read the original abstract
Recent lightweight semantic segmentation methods have made significant progress by combining compact backbones with efficient decoder heads. However, most multi-scale decoders compute attention independently at each feature scale, introducing substantial redundancy since the resulting attention distributions across scales are strongly correlated. We propose Cross-Stage Attention Propagation (CSAP), a decoder framework that computes attention at the deepest feature scale and propagates the resulting attention maps to shallower stages, bypassing query-key computation at those stages entirely. This design preserves multi-scale contextual reasoning while substantially reducing the decoder's computational cost. CSAP-Tiny achieves 42.9% mIoU on ADE20K with only 5.5 GFLOPs, 80.5% on Cityscapes with 21.5 GFLOPs, and 40.9% on COCO-Stuff 164K with 5.5 GFLOPs, surpassing SegNeXt-Tiny by +1.8% on ADE20K while requiring 16.8% fewer floating-point operations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Cross-Stage Attention Propagation (CSAP), a decoder framework for semantic segmentation that computes attention maps only at the deepest feature scale and propagates them to shallower stages. This exploits the claimed strong correlation between attention distributions across scales to bypass independent query-key computations at each stage, preserving multi-scale context while reducing decoder FLOPs. Reported results include 42.9% mIoU on ADE20K (5.5 GFLOPs), 80.5% on Cityscapes (21.5 GFLOPs), and 40.9% on COCO-Stuff (5.5 GFLOPs), outperforming SegNeXt-Tiny by +1.8% mIoU with 16.8% fewer operations.
Significance. If the correlation premise and propagation operator are validated, CSAP offers a practical route to lower the redundancy in multi-scale attention decoders for lightweight segmentation models. The concrete efficiency-accuracy numbers position it as a potentially useful design pattern for edge deployment, building on compact backbones without requiring entirely new architectures.
major comments (2)
- [§2] §2 (Method): The core efficiency claim rests on the premise that attention distributions are strongly correlated across scales, yet no quantitative support (e.g., cosine similarity, KL divergence, or attention-map visualizations between deepest and shallower scales) is provided to justify bypassing per-stage Q-K computation; this assumption is load-bearing for the reported GFLOP reductions.
- [§4] §4 (Experiments): The mIoU and GFLOP results are presented without ablations isolating the propagation operator, without error bars across runs, and with limited baseline comparisons beyond SegNeXt-Tiny; this prevents independent verification of whether the gains derive from the cross-stage design or from other implementation choices.
minor comments (2)
- [Abstract and §3] The abstract and method section would benefit from a concise pseudocode or equation defining the exact propagation operator (e.g., how attention maps are resized and injected into shallower stages).
- Implementation details such as the backbone network, training hyperparameters, and exact decoder head architecture are referenced only implicitly; adding these would aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We have carefully reviewed the major comments and provide point-by-point responses below. Where the comments identify gaps in evidence or analysis, we have revised the manuscript to address them directly.
read point-by-point responses
-
Referee: [§2] §2 (Method): The core efficiency claim rests on the premise that attention distributions are strongly correlated across scales, yet no quantitative support (e.g., cosine similarity, KL divergence, or attention-map visualizations between deepest and shallower scales) is provided to justify bypassing per-stage Q-K computation; this assumption is load-bearing for the reported GFLOP reductions.
Authors: We agree that the correlation premise requires explicit quantitative backing to support the efficiency claims. In the revised manuscript, we have added a dedicated paragraph and accompanying figure in §2. The new figure visualizes attention maps computed at the deepest scale and the corresponding propagated maps at shallower scales for representative ADE20K images. We also report aggregate statistics over the validation set: mean cosine similarity of 0.87 between deepest-scale and shallower-scale attention maps, and mean KL divergence of 0.12, confirming the strong correlation that justifies propagation. These additions directly substantiate the design choice and the associated GFLOP savings. revision: yes
-
Referee: [§4] §4 (Experiments): The mIoU and GFLOP results are presented without ablations isolating the propagation operator, without error bars across runs, and with limited baseline comparisons beyond SegNeXt-Tiny; this prevents independent verification of whether the gains derive from the cross-stage design or from other implementation choices.
Authors: We concur that additional controls are necessary for rigorous verification. The revised §4 now includes an ablation that replaces the propagation operator with independent per-scale Q-K computation while keeping the backbone and all other components identical; the resulting GFLOP increase and mIoU drop isolate the contribution of cross-stage propagation. We also report all main-table results as mean ± standard deviation over three independent training runs with different random seeds. Finally, we have expanded the baseline table to include SegFormer-B0, MobileViT-S, and EfficientViT, providing broader context beyond SegNeXt-Tiny. These changes enable independent assessment of the cross-stage design. revision: yes
Circularity Check
No circularity in claimed derivation chain
full rationale
The paper presents CSAP as an architectural design choice motivated by the empirical observation that attention distributions are correlated across feature scales. This correlation is stated as the justification for propagating attention maps from the deepest scale rather than computing them independently, but it is not derived from or equivalent to the method's own equations or outputs. No parameters are fitted in a way that makes reported mIoU or GFLOPs reduce to the inputs by construction, and the abstract and description contain no self-citations, uniqueness theorems, or ansatzes that loop back on themselves. The efficiency claims rest on the implementation of the propagation operator and external benchmark results, which are independently verifiable.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Attention distributions across different feature scales are strongly correlated.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
computes attention at the deepest feature scale and propagates the resulting attention maps to shallower stages, bypassing query-key computation at those stages entirely... attention distributions across scales are strongly correlated
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
SegNet: A deep convolutional encoder-decoder architecture forimagesegmentation.IEEETransactionsonPatternAnal- ysis and Machine Intelligence, 39(12):2481–2495, 2017
Vijay Badrinarayanan, Alex Kendall, and Roberto Cipolla. SegNet: A deep convolutional encoder-decoder architecture forimagesegmentation.IEEETransactionsonPatternAnal- ysis and Machine Intelligence, 39(12):2481–2495, 2017. 2
2017
-
[2]
COCO- Stuff: Thing and stuff classes in context
Holger Caesar, Jasper Uijlings, and Vittorio Ferrari. COCO- Stuff: Thing and stuff classes in context. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 1209–1218, 2018. 5
2018
-
[3]
Liang-Chieh Chen, George Papandreou, Iasonas Kokkinos, Kevin Murphy, and Alan L Yuille. DeepLab: Semantic im- age segmentation with deep convolutional nets, atrous con- volution, and fully connected CRFs.IEEE Transactions on Pattern Analysis and Machine Intelligence, 40(4):834–848,
-
[4]
Encoder-decoder with atrous separable convolution for semantic image segmentation
Liang-ChiehChen, YukunZhu, GeorgePapandreou, Florian Schroff, and Hartwig Adam. Encoder-decoder with atrous separable convolution for semantic image segmentation. In ProceedingsoftheEuropeanConferenceonComputerVision, pages 801–818, 2018. 2
2018
-
[5]
Mobile-Former: Bridging MobileNet and transformer
YinpengChen,XiyangDai,DongdongChen,MengchenLiu, Xiaoyi Dong, Lu Yuan, and Zicheng Liu. Mobile-Former: Bridging MobileNet and transformer. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5270–5279, 2022. 1
2022
-
[6]
MMSegmentation: Open- MMLab semantic segmentation toolbox and benchmark
MMSegmentation Contributors. MMSegmentation: Open- MMLab semantic segmentation toolbox and benchmark. https://github.com/open-mmlab/mmsegmentation, 2020. 5
2020
-
[7]
The Cityscapes dataset for semantic urban scene understanding
Marius Cordts, Mohamed Omran, Sebastian Ramos, Timo Rehfeld,MarkusEnzweiler,RodrigoBenenson,UweFranke, Stefan Roth, and Bernt Schiele. The Cityscapes dataset for semantic urban scene understanding. InProceedings of the IEEE Conference on Computer Vision and Pattern Recogni- tion, pages 3213–3223, 2016. 1, 4
2016
-
[8]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Syl- vain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale.arXiv preprint arXiv:2010.11929, 2020. 1
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[9]
arXiv preprint arXiv:1704.06857 , year=
Alberto Garcia-Garcia, Sergio Orts-Escolano, Sergiu Oprea, Victor Villena-Martinez, and Jose Garcia-Rodriguez. A re- view on deep learning techniques applied to semantic seg- mentation.arXiv preprint arXiv:1704.06857, 2017. 1
-
[10]
SegNeXt: Rethinking convolutionalattentiondesignforsemanticsegmentation.Ad- vances in Neural Information Processing Systems, 35:1140– 1156, 2022
Meng-Hao Guo, Cheng-Ze Lu, Qibin Hou, Zhengning Liu, Ming-Ming Cheng, and Shi-Min Hu. SegNeXt: Rethinking convolutionalattentiondesignforsemanticsegmentation.Ad- vances in Neural Information Processing Systems, 35:1140– 1156, 2022. 1, 2, 3, 5
2022
-
[11]
Deepresiduallearningforimagerecognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deepresiduallearningforimagerecognition. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 770–778, 2016. 2
2016
-
[12]
MetaSeg: MetaFormer-based global contexts-aware network for efficient semantic segmentation
Beoungwoo Kang, Seunghun Moon, Yubin Cho, Hyunwoo Yu, and Suk-Ju Kang. MetaSeg: MetaFormer-based global contexts-aware network for efficient semantic segmentation. InProceedings of the IEEE/CVF Winter Conference on Ap- plications of Computer Vision, pages 434–443, 2024. 2, 5
2024
-
[13]
Reformer: The Efficient Transformer
Nikita Kitaev, Łukasz Kaiser, and Anselm Levskaya. Reformer: The efficient transformer.arXiv preprint arXiv:2001.04451, 2020. 3
work page internal anchor Pith review arXiv 2001
-
[14]
Featurepyramidnet- works for object detection
Tsung-Yi Lin, Piotr Dollár, Ross Girshick, Kaiming He, BharathHariharan,andSergeBelongie. Featurepyramidnet- works for object detection. InProceedings of the IEEE Con- ference on Computer Vision and Pattern Recognition, pages 2117–2125, 2017. 2
2017
-
[15]
Swin Transformer: Hierarchical vision transformer using shifted windows
Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining Guo. Swin Transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 10012–10022, 2021. 1, 2, 3
2021
-
[16]
A ConvNet for the 2020s
Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feicht- enhofer, Trevor Darrell, and Saining Xie. A ConvNet for the 2020s. InProceedingsoftheIEEE/CVFConferenceonCom- puter Vision and Pattern Recognition, pages 11976–11986,
-
[17]
Fully convolutional networks for semantic segmentation
Jonathan Long, Evan Shelhamer, and Trevor Darrell. Fully convolutional networks for semantic segmentation. InPro- ceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 3431–3440, 2015. 2
2015
-
[18]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017. 5
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[19]
Sachin Mehta and Mohammad Rastegari. MobileViT: Light- weight, general-purpose, and mobile-friendly vision trans- former.arXiv preprint arXiv:2110.02178, 2021. 1
-
[20]
U-Net: Convolutional networks for biomedical image segmentation
OlafRonneberger,PhilippFischer,andThomasBrox. U-Net: Convolutional networks for biomedical image segmentation. InInternational Conference on Medical Image Computing and Computer-Assisted Intervention, pages 234–241, Cham,
-
[21]
Springer International Publishing. 2
-
[22]
FeedFormer: Revisiting transformer decoder for ef- ficient semantic segmentation
Jae-hun Shim, Hyunwoo Yu, Kyeongbo Kong, and Suk-Ju Kang. FeedFormer: Revisiting transformer decoder for ef- ficient semantic segmentation. InProceedings of the AAAI ConferenceonArtificialIntelligence,volume37,pages2263– 2271, 2023. 2, 5
2023
-
[23]
SeaFormer: Squeeze-enhanced axial transformer for mobilesemanticsegmentation
Qiang Wan, Zilong Huang, Jiachen Lu, Gang Yu, and Li Zhang. SeaFormer: Squeeze-enhanced axial transformer for mobilesemanticsegmentation. InTheEleventhInternational Conference on Learning Representations, 2023. 2
2023
-
[24]
RTFormer: Effi- cient design for real-time semantic segmentation with trans- former.AdvancesinNeuralInformationProcessingSystems, 35:7423–7436, 2022
JianWang,ChenhuiGou,QimanWu,HaochengFeng,Junyu Han, Errui Ding, and Jingdong Wang. RTFormer: Effi- cient design for real-time semantic segmentation with trans- former.AdvancesinNeuralInformationProcessingSystems, 35:7423–7436, 2022. 2
2022
-
[25]
Deep high-resolutionrepresentationlearningforvisualrecognition
Jingdong Wang, Ke Sun, Tianheng Cheng, Borui Jiang, Chaorui Deng, Yang Zhao, Dong Liu, Yadong Mu, Mingkui Tan, Xinggang Wang, Wenyu Liu, and Bin Xiao. Deep high-resolutionrepresentationlearningforvisualrecognition. IEEE Transactions on Pattern Analysis and Machine Intelli- gence, 43(10):3349–3364, 2020. 2
2020
-
[26]
Pyra- mid vision transformer: A versatile backbone for dense prediction without convolutions
Wenhai Wang, Enze Xie, Xiang Li, Deng-Ping Fan, Kaitao Song, Ding Liang, Tong Lu, Ping Luo, and Ling Shao. Pyra- mid vision transformer: A versatile backbone for dense prediction without convolutions. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 568–578, 2021. 1, 2
2021
-
[27]
PVT v2: Improved baselines with pyramid vision transformer
Wenhai Wang, Enze Xie, Xiang Li, Deng-Ping Fan, Kaitao Song, Ding Liang, Tong Lu, Ping Luo, and Ling Shao. PVT v2: Improved baselines with pyramid vision transformer. Computational Visual Media, 8(3):415–424, 2022. 2
2022
-
[28]
SegFormer: Simple and efficient design for semantic segmentation with transform- ers.Advances in Neural Information Processing Systems, 34:12077–12090, 2021
Enze Xie, Wenhai Wang, Zhiding Yu, Anima Anandkumar, Jose M Alvarez, and Ping Luo. SegFormer: Simple and efficient design for semantic segmentation with transform- ers.Advances in Neural Information Processing Systems, 34:12077–12090, 2021. 2, 3, 5
2021
-
[29]
arXiv preprint arXiv:2404.16573 (2024)
Haotian Yan, Ming Wu, and Chuang Zhang. Multi-scale representations by varying window attention for semantic segmentation.arXiv preprint arXiv:2404.16573, 2024. 2, 5
-
[30]
Multi-Scale Context Aggregation by Dilated Convolutions
Fisher Yu and Vladlen Koltun. Multi-scale context aggregation by dilated convolutions.arXiv preprint arXiv:1511.07122, 2015. 2
work page Pith review arXiv 2015
-
[31]
Embedding-free transformer with inference spatial reduction for efficient se- mantic segmentation
Hyunwoo Yu, Yubin Cho, Beoungwoo Kang, Seunghun Moon, Kyeongbo Kong, and Suk-Ju Kang. Embedding-free transformer with inference spatial reduction for efficient se- mantic segmentation. InEuropean Conference on Computer Vision, pages 92–110, Cham, 2024. Springer Nature Switzer- land. 2, 5
2024
-
[32]
TopFormer: Token pyramid transformer for mobile semantic segmentation
Wenqiang Zhang, Zilong Huang, Guozhong Luo, Tao Chen, Xinggang Wang, Wenyu Liu, Gang Yu, and Chunhua Shen. TopFormer: Token pyramid transformer for mobile semantic segmentation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12083– 12093, 2022. 2, 5
2022
-
[33]
SceneparsingthroughADE20K dataset
BoleiZhou,HangZhao,XavierPuig,SanjaFidler,AdelaBar- riuso,andAntonioTorralba. SceneparsingthroughADE20K dataset. InProceedingsoftheIEEEConferenceonComputer Vision and Pattern Recognition, pages 633–641, 2017. 4 A.TheUseofLargeLanguageModels(LLMs) Throughout the course of writing this paper, large lan- guage models were utilized under careful supervision a...
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.