Recognition: no theorem link
UniCreative: Unifying Long-form Logic and Short-form Sparkle via Reference-Free Reinforcement Learning
Pith reviewed 2026-05-10 18:49 UTC · model grok-4.3
The pith
A reference-free reinforcement learning system lets language models create their own quality rules for each writing task, unifying detailed planning in long stories with spontaneous expression in short texts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
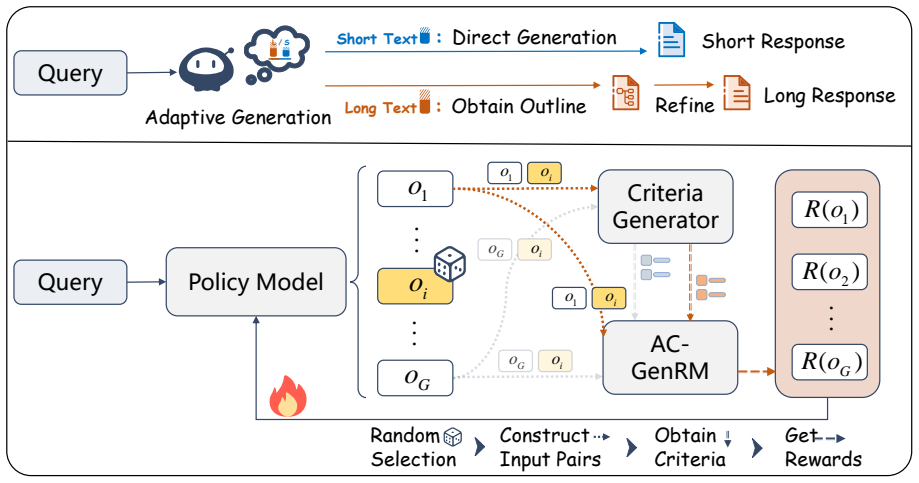
UniCreative introduces AC-GenRM, an adaptive constraint-aware reward model that dynamically synthesizes query-specific criteria to deliver fine-grained preference judgments, paired with ACPO, a policy optimization algorithm that aligns the model to human preferences on both content quality and structural demands without supervised fine-tuning or ground-truth references. Empirical tests show AC-GenRM matches expert judgments closely, ACPO raises performance across varied writing tasks, and the aligned model acquires an emergent meta-cognitive ability to distinguish tasks that require rigorous planning from those that favor direct generation.
What carries the argument
AC-GenRM, the adaptive constraint-aware reward model that invents task-specific evaluation criteria without references or supervised data to supply preference signals for policy optimization.
If this is right
- Models achieve measurable gains on both long-form coherence and short-form expressiveness using only preference signals.
- The same alignment process produces an internal ability to select planning versus direct generation according to task demands.
- Creative generation scales without the cost and scarcity of high-quality supervised datasets.
- A single policy optimization loop handles both content quality and structural format requirements.
Where Pith is reading between the lines
- The dynamic-criteria approach could transfer to other open-ended generation domains such as code or design where reference answers are scarce.
- If the meta-cognitive selection generalizes, it may reduce the need for separate planning modules in agent systems.
- Testing the method on multi-turn interactive writing would reveal whether the learned distinction between planning and direct output persists over extended interactions.
- The absence of fixed reward functions opens a route to continual self-alignment as new preference data arrives.
Load-bearing premise
The adaptive reward model can synthesize accurate, query-specific criteria that match human preferences without any supervised examples or ground-truth references.
What would settle it
Collect AC-GenRM judgments on a held-out set of long and short writing prompts, then have multiple independent expert raters score the same outputs; substantial systematic disagreement between the model-generated criteria and the experts would falsify the core mechanism.
Figures







read the original abstract
A fundamental challenge in creative writing lies in reconciling the inherent tension between maintaining global coherence in long-form narratives and preserving local expressiveness in short-form texts. While long-context generation necessitates explicit macroscopic planning, short-form creativity often demands spontaneous, constraint-free expression. Existing alignment paradigms, however, typically employ static reward signals and rely heavily on high-quality supervised data, which is costly and difficult to scale. To address this, we propose \textbf{UniCreative}, a unified reference-free reinforcement learning framework. We first introduce \textbf{AC-GenRM}, an adaptive constraint-aware reward model that dynamically synthesizes query-specific criteria to provide fine-grained preference judgments. Leveraging these signals, we propose \textbf{ACPO}, a policy optimization algorithm that aligns models with human preferences across both content quality and structural paradigms without supervised fine-tuning and ground-truth references. Empirical results demonstrate that AC-GenRM aligns closely with expert evaluations, while ACPO significantly enhances performance across diverse writing tasks. Crucially, our analysis reveals an emergent meta-cognitive ability: the model learns to autonomously differentiate between tasks requiring rigorous planning and those favoring direct generation, validating the effectiveness of our direct alignment approach.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes UniCreative, a reference-free reinforcement learning framework for creative writing that reconciles long-form coherence with short-form expressiveness. It introduces AC-GenRM, an adaptive constraint-aware reward model that dynamically synthesizes query-specific criteria for preference judgments without supervised data or references, and ACPO, a policy optimization algorithm. The authors claim empirical results showing close alignment of AC-GenRM with expert evaluations, significant performance gains across writing tasks via ACPO, and an emergent meta-cognitive ability in the model to differentiate planning-heavy tasks from direct generation.
Significance. If the central claims hold with rigorous validation, this could represent a meaningful advance in scalable, reference-free alignment for generative models, particularly by addressing the tension between structured long-form and spontaneous short-form creativity without costly supervised fine-tuning. The potential for emergent meta-cognition would be noteworthy if demonstrated through controlled experiments rather than post-hoc analysis.
major comments (3)
- [Abstract] Abstract: The claim that 'AC-GenRM aligns closely with expert evaluations' is presented without any quantitative metrics, correlation coefficients, baseline comparisons, ablation studies, or error analysis. This is load-bearing for the entire framework, as the adaptive synthesis of criteria must be shown to track human preferences on coherence vs. expressiveness to support the reported ACPO gains and meta-cognitive interpretation.
- [Abstract] Abstract: The assertion of an 'emergent meta-cognitive ability' where the model 'autonomously differentiate[s] between tasks requiring rigorous planning and those favoring direct generation' lacks any description of measurement protocol, controls, or statistical evidence. Without this, the observation risks being an unverified interpretation of policy behavior rather than a validated outcome of the direct alignment approach.
- [Abstract] Abstract (and implied methods): The reference-free AC-GenRM relies on on-the-fly criterion synthesis, yet no evidence is provided that these synthesized signals are more accurate or less circular than base LLM priors. The paper must demonstrate via human preference correlations or external validation that the adaptive component adds value beyond what a static reward model would achieve, as this underpins both the alignment claim and the avoidance of supervised data.
minor comments (1)
- [Abstract] Abstract: The phrase 'diverse writing tasks' is used without enumeration or categorization of the tasks (e.g., story continuation vs. poetry), which would clarify the scope of the claimed generalization.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below, referencing the full manuscript for supporting details where the abstract provides only a summary. We agree that the abstract presentation can be improved for clarity and will make targeted revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that 'AC-GenRM aligns closely with expert evaluations' is presented without any quantitative metrics, correlation coefficients, baseline comparisons, ablation studies, or error analysis. This is load-bearing for the entire framework, as the adaptive synthesis of criteria must be shown to track human preferences on coherence vs. expressiveness to support the reported ACPO gains and meta-cognitive interpretation.
Authors: The abstract is a concise summary of results; the full manuscript provides the requested quantitative support in the Experiments section (including Pearson correlations with expert judgments, baseline comparisons against static reward models, ablation studies on the adaptive criterion synthesis, and error analysis focused on coherence/expressiveness trade-offs). We agree the abstract would benefit from a brief reference to these metrics and will revise it to include summary statistics from our evaluations. revision: yes
-
Referee: [Abstract] Abstract: The assertion of an 'emergent meta-cognitive ability' where the model 'autonomously differentiate[s] between tasks requiring rigorous planning and those favoring direct generation' lacks any description of measurement protocol, controls, or statistical evidence. Without this, the observation risks being an unverified interpretation of policy behavior rather than a validated outcome of the direct alignment approach.
Authors: We acknowledge the abstract's brevity on this point. The full manuscript (Analysis section) details the measurement protocol, including controlled task prompting (planning-heavy vs. direct-generation tasks), behavioral metrics such as autonomous planning step generation, comparison controls against the base model, and statistical validation. We will revise the abstract to include a short description of this evaluation approach to clarify it is not merely post-hoc interpretation. revision: yes
-
Referee: [Abstract] Abstract (and implied methods): The reference-free AC-GenRM relies on on-the-fly criterion synthesis, yet no evidence is provided that these synthesized signals are more accurate or less circular than base LLM priors. The paper must demonstrate via human preference correlations or external validation that the adaptive component adds value beyond what a static reward model would achieve, as this underpins both the alignment claim and the avoidance of supervised data.
Authors: The manuscript includes direct comparisons and ablations in the Results section demonstrating that the adaptive on-the-fly synthesis improves human preference alignment over static LLM-based reward models (via win-rate evaluations and generalization tests on unseen constraints). These results address potential circularity by showing the adaptive component adds measurable value. We will revise the abstract to explicitly reference this empirical validation. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper introduces UniCreative as a reference-free RL framework using AC-GenRM to synthesize query-specific criteria and ACPO for policy optimization, claiming empirical alignment with expert evaluations and emergent meta-cognitive behavior. No equations, derivations, or self-referential constructions are present in the abstract or described claims that reduce any prediction or result to its inputs by construction. The adaptive synthesis step is presented as a design choice whose accuracy is asserted via external expert comparisons rather than internal fitting or renaming; self-citations are not invoked as load-bearing uniqueness theorems. The derivation chain remains self-contained against the stated benchmarks without the prohibited patterns.
Axiom & Free-Parameter Ledger
free parameters (1)
- query-specific constraint criteria
axioms (2)
- domain assumption Human preferences over creative text can be captured by on-the-fly synthesized criteria without ground-truth references
- domain assumption Reinforcement learning from these adaptive signals will improve both content quality and structural coherence
invented entities (2)
-
AC-GenRM
no independent evidence
-
ACPO
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Ruizhe Li, Chiwei Zhu, Benfeng Xu, Xiaorui Wang, and Zhendong Mao
Writing-zero: Bridge the gap between non- verifiable tasks and verifiable rewards.arXiv e-prints, pages arXiv–2506. Ruizhe Li, Chiwei Zhu, Benfeng Xu, Xiaorui Wang, and Zhendong Mao. 2025. Automated creativity evalu- ation for large language models: A reference-based approach.arXiv preprint arXiv:2504.15784. Jianxing Liao, Tian Zhang, Xiao Feng, Yusong Zh...
-
[2]
Generative reward models.arXiv preprint arXiv:2410.12832, 2024
Generative reward models.arXiv preprint arXiv:2410.12832. Moran Mizrahi, Chen Shani, Gabriel Stanovsky, Dan Jurafsky, and Dafna Shahaf. 2025. Cooking up cre- ativity: A cognitively-inspired approach for enhanc- ing llm creativity through structured representations. arXiv preprint arXiv:2504.20643. Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll ...
-
[3]
Spark: A system for scientifically creative idea generation.arXiv preprint arXiv:2504.20090, 2025
Direct preference optimization: Your language model is secretly a reward model.Advances in neural information processing systems, 36:53728–53741. Aishik Sanyal, Samuel Schapiro, Sumuk Shashidhar, Royce Moon, Lav R Varshney, and Dilek Hakkani- Tur. 2025. Spark: A system for scientifically creative idea generation.arXiv preprint arXiv:2504.20090. Chenglong ...
-
[4]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Uncle: Benchmarking uncertainty expressions in long-form generation. InProceedings of the 2025 Conference on Empirical Methods in Natural Lan- guage Processing, pages 30328–30344. Lili Yao, Nanyun Peng, Ralph Weischedel, Kevin Knight, Dongyan Zhao, and Rui Yan. 2019. Plan- and-write: Towards better automatic storytelling. In Proceedings of the AAAI Confer...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
decisive
Assessing and understanding creativity in large language models.Machine Intelligence Research, 22(3):417–436. A Appendix A.1 Training Configuration Our experiments are conducted on a computational cluster equipped with 8 × NVIDIA H800 (80GB) GPUs. The training pipeline consists of two se- quential stages: supervised fine-tuning for the re- ward model and ...
2025
-
[6]
Carefully read the Query, Response A, Response B, and all Evaluation Criteria
-
[7]
For each criterion, mentally compare A and B, referencing the scoring rubrics to decide which is superior
-
[8]
winner":
After analyzing all criteria, synthesize your findings to determine the overall winner. Your decision must be definitive. **Your Final Output:** After completing your internal analysis, you must output ONLY the final winner in the specified JSON format. Do not include any other keys, text, explanations, or justifications. **Query:** {query} **Response A:*...
-
[9]
Then, generate the main content
**Structure**: First, generate a structured outline enclosed within `<|plan|>` and `<|end_plan|>` tags. Then, generate the main content
-
[10]
Do not deviate from the plan or omit key events
**Plan Adherence**: The main content **MUST strictly follow** the plot points, arguments, and logic defined in your `<|plan|>`. Do not deviate from the plan or omit key events
-
[11]
at least 800 words
**Length Constraint**: If the user specifies a word/character count (e.g., "at least 800 words"), the final output MUST meet this requirement. - **Format Example**: <|plan|>
-
[12]
<|end_plan|> (Main content starts here, strictly following the plan...) ### 3
Development... <|end_plan|> (Main content starts here, strictly following the plan...) ### 3. Short-Form Mode: Direct Generation - **Applicable Scenarios**: Greetings, mottos, social media captions, slogans, short poems, or requests for **brief text**. - **Mandatory Requirements**:
-
[13]
**No Plan**: It is **STRICTLY FORBIDDEN** to generate any `<|plan|>` tags
-
[14]
**One Sentence**: The output must be strictly limited to **ONE single sentence** unless the user explicitly asks for a couplet or specific short format
-
[15]
under 10 words
**Length Constraint**: If the user specifies a length limit (e.g., "under 10 words", "within 20 characters"), strictly obey it while maintaining the one-sentence rule
-
[16]
A time traveler regretting changing history
**Impact**: Focus on wit, conciseness, and emotional impact. --- ### Few-Shot Examples **User:** 写⼀句关于 “ 坚持 ” 的励志短句,适合做座右铭,不超过 15 个字。 **Assistant:** 星光不问赶路⼈,时光不负有⼼⼈。 **User:** Write a concise slogan for a coffee brand (under 10 words). **Assistant:** Wake up to life, one sip at a time. **User:** Write a sci-fi story outline and content about "A time trave...
-
[17]
Protagonist uses a device to go back 10 years to stop a car accident
-
[18]
The accident is prevented, but the butterfly effect causes his best friend never to be born
-
[19]
<|end_plan|> When the humming of the machine stopped, Li Ming's hands were still trembling
Protagonist faces a dilemma and finally destroys the device, accepting the regret. <|end_plan|> When the humming of the machine stopped, Li Ming's hands were still trembling. He rushed out of the lab and saw the familiar street from ten years ago... --- **Query** {query} Figure 9: Prompt for the Generate
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.