Recognition: no theorem link
COSMO-Agent: Tool-Augmented Agent for Closed-loop Optimization,Simulation,and Modeling Orchestration
Pith reviewed 2026-05-10 19:50 UTC · model grok-4.3
The pith
COSMO-Agent trains small open-source LLMs to outperform larger models at closing the CAD-CAE gap through tool-augmented reinforcement learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
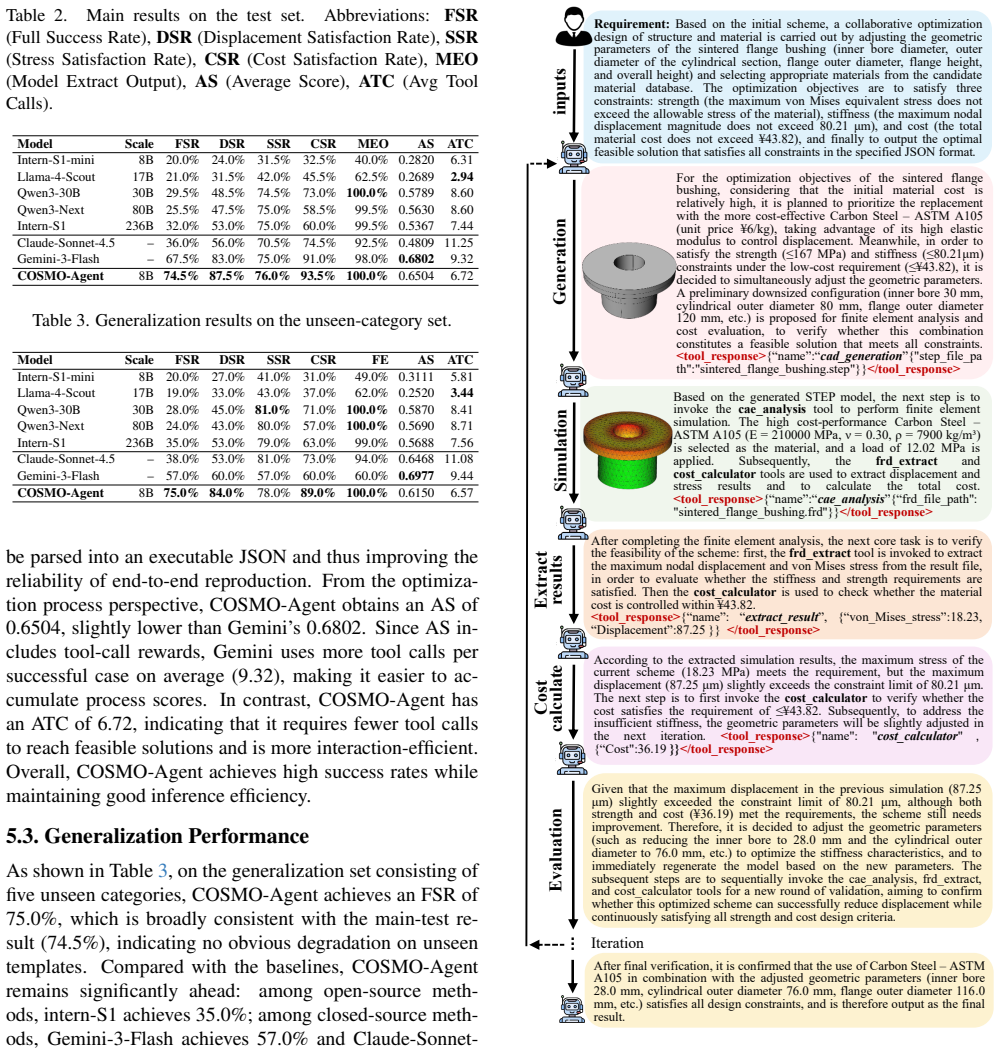
COSMO-Agent is a tool-augmented reinforcement learning framework that turns CAD generation, CAE solving, result parsing, and geometry revision into an interactive environment; an LLM learns to orchestrate these external tools and revise parametric geometries until all constraints are satisfied, guided by a multi-constraint reward that jointly rewards feasibility, toolchain robustness, and output validity, and supported by an industry-aligned dataset covering 25 component categories.
What carries the argument
COSMO-Agent interactive RL environment, which sequences tool calls for CAD-CAE steps under a multi-constraint reward to train LLMs for closed-loop orchestration.
If this is right
- Small open-source LLMs achieve higher feasibility when generating parametric geometries that meet multiple coupled constraints.
- The trained models reach valid designs with greater efficiency and fewer iterations than untrained or larger baselines.
- Tool-call stability improves, reducing the frequency of invalid models or execution errors during the closed loop.
- The contributed dataset enables consistent training and evaluation across 25 industrial component categories.
- The framework allows LLMs to complete the full CAD-to-simulation revision cycle without manual translation steps.
Where Pith is reading between the lines
- The same RL setup could be applied to other simulation-driven domains such as fluid flow or thermal analysis that share iterative edit-and-check loops.
- Specialized training environments like this one may let smaller models handle routine constraint-satisfaction tasks while reserving larger models for open-ended reasoning.
- Integrating the framework directly with commercial CAD software would test whether the learned tool orchestration transfers to proprietary environments.
- Varying the weights inside the multi-constraint reward could reveal trade-offs between feasibility, speed, and other industrial priorities such as manufacturability.
Load-bearing premise
The multi-constraint reward and interactive RL environment can reliably train LLMs to produce valid parametric geometry edits that satisfy coupled industrial constraints without generating invalid models or unstable tool calls.
What would settle it
After COSMO-Agent training, compare the small LLMs against the larger baselines on the held-out dataset tasks and check whether the small models still produce more invalid CAD outputs or fail to satisfy constraints at higher rates.
Figures


read the original abstract
Iterative industrial design-simulation optimization is bottlenecked by the CAD-CAE semantic gap: translating simulation feedback into valid geometric edits under diverse, coupled constraints. To fill this gap, we propose COSMO-Agent (Closed-loop Optimization, Simulation, and Modeling Orchestration), a tool-augmented reinforcement learning (RL) framework that teaches LLMs to complete the closed-loop CAD-CAE process. Specifically, we cast CAD generation, CAE solving, result parsing, and geometry revision as an interactive RL environment, where an LLM learns to orchestrate external tools and revise parametric geometries until constraints are satisfied. To make this learning stable and industrially usable, we design a multi-constraint reward that jointly encourages feasibility, toolchain robustness, and structured output validity. In addition, we contribute an industry-aligned dataset that covers 25 component categories with executable CAD-CAE tasks to support realistic training and evaluation. Experiments show that COSMO-Agent training substantially improves small open-source LLMs for constraint-driven design, exceeding large open-source and strong closed-source models in feasibility, efficiency, and stability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes COSMO-Agent, a tool-augmented reinforcement learning framework that trains LLMs to orchestrate CAD generation, CAE solving, result parsing, and parametric geometry revisions in an interactive closed-loop environment to address the CAD-CAE semantic gap in industrial design optimization. It introduces a multi-constraint reward jointly promoting feasibility, toolchain robustness, and output validity, plus an industry-aligned dataset spanning 25 component categories with executable CAD-CAE tasks. The central claim is that this training substantially improves small open-source LLMs, enabling them to outperform larger open-source and strong closed-source models in feasibility, efficiency, and stability for constraint-driven design.
Significance. If the results hold, the work could meaningfully advance automated iterative design-simulation loops by demonstrating that RL-augmented LLMs can reliably close the CAD-CAE gap under coupled industrial constraints. The contributed dataset of realistic tasks across 25 categories would provide a valuable benchmark resource for the community working on tool-use and constraint satisfaction in engineering AI.
major comments (3)
- [Methods (multi-constraint reward formulation)] The multi-constraint reward (described in the methods as jointly encouraging feasibility, toolchain robustness, and structured output validity) does not appear to include explicit negative terms or penalties for invalid CAD outputs such as non-manifold geometry, solver failures, or unstable revisions. Without these, the RL policy could achieve high reward via reward hacking rather than genuine constraint satisfaction, directly threatening the reported gains in feasibility and stability.
- [Abstract and Experiments section] The abstract and experimental claims assert that COSMO-Agent training yields substantial improvements with small LLMs exceeding large open-source and closed-source baselines in feasibility, efficiency, and stability, yet no quantitative metrics, specific baselines, ablation results, statistical details, error bars, or tables of results are supplied to support these assertions.
- [§3 (RL environment and training setup)] The interactive RL environment is presented as reliably training LLMs to produce valid parametric edits, but the weakest assumption—that the environment and reward prevent generation of invalid models or unstable tool calls—remains unverified without details on how invalid states are detected and penalized during training episodes.
minor comments (2)
- [Title] The title contains a typographical error ('Optimization,Simulation,and Modeling' missing spaces after commas).
- [Methods] Notation for the reward components and tool interfaces could be formalized with equations or pseudocode to improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We have addressed each major comment point by point below, making revisions to improve clarity, rigor, and completeness where the concerns are valid.
read point-by-point responses
-
Referee: [Methods (multi-constraint reward formulation)] The multi-constraint reward (described in the methods as jointly encouraging feasibility, toolchain robustness, and structured output validity) does not appear to include explicit negative terms or penalties for invalid CAD outputs such as non-manifold geometry, solver failures, or unstable revisions. Without these, the RL policy could achieve high reward via reward hacking rather than genuine constraint satisfaction, directly threatening the reported gains in feasibility and stability.
Authors: We thank the referee for highlighting this potential vulnerability. The referee is correct that the original Methods description emphasized positive encouragement terms without explicitly detailing negative penalties for invalid outputs. This omission could indeed invite reward-hacking concerns. We have revised the Methods section to add explicit negative reward terms for non-manifold geometry (detected via CAD kernel validation), solver failures (via error-code parsing), and unstable revisions (via constraint-violation tracking). These penalties are now formulated as additive negative components with defined thresholds and integrated into the overall reward. We have also added a short ablation demonstrating degraded performance when penalties are removed. revision: yes
-
Referee: [Abstract and Experiments section] The abstract and experimental claims assert that COSMO-Agent training yields substantial improvements with small LLMs exceeding large open-source and closed-source baselines in feasibility, efficiency, and stability, yet no quantitative metrics, specific baselines, ablation results, statistical details, error bars, or tables of results are supplied to support these assertions.
Authors: We acknowledge that the abstract lacked quantitative support for the stated improvements. While the Experiments section reports results across the 25-category dataset with comparisons to larger open-source and closed-source models plus some ablation analysis, we agree that metrics, baselines, error bars, and statistical details were not sufficiently prominent. We have updated the abstract to summarize key quantitative outcomes and revised the Experiments section to include additional tables, explicit baseline names, ablation results on reward components, error bars on all plots, and statistical significance tests. revision: yes
-
Referee: [§3 (RL environment and training setup)] The interactive RL environment is presented as reliably training LLMs to produce valid parametric edits, but the weakest assumption—that the environment and reward prevent generation of invalid models or unstable tool calls—remains unverified without details on how invalid states are detected and penalized during training episodes.
Authors: We agree that §3 would benefit from explicit verification of invalid-state handling. The original text described the overall RL loop but did not detail detection mechanisms. We have expanded §3 with a dedicated subsection on state validation, specifying CAD-kernel checks for manifold and topological validity, CAE-solver error parsing for failures, and mapping of these events to negative rewards or episode termination. Pseudocode for the validation step and example penalized trajectories have been added to demonstrate that the environment actively discourages invalid generations. revision: yes
Circularity Check
No circularity; claims rest on experimental results without self-referential reductions
full rationale
The paper describes a tool-augmented RL framework (COSMO-Agent) that casts CAD-CAE tasks as an interactive environment and introduces a multi-constraint reward plus an industry dataset. No equations, derivations, fitted parameters labeled as predictions, or self-citations appear in the abstract or described content. Performance claims (improved feasibility, efficiency, stability on small LLMs) are presented as outcomes of training and evaluation rather than reducing by construction to inputs. This matches the absence of any load-bearing self-definitional, fitted-input, or uniqueness-imported steps, yielding a self-contained experimental report.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLMs can learn stable tool orchestration and geometry revision through RL with a multi-constraint reward
invented entities (1)
-
COSMO-Agent framework
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Do as I can, not as I say: Grounding language in robotic affor- dances
Michael Ahn, Anthony Brohan, Noah Brown, Yevgen Cheb- otar, Omar Cortes, Byron David, Chelsea Finn, Chuyuan Fu, Keerthana Gopalakrishnan, Karol Hausman, et al. Do as I can, not as I say: Grounding language in robotic affor- dances. InConference on Robot Learning, CoRL 2022, 14- 18 December 2022, Auckland, New Zealand, pages 287–318. PMLR, 2022. 2, 3
2022
-
[2]
Claude Sonnet 4.5: System Card
Anthropic. Claude Sonnet 4.5: System Card. System card, Anthropic PBC, 2025. 6
2025
-
[3]
Dennis, Jr
Charles Audet and John E. Dennis, Jr. Mesh adaptive direct search algorithms for constrained optimization.SIAM Jour- nal on Optimization, 17(1):188–217, 2006. 2
2006
-
[4]
Intern- s1: A scientific multimodal foundation model, 2025
Lei Bai, Zhongrui Cai, Maosong Cao, Weihan Cao, Chiyu Chen, Haojiong Chen, Kai Chen, Pengcheng Chen, Ying Chen, Yongkang Chen, Yu Cheng, Yu Cheng, Pei Chu, Tao Chu, Erfei Cui, Ganqu Cui, Long Cui, Ziyun Cui, Ni- anchen Deng, Ning Ding, Nanqin Dong, Peijie Dong, Shi- han Dou, Sinan Du, Haodong Duan, Caihua Fan, Ben Gao, Changjiang Gao, Jianfei Gao, Songyan...
2025
-
[5]
arXiv preprint arXiv:2407.21320 , year =
Yuxuan Chen, Xu Zhu, Hua Zhou, and Zhuyin Ren. Metaopenfoam: an llm-based multi-agent framework for cfd. arXiv preprint arXiv:2407.21320, 2024. 2
-
[6]
Christiano, Jan Leike, Tom B
Paul F. Christiano, Jan Leike, Tom B. Brown, Miljan Mar- tic, Shane Legg, and Dario Amodei. completelyinforcement learning from human preferences. InAdvances in Neural Information Processing Systems, pages 4299–4307, 2017. 2
2017
-
[7]
Cadquery, 2025
CadQuery contributors. Cadquery, 2025. 5
2025
-
[8]
Fine-tuning a large language model for automating computational fluid dynam- ics simulations.Theoretical and Applied Mechanics Letters, page 100594, 2025
Zhehao Dong, Zhen Lu, and Yue Yang. Fine-tuning a large language model for automating computational fluid dynam- ics simulations.Theoretical and Applied Mechanics Letters, page 100594, 2025. 2
2025
-
[9]
Gmsh: A 3-d finite element mesh generator with built-in pre-and post-processing facilities.International journal for numer- ical methods in engineering, 79(11):1309–1331, 2009
Christophe Geuzaine and Jean-Franc ¸ois Remacle. Gmsh: A 3-d finite element mesh generator with built-in pre-and post-processing facilities.International journal for numer- ical methods in engineering, 79(11):1309–1331, 2009. 6
2009
-
[10]
Gemini 3 flash model card
Google DeepMind. Gemini 3 flash model card. Online PDF,
-
[11]
Model card for the Gemini 3 Flash generative AI model. 6
-
[12]
Completely de- randomized self-adaptation in evolution strategies.Evolu- tionary Computation, 9(2):159–195, 2001
Nikolaus Hansen and Andreas Ostermeier. Completely de- randomized self-adaptation in evolution strategies.Evolu- tionary Computation, 9(2):159–195, 2001. 2
2001
-
[13]
Difftaichi: Differentiable programming for physical simulation
Yuanming Hu, Luke Anderson, Tzu-Mao Li, Qi Sun, Nathan Carr, Jonathan Ragan-Kelley, and Fr´edo Durand. Difftaichi: Differentiable programming for physical simulation. InIn- ternational Conference on Learning Representations, 2020. 2
2020
-
[14]
Jones, Matthias Schonlau, and William J
Donald R. Jones, Matthias Schonlau, and William J. Welch. Efficient global optimization of expensive black-box func- tions.Journal of Global Optimization, 13(4):455–492, 1998. 2
1998
-
[15]
Ehud Karpas, Omri Abend, Yonatan Belinkov, Barak Lenz, Opher Lieber, Nir Ratner, Yoav Shoham, Hofit Bata, Yoav Levine, Kevin Leyton-Brown, et al. Mrkl systems: A mod- ular, neuro-symbolic architecture that combines large lan- guage models, external knowledge sources and discrete rea- soning.arXiv preprint arXiv:2205.00445, 2022. 3
-
[16]
Internbootcamp technical report: Boosting llm reasoning with verifiable task scaling, 2025
Peiji Li, Jiasheng Ye, Yongkang Chen, Yichuan Ma, Zijie Yu, Kedi Chen, Ganqu Cui, Haozhan Li, Jiacheng Chen, Chengqi Lyu, Wenwei Zhang, Linyang Li, Qipeng Guo, Dahua Lin, Bowen Zhou, and Kai Chen. Internbootcamp technical report: Boosting llm reasoning with verifiable task scaling, 2025. 3, 6
2025
-
[17]
Llm4cad: Multi-modal large language models for 3d computer-aided design generation
Xingang Li, Yuewan Sun, and Zhenghui Sha. Llm4cad: Multi-modal large language models for 3d computer-aided design generation. InInternational Design Engineering Technical Conferences and Computers and Information in Engineering Conference, page V006T06A015. American Society of Mechanical Engineers, 2024. 2
2024
-
[18]
Kovachki, Kamyar Azizzadenesheli, Burigede Liu, Kaushik Bhattacharya, Andrew Stuart, and Anima Anandkumar
Zongyi Li, Nikola B. Kovachki, Kamyar Azizzadenesheli, Burigede Liu, Kaushik Bhattacharya, Andrew Stuart, and Anima Anandkumar. Fourier neural operator for parametric partial differential equations. InInternational Conference on Learning Representations, 2021. 2
2021
-
[19]
Learning nonlinear operators via DeepONet based on the universal approximation theorem of operators.Nature Machine Intelligence, 3:218–229, 2021
Lu Lu, Pengzhan Jin, Guofei Pang, Zhongqiang Zhang, and George Em Karniadakis. Learning nonlinear operators via DeepONet based on the universal approximation theorem of operators.Nature Machine Intelligence, 3:218–229, 2021. 2
2021
-
[20]
Cad- assistant: tool-augmented vllms as generic cad task solvers
Dimitrios Mallis, Ahmet Serda Karadeniz, Sebastian Cavada, Danila Rukhovich, Niki Foteinopoulou, Kseniya Cherenkova, Anis Kacem, and Djamila Aouada. Cad- assistant: tool-augmented vllms as generic cad task solvers. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 7284–7294, 2025. 2
2025
-
[21]
Llama 4 Scout (17B×16E) Instruct: Model Card
Meta. Llama 4 Scout (17B×16E) Instruct: Model Card. On- line model card, 2025. Model release date: April 5, 2025. Accessed: 2026-01-23. 6
2025
-
[22]
Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agar- wal, Katarina Slama, Alex Ray, et al
Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agar- wal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback. InAd- vances in Neural Information Processing Systems, 2022. 2
2022
-
[23]
Toolllm: Facilitating large language models to mas- ter 16000+ real-world apis
Yujia Qin, Shihao Liang, Yining Ye, Kunlun Zhu, Lan Yan, Yaxi Lu, Yankai Lin, Xin Cong, Xiangru Tang, Bill Qian, Sihan Zhao, Lauren Hong, Runchu Tian, Ruobing Xie, Jie Zhou, Mark Gerstein, Dahai Li, Zhiyuan Liu, and Maosong Sun. Toolllm: Facilitating large language models to mas- ter 16000+ real-world apis. InInternational Conference on Learning Represent...
2024
-
[24]
Karniadakis
Maziar Raissi, Paris Perdikaris, and George E. Karniadakis. Physics-informed neural networks: A deep learning frame- work for solving forward and inverse problems involving nonlinear partial differential equations.Journal of Computa- tional Physics, 378:686–707, 2019. 2
2019
-
[25]
Freecad, 2001–2017
Juergen Riegel, Werner Mayer, and Yorik van Havre. Freecad, 2001–2017. Accessed: 2001–2017. 6
2001
-
[26]
Toolformer: Language models can teach themselves to use tools
Timo Schick, Jane Dwivedi-Yu, Roberto Dess `ı, Roberta Raileanu, Maria Lomeli, Luke Zettlemoyer, Nicola Can- cedda, and Thomas Scialom. Toolformer: Language models can teach themselves to use tools. InAdvances in Neural Information Processing Systems (NeurIPS), pages 68539– 68551, 2023. 2, 3
2023
-
[27]
Ari Seff, Yaniv Ovadia, Wenda Zhou, and Ryan P. Adams. Sketchgraphs: A large-scale dataset for modeling relational geometry in computer-aided design, 2020. 2
2020
-
[28]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y . K. Li, Y . Wu, and Daya Guo. Deepseekmath: Pushing the limits of mathematical reasoning in open language models, 2024. 5
2024
-
[29]
HybridFlow: A Flexible and Efficient RLHF Framework
Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, and Chuan Wu. Hybridflow: A flexible and efficient rlhf frame- work.arXiv preprint arXiv: 2409.19256, 2024. 3
work page internal anchor Pith review arXiv 2024
-
[30]
Jasper Snoek, Hugo Larochelle, and Ryan P. Adams. Practi- cal bayesian optimization of machine learning algorithms. In Advances in Neural Information Processing Systems, pages 2960–2968, 2012. 2
2012
-
[31]
Qwen3 technical report, 2025
Qwen Team. Qwen3 technical report, 2025. 6
2025
-
[32]
Smith, Daniel Khashabi, and Hannaneh Hajishirzi
Yizhong Wang, Yeganeh Kordi, Swaroop Mishra, Alisa Liu, Noah A. Smith, Daniel Khashabi, and Hannaneh Hajishirzi. Self-instruct: Aligning language models with self-generated instructions. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (ACL), 2023. 2
2023
-
[33]
Chain-of-thought prompting elicits reasoning in large language models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc V Le, and Denny Zhou. Chain-of-thought prompting elicits reasoning in large language models. InAdvances in Neural Information Pro- cessing Systems (NeurIPS), pages 24824–24837, 2022. 2
2022
-
[34]
Karl D. D. Willis, Yewen Pu, Jieliang Luo, Hang Chu, Tao Du, Joseph G. Lambourne, Armando Solar-Lezama, and Wojciech Matusik. Fusion 360 gallery: a dataset and en- vironment for programmatic CAD construction from human design sequences.ACM Trans. Graph., 40(4):54:1–54:24,
-
[35]
Karl D. D. Willis, Pradeep Kumar Jayaraman, Hang Chu, Yunsheng Tian, Yifei Li, Daniele Grandi, Aditya Sanghi, Linh Tran, Joseph G. Lambourne, Armando Solar-Lezama, and Wojciech Matusik. Joinable: Learning bottom-up as- sembly of parametric CAD joints. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2022, New Orleans, LA, USA, June 1...
2022
-
[36]
Haoyang Xie and Feng Ju. Text-to-cadquery: A new paradigm for cad generation with scalable large model ca- pabilities.arXiv preprint arXiv:2505.06507, 2025. 2
-
[37]
Cfdagent: A language-guided, zero-shot multi-agent system for complex flow simulation.Physics of Fluids, 37 (11), 2025
Zhaoyue Xu, Long Wang, Chunyu Wang, Yixin Chen, Qingyong Luo, Hua-Dong Yao, Shizhao Wang, and Guowei He. Cfdagent: A language-guided, zero-shot multi-agent system for complex flow simulation.Physics of Fluids, 37 (11), 2025. 2
2025
-
[38]
Qwen3 technical report, 2025
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jia- long Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jing Zhou, Jingren Zhou, Junyang Lin, Kai Dang, Keqin Bao, Kexin Yang...
2025
-
[39]
Narasimhan, and Yuan Cao
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R. Narasimhan, and Yuan Cao. ReAct: Synergizing reasoning and acting in language models. InInternational Conference on Learning Representations (ICLR), 2023. 2, 3
2023
-
[40]
Openecad: An efficient visual language model for editable 3d-cad design
Zhe Yuan, Jianqi Shi, and Yanhong Huang. Openecad: An efficient visual language model for editable 3d-cad design. Computers & Graphics, 124:104048, 2024. 2
2024
-
[41]
Foam-agent: Towards au- tomated intelligent CFD workflows.arXiv preprint arXiv:2505.04997, 2025
Ling Yue, Nithin Somasekharan, Yadi Cao, and Shaowu Pan. Foam-agent: Towards automated intelligent cfd workflows. arXiv preprint arXiv:2505.04997, 2025. 3
-
[42]
Marti: A framework for multi-agent llm systems reinforced training and inference,
Kaiyan Zhang, Runze Liu, Xuekai Zhu, Kai Tian, Sihang Zeng, Guoli Jia, Yuchen Fan, Xingtai Lv, Yuxin Zuo, Che Jiang, Ziyang Liu, Jianyu Wang, Yuru Wang, Ruotong Zhao, Ermo Hua, Yibo Wang, Shijie Wang, Junqi Gao, Xinwei Long, Youbang Sun, Zhiyuan Ma, Ganqu Cui, Lei Bai, Ning Ding, Biqing Qi, and Bowen Zhou. Marti: A framework for multi-agent llm systems re...
-
[43]
Tao Zhang, Zhenhai Liu, Yong Xin, and Yongjun Jiao. Mooseagent: A llm based multi-agent frame- work for automating moose simulation.arXiv preprint arXiv:2504.08621, 2025. 3
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.