Recognition: no theorem link
Qurator: Scheduling Hybrid Quantum-Classical Workflows Across Heterogeneous Cloud Providers
Pith reviewed 2026-05-10 20:07 UTC · model grok-4.3
The pith
Qurator jointly optimizes queue time and fidelity for hybrid quantum-classical workflows across heterogeneous providers by modeling them as dynamic DAGs with a unified logarithmic success score.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Qurator is an architecture-agnostic quantum-classical task scheduler that jointly optimizes queue time and circuit fidelity across heterogeneous providers. It models hybrid workloads as dynamic DAGs with explicit quantum semantics, including entanglement dependencies, synchronization barriers, no-cloning constraints, and circuit cutting and merging decisions. Fidelity is estimated through a unified logarithmic success score that reconciles incompatible calibration data from IBM, IonQ, IQM, Rigetti, AQT, and QuEra into a canonical set of gate error, readout fidelity, and decoherence terms.
What carries the argument
The unified logarithmic success score that converts disparate provider calibration data into one comparable fidelity value, together with the dynamic DAG model that captures quantum-specific dependencies.
Load-bearing premise
A single logarithmic success score can accurately reconcile calibration data from different providers and the historical queue simulator faithfully predicts real-world joint optimization results.
What would settle it
Running the same workloads on live queues at the listed providers and checking whether observed queue times and achieved fidelities fall within the 1 percent and 30-75 percent bounds reported by the simulator.
Figures

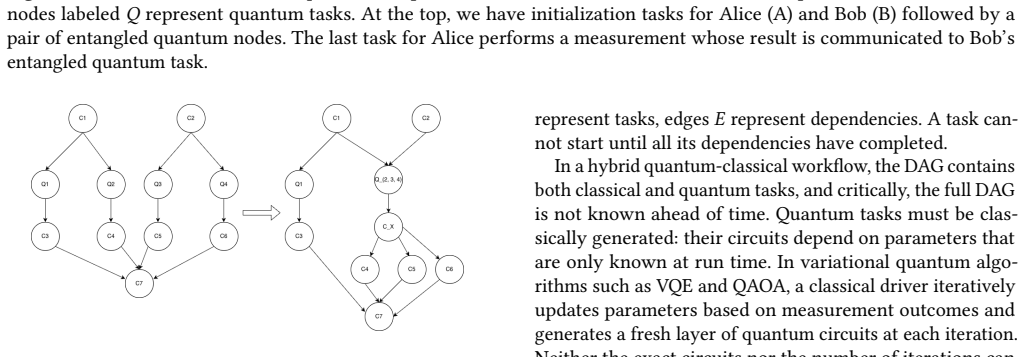






read the original abstract
As quantum computing moves from isolated experiments toward integration with large-scale workflows, the integration of quantum devices into HPC systems has gained much interest. Quantum cloud providers expose shared devices through first-come first-serve queues where a circuit that executes in 3 seconds can spend minutes to an entire day waiting. Minimizing this overhead while maintaining execution fidelity is the central challenge of quantum cloud scheduling, and existing approaches treat the two as separate concerns. We present Qurator, an architecture-agnostic quantum-classical task scheduler that jointly optimizes queue time and circuit fidelity across heterogeneous providers. Qurator models hybrid workloads as dynamic DAGs with explicit quantum semantics, including entanglement dependencies, synchronization barriers, no-cloning constraints, and circuit cutting and merging decisions, all of which render classical scheduling techniques ineffective. Fidelity is estimated through a unified logarithmic success score that reconciles incompatible calibration data from IBM, IonQ, IQM, Rigetti, AQT, and QuEra into a canonical set of gate error, readout fidelity, and decoherence terms. We evaluate Qurator on a simulator driven by four months of real queue data using circuits from the Munich Quantum Toolkit benchmark suite. Across load conditions from 5 to 35,000 quantum tasks, Qurator stays within 1% of the highest-fidelity baseline at low load while achieving 30-75% queue time reduction at high load, at a fidelity cost bounded by a user-specified target.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents Qurator, an architecture-agnostic scheduler for hybrid quantum-classical workflows modeled as dynamic DAGs that incorporate quantum semantics such as entanglement, no-cloning, and circuit cutting. It jointly optimizes queue time and execution fidelity across heterogeneous providers (IBM, IonQ, IQM, Rigetti, AQT, QuEra) via a unified logarithmic success score derived from gate error, readout, and decoherence terms, and evaluates the system on a simulator replaying four months of real queue traces with Munich Quantum Toolkit benchmark circuits. The central claims are that Qurator stays within 1% of the highest-fidelity baseline at low load (5 tasks) while delivering 30-75% queue-time reduction at high load (up to 35,000 tasks), with fidelity cost bounded by a user-specified target.
Significance. If the unified fidelity model and simulation predictions are shown to hold on real hardware, the work would be significant for practical quantum-cloud integration by demonstrating that joint queue-fidelity optimization is feasible at scale without classical scheduling techniques. The use of real multi-month queue data and standard benchmarks is a positive aspect that grounds the evaluation in realistic conditions.
major comments (2)
- [Abstract and Evaluation] Abstract and Evaluation section: the reported 1% fidelity adherence and bounded-cost claims at high load rest on the unified logarithmic success score, yet the manuscript supplies no derivation details, error bars, sensitivity analysis, or validation of this score against actual hardware executions on the listed providers; the simulator only replays historical wait times and does not run circuits or measure success probabilities, leaving the fidelity component of the joint objective unverified.
- [Fidelity Model] Fidelity Model description: the assumption that a single logarithmic score can produce accurate relative fidelity estimates across incompatible calibration formats and measurement protocols (gate error, readout, decoherence) from IBM, IonQ, IQM, Rigetti, AQT, and QuEra is load-bearing for all cross-provider scheduling decisions; without cross-architecture hardware benchmarks or explicit reconciliation methodology, the claim that fidelity cost remains bounded by the user target cannot be substantiated.
minor comments (2)
- [Evaluation] Clarify the precise number of benchmark circuits, task counts per load point, and how the four-month queue trace was sampled to enable reproducibility.
- [System Model] The DAG model description would benefit from an explicit statement of which quantum constraints (entanglement, synchronization, circuit cutting) are actually enforced in the scheduler implementation versus treated as soft constraints.
Simulated Author's Rebuttal
We thank the referee for the constructive comments highlighting the need for greater transparency in the fidelity model and its role in the evaluation. We address each major comment below, indicating revisions where appropriate while noting limitations that cannot be fully resolved without additional hardware experiments.
read point-by-point responses
-
Referee: [Abstract and Evaluation] Abstract and Evaluation section: the reported 1% fidelity adherence and bounded-cost claims at high load rest on the unified logarithmic success score, yet the manuscript supplies no derivation details, error bars, sensitivity analysis, or validation of this score against actual hardware executions on the listed providers; the simulator only replays historical wait times and does not run circuits or measure success probabilities, leaving the fidelity component of the joint objective unverified.
Authors: We acknowledge that the evaluation relies on the fidelity model for estimated success probabilities rather than direct hardware measurements of circuit outcomes. The simulator replays real queue traces to drive scheduling decisions and reports model-derived fidelity scores, but does not execute circuits. In revision we will add a detailed derivation of the logarithmic success score (including the precise formulas combining gate-error, readout, and decoherence contributions) together with sensitivity analysis over calibration-parameter ranges and error bars derived from the model. We will also explicitly state the reliance on the model and the absence of end-to-end hardware success-probability validation as a limitation of the current study. revision: partial
-
Referee: [Fidelity Model] Fidelity Model description: the assumption that a single logarithmic score can produce accurate relative fidelity estimates across incompatible calibration formats and measurement protocols (gate error, readout, decoherence) from IBM, IonQ, IQM, Rigetti, AQT, and QuEra is load-bearing for all cross-provider scheduling decisions; without cross-architecture hardware benchmarks or explicit reconciliation methodology, the claim that fidelity cost remains bounded by the user target cannot be substantiated.
Authors: The model first normalizes each provider’s published calibration data into a common canonical set of per-gate error rates, readout fidelities, and T1/T2 decoherence times, then applies a logarithmic aggregation to obtain a relative success score. We will expand the Fidelity Model section with an explicit reconciliation subsection that documents the mapping steps for every listed provider. The user-specified fidelity target is enforced directly as a hard constraint within the joint optimization, guaranteeing that no selected schedule exceeds the allowed degradation relative to the highest-fidelity feasible option under the model. Cross-architecture hardware benchmarks would strengthen the claims but lie outside the present simulation-based scope. revision: partial
- Empirical validation of the unified logarithmic fidelity score against measured success probabilities obtained from actual circuit executions on the six listed hardware providers
Circularity Check
No significant circularity detected in Qurator's scheduling derivation
full rationale
The paper presents Qurator as modeling hybrid workloads as dynamic DAGs with quantum semantics and estimating fidelity via a unified logarithmic success score that maps provider calibrations to canonical terms. Performance results (1% fidelity adherence at low load, 30-75% queue time reduction at high load) are obtained from a simulator replaying four months of historical queue data on Munich Quantum Toolkit circuits, with comparisons to baselines. No equations, predictions, or central claims reduce by construction to fitted parameters defined from the evaluation data, self-citations, or ansatzes smuggled via prior author work; the unification and scheduling logic are presented as independent design choices grounded in external calibrations and traces.
Axiom & Free-Parameter Ledger
free parameters (1)
- user-specified fidelity target bound
axioms (2)
- domain assumption Logarithmic success score unifies gate error, readout fidelity, and decoherence terms across providers
- domain assumption Simulator driven by four months of real queue data accurately represents production behavior
Reference graph
Works this paper leans on
-
[1]
Mohit Agarwal and Gur Mauj Saran Srivastava. 2016. A genetic algorithm inspired task scheduling in cloud computing. In2016 Inter- national Conference on Computing, Communication and Automation (ICCCA). 364–367. doi:10.1109/CCAA.2016.7813746
-
[2]
A.H. Alhusaini, V.K. Prasanna, and C.S. Raghavendra. 1999. A unified resource scheduling framework for heterogeneous computing envi- ronments. InProceedings. Eighth Heterogeneous Computing Workshop (HCW’99). 156–165. doi:10.1109/HCW.1999.765123
-
[3]
Jaime Alvarado-Valiente, Javier Romero-Álvarez, Enrique Moguel, Jose García-Alonso, and Juan M. Murillo. 2024. Orchestration for quantum services: The power of load balancing across multiple service providers. Science of Computer Programming237 (2024), 103139. doi:10.1016/j. scico.2024.103139
work page doi:10.1016/j 2024
-
[4]
Amazon Web Services. [n. d.]. Amazon Braket.https://aws.amazon. com/braket/
-
[5]
Hamid Arabnejad and Jorge G. Barbosa. 2014. List Scheduling Algorithm for Heterogeneous Systems by an Optimistic Cost Ta- ble.IEEE Trans. Parallel Distrib. Syst.25, 3 (March 2014), 682–694. doi:10.1109/TPDS.2013.57
-
[6]
P. Armstrong, A. Agarwal, A. Bishop, A. Charbonneau, R. Desmarais, K. Fransham, N. Hill, I. Gable, S. Gaudet, S. Goliath, R. Impey, C. Leavett- Brown, J. Ouellete, M. Paterson, C. Pritchet, D. Penfold-Brown, W. Podaima, D. Schade, and R. J. Sobie. 2010. Cloud Scheduler: a resource manager for distributed compute clouds. arXiv:1007.0050 [cs.DC]
-
[7]
M. Arora, S.K. Das, and R. Biswas. 2002. A de-centralized scheduling and load balancing algorithm for heterogeneous grid environments. In Proceedings. International Conference on Parallel Processing Workshop. 499–505. doi:10.1109/ICPPW.2002.1039771
-
[8]
Cédric Augonnet, Samuel Thibault, Raymond Namyst, and Pierre- André Wacrenier. 2011. StarPU: a unified platform for task scheduling on heterogeneous multicore architectures.Concurr. Comput.: Pract. Exper.23, 2 (Feb. 2011), 187–198. doi:10.1002/cpe.1631 12
-
[9]
Rashmi Bajaj and D.P. Agrawal. 2004. Improving scheduling of tasks in a heterogeneous environment.IEEE Transactions on Parallel and Distributed Systems15, 2 (2004), 107–118. doi:10.1109/TPDS.2004. 1264795
-
[10]
Humble, Ryan Landfield, Ketan Mahesh- wari, Sarp Oral, Michael A
Thomas Beck, Alessandro Baroni, Ryan Bennink, Gilles Buchs, Ed- uardo Antonio Coello Pérez, Markus Eisenbach, Rafael Ferreira da Silva, Muralikrishnan Gopalakrishnan Meena, Kalyan Gottiparthi, Peter Groszkowski, Travis S. Humble, Ryan Landfield, Ketan Mahesh- wari, Sarp Oral, Michael A. Sandoval, Amir Shehata, In-Saeng Suh, and Christopher Zimmer. 2024. I...
-
[11]
Martin Beisel, Johanna Barzen, Marvin Bechtold, Frank Leymann, Felix Truger, and Benjamin Weder. 2023. QuantME4VQA: Modeling and Executing Variational Quantum Algorithms Using Workflows. InInternational Conference on Cloud Computing and Services Science. doi:10.5220/0011997500003488
-
[12]
Martin Beisel, Johanna Barzen, Simon Garhofer, Frank Leymann, Felix Truger, Benjamin Weder, and Vladimir Yussupov. 2022. Quokka: A Ser- vice Ecosystem for Workflow-Based Execution of Variational Quantum Algorithms. InService-Oriented Computing – ICSOC 2022 Workshops: ASOCA, AI-PA, FMCIoT, WESOACS 2022, Sevilla, Spain, November 29 – December 2, 2022 Procee...
- [13]
-
[14]
Nicola Capodieci, Roberto Cavicchioli, Marko Bertogna, and Aingara Paramakuru. 2018. Deadline-Based Scheduling for GPU with Pre- emption Support. In2018 IEEE Real-Time Systems Symposium (RTSS). 119–130. doi:10.1109/RTSS.2018.00021
-
[15]
Splitwise: Efficient generative llm inference using phase splitting
Ishita Chaturvedi, Bhargav Reddy Godala, Yucan Wu, Ziyang Xu, Konstantinos Iliakis, Panagiotis-Eleftherios Eleftherakis, Sotirios Xy- dis, Dimitrios Soudris, Tyler Sorensen, Simone Campanoni, Tor M. Aamodt, and David I. August. 2024. GhOST: a GPU Out-of-Order Scheduling Technique for Stall Reduction. In2024 ACM/IEEE 51st An- nual International Symposium o...
- [16]
-
[17]
Andrew Cross, Ali Javadi-Abhari, Thomas Alexander, Niel De Beau- drap, Lev S. Bishop, Steven Heidel, Colm A. Ryan, Prasahnt Sivara- jah, John Smolin, Jay M. Gambetta, and Blake R. Johnson. 2022. OpenQASM 3: A Broader and Deeper Quantum Assembly Language. ACM Transactions on Quantum Computing3, 3 (Sept. 2022), 1–50. doi:10.1145/3505636
-
[18]
Difallah, Chris Douglas, Subru Krishnan, Raghu Ramakrishnan, and Sriram Rao
Carlo Curino, Djellel E. Difallah, Chris Douglas, Subru Krishnan, Raghu Ramakrishnan, and Sriram Rao. 2014. Reservation-based Scheduling: If You’re Late Don’t Blame Us!. InProceedings of the ACM Symposium on Cloud Computing(Seattle, WA, USA)(SOCC ’14). Association for Computing Machinery, New York, NY, USA, 1–14. doi:10.1145/2670979.2670981
-
[19]
Axel Dahlberg, Matthew Skrzypczyk, Tim Coopmans, Leon Wubben, Filip Rozpędek, Matteo Pompili, Arian Stolk, Przemysław Pawełczak, Robert Knegjens, Julio de Oliveira Filho, Ronald Hanson, and Stephanie Wehner. 2019. A link layer protocol for quantum networks. InPro- ceedings of the ACM Special Interest Group on Data Communication (SIGCOMM ’19). ACM, 159–173...
-
[20]
Ulrik de Muelenaere, Sinan Pehlivanoglu, Amr Sabry, and Peter M. Kogge. 2025. A Formalization of Measurement-Commuting Unitaries. In2025 IEEE International Conference on Quantum Computing and Engineering (QCE), Vol. 01. 439–447. doi:10.1109/QCE65121.2025.00056
-
[21]
Diamos and Sudhakar Yalamanchili
Gregory F. Diamos and Sudhakar Yalamanchili. 2008. Harmony: an execution model and runtime for heterogeneous many core systems. In Proceedings of the 17th International Symposium on High Performance Distributed Computing(Boston, MA, USA)(HPDC ’08). Association for Computing Machinery, New York, NY, USA, 197–200. doi:10.1145/ 1383422.1383447
-
[22]
Amr Elsharkawy, Xiaorang Guo, and Martin Schulz. 2024. Integration of Quantum Accelerators into HPC: Toward a Unified Quantum Plat- form. In2024 IEEE International Conference on Quantum Computing and Engineering (QCE), Vol. 01. 774–783. doi:10.1109/QCE60285.2024.00097
-
[23]
Distribution of entanglement in two-dimensional square grid network,
Aniello Esposito, Jessica R. Jones, Sebastien Cabaniols, and David Brayford. 2023. A Hybrid Classical-Quantum HPC Workload. In2023 IEEE International Conference on Quantum Computing and Engineering (QCE), Vol. 02. 117–121. doi:10.1109/QCE57702.2023.10194
-
[24]
Lionel Eyraud-Dubois, Gregory Mounie, and Denis Trystram. 2007. Analysis of Scheduling Algorithms with Reservations. In2007 IEEE International Parallel and Distributed Processing Symposium. 1–8. doi:10.1109/IPDPS.2007.370304
-
[25]
Ruwen Fan, Tingxu Ren, Minhui Xie, Shiwei Gao, Jiwu Shu, and Youyou Lu. 2025. GPREEMPT: GPU preemptive scheduling made general and efficient. InProceedings of the 2025 USENIX Conference on Usenix Annual Technical Conference(Boston, MA, USA)(USENIX ATC ’25). USENIX Association, USA, Article 16, 10 pages
2025
-
[26]
Nordine Feddal, Giuseppe Lipari, and Houssam-Eddine Zahaf. 2025. Towards Efficient Parallel GPU Scheduling: Interference Awareness with Schedule Abstraction. InProceedings of the 32nd International Conference on Real-Time Networks and Systems (RTNS ’24). Association for Computing Machinery, New York, NY, USA, 82–93. doi:10.1145/ 3696355.3696361
-
[27]
Vladlen Galetsky, Nilesh Vyas, Alberto Comin, and Janis Nötzel. 2025. Feasibility of logical Bell state generation in memory assisted quantum networks.Phys. Rev. Res.7 (July 2025), 033090. Issue 3. doi:10.1103/rsrk- c7yg
- [28]
-
[29]
Chris Gregg, Michael Boyer, Kim Hazelwood, and Kevin Skadron
-
[30]
(May 2012)
Dynamic Heterogeneous Scheduling Decisions Using Historical Runtime Data. (May 2012)
2012
-
[31]
HTCondor. [n. d.].https://htcondor.org/
-
[32]
Menglan Hu and Bharadwaj Veeravalli. 2014. Dynamic Scheduling of Hybrid Real-Time Tasks on Clusters.IEEE Trans. Comput.63, 12 (2014), 2988–2997. doi:10.1109/TC.2013.170
-
[33]
Jing-Jang Hwang, Yuan-Chieh Chow, Frank D. Anger, and Chung-Yee Lee. 1989. Scheduling precedence graphs in systems with interproces- sor communication times.SIAM J. Comput.18, 2 (April 1989), 244–257. doi:10.1137/0218016
-
[34]
IBM Quantum. [n. d.]. Quantum teleportation.https: //quantum.cloud.ibm.com/learning/en/courses/basics-of-quantum- information/entanglement-in-action/quantum-teleportation
-
[35]
Alexey Ilyushkin, Bogdan Ghit, and Dick Epema. 2015. Scheduling Workloads of Workflows with Unknown Task Runtimes. In2015 15th IEEE/ACM International Symposium on Cluster, Cloud and Grid Com- puting. 606–616. doi:10.1109/CCGrid.2015.27
-
[36]
Manar Jammal, Ali Kanso, and Abdallah Shami. 2015. CHASE: Compo- nent High Availability-Aware Scheduler in Cloud Computing Environ- ment. In2015 IEEE 8th International Conference on Cloud Computing. 477–484. doi:10.1109/CLOUD.2015.70
-
[37]
Ali Javadi-Abhari, Matthew Treinish, Kevin Krsulich, Christopher J. Wood, Jake Lishman, Julien Gacon, Simon Martiel, Paul D. Nation, Lev S. Bishop, Andrew W. Cross, Blake R. Johnson, and Jay M. Gam- betta. 2024. Quantum Computing with Qiskit. arXiv:2405.08810 [quant- ph] 13
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[38]
Konstantinos Karanasos, Sriram Rao, Carlo Curino, Chris Douglas, Kishore Chaliparambil, Giovanni Matteo Fumarola, Solom Heddaya, Raghu Ramakrishnan, and Sarvesh Sakalanaga. 2015. Mercury: hybrid centralized and distributed scheduling in large shared clusters. In Proceedings of the 2015 USENIX Conference on Usenix Annual Technical Conference(Santa Clara, C...
2015
-
[39]
Tran, Pradipta Ghosh, Pranav Sakulkar, Bhaskar Krishnamachari, and Murali Annavaram
Aleksandra Knezevic, Quynh Nguyen, Jason A. Tran, Pradipta Ghosh, Pranav Sakulkar, Bhaskar Krishnamachari, and Murali Annavaram
-
[40]
InProceedings of the Second ACM/IEEE Symposium on Edge Computing(San Jose, California)(SEC ’17)
CIRCE - a runtime scheduler for DAG-based dispersed com- puting: demo. InProceedings of the Second ACM/IEEE Symposium on Edge Computing(San Jose, California)(SEC ’17). Association for Computing Machinery, New York, NY, USA, Article 31, 2 pages. doi:10.1145/3132211.3132451
-
[41]
Final result of the ma- jorana demonstrator’s search for neutrinoless double-β decay in 76Ge (2023)
V. Krutyanskiy, M. Canteri, M. Meraner, J. Bate, V. Krcmarsky, J. Schupp, N. Sangouard, and B. P. Lanyon. 2023. Telecom-Wavelength Quantum Repeater Node Based on a Trapped-Ion Processor.Phys. Rev. Lett.130 (May 2023), 213601. Issue 21. doi:10.1103/PhysRevLett.130. 213601
-
[42]
Kumar, D.M
R. Kumar, D.M. Tullsen, P. Ranganathan, N.P. Jouppi, and K.I. Farkas
-
[43]
Single-ISA heterogeneous multi-core architectures for multi- threaded workload performance. InProceedings. 31st Annual Interna- tional Symposium on Computer Architecture, 2004.64–75. doi:10.1109/ ISCA.2004.1310764
-
[44]
Mehmet Can Kurt, Sriram Krishnamoorthy, Kunal Agrawal, and Gagan Agrawal. 2014. Fault-Tolerant Dynamic Task Graph Scheduling. InSC ’14: Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis. 719–730. doi:10.1109/ SC.2014.64
2014
-
[45]
Chung-Yee Lee, Jing-Jang Hwang, Yuan-Chieh Chow, and Frank D. Anger. 1988. Multiprocessor scheduling with interprocessor commu- nication delays.Oper. Res. Lett.7, 3 (June 1988), 141–147. doi:10.1016/ 0167-6377(88)90080-6
1988
-
[46]
Tingting Li and Ziming Zhao. 2024. Moirai: Optimizing Quantum Serverless Function Orchestration via Device Allocation and Circuit Deployment. In2024 IEEE International Conference on Web Services (ICWS). 707–717. doi:10.1109/ICWS62655.2024.00090
-
[47]
Michael D. Linderman, Jamison D. Collins, Hong Wang, and Teresa H. Meng. 2008. Merge: a programming model for heterogeneous multi- core systems. InProceedings of the 13th International Conference on Ar- chitectural Support for Programming Languages and Operating Systems (Seattle, WA, USA)(ASPLOS XIII). Association for Computing Machin- ery, New York, NY, ...
-
[48]
Chi-Keung Luk, Sunpyo Hong, and Hyesoon Kim. 2009. Qilin: Ex- ploiting parallelism on heterogeneous multiprocessors with adaptive mapping. In2009 42nd Annual IEEE/ACM International Symposium on Microarchitecture (MICRO). 45–55. doi:10.1145/1669112.1669121
-
[49]
Eleonora Maria Mocanu, Mihai Florea, Mugurel Ionuţ Andreica, and Nicolae Ţăpuş. 2012. Cloud Computing—Task scheduling based on ge- netic algorithms. In2012 IEEE International Systems Conference SysCon
2012
-
[50]
doi:10.1109/SysCon.2012.6189509
1–6. doi:10.1109/SysCon.2012.6189509
-
[51]
Paul D. Nation, Abdullah Ash Saki, Sebastian Brandhofer, Luciano Bello, Shelly Garion, Matthew Treinish, and Ali Javadi-Abhari. 2024. Benchmarking the performance of quantum computing software. arXiv:2409.08844 [quant-ph]
-
[52]
Kelvin K. W. Ng, Henri Maxime Demoulin, and Vincent Liu. 2023. Paella: Low-latency Model Serving with Software-defined GPU Sched- uling. InProceedings of the 29th Symposium on Operating Systems Prin- ciples(Koblenz, Germany)(SOSP ’23). Association for Computing Ma- chinery, New York, NY, USA, 595–610. doi:10.1145/3600006.3613163
-
[53]
NVIDIA. [n. d.]. CUDA.https://developer.nvidia.com/cuda
-
[54]
Fatma A. Omara and Mona M. Arafa. 2010. Genetic algorithms for task scheduling problem.J. Parallel and Distrib. Comput.70, 1 (2010), 13–22. doi:10.1016/j.jpdc.2009.09.009
-
[55]
OpenACC. [n. d.].https://www.openacc.org/
-
[56]
Aaron Orenstein and Vipin Chaudhary. 2024. QGroup: Parallel Quan- tum Job Scheduling Using Dynamic Programming. In2024 IEEE Inter- national Conference on Quantum Computing and Engineering (QCE), Vol. 01. 990–999. doi:10.1109/QCE60285.2024.00118
-
[57]
A.J. Page and T.J. Naughton. 2005. Dynamic task scheduling us- ing genetic algorithms for heterogeneous distributed computing. In 19th IEEE International Parallel and Distributed Processing Symposium. doi:10.1109/IPDPS.2005.184
-
[58]
Badia, Eduard Ayguadé, and Jesús Labarta
Judit Planas, Rosa M. Badia, Eduard Ayguadé, and Jesús Labarta. 2015. SSMART: smart scheduling of multi-architecture tasks on heteroge- neous systems. InProceedings of the Second Workshop on Accelerator Programming Using Directives(Austin, Texas)(W ACCPD ’15). Associa- tion for Computing Machinery, New York, NY, USA, Article 1, 11 pages. doi:10.1145/28321...
-
[59]
Nils Quetschlich, Lukas Burgholzer, and Robert Wille. 2023. MQT Bench: Benchmarking Software and Design Automation Tools for Quantum Computing.Quantum(2023). doi:10.22331/q-2023-07- 20-1062MQT Bench is available athttps://www.cda.cit.tum.de/ mqtbench/
-
[60]
Andrei Radulescu and Arjan JC Van Gemund. 2000. Fast and effective task scheduling in heterogeneous systems. InProceedings 9th het- erogeneous computing workshop (HCW 2000)(Cat. No. PR00556). IEEE, 229–238. doi:10.1109/HCW.2000.843747
-
[61]
Andrei Radulescu and Arjan J. C. Van Gemund. 1999. FLB: Fast Load Balancing for Distributed-Memory Machines. InProceedings of the 1999 International Conference on Parallel Processing (ICPP ’99). IEEE Computer Society, USA, 534. doi:10.1109/ICPP.1999.797442
-
[62]
Smith, Prakash Murali, and Fred- eric T
Gokul Subramanian Ravi, Kaitlin N. Smith, Prakash Murali, and Fred- eric T. Chong. 2021. Adaptive Job and Resource Management for the Growing Quantum Cloud. In2021 IEEE International Conference on Quantum Computing and Engineering (QCE). IEEE, Broomfield, CO, USA, 301–312. doi:10.1109/QCE52317.2021.00047
-
[63]
Vignesh T. Ravi and Gagan Agrawal. 2011. A dynamic scheduling framework for emerging heterogeneous systems. In18th International Conference on High Performance Computing. 1–10. doi:10.1109/HiPC. 2011.6152724
-
[64]
Ravi, Michela Becchi, Wei Jiang, Gagan Agrawal, and Srimat Chakradhar
Vignesh T. Ravi, Michela Becchi, Wei Jiang, Gagan Agrawal, and Srimat Chakradhar. 2012. Scheduling Concurrent Applications on a Cluster of CPU-GPU Nodes. In2012 12th IEEE/ACM International Symposium on Cluster, Cloud and Grid Computing (ccgrid 2012). 140–
2012
-
[65]
doi:10.1109/CCGrid.2012.78
-
[66]
R. Sakellariou and H. Zhao. 2004. A hybrid heuristic for DAG scheduling on heterogeneous systems. In18th International Par- allel and Distributed Processing Symposium, 2004. Proceedings.111. doi:10.1109/IPDPS.2004.1303065
- [67]
- [68]
-
[69]
Philipp Seitz, Manuel Geiger, and Christian B. Mendl. 2024. Mul- tithreaded Parallelism for Heterogeneous Clusters of QPUs. InISC High Performance 2024 Research Paper Proceedings (39th International Conference). IEEE, 1–8. doi:10.23919/isc.2024.10528940
-
[70]
Philipp Seitz, Manuel Geiger, Christian Ufrecht, Axel Plinge, Christo- pher Mutschler, Daniel D. Scherer, and Christian B. Mendl. 2024. SCIM MILQ: An HPC Quantum Scheduler. In2024 IEEE International Con- ference on Quantum Computing and Engineering (QCE). IEEE, 292–298. doi:10.1109/qce60285.2024.10294
-
[71]
Dipanjan Sengupta, Anshuman Goswami, Karsten Schwan, and Kr- ishna Pallavi. 2014. Scheduling Multi-tenant Cloud Workloads on 14 Accelerator-Based Systems. InSC ’14: Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis. 513–524. doi:10.1109/SC.2014.47
-
[72]
Jialun Shao, Junming Ma, Yan Li, Bo An, and Donggang Cao. 2019. GPU Scheduling for Short Tasks in Private Cloud. In2019 IEEE International Conference on Service-Oriented System Engineering (SOSE). 215–2155. doi:10.1109/SOSE.2019.00037
-
[73]
Amir Shehata, Peter Groszkowski, Thomas Naughton, Muralikrishnan Gopalakrishnan Meena, Elaine Wong, Daniel Claudino, Rafael Fer- reira da Silva, and Thomas Beck. 2026. Bridging paradigms: Designing for HPC-Quantum convergence.Future Generation Computer Systems 174 (Jan. 2026), 107980. doi:10.1016/j.future.2025.107980
-
[74]
Mateusz Slysz, Piotr Rydlichowski, Krzysztof Kurowski, Omar Bacar- reza, Esperanza Cuenca Gomez, Zohim Chandani, Bettina Heim, Prad- nya Khalate, William R. Clements, and James Fletcher. 2025. Hybrid Classical-Quantum Supercomputing: A demonstration of a multi-user, multi-QPU and multi-GPU environment. arXiv:2508.16297 [quant-ph]
-
[75]
W. Smith, I. Foster, and V. Taylor. 2000. Scheduling with advanced reservations. InProceedings 14th International Parallel and Distributed Processing Symposium. IPDPS 2000. 127–132. doi:10.1109/IPDPS.2000. 845974
-
[76]
Warren Smith, Valerie E. Taylor, and Ian T. Foster. 1999. Using Run- Time Predictions to Estimate Queue Wait Times and Improve Sched- uler Performance. InProceedings of the Job Scheduling Strategies for Parallel Processing (IPPS/SPDP ’99/JSSPP ’99). Springer-Verlag, Berlin, Heidelberg, 202–219. doi:10.1007/3-540-47954-6_11
-
[77]
Wei Tang, Teague Tomesh, Martin Suchara, Jeffrey Larson, and Mar- garet Martonosi. 2021. CutQC: Using Small Quantum Computers for Large Quantum Circuit Evaluations. InProceedings of the 26th ACM International Conference on Architectural Support for Program- ming Languages and Operating Systems. ACM, Virtual USA, 473–486. doi:10.1145/3445814.3446758
-
[78]
Xiaoyong Tang, Kenli Li, Guiping Liao, and Renfa Li. 2010. List schedul- ing with duplication for heterogeneous computing systems.J. Parallel and Distrib. Comput.70, 4 (2010), 323–329. doi:10.1016/j.jpdc.2010.01. 003
-
[79]
The Khronos Group. [n. d.]. OpenCL.https://www.khronos.org/ opencl/
-
[80]
H. Topcuoglu, S. Hariri, and Min-You Wu. 1999. Task scheduling algorithms for heterogeneous processors. InProceedings. Eighth Het- erogeneous Computing Workshop (HCW’99). 3–14. doi:10.1109/HCW. 1999.765092
work page doi:10.1109/hcw 1999
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.