Recognition: 3 theorem links
· Lean TheoremSignalClaw: LLM-Guided Evolutionary Synthesis of Interpretable Traffic Signal Control Skills
Pith reviewed 2026-05-10 20:10 UTC · model grok-4.3
The pith
Large language models evolve human-readable traffic signal rules that match or beat standard methods while handling emergencies.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
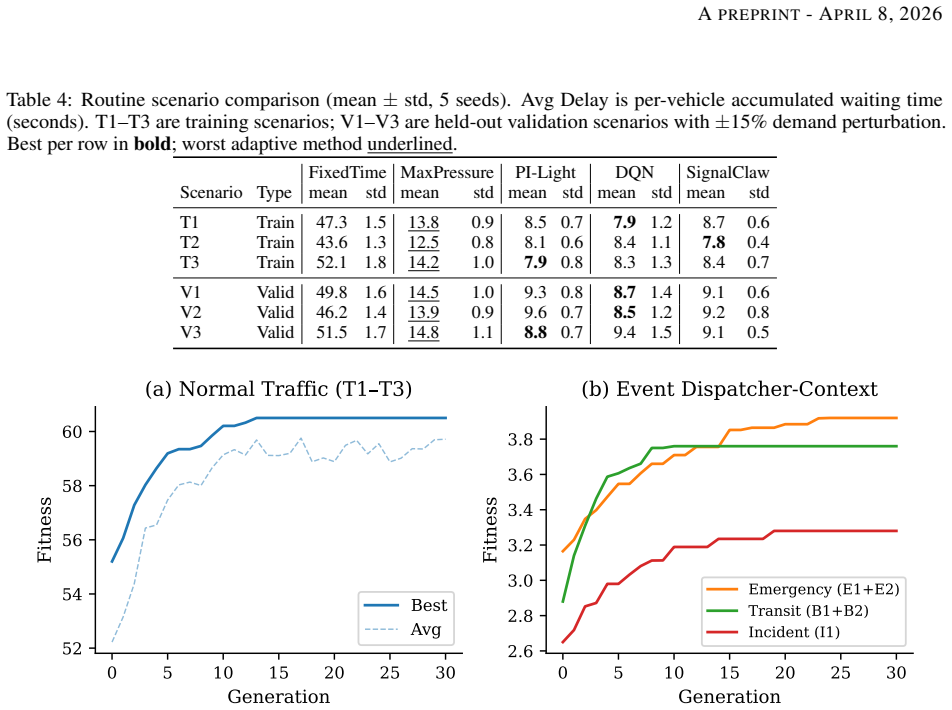
SignalClaw uses LLMs to synthesize and evolve interpretable control skills for traffic signals. Skills are refined across generations by converting simulation metrics into language feedback. An event-driven dispatcher identifies scenarios such as emergency vehicles or transit priority and selects or chains specialized skills. In SUMO tests on routine traffic the method reaches average delays of 7.8 to 9.2 seconds, within 3 to 10 percent of the best baseline. Under injected events it records the lowest emergency-vehicle delay of 11.2 to 18.5 seconds and the lowest transit-person delay of 9.8 to 11.5 seconds, while the composed skills remain fully inspectable and modifiable.
What carries the argument
LLM-guided evolutionary skill synthesis that produces self-documenting skills (rationale plus code) and composes them at runtime via an event detector and priority dispatcher.
If this is right
- Skills advance from simple linear rules to conditional multi-feature logic while staying readable.
- The dispatcher keeps overall delay stable when multiple event types occur at once.
- No retraining is needed when new event types are added; only the relevant skill evolves.
- Low variance across random seeds indicates the evolutionary process is repeatable.
- Traffic engineers can directly edit the generated code and rationales for local conditions.
Where Pith is reading between the lines
- The same loop could let cities adapt signal plans quickly when road layouts change without hiring ML specialists.
- Because each skill carries its own rationale, regulators could require human sign-off on every skill before use.
- Extending the event detector to include weather or construction data would test whether the compositional approach scales beyond the current four event types.
- The method might generalize to other networked control problems such as ramp metering or dynamic lane assignment.
Load-bearing premise
Skills created and tested only inside traffic simulators will remain safe and effective when placed in real streets without introducing dangerous edge-case behavior.
What would settle it
Running the final evolved skills on a physical intersection or high-fidelity real-world trace and checking whether emergency delays stay below 20 seconds and no unsafe phase sequences appear.
Figures


read the original abstract
Traffic signal control TSC requires strategies that are both effective and interpretable for deployment, yet reinforcement learning produces opaque neural policies while program synthesis depends on restrictive domain-specific languages. We present SIGNALCLAW, a framework that uses large language models LLMs as evolutionary skill generators to synthesize and refine interpretable control skills for adaptive TSC. Each skill includes rationale, selection guidance, and executable code, making policies human-inspectable and self-documenting. At each generation, evolution signals from simulation metrics such as queue percentiles, delay trends, and stagnation are translated into natural language feedback to guide improvement. SignalClaw also introduces event-driven compositional evolution: an event detector identifies emergency vehicles, transit priority, incidents, and congestion via TraCI, and a priority dispatcher selects specialized skills. Each skill is evolved independently, and a priority chain enables runtime composition without retraining. We evaluate SignalClaw on routine and event-injected SUMO scenarios against four baselines. On routine scenarios, it achieves average delay of 7.8 to 9.2 seconds, within 3 to 10 percent of the best method, with low variance across random seeds. Under event scenarios, it yields the lowest emergency delay 11.2 to 18.5 seconds versus 42.3 to 72.3 for MaxPressure and 78.5 to 95.3 for DQN, and the lowest transit person delay 9.8 to 11.5 seconds versus 38.7 to 45.2 for MaxPressure. In mixed events, the dispatcher composes skills effectively while maintaining stable overall delay. The evolved skills progress from simple linear rules to conditional strategies with multi-feature interactions, while remaining fully interpretable and directly modifiable by traffic engineers.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents SignalClaw, a framework that employs LLMs as evolutionary generators to synthesize and iteratively refine interpretable traffic signal control skills (each including rationale, selection guidance, and executable code) for adaptive TSC in SUMO simulations. It incorporates event-driven compositional evolution via a TraCI-based event detector and priority dispatcher that selects among independently evolved skills for emergencies, transit priority, incidents, and congestion. On routine scenarios, SignalClaw reports average delays of 7.8–9.2 seconds (within 3–10% of the best baseline) with low variance; under event scenarios, it claims the lowest emergency delays (11.2–18.5 s vs. 42.3–72.3 s for MaxPressure and 78.5–95.3 s for DQN) and transit person delays (9.8–11.5 s vs. 38.7–45.2 s for MaxPressure), with effective skill composition in mixed events.
Significance. If the performance claims hold after proper isolation of components, the work would demonstrate a viable path to interpretable, composable policies that combine the adaptability of evolutionary search with LLM-driven natural-language feedback, addressing the opacity of RL policies and the rigidity of traditional program synthesis in TSC. Strengths include the use of simulation-derived metrics (queue percentiles, delay trends) for evolutionary signals, independent per-skill evolution, and runtime priority chaining without retraining. These elements could support falsifiable predictions about skill transfer and human modifiability.
major comments (2)
- [Experiments / Evaluation] Experiments section (performance tables and event-scenario results): the headline gains (emergency delay 11.2–18.5 s, transit 9.8–11.5 s) are produced by the full pipeline including event detector + priority dispatcher; the manuscript does not state that the four baselines (MaxPressure, DQN, etc.) received equivalent event detection and dispatching logic. Without an ablation that fixes the dispatcher and varies only skill source (LLM-evolved vs. hand-crafted vs. none), the central claim that LLM-guided evolutionary synthesis produces the superior interpretable policies is not isolated from the compositional dispatcher.
- [Experiments] Evaluation subsection on routine and event scenarios: concrete delay numbers and variance claims are reported, yet the text supplies no information on run counts per scenario, random seeds, statistical tests (e.g., t-tests or confidence intervals), or hyperparameter sensitivity for the evolutionary process and LLM prompts. This prevents verification of the low-variance and superiority assertions.
minor comments (2)
- [Method] The description of how evolved skills are executed at runtime (via TraCI) and how the priority chain resolves conflicts could be clarified with a short pseudocode or diagram in the method section.
- [Introduction / Related Work] Missing references to prior LLM-based code synthesis or evolutionary program synthesis work in traffic control; adding 2–3 targeted citations would better situate the contribution.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments, which identify key areas for strengthening the experimental isolation and reproducibility of our results. We address each major comment below and will incorporate the suggested revisions to better support the central claims of the paper.
read point-by-point responses
-
Referee: [Experiments / Evaluation] Experiments section (performance tables and event-scenario results): the headline gains (emergency delay 11.2–18.5 s, transit 9.8–11.5 s) are produced by the full pipeline including event detector + priority dispatcher; the manuscript does not state that the four baselines (MaxPressure, DQN, etc.) received equivalent event detection and dispatching logic. Without an ablation that fixes the dispatcher and varies only skill source (LLM-evolved vs. hand-crafted vs. none), the central claim that LLM-guided evolutionary synthesis produces the superior interpretable policies is not isolated from the compositional dispatcher.
Authors: We agree that the current evaluation does not fully isolate the contribution of the LLM-guided evolutionary synthesis from the event detector and priority dispatcher. To address this directly, we will add a new ablation study to the revised manuscript. In this study, the event detector and priority dispatcher will be held fixed across all conditions, while varying only the source of the control skills: (1) the LLM-evolved skills from SignalClaw, (2) equivalent hand-crafted interpretable skills written by domain experts, and (3) a no-skill baseline relying on default SUMO controllers. This design will enable a controlled comparison of skill quality independent of the compositional mechanism, thereby strengthening evidence for the value of the evolutionary synthesis process. revision: yes
-
Referee: [Experiments] Evaluation subsection on routine and event scenarios: concrete delay numbers and variance claims are reported, yet the text supplies no information on run counts per scenario, random seeds, statistical tests (e.g., t-tests or confidence intervals), or hyperparameter sensitivity for the evolutionary process and LLM prompts. This prevents verification of the low-variance and superiority assertions.
Authors: We acknowledge that the manuscript lacks sufficient detail on experimental protocol to allow independent verification of the low-variance claims and performance differences. In the revision, we will expand the Experiments section and add an appendix with the following: the number of independent runs per scenario (10 runs), the specific random seeds used for SUMO traffic generation and simulation stochasticity, full statistical reporting including means, standard deviations, and 95% confidence intervals for all delay metrics, and results of paired t-tests assessing significance against baselines. We will also report a sensitivity analysis covering key evolutionary hyperparameters (population size, generations, mutation rate) and LLM prompt variations (temperature, feedback phrasing) to demonstrate robustness of the reported outcomes. revision: yes
Circularity Check
No circularity: empirical evaluation against external baselines
full rationale
The paper describes an LLM-guided evolutionary framework for synthesizing interpretable traffic signal control skills, with performance measured directly via SUMO simulations on routine and event-injected scenarios. Results (e.g., delay metrics) are reported as outcomes of independent runs compared to external baselines (MaxPressure, DQN) without any equations, fitted parameters, or predictions that reduce to internal definitions or self-citations. No derivation chain exists that could be tautological; the central claims rest on observable simulation outputs rather than self-referential constructions.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearSignalClaw uses LLMs as evolutionary skill generators... event detection module identifies... priority dispatcher selects... fitness f(σ) = C − (wd·d̄ + wq·q̄) + wt·t̄
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclearpriority chain (emergency > incident > transit > congestion > normal)
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclearevolution signals... high_queue, low_throughput, force_innovation
Reference graph
Works this paper leans on
-
[1]
Hua Wei, Guanjie Zheng, Huaxiu Yao, and Zhenhui Li. IntelliLight : A reinforcement learning approach for intelligent traffic light control. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, pages 2496--2505. ACM, 2018. doi:10.1145/3219819.3220096
-
[2]
CoLight : Learning network-level cooperation for traffic signal control
Guanjie Zheng, Yuanhao Xiong, Xinshi Zang, Jie Feng, Hua Wei, Huichu Zhang, Yong Li, Kai Xu, and Zhenhui Li. Learning phase competition for traffic signal control. In Proceedings of the 28th ACM International Conference on Information and Knowledge Management (CIKM), pages 1963--1972. ACM, 2019 a . doi:10.1145/3357384.3357900
-
[3]
PressLight : Learning max pressure control to coordinate traffic signals in arterial network
Hua Wei, Chacha Chen, Guanjie Zheng, Kan Wu, Vikash Gayah, Kai Xu, and Zhenhui Li. PressLight : Learning max pressure control to coordinate traffic signals in arterial network. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, pages 1290--1298. ACM, 2019 a . doi:10.1145/3292500.3330949
-
[4]
Yin Gu, Kai Zhang, Qi Liu, Weibo Gao, Longfei Li, and Jun Zhou. -Light : Programmatic interpretable reinforcement learning for resource-limited traffic signal control. In Proceedings of the AAAI Conference on Artificial Intelligence, pages 21107--21115. AAAI Press, 2024. doi:10.1609/aaai.v38i19.30103
-
[5]
Mathematical discoveries from program search with large language models
Bernardino Romera-Paredes, Mohammadamin Barekatain, Alexander Novikov, Matej Balog, M. Pawan Kumar, Emilien Dupont, Francisco J. R. Ruiz, Jordan S. Ellenberg, Pengming Wang, Omar Fawzi, Pushmeet Kohli, and Alhussein Fawzi. Mathematical discoveries from program search with large language models. Nature, 625 0 (7995): 0 468--475, 2024. doi:10.1038/s41586-02...
-
[6]
Alexander Novikov, Ng \^a n V \ u , Marvin Eisenberger, Emilien Dupont, Po-Sen Huang, Adam Zsolt Wagner, Sergey Shirobokov, Borislav Kozlovskii, Francisco J. R. Ruiz, Abbas Mehrabian, M. Pawan Kumar, Abigail See, et al. AlphaEvolve : A coding agent for scientific and algorithmic discovery. arXiv preprint arXiv:2506.13131, 2025
work page internal anchor Pith review arXiv 2025
-
[7]
Self-improving language models for evolutionary program synthesis: A case study on ARC - AGI
Julien Pourcel, C \'e dric Colas, and Pierre-Yves Oudeyer. Self-improving language models for evolutionary program synthesis: A case study on ARC - AGI . arXiv preprint arXiv:2507.14172, 2025
-
[8]
CoLight : Learning network-level cooperation for traffic signal control
Hua Wei, Nan Xu, Huichu Zhang, Guanjie Zheng, Xinshi Zang, Chacha Chen, Weinan Zhang, Yanmin Zhu, Kai Xu, and Zhenhui Li. CoLight : Learning network-level cooperation for traffic signal control. In Proceedings of the 28th ACM International Conference on Information and Knowledge Management (CIKM), pages 1913--1922. ACM, 2019 b . doi:10.1145/3357384.3357902
-
[9]
Chacha Chen, Hua Wei, Nan Xu, Guanjie Zheng, Ming Yang, Yuanhao Xiong, Kai Xu, and Zhenhui Li. Toward a thousand lights: Decentralized deep reinforcement learning for large-scale traffic signal control. In Proceedings of the 34th AAAI Conference on Artificial Intelligence (AAAI), pages 3414--3421. AAAI Press, 2020. doi:10.1609/aaai.v34i04.5744
-
[10]
FRAP : Learning phase competition for traffic signal control
Guanjie Zheng, Xinshi Zang, Nan Xu, Hua Wei, Zhengyao Yu, Vikash Gayah, Kai Xu, and Zhenhui Li. FRAP : Learning phase competition for traffic signal control. In Proceedings of the 28th ACM International Conference on Information and Knowledge Management (CIKM), pages 1963--1972. ACM, 2019 b
1963
-
[11]
MetaLight : Value-based meta-reinforcement learning for traffic signal control
Xinshi Zang, Huaxiu Yao, Guanjie Zheng, Nan Xu, Kai Xu, and Zhenhui Li. MetaLight : Value-based meta-reinforcement learning for traffic signal control. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 34, pages 1153--1160, 2020
2020
-
[12]
Verifiable reinforcement learning via policy extraction
Osbert Bastani, Yewen Pu, and Armando Solar-Lezama. Verifiable reinforcement learning via policy extraction. In Advances in Neural Information Processing Systems (NeurIPS), volume 31, 2018
2018
-
[13]
Siqi Lai, Zhao Xu, Weijia Zhang, Hao Liu, and Hui Xiong. LLMLight : Large language models as traffic signal control agents. arXiv preprint arXiv:2312.16044, 2023
-
[14]
Traffic-r1: Reinforced llms bring human-like reasoning to traffic signal control systems,
Xingchen Zou, Yuhao Yang, Zheng Chen, Xixuan Hao, Yiqi Chen, Chao Huang, and Yuxuan Liang. Traffic-R1 : Reinforced LLM s bring human-like reasoning to traffic signal control systems. arXiv preprint arXiv:2508.02344, 2025
-
[15]
SymLight : Exploring interpretable and deployable symbolic policies for traffic signal control
Xiao-Cheng Liao, Yi Mei, and Mengjie Zhang. SymLight : Exploring interpretable and deployable symbolic policies for traffic signal control. arXiv preprint arXiv:2511.05790, 2025
-
[16]
Evolutionary discovery of heuristic policies for traffic signal control
Ruibing Wang, Shuhan Guo, Zeen Li, Zhen Wang, and Quanming Yao. Evolutionary discovery of heuristic policies for traffic signal control. arXiv preprint arXiv:2511.23122, 2025
-
[17]
Xiaolin Qin and Ata M. Khan. Control strategies of traffic signal timing transition for emergency vehicle preemption. Transportation Research Part C: Emerging Technologies, 25: 0 1--17, 2012. doi:10.1016/j.trc.2012.04.004
-
[18]
Qing He, King H. Head, and Jun Ding. Multi-modal traffic signal control with priority, signal actuation and coordination. Transportation Research Part C: Emerging Technologies, 46: 0 65--82, 2014. doi:10.1016/j.trc.2014.05.001
-
[19]
Person-based traffic responsive signal control optimization
Eleni Christofa, Ioannis Papamichail, and Alexander Skabardonis. Person-based traffic responsive signal control optimization. IEEE Transactions on Intelligent Transportation Systems, 14 0 (3): 0 1278--1289, 2013. doi:10.1109/TITS.2013.2259623
-
[20]
Development and evaluation of a coordinated and conditional bus priority approach
Wanjing Ma, Xiaoguang Yang, and Yue Liu. Development and evaluation of a coordinated and conditional bus priority approach. Transportation Research Record, 2356 0 (1): 0 49--57, 2013. doi:10.3141/2356-06
-
[21]
P. B. Hunt, D. I. Robertson, R. D. Bretherton, and M. C. Royle. The SCOOT on-line traffic signal optimisation technique. Traffic Engineering & Control, 23 0 (4): 0 190--192, 1982
1982
-
[22]
Max pressure control of a network of signalized intersections
Pravin Varaiya. Max pressure control of a network of signalized intersections. Transportation Research Part C: Emerging Technologies, 36: 0 177--195, 2013. doi:10.1016/j.trc.2013.08.014
-
[23]
F. V. Webster. Traffic signal settings. Technical Report Technical Paper No. 39, Road Research Laboratory, UK, 1958
1958
-
[24]
Microscopic traffic simulation using sumo,
Pablo Alvarez Lopez, Michael Behrisch, Laura Bieker-Walz, Jakob Erdmann, Yun-Pang Fl \"o tter \"o d, Robert Hilbrich, Leonhard L \"u cken, Johannes Rummel, Peter Wagner, and Evamarie Wie ner. Microscopic traffic simulation using SUMO . In IEEE International Conference on Intelligent Transportation Systems (ITSC), pages 2575--2582. IEEE, 2018. doi:10.1109/...
-
[25]
Stable-baselines3: Reliable reinforcement learning implementations
Antonin Raffin, Ashley Hill, Adam Gleave, Anssi Kanervisto, Maximilian Ernestus, and Noah Dormann. Stable-baselines3: Reliable reinforcement learning implementations. Journal of Machine Learning Research, 22 0 (268): 0 1--8, 2021
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.