Recognition: 2 theorem links
· Lean TheoremID-Selection: Importance-Diversity Based Visual Token Selection for Efficient LVLM Inference
Pith reviewed 2026-05-10 18:56 UTC · model grok-4.3
The pith
ID-Selection prunes 97 percent of visual tokens in large vision-language models while keeping 91.8 percent of original performance without retraining.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
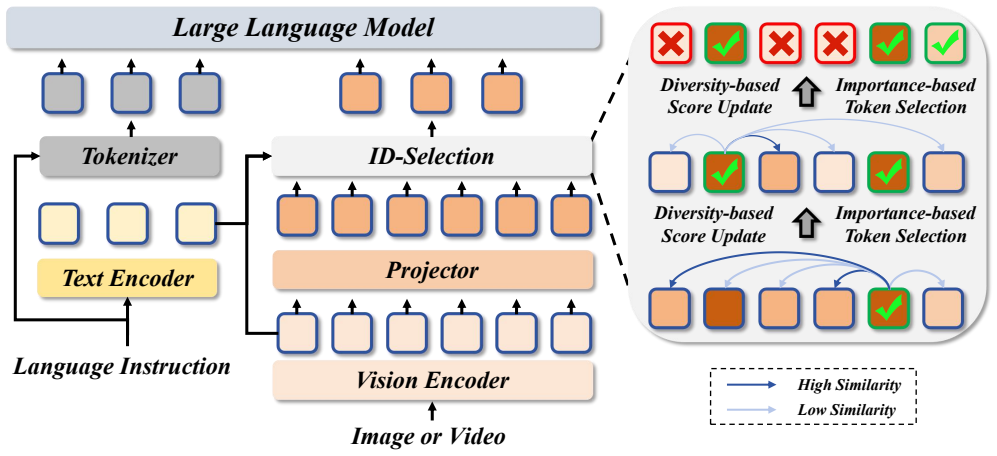
ID-Selection first computes an importance score for every visual token, then repeatedly picks the current highest-scoring token and lowers the scores of all remaining tokens whose visual features are similar to the one just chosen. Experiments show this yields better accuracy-efficiency trade-offs than prior importance-only or diversity-only baselines, especially when the retained token count is reduced to sixteen on LLaVA-1.5-7B, producing over 97 percent FLOP savings while holding 91.8 percent of the unpruned accuracy.
What carries the argument
The importance-diversity selection loop that assigns per-token importance scores and then applies progressive similarity suppression during one-by-one selection.
Load-bearing premise
The chosen importance estimator combined with similarity suppression will not drop tokens that are individually low-scoring yet collectively required for correct answers on unseen images or tasks.
What would settle it
A controlled test set of images whose correct answers depend on a combination of individually low-importance but non-redundant visual details; if accuracy falls sharply after pruning to sixteen tokens, the method fails to preserve necessary information.
Figures




read the original abstract
Recent advances have explored visual token pruning to accelerate the inference of large vision-language models (LVLMs). However, existing methods often struggle to balance token importance and diversity: importance-based methods tend to retain redundant tokens, whereas diversity-based methods may overlook informative ones. This trade-off becomes especially problematic under high reduction ratios, where preserving only a small subset of visual tokens is critical. To address this issue, we propose ID-Selection, a simple yet effective token selection strategy for efficient LVLM inference. The key idea is to couple importance estimation with diversity-aware iterative selection: each token is first assigned an importance score, after which high-scoring tokens are selected one by one while the scores of similar tokens are progressively suppressed. In this way, ID-Selection preserves informative tokens while reducing redundancy in a unified selection process. Extensive experiments across 5 LVLM backbones and 16 main benchmarks demonstrate that ID-Selection consistently achieves superior performance and efficiency, especially under extreme pruning ratios. For example, on LLaVA-1.5-7B, ID-Selection prunes 97.2% of visual tokens, retaining only 16 tokens, while reducing inference FLOPs by over 97% and preserving 91.8% of the original performance, all without additional training.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces ID-Selection, a training-free visual token pruning method for large vision-language models that first assigns importance scores to tokens and then performs iterative selection while progressively suppressing scores of similar tokens to balance informativeness and diversity. It reports consistent gains in efficiency and performance retention across five LVLM backbones and sixteen benchmarks, with the headline result that on LLaVA-1.5-7B the method retains only 16 tokens (97.2% pruning), cuts inference FLOPs by over 97%, and preserves 91.8% of original accuracy.
Significance. If the empirical results prove robust, the work offers a practical, training-free route to extreme visual-token reduction in LVLMs, directly addressing the importance-diversity trade-off that limits prior pruning methods at high reduction ratios. The absence of any retraining requirement and the breadth of tested backbones and tasks would make the approach immediately deployable for resource-constrained inference.
major comments (2)
- [§3] §3 (Method), the description of the importance estimator and progressive suppression step: the central performance claim at 97%+ pruning ratios rests on the assumption that the chosen importance metric plus iterative similarity suppression never discards a set of individually low-scoring yet jointly necessary tokens (e.g., subtle spatial relations or multiple similar objects). No quantitative definition or pseudocode for the score-update rule is provided, making it impossible to verify whether the procedure can systematically under-rate such tokens.
- [§4] §4 (Experiments), Tables 1–3 and the LLaVA-1.5-7B row: the headline numbers (91.8% retained performance at 16 tokens) are reported without per-benchmark standard deviations, without the exact baseline implementations used for comparison, and without targeted ablations on images where collective token necessity is known to matter. These omissions leave the robustness of the 97% pruning claim unverified.
minor comments (2)
- [Abstract, §1] The abstract and §1 repeatedly use “over 97%” for FLOP reduction; the exact percentage and the precise token count (16) should be stated uniformly with the same precision throughout.
- [Figure 2] Figure 2 (qualitative examples) would benefit from an additional column showing the tokens that were suppressed by the diversity step, to illustrate the mechanism.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the potential of ID-Selection as a practical, training-free approach to extreme visual token pruning. We address each major comment below and will revise the manuscript to enhance clarity, reproducibility, and empirical rigor.
read point-by-point responses
-
Referee: [§3] §3 (Method), the description of the importance estimator and progressive suppression step: the central performance claim at 97%+ pruning ratios rests on the assumption that the chosen importance metric plus iterative similarity suppression never discards a set of individually low-scoring yet jointly necessary tokens (e.g., subtle spatial relations or multiple similar objects). No quantitative definition or pseudocode for the score-update rule is provided, making it impossible to verify whether the procedure can systematically under-rate such tokens.
Authors: We agree that the method description in §3 would be strengthened by a precise quantitative formulation and pseudocode. The current text describes the process at a high level but does not provide the exact score-update equation or algorithmic steps. In the revision we will add the formal definition of the progressive suppression rule (based on cosine similarity in the visual embedding space) together with pseudocode for the full iterative selection procedure. We will also include a short discussion of potential limitations, including scenarios where jointly necessary low-scoring tokens might be under-retained, and any empirical safeguards observed in our experiments. revision: yes
-
Referee: [§4] §4 (Experiments), Tables 1–3 and the LLaVA-1.5-7B row: the headline numbers (91.8% retained performance at 16 tokens) are reported without per-benchmark standard deviations, without the exact baseline implementations used for comparison, and without targeted ablations on images where collective token necessity is known to matter. These omissions leave the robustness of the 97% pruning claim unverified.
Authors: We acknowledge that the experimental reporting can be improved for greater statistical transparency and verifiability. In the revised manuscript we will augment Tables 1–3 with per-benchmark standard deviations obtained from multiple inference runs. We will also specify the exact baseline codebases, versions, and hyper-parameters used for all compared methods. Additionally, we will add a targeted analysis (in the main text or appendix) that examines performance on images known to require collective token information, such as those involving subtle spatial relations or multiple similar objects, to directly address robustness at high pruning ratios. revision: yes
Circularity Check
No circularity: algorithmic heuristic evaluated on external benchmarks
full rationale
The paper introduces ID-Selection as a procedural algorithm that first computes per-token importance scores and then performs iterative selection with progressive similarity suppression. All reported results (e.g., 97.2 % pruning to 16 tokens while retaining 91.8 % performance on LLaVA-1.5-7B) are obtained by running this fixed procedure on standard VQA/captioning benchmarks without any parameter fitting to the test data or self-referential definitions. No equation or claim reduces the measured accuracy or FLOPs reduction to a quantity that is defined in terms of itself or to a self-citation whose validity depends on the present work. The method is therefore self-contained against external evaluation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Token importance scores derived from the LVLM can be used as a reliable ranking signal
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel uncleareach token is first assigned an importance score, after which high-scoring tokens are selected one by one while the scores of similar tokens are progressively suppressed... w_ij = exp(−γ·d(i,j)²)
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearID-Selection prunes 97.2% of visual tokens, retaining only 16 tokens, while reducing inference FLOPs by over 97%
Reference graph
Works this paper leans on
-
[1]
Divprune: Diversity-based visual token pruning for large multimodal models
Saeed Ranjbar Alvar, Gursimran Singh, Mohammad Akbari, and Yong Zhang. Divprune: Diversity-based visual token pruning for large multimodal models. InCVPR, 2025. 1, 2, 3, 4, 5, 6, 7, 8 9
2025
-
[2]
Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, et al. Qwen technical report.arXiv preprint arXiv:2309.16609, 2023. 1, 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and Jingren Zhou. Qwen-vl: A frontier large vision-language model with versatile abilities.arXiv preprint arXiv:2308.12966, 2023. 1, 2
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2. 5-vl technical report.arXiv preprint arXiv:2502.13923, 2025. 1, 5, 7, 8
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Collecting highly paral- lel data for paraphrase evaluation
David Chen and William B Dolan. Collecting highly paral- lel data for paraphrase evaluation. InProceedings of the 49th annual meeting of the association for computational linguis- tics: human language technologies, 2011. 5, 8
2011
-
[6]
An image is worth 1/2 tokens after layer 2: Plug-and-play inference acceleration for large vision-language models
Liang Chen, Haozhe Zhao, Tianyu Liu, Shuai Bai, Junyang Lin, Chang Zhou, and Baobao Chang. An image is worth 1/2 tokens after layer 2: Plug-and-play inference acceleration for large vision-language models. InECCV, 2024. 1, 2, 3, 4, 5, 6, 7, 8, 9
2024
-
[7]
Cf-vit: A general coarse-to-fine method for vision transformer
Mengzhao Chen, Mingbao Lin, Ke Li, Yunhang Shen, Yongjian Wu, Fei Chao, and Rongrong Ji. Cf-vit: A general coarse-to-fine method for vision transformer. InProceed- ings of the AAAI conference on artificial intelligence, pages 7042–7052, 2023. 2
2023
-
[8]
Zhe Chen, Weiyun Wang, Yue Cao, Yangzhou Liu, Zhang- wei Gao, Erfei Cui, Jinguo Zhu, Shenglong Ye, Hao Tian, Zhaoyang Liu, et al. Expanding performance boundaries of open-source multimodal models with model, data, and test- time scaling.arXiv preprint arXiv:2412.05271, 2024. 5, 7, 8
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
MME: A Comprehensive Evaluation Benchmark for Multimodal Large Language Models
Chaoyou Fu, Peixian Chen, Yunhang Shen, Yulei Qin, Mengdan Zhang, Xu Lin, Jinrui Yang, Xiawu Zheng, Ke Li, Xing Sun, et al. Mme: A comprehensive evaluation bench- mark for multimodal large language models.arXiv preprint arXiv:2306.13394, 2023. 5, 8
work page internal anchor Pith review arXiv 2023
-
[10]
Making the v in vqa matter: Elevating the role of image understanding in visual question answer- ing
Yash Goyal, Tejas Khot, Douglas Summers-Stay, Dhruv Ba- tra, and Devi Parikh. Making the v in vqa matter: Elevating the role of image understanding in visual question answer- ing. InCVPR, 2017. 5
2017
-
[11]
Vizwiz grand challenge: Answering visual questions from blind people
Danna Gurari, Qing Li, Abigale J Stangl, Anhong Guo, Chi Lin, Kristen Grauman, Jiebo Luo, and Jeffrey P Bigham. Vizwiz grand challenge: Answering visual questions from blind people. InCVPR, 2018. 5
2018
-
[12]
Opera: Alleviating hallucination in multi- modal large language models via over-trust penalty and retrospection-allocation
Qidong Huang, Xiaoyi Dong, Pan Zhang, Bin Wang, Con- ghui He, Jiaqi Wang, Dahua Lin, Weiming Zhang, and Nenghai Yu. Opera: Alleviating hallucination in multi- modal large language models via over-trust penalty and retrospection-allocation. InCVPR, 2024. 2
2024
-
[13]
Gqa: A new dataset for real-world visual reasoning and compositional question answering
Drew A Hudson and Christopher D Manning. Gqa: A new dataset for real-world visual reasoning and compositional question answering. InCVPR, 2019. 5, 8, 9
2019
-
[14]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perel- man, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Weli- hinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card. arXiv preprint arXiv:2410.21276, 2024. 1
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
Tgif-qa: Toward spatio-temporal reasoning in visual question answering
Yunseok Jang, Yale Song, Youngjae Yu, Youngjin Kim, and Gunhee Kim. Tgif-qa: Toward spatio-temporal reasoning in visual question answering. InCVPR, 2017. 5, 8
2017
-
[16]
Visa: Group-wise visual token selection and aggregation via graph summarization for efficient mllms inference
Pengfei Jiang, Hanjun Li, Linglan Zhao, Fei Chao, Ke Yan, Shouhong Ding, and Rongrong Ji. Visa: Group-wise visual token selection and aggregation via graph summarization for efficient mllms inference. InACM MM, 2025. 1
2025
-
[17]
Determinantal point pro- cesses for machine learning.Foundations and Trends® in Machine Learning, 2012
Alex Kulesza, Ben Taskar, et al. Determinantal point pro- cesses for machine learning.Foundations and Trends® in Machine Learning, 2012. 2
2012
-
[18]
Evaluating Object Hallucination in Large Vision-Language Models
Yifan Li, Yifan Du, Kun Zhou, Jinpeng Wang, Wayne Xin Zhao, and Ji-Rong Wen. Evaluating object hallucina- tion in large vision-language models.arXiv preprint arXiv:2305.10355, 2023. 1, 5, 8, 9
work page internal anchor Pith review arXiv 2023
-
[19]
Video-llava: Learning united visual repre- sentation by alignment before projection
Bin Lin, Yang Ye, Bin Zhu, Jiaxi Cui, Munan Ning, Peng Jin, and Li Yuan. Video-llava: Learning united visual repre- sentation by alignment before projection. InENNLP, 2024. 1, 2, 3, 4, 5, 7, 8
2024
-
[20]
Visual instruction tuning.NeurIPS, 2023
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.NeurIPS, 2023. 1, 2, 3, 4, 5, 6, 8
2023
-
[21]
Llavanext: Improved reasoning, ocr, and world knowledge, 2024
Haotian Liu, Chunyuan Li, Yuheng Li, Bo Li, Yuanhan Zhang, Sheng Shen, and Yong Jae Lee. Llavanext: Improved reasoning, ocr, and world knowledge, 2024. 1, 2, 3, 4, 5, 6, 7, 9
2024
-
[22]
Mmbench: Is your multi-modal model an all-around player? InECCV, 2024
Yuan Liu, Haodong Duan, Yuanhan Zhang, Bo Li, Songyang Zhang, Wangbo Zhao, Yike Yuan, Jiaqi Wang, Conghui He, Ziwei Liu, et al. Mmbench: Is your multi-modal model an all-around player? InECCV, 2024. 2, 5, 8
2024
-
[23]
Ocrbench: On the hidden mystery of ocr in large multimodal models.Science China Information Sciences, 67(12):220102, 2024
Yuliang Liu, Zhang Li, Mingxin Huang, Biao Yang, Wenwen Yu, Chunyuan Li, Xu-Cheng Yin, Cheng-Lin Liu, Lianwen Jin, and Xiang Bai. Ocrbench: On the hidden mystery of ocr in large multimodal models.Science China Information Sciences, 67(12):220102, 2024. 5, 8
2024
-
[24]
Learn to explain: Multimodal reasoning via thought chains for science question answering.NeurIPS,
Pan Lu, Swaroop Mishra, Tanglin Xia, Liang Qiu, Kai-Wei Chang, Song-Chun Zhu, Oyvind Tafjord, Peter Clark, and Ashwin Kalyan. Learn to explain: Multimodal reasoning via thought chains for science question answering.NeurIPS,
-
[25]
Feast your eyes: Mixture-of- resolution adaptation for multimodal large language models
Gen Luo, Yiyi Zhou, Yuxin Zhang, Xiawu Zheng, Xi- aoshuai Sun, and Rongrong Ji. Feast your eyes: Mixture-of- resolution adaptation for multimodal large language models. InICLR, 2025. 2
2025
-
[26]
Chartqa: A benchmark for question answer- ing about charts with visual and logical reasoning
Ahmed Masry, Do Xuan Long, Jia Qing Tan, Shafiq Joty, and Enamul Hoque. Chartqa: A benchmark for question answer- ing about charts with visual and logical reasoning. 2022. 5, 8
2022
-
[27]
Docvqa: A dataset for vqa on document images
Minesh Mathew, Dimosthenis Karatzas, and CV Jawahar. Docvqa: A dataset for vqa on document images. 2021. 5
2021
-
[28]
Infographicvqa
Minesh Mathew, Viraj Bagal, Rub `en Tito, Dimosthenis Karatzas, Ernest Valveny, and CV Jawahar. Infographicvqa
-
[29]
A simple and effective algorithm for the maxmin diversity problem.Annals of Operations Research, 2011
Daniel Cosmin Porumbel, Jin-Kao Hao, and Fred Glover. A simple and effective algorithm for the maxmin diversity problem.Annals of Operations Research, 2011. 3
2011
-
[30]
Learn- ing transferable visual models from natural language super- vision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, 10 Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learn- ing transferable visual models from natural language super- vision. InInt. Conf. Mach. Intell., 2021. 1, 2, 3, 4, 5, 6, 7, 8, 9
2021
-
[31]
Llava-prumerge: Adaptive token reduction for efficient large multimodal models.ICCV, 2025
Yuzhang Shang, Mu Cai, Bingxin Xu, Yong Jae Lee, and Yan Yan. Llava-prumerge: Adaptive token reduction for efficient large multimodal models.ICCV, 2025. 2, 5, 6, 7
2025
-
[32]
Towards vqa models that can read
Amanpreet Singh, Vivek Natarajan, Meet Shah, Yu Jiang, Xinlei Chen, Dhruv Batra, Devi Parikh, and Marcus Rohrbach. Towards vqa models that can read. InCVPR,
-
[33]
Gemini: A Family of Highly Capable Multimodal Models
Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean- Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, Katie Millican, et al. Gemini: a family of highly capable multimodal models.arXiv preprint arXiv:2312.11805, 2023. 1, 2
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[34]
LLaMA: Open and Efficient Foundation Language Models
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timoth´ee Lacroix, Baptiste Rozi`ere, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971, 2023. 1, 2
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[35]
Attention is all you need.NeurIPS, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszko- reit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.NeurIPS, 2017. 3
2017
-
[36]
Stop looking for important tokens in multimodal language models: Duplication matters more.EMNLP, 2025
Zichen Wen, Yifeng Gao, Shaobo Wang, Junyuan Zhang, Qintong Zhang, Weijia Li, Conghui He, and Linfeng Zhang. Stop looking for important tokens in multimodal language models: Duplication matters more.EMNLP, 2025. 2, 3, 4, 5, 6, 7, 8
2025
-
[37]
Msr-vtt: A large video description dataset for bridging video and language
Jun Xu, Tao Mei, Ting Yao, and Yong Rui. Msr-vtt: A large video description dataset for bridging video and language. In CVPR, 2016. 5, 8
2016
-
[38]
Visionzip: Longer is better but not necessary in vision language models
Senqiao Yang, Yukang Chen, Zhuotao Tian, Chengyao Wang, Jingyao Li, Bei Yu, and Jiaya Jia. Visionzip: Longer is better but not necessary in vision language models. In CVPR, 2025. 2, 5, 6, 7
2025
-
[39]
Sigmoid loss for language image pre-training
Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, and Lucas Beyer. Sigmoid loss for language image pre-training. InICCV, 2023. 1, 4
2023
-
[40]
Qizhe Zhang, Aosong Cheng, Ming Lu, Zhiyong Zhuo, Minqi Wang, Jiajun Cao, Shaobo Guo, Qi She, and Shang- hang Zhang. [cls] attention is all you need for training- free visual token pruning: Make vlm inference faster.arXiv preprint arXiv:2412.01818, 2024. 1, 2, 3, 4, 5, 6, 7, 8, 9
-
[41]
Beyond text-visual attention: Exploiting visual cues for effective token pruning in vlms.ICCV, 2025
Qizhe Zhang, Aosong Cheng, Ming Lu, Renrui Zhang, Zhiy- ong Zhuo, Jiajun Cao, Shaobo Guo, Qi She, and Shanghang Zhang. Beyond text-visual attention: Exploiting visual cues for effective token pruning in vlms.ICCV, 2025. 2, 3, 5, 6, 7, 8
2025
-
[42]
Beyond attention or similarity: Maximizing conditional diversity for token pruning in mllms.NeurIPS, 2025
Qizhe Zhang, Mengzhen Liu, Lichen Li, Ming Lu, Yuan Zhang, Junwen Pan, Qi She, and Shanghang Zhang. Beyond attention or similarity: Maximizing conditional diversity for token pruning in mllms.NeurIPS, 2025. 2, 3, 4, 5, 6, 7, 8
2025
-
[43]
Sparsevlm: Vi- sual token sparsification for efficient vision-language model inference.Int
Yuan Zhang, Chun-Kai Fan, Junpeng Ma, Wenzhao Zheng, Tao Huang, Kuan Cheng, Denis Gudovskiy, Tomoyuki Okuno, Yohei Nakata, Kurt Keutzer, et al. Sparsevlm: Vi- sual token sparsification for efficient vision-language model inference.Int. Conf. Mach. Intell., 2025. 3, 5, 6, 7 11
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.