Recognition: 2 theorem links
· Lean TheoremCrowdVLA: Embodied Vision-Language-Action Agents for Context-Aware Crowd Simulation
Pith reviewed 2026-05-10 18:50 UTC · model grok-4.3
The pith
CrowdVLA turns each simulated pedestrian into a vision-language-action agent that reads scene meaning and reasons about consequences before choosing how to move.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
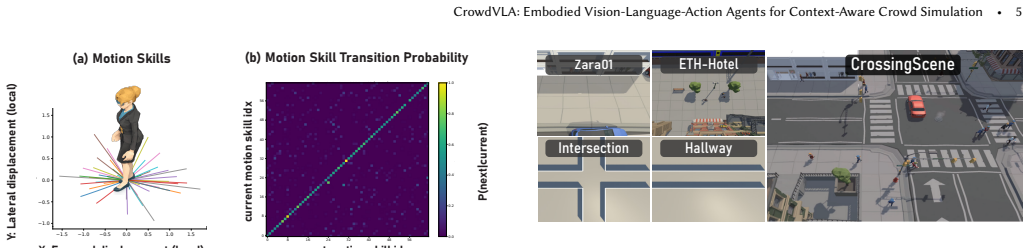
CrowdVLA formulates crowd simulation by equipping each agent with a Vision-Language-Action model that interprets scene semantics and social norms from visual observations and language instructions, then selects actions through consequence-aware reasoning within a motion skill action space, trained via LoRA fine-tuning on semantically reconstructed environments and exploration-based question answering to overcome limited agent-centric supervision, per-frame instability, and success-biased datasets.
What carries the argument
The Vision-Language-Action (VLA) agent, which processes visual observations and language instructions to perform consequence-aware action selection bridged to continuous locomotion via a motion skill space.
If this is right
- Crowd movements become responsive to high-level language instructions about urgency, safety, or social norms rather than fixed trajectories.
- Agents can weigh counterfactual outcomes during training, leading to more robust decision making in dynamic or uncertain environments.
- Simulation pipelines can generate diverse, contextually varied behaviors from the same base environment without collecting new motion capture data.
- The separation of symbolic reasoning from low-level locomotion allows easier integration of new skills or norms without retraining entire motion models.
Where Pith is reading between the lines
- The same VLA structure could be tested in non-crowd domains such as traffic simulation or multi-robot coordination where agents must interpret shared visual scenes and rules.
- If the consequence-aware reasoning holds, these agents might serve as synthetic data generators to improve real-world pedestrian prediction models used in autonomous vehicles.
- Physical robot experiments in controlled public spaces could check whether the learned reasoning transfers beyond simulation rollouts.
Load-bearing premise
Fine-tuning a pretrained vision-language model with LoRA on semantically reconstructed environments, paired with a motion skill action space and exploration-based question answering, produces stable human-like contextual reasoning without per-frame instability or success bias.
What would settle it
Running the trained agents in new crowd scenes and observing persistent per-frame control instability or repeated selection of context-inappropriate actions that ignore social norms or consequences would falsify the central claim.
Figures







read the original abstract
Crowds do not merely move; they decide. Human navigation is inherently contextual: people interpret the meaning of space, social norms, and potential consequences before acting. Sidewalks invite walking, crosswalks invite crossing, and deviations are weighed against urgency and safety. Yet most crowd simulation methods reduce navigation to geometry and collision avoidance, producing motion that is plausible but rarely intentional. We introduce CrowdVLA, a new formulation of crowd simulation that models each pedestrian as a Vision-Language-Action (VLA) agent. Instead of replaying recorded trajectories, CrowdVLA enables agents to interpret scene semantics and social norms from visual observations and language instructions, and to select actions through consequence-aware reasoning. CrowdVLA addresses three key challenges-limited agent-centric supervision in crowd datasets, unstable per-frame control, and success-biased datasets-through: (i) agent-centric visual supervision via semantically reconstructed environments and Low-Rank Adaptation (LoRA) fine-tuning of a pretrained vision-language model, (ii) a motion skill action space that bridges symbolic decision making and continuous locomotion, and (iii) exploration-based question answering that exposes agents to counterfactual actions and their outcomes through simulation rollouts. Our results shift crowd simulation from motion-centric synthesis toward perception-driven, consequence-aware decision making, enabling crowds that move not just realistically, but meaningfully.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CrowdVLA, a formulation of crowd simulation in which each pedestrian is an embodied Vision-Language-Action (VLA) agent. Agents interpret visual observations and language instructions to extract scene semantics and social norms, then choose actions via consequence-aware reasoning rather than replaying trajectories or applying geometric rules. Three technical contributions are described: (i) agent-centric visual supervision obtained by semantically reconstructing environments and applying LoRA fine-tuning to a pretrained vision-language model, (ii) a motion-skill action space that discretizes high-level decisions while retaining continuous locomotion, and (iii) exploration-based question answering that generates counterfactual rollouts inside the simulator to expose agents to action outcomes. The central claim is that these components shift crowd simulation from motion-centric synthesis to perception-driven, consequence-aware decision making.
Significance. If the proposed VLA agents can be shown to produce stable, human-like contextual reasoning and to avoid the per-frame instability and success bias noted in the abstract, the work would constitute a meaningful advance in crowd simulation. It would demonstrate a practical route for injecting pretrained vision-language models into simulation pipelines and for using exploration-based training to instill sensitivity to social norms and urgency. Such a shift could improve downstream applications in robotics, urban planning, and virtual environments where purely geometric models fall short.
major comments (2)
- [Abstract] Abstract: The manuscript states three technical contributions and asserts that the resulting agents perform 'consequence-aware reasoning' and produce 'meaningful' crowd behavior, yet supplies no quantitative results, baselines, success rates, error analysis, or validation experiments. Without such evidence it is impossible to determine whether any of the three components actually support the central claim.
- [Abstract] Abstract (exploration-based QA): The description indicates that counterfactual rollouts occur inside the same semantically reconstructed environments and motion-skill simulator used to generate the LoRA fine-tuning data. Because these rollouts therefore remain within the training distribution, it is unclear whether the procedure can enforce genuine out-of-distribution reasoning about norm violations or safety consequences, as opposed to simply learning simulator-consistent behavior.
minor comments (1)
- [Abstract] Abstract: The sentence 'Our results shift crowd simulation...' presupposes empirical findings that are not presented or quantified in the abstract.
Simulated Author's Rebuttal
We thank the referee for the insightful comments and for recognizing the potential of CrowdVLA to advance crowd simulation through perception-driven, consequence-aware agents. We address each major comment below with clarifications drawn from the full manuscript and indicate where revisions will be made.
read point-by-point responses
-
Referee: [Abstract] Abstract: The manuscript states three technical contributions and asserts that the resulting agents perform 'consequence-aware reasoning' and produce 'meaningful' crowd behavior, yet supplies no quantitative results, baselines, success rates, error analysis, or validation experiments. Without such evidence it is impossible to determine whether any of the three components actually support the central claim.
Authors: We agree that the abstract would be strengthened by explicitly summarizing quantitative evidence. The full manuscript reports experimental results in the Evaluation section, including direct comparisons to geometric and trajectory-replay baselines, metrics on per-frame stability and collision avoidance, task success rates across semantic scenarios, and analyses of norm adherence via simulated outcomes. We will revise the abstract to include key figures (e.g., improved human-likeness scores and reduced instability) so that the claims are supported at the outset. revision: yes
-
Referee: [Abstract] Abstract (exploration-based QA): The description indicates that counterfactual rollouts occur inside the same semantically reconstructed environments and motion-skill simulator used to generate the LoRA fine-tuning data. Because these rollouts therefore remain within the training distribution, it is unclear whether the procedure can enforce genuine out-of-distribution reasoning about norm violations or safety consequences, as opposed to simply learning simulator-consistent behavior.
Authors: We acknowledge the concern that shared environments limit the degree of distribution shift. While base scenes are reconstructed from the same sources, the exploration procedure generates novel action sequences and their simulated consequences (including norm-violating or unsafe trajectories absent from the original fine-tuning data). This supplies consequence signals that encourage reasoning beyond replay. We will add a dedicated paragraph in the Method and Discussion sections that quantifies the induced shift in action-outcome pairs and notes remaining limitations regarding fully novel environments. revision: partial
Circularity Check
No circularity: methodological pipeline is self-contained
full rationale
The paper introduces CrowdVLA as a new VLA-based crowd simulation framework relying on external pretrained vision-language models, LoRA fine-tuning, a custom motion skill action space, and exploration-based QA rollouts. No equations, derivations, or parameter-fitting steps are described that reduce by construction to the inputs or to self-citations. The central claims rest on the proposed training procedures and architecture rather than any self-referential normalization, uniqueness theorem, or renamed empirical pattern.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
models each pedestrian as a Vision-Language-Action (VLA) agent... motion skill action space... exploration-based question answering that exposes agents to counterfactual actions
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
shift crowd simulation from motion-centric synthesis toward perception-driven, consequence-aware decision making
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xiong-Hui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Rongyao Fang, Chang Gao, Chunjiang Ge, Wenbin Ge, Zhifang Guo, Qidong Huang, Jie Huang, Fei Huang, Binyuan Hui, Shutong Jiang, Zhaohai Li, Mingsheng Li, Mei Li, Kaixin Li, Zicheng Lin, Junyang Lin, Xuejing Liu, Jiawei Liu, Chenglong Liu, Yang Liu, Dayihen...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Peng Chen, Pi Bu, Yingyao Wang, Xinyi Wang, Ziming Wang, Jie Guo, Yingxiu Zhao, Qi Zhu, Jun Song, Siran Yang, et al
Greil-crowds: Crowd simulation with deep reinforcement learning and examples.ACM Transactions on Graphics (TOG)42, 4 (2023), 1–15. Peng Chen, Pi Bu, Yingyao Wang, Xinyi Wang, Ziming Wang, Jie Guo, Yingxiu Zhao, Qi Zhu, Jun Song, Siran Yang, et al
2023
-
[3]
doi:10.48550/arXiv.2503.09527 , author =
Combatvla: An efficient vision-language- action model for combat tasks in 3d action role-playing games.arXiv preprint arXiv:2503.09527(2025). Shaoyu Chen, Bo Jiang, Hao Gao, Bencheng Liao, Qing Xu, Qian Zhang, Chang Huang, Wenyu Liu, and Xinggang Wang
-
[4]
VADv2: End-to-End Vectorized Autonomous Driving via Probabilistic Planning
Vadv2: End-to-end vectorized autonomous driving via probabilistic planning.arXiv preprint arXiv:2402.13243(2024). Zane Durante, Ran Gong, Bidipta Sarkar, Naoki Wake, Rohan Taori, Paul Tang, Shrinidhi Lakshmikanth, Kevin Schulman, Arnold Milstein, Hoi Vo, et al
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
InProceedings of the 2009 ACM SIGGRAPH/Eurographics Symposium on Computer Animation
Clearpath: highly parallel collision avoidance for multi-agent simulation. InProceedings of the 2009 ACM SIGGRAPH/Eurographics Symposium on Computer Animation. 177–187. Stephen J Guy, Sujeong Kim, Ming C Lin, and Dinesh Manocha
2009
-
[6]
InProceedings of the 2011 ACM SIGGRAPH/Eurographics symposium on computer animation
Simulating heterogeneous crowd behaviors using personality trait theory. InProceedings of the 2011 ACM SIGGRAPH/Eurographics symposium on computer animation. 43–52. Dirk Helbing and Peter Molnar
2011
-
[7]
Physical review E51, 5 (1995),
Social force model for pedestrian dynamics. Physical review E51, 5 (1995),
1995
-
[8]
Lora: Low-rank adaptation of large language models.ICLR1, 2 (2022),
2022
-
[9]
Xuebo Ji, Zherong Pan, Xifeng Gao, and Jia Pan
Heterogeneous crowd simulation using parametric reinforcement learning.IEEE Transactions on Visualization and Computer Graphics 29, 4 (2021), 2036–2052. Xuebo Ji, Zherong Pan, Xifeng Gao, and Jia Pan
2021
-
[10]
InACM SIGGRAPH 2024 Conference Papers
Text-guided synthesis of crowd animation. InACM SIGGRAPH 2024 Conference Papers. 1–11. Hao Jiang, Wenbin Xu, Tianlu Mao, Chunpeng Li, Shihong Xia, and Zhaoqi Wang
2024
-
[11]
Mubbasir Kapadia, Alejandro Beacco, Francisco Garcia, Vivek Reddy, Nuria Pelechano, and Norman I Badler
Continuum crowd simulation in complex environments.Computers & Graphics34, 5 (2010), 537–544. Mubbasir Kapadia, Alejandro Beacco, Francisco Garcia, Vivek Reddy, Nuria Pelechano, and Norman I Badler
2010
-
[12]
Fine-Tuning Vision-Language-Action Models: Optimizing Speed and Success
Fine-tuning vision-language-action models: Optimizing speed and success.arXiv preprint arXiv:2502.19645(2025). Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanketi, et al
work page internal anchor Pith review arXiv 2025
-
[13]
OpenVLA: An Open-Source Vision-Language-Action Model
Openvla: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246 (2024). Jaedong Lee, Jungdam Won, and Jehee Lee
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
InProceedings of the 2007 ACM SIGGRAPH/Eurographics symposium on Computer animation
Group behavior from video: a data-driven approach to crowd simulation. InProceedings of the 2007 ACM SIGGRAPH/Eurographics symposium on Computer animation. 109–118. Alon Lerner, Yiorgos Chrysanthou, and Dani Lischinski
2007
-
[15]
End-to-end driving with online trajectory evaluation via bev world model.arXiv preprint arXiv:2504.01941(2025). Zhenxin Li, Kailin Li, Shihao Wang, Shiyi Lan, Zhiding Yu, Yishen Ji, Zhiqi Li, Ziyue Zhu, Jan Kautz, Zuxuan Wu, et al
-
[16]
Hydra-MDP: End-to-end Multimodal Planning with Multi-target Hydra-Distillation
Hydra-mdp: End-to-end multimodal planning with multi-target hydra-distillation.arXiv preprint arXiv:2406.06978(2024). Jan Ondřej, Julien Pettré, Anne-Hélène Olivier, and Stéphane Donikian
work page internal anchor Pith review arXiv 2024
-
[17]
Andreas Panayiotou, Theodoros Kyriakou, Marilena Lemonari, Yiorgos Chrysanthou, and Panayiotis Charalambous
A synthetic-vision based steering approach for crowd simulation.ACM Transactions on Graphics (TOG)29, 4 (2010), 1–9. Andreas Panayiotou, Theodoros Kyriakou, Marilena Lemonari, Yiorgos Chrysanthou, and Panayiotis Charalambous
2010
-
[18]
InACM SIGGRAPH 2022 conference proceedings
Ccp: Configurable crowd profiles. InACM SIGGRAPH 2022 conference proceedings. 1–10. Stefano Pellegrini, Andreas Ess, Konrad Schindler, and Luc Van Gool
2022
-
[19]
Alexandre Robicquet, Amir Sadeghian, Alexandre Alahi, and Silvio Savarese
Modeling group structures in pedestrian crowd simulation.Simulation Modelling Practice and Theory18, 2 (2010), 190–205. Alexandre Robicquet, Amir Sadeghian, Alexandre Alahi, and Silvio Savarese
2010
-
[20]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Llama 2: Open foundation and fine-tuned chat models.arXiv preprint arXiv:2307.09288(2023). Jur Van den Berg, Ming Lin, and Dinesh Manocha
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[21]
In2008 IEEE international conference on robotics and automation
Reciprocal velocity obstacles for real-time multi-agent navigation. In2008 IEEE international conference on robotics and automation. Ieee, 1928–1935. Xiang Wei, Wei Lu, Lili Zhu, and Weiwei Xing
1928
-
[22]
Learning motion rules from real data: Neural network for crowd simulation.Neurocomputing310 (2018), 125–134. , Vol. 1, No. 1, Article . Publication date: April
2018
-
[23]
Zewei Zhou, Tianhui Cai, Seth Z Zhao, Yun Zhang, Zhiyu Huang, Bolei Zhou, and Jiaqi Ma
Improved multi-agent deep deterministic policy gradient for path planning-based crowd simulation.Ieee Access7 (2019), 147755– 147770. Zewei Zhou, Tianhui Cai, Seth Z Zhao, Yun Zhang, Zhiyu Huang, Bolei Zhou, and Jiaqi Ma
2019
-
[24]
AutoVLA: A Vision-Language-Action Model for End-to-End Autonomous Driving with Adaptive Reasoning and Reinforcement Fine-Tuning.arXiv preprint arXiv:2506.13757(2025). Brianna Zitkovich, Tianhe Yu, Sichun Xu, Peng Xu, Ted Xiao, Fei Xia, Jialin Wu, Paul Wohlhart, Stefan Welker, Ayzaan Wahid, et al
work page internal anchor Pith review arXiv 2025
-
[25]
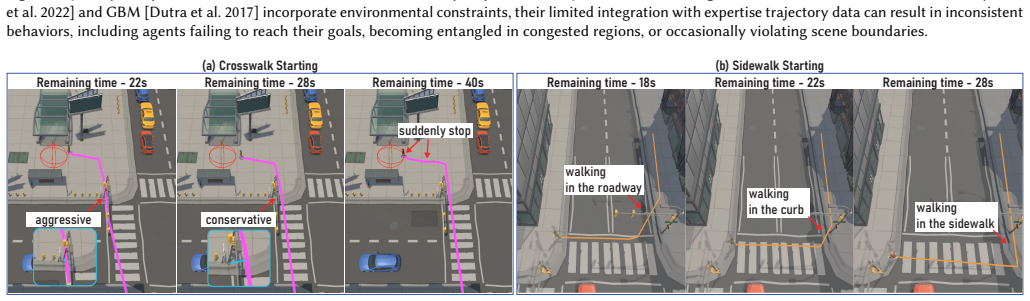
We compare pedestrian trajectories when nine agents cross in each scene
Trajectory Comparison in Hall and Intersection scenes. We compare pedestrian trajectories when nine agents cross in each scene. While CCP [Panayiotou et al. 2022] and GBM [Dutra et al. 2017] incorporate environmental constraints, their limited integration with expertise trajectory data can result in inconsistent behaviors, including agents failing to reac...
2022
-
[26]
Each column shows the agent’s trajectory (top) and corresponding third-person observations at selected timesteps (bottom)
Qualitative stress-test results across unseen environments with similar start–goal configurations. Each column shows the agent’s trajectory (top) and corresponding third-person observations at selected timesteps (bottom). Despite the similar start and goal locations, agents adapt their behavior to scene-specific context, including indoor entrances, crossw...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.