Recognition: no theorem link
Not All Agents Matter: From Global Attention Dilution to Risk-Prioritized Game Planning
Pith reviewed 2026-05-10 18:47 UTC · model grok-4.3
The pith
End-to-end autonomous driving improves when high-risk agents are prioritized over equal treatment of all agents in a game model.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
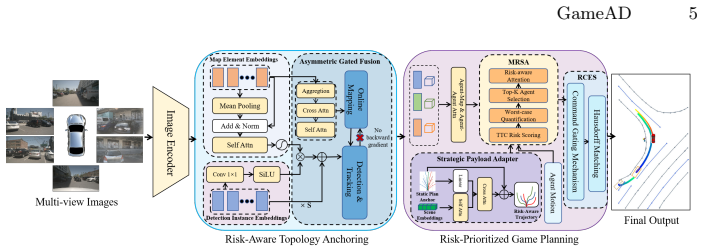
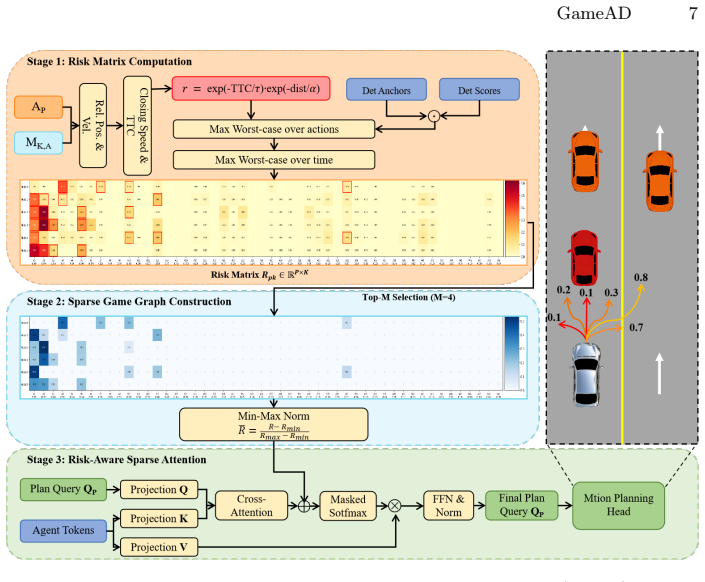
GameAD models end-to-end autonomous driving as a risk-aware game problem that integrates Risk-Aware Topology Anchoring, Strategic Payload Adapter, Minimax Risk-Aware Sparse Attention, and Risk Consistent Equilibrium Stabilization to enable game-theoretic decision making with risk-prioritized interactions, while the Planning Risk Exposure metric quantifies cumulative risk intensity of planned trajectories.
What carries the argument
The GameAD framework, which recasts end-to-end driving as risk-aware game planning and uses four modules to anchor and sparsify attention toward high-risk agents instead of uniform treatment.
If this is right
- Planned trajectories exhibit lower cumulative risk exposure over long horizons on nuScenes and Bench2Drive.
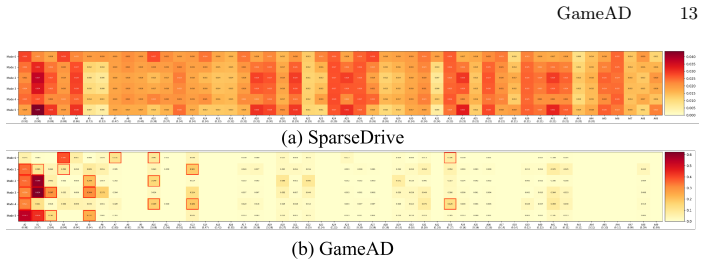
- Game-theoretic interactions focus computation on agents that actually threaten collision rather than all surrounding objects.
- Sparse attention mechanisms reduce dilution from complex backgrounds while preserving safety-critical signals.
- The approach yields measurable gains in trajectory safety metrics over prior state-of-the-art end-to-end planners.
Where Pith is reading between the lines
- Similar risk-prioritization logic could apply to multi-agent coordination in robotics tasks outside driving, such as drone swarms or warehouse automation.
- The framework suggests that attention dilution is a general problem in unified perception-planning models whenever background elements outnumber threats.
- Testing the modules individually on controlled synthetic scenes would isolate which component contributes most to the reported safety gains.
Load-bearing premise
Modeling driving as this specific risk-aware game with the listed modules decouples real collision threats from backgrounds more reliably than equal-attention baselines without creating new failure modes.
What would settle it
Run GameAD on driving scenes that add many non-threatening agents engineered to trigger the risk modules, then measure whether planned trajectories become less safe or more conservative than equal-treatment baselines.
Figures


read the original abstract
End-to-end autonomous driving resides not in the integration of perception and planning, but rather in the dynamic multi-agent game within a unified representation space. Most existing end-to-end models treat all agents equally, hindering the decoupling of real collision threats from complex backgrounds. To address this issue, We introduce the concept of Risk-Prioritized Game Planning, and propose GameAD, a novel framework that models end-to-end autonomous driving as a risk-aware game problem. The GameAD integrates Risk-Aware Topology Anchoring, Strategic Payload Adapter, Minimax Risk-Aware Sparse Attention, and Risk Consistent Equilibrium Stabilization to enable game theoretic decision making with risk prioritized interactions. We also present the Planning Risk Exposure metric, which quantifies the cumulative risk intensity of planned trajectories over a long horizon for safe autonomous driving. Extensive experiments on the nuScenes and Bench2Drive datasets show that our approach significantly outperforms state-of-the-art methods, especially in terms of trajectory safety.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that end-to-end autonomous driving should be modeled as a risk-aware multi-agent game rather than treating all agents equally in attention mechanisms. It introduces the GameAD framework, which integrates Risk-Aware Topology Anchoring, Strategic Payload Adapter, Minimax Risk-Aware Sparse Attention, and Risk Consistent Equilibrium Stabilization to enable risk-prioritized interactions. The work also proposes the Planning Risk Exposure metric to quantify long-horizon trajectory risk and reports significant outperformance over state-of-the-art methods on nuScenes and Bench2Drive, especially in trajectory safety.
Significance. If the empirical gains are shown to arise specifically from the game-theoretic risk prioritization rather than from additional capacity or tuning, the approach could meaningfully advance safe planning in dense multi-agent scenes by mitigating global attention dilution. The Planning Risk Exposure metric offers a potentially useful safety-oriented evaluation tool beyond standard collision rates.
major comments (2)
- [Abstract] Abstract: The central claim that the four modules produce risk-prioritized game equilibria (rather than heuristic sparse attention) is load-bearing for the title, abstract, and reported safety gains, yet no convergence analysis, best-response deviation test, or equilibrium verification is described for Risk Consistent Equilibrium Stabilization or Minimax Risk-Aware Sparse Attention. Without such checks, it is impossible to confirm that attention sparsity is driven by risk quantities rather than learned heuristics or auxiliary losses.
- [Abstract] Abstract: No ablation studies, component-wise comparisons, or controls against plain sparse attention are mentioned, making it impossible to isolate whether performance improvements on nuScenes and Bench2Drive stem from the risk-aware game framing or from unstated implementation details. This directly affects the claim that the framework decouples collision threats better than equal-treatment attention.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which highlights important aspects of validating the game-theoretic claims and isolating the contributions of our proposed components. We address each major comment below and will incorporate revisions to strengthen the empirical grounding of the risk-prioritized game framing.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that the four modules produce risk-prioritized game equilibria (rather than heuristic sparse attention) is load-bearing for the title, abstract, and reported safety gains, yet no convergence analysis, best-response deviation test, or equilibrium verification is described for Risk Consistent Equilibrium Stabilization or Minimax Risk-Aware Sparse Attention. Without such checks, it is impossible to confirm that attention sparsity is driven by risk quantities rather than learned heuristics or auxiliary losses.
Authors: We agree that explicit verification is needed to substantiate that the attention sparsity and stabilization arise from risk quantities rather than auxiliary effects. The Minimax Risk-Aware Sparse Attention and Risk Consistent Equilibrium Stabilization modules are designed to use per-agent risk scores (derived from trajectory predictions and collision probabilities) to modulate attention weights and enforce equilibrium-like consistency. However, the original submission did not include convergence analysis or best-response deviation tests. In revision, we will add an appendix with: (i) empirical best-response deviation metrics computed on held-out multi-agent rollouts, comparing risk-aware attention outputs against optimal responses in simplified game simulations; and (ii) ablation of risk-score influence by replacing risk quantities with uniform weights while keeping sparsity level fixed. This will directly address whether sparsity is risk-driven. revision: yes
-
Referee: [Abstract] Abstract: No ablation studies, component-wise comparisons, or controls against plain sparse attention are mentioned, making it impossible to isolate whether performance improvements on nuScenes and Bench2Drive stem from the risk-aware game framing or from unstated implementation details. This directly affects the claim that the framework decouples collision threats better than equal-treatment attention.
Authors: We concur that component ablations and controls against plain sparse attention are essential to isolate the benefit of risk-prioritized interactions. The submitted manuscript reported overall gains on nuScenes and Bench2Drive but did not present these controls. We will revise the experiments section to include: (1) full component-wise ablations removing each of Risk-Aware Topology Anchoring, Strategic Payload Adapter, Minimax Risk-Aware Sparse Attention, and Risk Consistent Equilibrium Stabilization individually; (2) a direct baseline using standard sparse attention (e.g., top-k without risk modulation) at matched sparsity and capacity; and (3) corresponding results on both the Planning Risk Exposure metric and collision rates. These additions will clarify the source of the observed safety improvements. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper's abstract and high-level description introduce GameAD with four custom modules (Risk-Aware Topology Anchoring, Strategic Payload Adapter, Minimax Risk-Aware Sparse Attention, Risk Consistent Equilibrium Stabilization) and a new Planning Risk Exposure metric. No equations, parameter-fitting procedures, or derivation steps are visible that reduce predictions to inputs by construction, self-define terms circularly, or rely on load-bearing self-citations for uniqueness. The central claims rest on empirical outperformance versus SOTA on external datasets (nuScenes, Bench2Drive), which are independent benchmarks. The absence of formal equilibrium verification is a potential correctness gap but does not constitute circularity under the defined patterns, as no self-referential reduction is exhibited.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Caesar, H., Bankiti, V., Lang, A.H., Vora, S., Liong, V.E., Xu, Q., Krishnan, A., Pan, Y., Baldan, G., Beijbom, O.: nuscenes: A multimodal dataset for autonomous driving. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 11621–11631 (2020)
2020
-
[2]
IEEE Transactions on Pattern Analysis and Ma- chine Intelligence46(12), 10164–10183 (2024)
Chen, L., Wu, P., Chitta, K., Jaeger, B., Geiger, A., Li, H.: End-to-end autonomous driving: Challenges and frontiers. IEEE Transactions on Pattern Analysis and Ma- chine Intelligence46(12), 10164–10183 (2024)
2024
-
[3]
2024 IEEE International Conference on Robotics and Automation (ICRA) pp
Cheng, J., Chen, Y., Mei, X., Yang, B., Li, B., Liu, M.: Rethinking imitation- based planners for autonomous driving. 2024 IEEE International Conference on Robotics and Automation (ICRA) pp. 14123–14130 (2024),https://api. semanticscholar.org/CorpusID:271798811
2024
-
[4]
In: Conference on Robot Learning
Dauner, D., Hallgarten, M., Geiger, A., Chitta, K.: Parting with misconceptions about learning-based vehicle motion planning. In: Conference on Robot Learning. pp. 1268–1281. PMLR (2023)
2023
-
[5]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Gu, J., Hu, C., Zhang, T., Chen, X., Wang, Y., Wang, Y., Zhao, H.: Vip3d: End- to-end visual trajectory prediction via 3d agent queries. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 5496– 5506 (2023)
2023
-
[6]
2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) pp
He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) pp. 770–778 (2015),https://api.semanticscholar.org/CorpusID:206594692
2016
-
[7]
In: European Confer- ence on Computer Vision (2022),https://api.semanticscholar.org/CorpusID: 250607597
Hu, S., Chen, L., Wu, P., Li, H., Yan, J., Tao, D.: St-p3: End-to-end vision-based autonomous driving via spatial-temporal feature learning. In: European Confer- ence on Computer Vision (2022),https://api.semanticscholar.org/CorpusID: 250607597
2022
-
[8]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2023)
Hu, Y., Yang, J., Chen, L., Li, K., Sima, C., Zhu, X., Chai, S., Du, S., Lin, T., Wang, W., Lu, L., Jia, X., Liu, Q., Dai, J., Qiao, Y., Li, H.: Planning-oriented autonomous driving. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2023)
2023
-
[9]
arXiv preprint arXiv:2203.17054 (2022)
Huang, J., Huang, G.: Bevdet4d: Exploit temporal cues in multi-camera 3d object detection. arXiv preprint arXiv:2203.17054 (2022)
-
[10]
BEVDet: High-performance Multi-camera 3D Object Detection in Bird-Eye-View
Huang, J., Huang, G., Zhu, Z., Yun, Y., Du, D.: Bevdet: High-performance multi- camera 3d object detection in bird-eye-view. arXiv preprint arXiv:2112.11790 (2021)
work page internal anchor Pith review arXiv 2021
-
[11]
arXiv preprint arXiv:2503.10898 (2024)
Huang, Y., Cheng, Y., Wang, K.: Trajectory mamba: Efficient attention-mamba forecasting model based on selective ssm. arXiv preprint arXiv:2503.10898 (2024)
-
[12]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)
Huang, Z., Liu, H., Lv, C.: Gameformer: Game-theoretic modeling and learning of transformer-based interactive prediction and planning for autonomous driving. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). pp. 3903–3913 (October 2023)
2023
-
[13]
Advances in Neural Information Processing Systems37, 819–844 (2024)
Jia, X., Yang, Z., Li, Q., Zhang, Z., Yan, J.: Bench2drive: Towards multi-ability benchmarking of closed-loop end-to-end autonomous driving. Advances in Neural Information Processing Systems37, 819–844 (2024)
2024
-
[14]
In: The Fourteenth In- ternational Conference on Learning Representations (2026),https://openreview
Jiang, B., Chen, S., Gao, H., Liao, B., Zhang, Q., Liu, W., Wang, X.: VADv2: End-to-end autonomous driving via probabilistic planning. In: The Fourteenth In- ternational Conference on Learning Representations (2026),https://openreview. net/forum?id=0a4dA6eUHN 16 K. Ding et al
2026
-
[15]
In: 2023 IEEE/CVF International Conference on Computer Vision (ICCV)
Jiang, B., Chen, S., Xu, Q., Liao, B., Chen, J., Zhou, H., Zhang, Q., Liu, W., Huang,C.,Wang,X.:Vad:Vectorizedscenerepresentationforefficientautonomous driving. In: ICCV. pp. 8306–8316 (2023),https://doi.org/10.1109/ICCV51070. 2023.00766
-
[16]
Hdmapnet: An online HD map construction and evaluation framework
Li, Q., Wang, Y., Wang, Y., Zhao, H.: Hdmapnet: An online hd map construction and evaluation framework. CoRRabs/2107.06307(2021),https://arxiv.org/ abs/2107.06307
-
[17]
In: European Conference on Computer Vision (2022), https://api.semanticscholar.org/CorpusID:247839336
Li, Z., Wang, W., Li, H., Xie, E., Sima, C., Lu, T., Yu, Q., Dai, J.: Bev- former: Learning bird’s-eye-view representation from multi-camera images via spa- tiotemporal transformers. In: European Conference on Computer Vision (2022), https://api.semanticscholar.org/CorpusID:247839336
2022
-
[18]
Li, Z., Yu, Z., Lan, S., Li, J., Kautz, J., Lu, T., Álvarez, J.M.: Is ego status all you need for open-loop end-to-end autonomous driving? In: CVPR. pp. 14864–14873 (2024),https://doi.org/10.1109/CVPR52733.2024.01408
-
[19]
In: International Conference on Learning Representations (2023)
Liao, B., Chen, S., Wang, X., Cheng, T., Zhang, Q., Liu, W., Huang, C.: Maptr: Structured modeling and learning for online vectorized hd map construction. In: International Conference on Learning Representations (2023)
2023
-
[20]
Sparse4d v2: Recurrent temporal fusion with sparse model.arXiv preprint arXiv:2305.14018, 2023
Lin, X., Lin, T., Pei, Z.H., Huang, L., Su, Z.: Sparse4d v2: Recurrent tempo- ral fusion with sparse model. ArXivabs/2305.14018(2023),https://api. semanticscholar.org/CorpusID:258841133
-
[21]
arXiv preprint arXiv:2211.10581 (2022)
Lin,X.,Lin,T.,Pei,Z.,Huang,L.,Su,Z.:Sparse4d:Multi-view3dobjectdetection with sparse spatial-temporal fusion. CoRRabs/2211.10581(2022),https:// doi.org/10.48550/arXiv.2211.10581
-
[22]
In: International conference on machine learning
Liu, Y., Yuan, T., Wang, Y., Wang, Y., Zhao, H.: Vectormapnet: End-to-end vec- torized hd map learning. In: International conference on machine learning. PMLR (2023)
2023
-
[23]
Liu, Z., Tang, H., Amini, A., Yang, X., Mao, H., Rus, D., Han, S.: Bevfusion: Multi-taskmulti-sensorfusionwithunifiedbird’s-eyeviewrepresentation.In:IEEE International Conference on Robotics and Automation (ICRA) (2023)
2023
-
[24]
In: International Conference on Learning Representations (2017),https://api.semanticscholar
Loshchilov, I., Hutter, F.: Decoupled weight decay regularization. In: International Conference on Learning Representations (2017),https://api.semanticscholar. org/CorpusID:53592270
2017
-
[25]
In: International Conference on Learning Representations (2017),https : / / openreview.net/forum?id=Skq89Scxx
Loshchilov, I., Hutter, F.: SGDR: Stochastic gradient descent with warm restarts. In: International Conference on Learning Representations (2017),https : / / openreview.net/forum?id=Skq89Scxx
2017
-
[26]
In: The IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (June 2022)
Meinhardt, T., Kirillov, A., Leal-Taixe, L., Feichtenhofer, C.: Trackformer: Multi- object tracking with transformers. In: The IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (June 2022)
2022
-
[27]
In: Proceedings of the European Conference on Computer Vision (2020)
Philion, J., Fidler, S.: Lift, splat, shoot: Encoding images from arbitrary camera rigs by implicitly unprojecting to 3d. In: Proceedings of the European Conference on Computer Vision (2020)
2020
-
[28]
7073–7083 (2021),https://api.semanticscholar.org/ CorpusID:233148602
Prakash, A., Chitta, K., Geiger, A.: Multi-modal fusion transformer for end-to-end autonomousdriving.2021IEEE/CVFConferenceonComputerVisionandPattern Recognition (CVPR) pp. 7073–7083 (2021),https://api.semanticscholar.org/ CorpusID:233148602
2021
-
[29]
Advances in Neural Information Pro- cessing Systems35, 6531–6543 (2022)
Shi, S., Jiang, L., Dai, D., Schiele, B.: Motion transformer with global intention localization and local movement refinement. Advances in Neural Information Pro- cessing Systems35, 6531–6543 (2022)
2022
-
[30]
MTR++: Multi-Agent Motion Prediction with Symmetric Scene Modeling and Guided Intention Querying,
Shi, S., Jiang, L., Dai, D., Schiele, B.: Mtr++: Multi-agent motion prediction with symmetric scene modeling and guided intention querying. arXiv preprint arXiv:2306.17770 (2023) GameAD 17
-
[31]
2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) pp
Song, Z., Jia, C., Liu, L., Pan, H., Zhang, Y., Wang, J., Zhang, X., Xu, S., Yang, L., Luo, Y.: Don’t shake the wheel: Momentum-aware planning in end-to-end au- tonomous driving. 2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) pp. 22432–22441 (2025),https://api.semanticscholar. org/CorpusID:276782149
2025
-
[32]
IEEE Transactions on Intelligent Transportation Systems25, 15407–15436 (2024),https://api.semanticscholar.org/CorpusID:266977207
Song, Z., Liu, L., Jia, F., Luo, Y., Jia, C., Zhang, G., Yang, L., Wang, L.: Robustness-aware 3d object detection in autonomous driving: A review and out- look. IEEE Transactions on Intelligent Transportation Systems25, 15407–15436 (2024),https://api.semanticscholar.org/CorpusID:266977207
2024
-
[33]
2025 IEEE International Conference on Robotics and Automation (ICRA) pp
Sun, W., Lin, X., Shi, Y., Zhang, C., Wu, H., Zheng, S.: Sparsedrive: End-to- end autonomous driving via sparse scene representation. 2025 IEEE International Conference on Robotics and Automation (ICRA) pp. 8795–8801 (2024),https: //api.semanticscholar.org/CorpusID:270123261
2025
-
[34]
IEEE Transactions on Intelligent Vehicles8, 3781–3798 (2023),https://api.semanticscholar.org/CorpusID:260432447
xilinx Wang, L., Zhang, X., Song, Z., Bi, J., Zhang, G., Wei, H., Tang, L., Yang, L., Li, J., Jia, C., Zhao, L.: Multi-modal 3d object detection in autonomous driving: A survey and taxonomy. IEEE Transactions on Intelligent Vehicles8, 3781–3798 (2023),https://api.semanticscholar.org/CorpusID:260432447
2023
-
[35]
2023 IEEE/CVF Inter- national Conference on Computer Vision (ICCV) pp
Wang, S., Liu, Y., Wang, T., Li, Y., Zhang, X.: Exploring object-centric tempo- ral modeling for efficient multi-view 3d object detection. 2023 IEEE/CVF Inter- national Conference on Computer Vision (ICCV) pp. 3598–3608 (2023),https: //api.semanticscholar.org/CorpusID:257636991
2023
-
[36]
In: Workshop on Making Sense of Data in Robotics: Composition, Curation, and Interpretability at Scale at CoRL 2025 (2025),https://openreview.net/forum?id=4SXdVmswuu
Xu, Y., Yin, Y., Zablocki, E., Vu, T.H., Boulch, A., Cord, M.: PPT: Pretraining with pseudo-labeled trajectories for motion forecasting. In: Workshop on Making Sense of Data in Robotics: Composition, Curation, and Interpretability at Scale at CoRL 2025 (2025),https://openreview.net/forum?id=4SXdVmswuu
2025
-
[37]
CVPR (2021)
Yin, T., Zhou, X., Krähenbühl, P.: Center-based 3d object detection and tracking. CVPR (2021)
2021
-
[38]
In: European Conference on Computer Vision (ECCV) (2022)
Zeng, F., Dong, B., Zhang, Y., Wang, T., Zhang, X., Wei, Y.: Motr: End-to-end multiple-object tracking with transformer. In: European Conference on Computer Vision (ECCV) (2022)
2022
-
[39]
In: CVPR (2025)
Zhang, B., Song, N., Jin, X., Zhang, L.: Bridging past and future: End-to-end autonomous driving with historical prediction and planning. In: CVPR (2025)
2025
-
[40]
In: NeurIPS (2024),http://papers
Zhang, B., Song, N., Zhang, L.: Demo: Decoupling motion forecasting into di- rectional intentions and dynamic states. In: NeurIPS (2024),http://papers. nips.cc/paper_files/paper/2024/hash/c0ff9e52e94ae331bc0f2d28be06a9ca- Abstract-Conference.html
2024
-
[41]
Zhang, D., Wang, G., Zhu, R., Zhao, J., Chen, X., Zhang, S., Gong, J., Zhou, Q., Zhang, W., Wang, N., Tan, F., Zhou, H., Xu, Z., Yao, H., Zhang, C., Liu, X., Di, X., Li, B.: Sparsead: Sparse query-centric paradigm for efficient end-to-end autonomous driving. ArXivabs/2404.06892(2024),https://api. semanticscholar.org/CorpusID:269033031
-
[42]
Genad: Generative end-to-end autonomous driving.arXiv preprint arXiv:2402.11502, 2024
Zheng, W., Song, R., Guo, X., Zhang, C., Chen, L.: Genad: Generative end-to-end autonomous driving. arXiv preprint arXiv: 2402.11502 (2024)
-
[43]
2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) pp
Zhou, Z., Wang, J., Li, Y.H., Huang, Y.K.: Query-centric trajectory predic- tion. 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) pp. 17863–17873 (2023),https://api.semanticscholar.org/CorpusID: 259359908
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.