Recognition: 2 theorem links
· Lean TheoremSee the Forest for the Trees: Loosely Speculative Decoding via Visual-Semantic Guidance for Efficient Inference of Video LLMs
Pith reviewed 2026-05-10 19:53 UTC · model grok-4.3
The pith
LVSpec enables loosely speculative decoding for Video-LLMs by identifying sparse visual anchors for strict checks and allowing loose position-tolerant verification for fillers, achieving 2.7x-2.9x speedups with over 99.8% performance kept.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
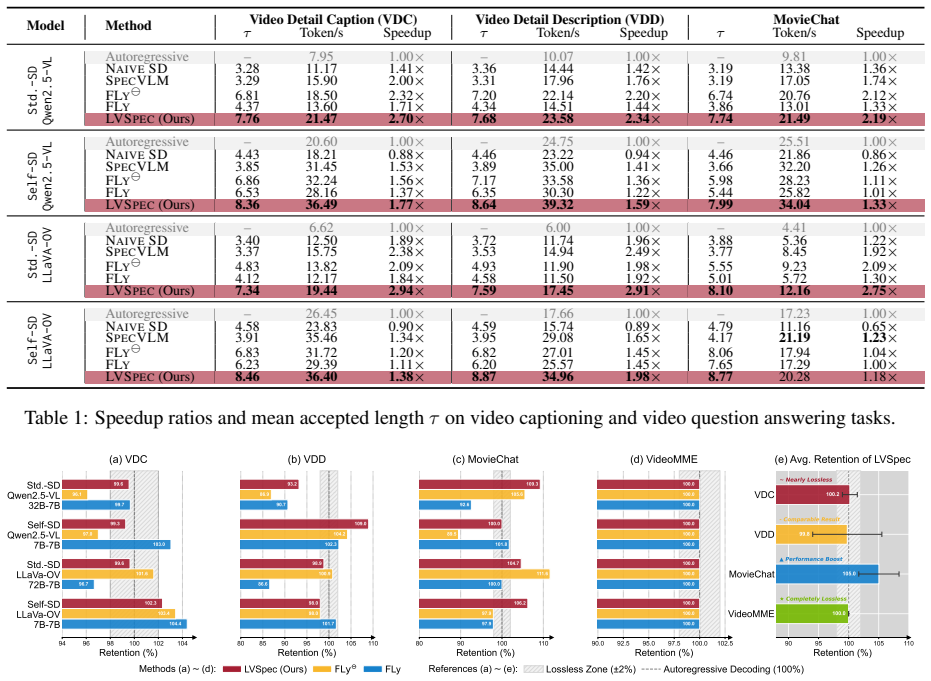
LVSpec is the first training-free loosely speculative decoding framework for Video-LLMs. It rests on the observation that generation is controlled by sparse visual-relevant anchors requiring strict verification amid abundant visual-irrelevant fillers that permit loose verification. The framework uses a lightweight visual-relevant token identification scheme to locate anchors and augments it with a position-shift tolerant mechanism that accepts semantically equivalent but positionally offset tokens, thereby increasing the mean accepted length and delivering the reported speedups while preserving >99.8% of target performance.
What carries the argument
Lightweight visual-relevant token identification scheme paired with position-shift tolerant verification to separate strict anchors from tolerant fillers.
If this is right
- Video-LLMs can generate responses at 2.7x to 2.9x lower latency without any model retraining or fine-tuning.
- Mean accepted draft length increases by 136% over existing training-free speculative decoding baselines for Video-LLMs.
- Speedup ratios improve by 35% relative to prior state-of-the-art training-free methods while output fidelity stays above 99.8%.
- The same framework applies across different Video-LLM sizes, including 32B and 72B parameter models.
- Rigid exact-match constraints in speculative decoding are no longer necessary when visual semantics provide natural separation between anchors and fillers.
Where Pith is reading between the lines
- The separation of strict and loose tokens could extend to other multimodal models where one modality supplies natural sparsity cues.
- Integrating the identification scheme with learned draft heads might compound the observed speed gains further.
- Real-time video applications such as live captioning or analysis could become practical on consumer hardware due to the reduced compute per token.
- The position-shift tolerance mechanism suggests that semantic equivalence rather than token identity is the more relevant acceptance criterion in visually grounded generation.
Load-bearing premise
A lightweight scheme can reliably distinguish visual-relevant anchors needing exact verification from fillers that tolerate loose position-shifted checks without introducing errors or extra overhead that cancels the gains.
What would settle it
If the token identification scheme mislabels anchors as fillers on a test video set, the generated outputs will diverge from the target model or the accepted length will drop to levels no better than rigid exact-match speculative decoding.
Figures











read the original abstract
Video Large Language Models (Video-LLMs) excel in video understanding but suffer from high inference latency during autoregressive generation. Speculative Decoding (SD) mitigates this by applying a draft-and-verify paradigm, yet existing methods are constrained by rigid exact-match rules, severely limiting the acceleration potential. To bridge this gap, we propose LVSpec, the first training-free loosely SD framework tailored for Video-LLMs. Grounded in the insight that generation is governed by sparse visual-relevant anchors (mandating strictness) amidst abundant visual-irrelevant fillers (permitting loose verification), LVSpec employs a lightweight visual-relevant token identification scheme to accurately pinpoint the former. To further maximize acceptance, we augment this with a position-shift tolerant mechanism that effectively salvages positionally mismatched but semantically equivalent tokens. Experiments demonstrate that LVSpec achieves high fidelity and speed: it preserves >99.8 of target performance while accelerating Qwen2.5-VL-32B by 2.70x and LLaVA-OneVision-72B by 2.94x. Notably, it boosts the mean accepted length and speedup ratio by 136% and 35% compared to SOTA training-free SD methods for Video-LLMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces LVSpec, a training-free loosely speculative decoding framework for Video-LLMs. It is based on the insight that generation involves sparse visual-relevant anchors (requiring strict verification) amid abundant visual-irrelevant fillers (permitting loose, position-shift tolerant verification). The method uses a lightweight visual-relevant token identification scheme plus a position-shift tolerant mechanism to increase acceptance rates. Experiments claim it preserves >99.8% of target performance while accelerating Qwen2.5-VL-32B by 2.70× and LLaVA-OneVision-72B by 2.94×, with 136% higher mean accepted length and 35% higher speedup ratio than SOTA training-free SD methods for Video-LLMs.
Significance. If the fidelity and speedup claims hold under rigorous validation, this would be a meaningful advance for efficient inference of video LLMs, offering a practical training-free acceleration technique that exploits video content structure. The training-free design and reported gains in accepted length are strengths that could enable broader deployment of large video models without retraining costs.
major comments (2)
- [§3] §3 (Visual-Relevant Token Identification and Position-Shift Tolerant Mechanism): The central claim of >99.8% fidelity rests on the assumption that the lightweight identification scheme perfectly separates anchors from fillers and that position-shift tolerance for fillers never introduces semantic drift in temporally ordered video (e.g., action sequences or object trajectories). The manuscript must include concrete examples, per-token error analysis, or long-generation metrics demonstrating that shift-tolerant matches do not accumulate violations of event ordering; without this, the speedup gains (2.70–2.94×) risk being offset by unmeasured fidelity loss on timing-sensitive tasks.
- [Experiments] Experimental section: The reported performance numbers (>99.8% fidelity, specific speedups, 136% mean-accepted-length gain) lack sufficient detail on experimental setup, exact baselines, number of video samples, task diversity, error bars, or ablation on the identification scheme's accuracy. This makes it impossible to verify the comparisons to SOTA training-free SD methods or to assess whether the loose verification truly preserves target performance across video domains.
minor comments (2)
- [Abstract] Abstract: the phrase 'preserves >99.8 of target performance' appears to be missing a '%' sign and should be clarified as '99.8%' for precision.
- [§3] Notation: the terms 'visual-relevant anchors' and 'visual-irrelevant fillers' are introduced without an explicit formal definition or pseudocode in the early sections, which could improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on LVSpec. We address the major comments point-by-point below and have revised the manuscript to incorporate the requested clarifications and analyses.
read point-by-point responses
-
Referee: [§3] §3 (Visual-Relevant Token Identification and Position-Shift Tolerant Mechanism): The central claim of >99.8% fidelity rests on the assumption that the lightweight identification scheme perfectly separates anchors from fillers and that position-shift tolerance for fillers never introduces semantic drift in temporally ordered video (e.g., action sequences or object trajectories). The manuscript must include concrete examples, per-token error analysis, or long-generation metrics demonstrating that shift-tolerant matches do not accumulate violations of event ordering; without this, the speedup gains (2.70–2.94×) risk being offset by unmeasured fidelity loss on timing-sensitive tasks.
Authors: We agree that explicit evidence is needed to confirm position-shift tolerance does not accumulate ordering violations on temporally sensitive content. Our existing results on action and temporal-reasoning benchmarks already show >99.8% fidelity retention, indicating that any drift remains negligible at the task level. In the revision we will add concrete token-level examples of accepted position-shifted fillers, per-token acceptance statistics, and additional long-sequence generation metrics to directly demonstrate preservation of event ordering. revision: yes
-
Referee: [Experiments] Experimental section: The reported performance numbers (>99.8% fidelity, specific speedups, 136% mean-accepted-length gain) lack sufficient detail on experimental setup, exact baselines, number of video samples, task diversity, error bars, or ablation on the identification scheme's accuracy. This makes it impossible to verify the comparisons to SOTA training-free SD methods or to assess whether the loose verification truly preserves target performance across video domains.
Authors: We acknowledge that expanded experimental details will improve reproducibility and verifiability. The manuscript already names the two target models, the SOTA training-free baselines, and the reported metrics. We will revise the experimental section to specify the exact number of video samples, a breakdown of task diversity, error bars computed over multiple runs, and a new ablation quantifying the accuracy of the visual-relevant token identification scheme. revision: yes
Circularity Check
No circularity: derivation introduces independent mechanisms
full rationale
The paper's core proposal—LVSpec's visual-relevant token identification scheme plus position-shift tolerant verification for fillers—is presented as a novel, training-free insight applied to Video-LLMs. No equations, definitions, or performance claims reduce by construction to fitted inputs, self-citations, or renamed priors. The abstract and described framework treat the anchor/filler separation and loose verification as externally motivated design choices whose validity is tested via experiments on Qwen2.5-VL and LLaVA-OneVision models, not derived tautologically from the inputs themselves. This is the common case of a self-contained empirical method.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Generation in Video-LLMs is governed by sparse visual-relevant anchors mandating strict verification amidst abundant visual-irrelevant fillers permitting loose verification.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel echoesgeneration is governed by sparse visual-relevant anchors (mandating strictness) amidst abundant visual-irrelevant fillers (permitting loose verification)
Reference graph
Works this paper leans on
-
[1]
Tianle Cai, Yuhong Li, Zhengyang Geng, Hongwu Peng, Jason D
3-Model Speculative Decoding.CoRR, abs/2510.12966. Tianle Cai, Yuhong Li, Zhengyang Geng, Hongwu Peng, Jason D. Lee, Deming Chen, and Tri Dao. 2024. Medusa: Simple LLM Inference Acceleration Frame- work with Multiple Decoding Heads. InForty-first In- ternational Conference on Machine Learning, ICML 2024, Vienna, Austria, July 21-27, 2024. Wenhao Chai, Enx...
-
[2]
InThe Thir- teenth International Conference on Learning Repre- sentations, ICLR 2025, Singapore, April 24-28, 2025
AuroraCap: Efficient, Performant Video De- tailed Captioning and a New Benchmark. InThe Thir- teenth International Conference on Learning Repre- sentations, ICLR 2025, Singapore, April 24-28, 2025. Jian Chen, Vashisth Tiwari, Ranajoy Sadhukhan, Zhuoming Chen, Jinyuan Shi, Ian En-Hsu Yen, and Beidi Chen. 2025. MagicDec: Breaking the Latency- Throughput Tra...
2025
-
[3]
Jun Gao, Qian Qiao, Tianxiang Wu, Zili Wang, Ziqiang Cao, and Wenjie Li
MASSV: Multimodal Adaptation and Self- Data Distillation for Speculative Decoding of Vision- Language Models.CoRR, abs/2505.10526. Jun Gao, Qian Qiao, Tianxiang Wu, Zili Wang, Ziqiang Cao, and Wenjie Li. 2025. Aim: Let any multimodal large language models embrace efficient in-context learning. InProceedings of the AAAI Conference on Artificial Intelligenc...
-
[4]
AutoJudge: Judge Decoding Without Manual Annotation.CoRR, abs/2504.20039. Songhao Han, Wei Huang, Hairong Shi, Le Zhuo, Xiu Su, Shifeng Zhang, Xu Zhou, Xiaojuan Qi, Yue Liao, and Si Liu. 2025. Videoespresso: A large-scale chain- of-thought dataset for fine-grained video reasoning via core frame selection. InProceedings of the Com- puter Vision and Pattern...
-
[5]
LLaVA-NeXT-Interleave: Tackling Multi-image, Video, and 3D in Large Multimodal Models
Fast Inference from Transformers via Specula- tive Decoding. InInternational Conference on Ma- chine Learning, ICML, volume 202 ofProceedings of Machine Learning Research, pages 19274–19286. PMLR. Bo Li, Peiyuan Zhang, Kaichen Zhang, Fanyi Pu, Xin- run Du, Yuhao Dong, Haotian Liu, Yuanhan Zhang, Ge Zhang, Chunyuan Li, and Ziwei Liu. 2024a. Lmms-eval: Acce...
work page internal anchor Pith review arXiv 2025
-
[6]
Heming Xia, Yongqi Li, Jun Zhang, Cunxiao Du, and Wenjie Li
Association for Computational Linguistics. Heming Xia, Yongqi Li, Jun Zhang, Cunxiao Du, and Wenjie Li. 2025. SWIFT: On-the-Fly Self- Speculative Decoding for LLM Inference Accelera- tion. InThe Thirteenth International Conference on Learning Representations. 12 Zhinan Xie, Peisong Wang, and Jian Cheng. 2025. HiViS: Hiding Visual Tokens from the Drafter f...
-
[7]
LongSpec: Long-Context Lossless Speculative Decoding with Efficient Drafting and Verification
LongSpec: Long-Context Speculative Decod- ing with Efficient Drafting and Verification.CoRR, abs/2502.17421. Bowen Zeng, Feiyang Ren, Jun Zhang, Xiaoling Gu, Ke Chen, Lidan Shou, and Huan Li. 2026. Hybridkv: Hybrid kv cache compression for efficient multi- modal large language model inference.Preprint, arXiv:2604.05887. Jun Zhang, Yicheng Ji, Feiyang Ren,...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[8]
an- chor
in Table 7. Here, LVSPECand SPECVLM (K= 10 ) differ only in the verification crite- rion. The comparison shows that: (i) LVSPEC surpasses SPECVLM with the same draft struc- ture in both mean accepted length ( +128%) and speedup ( +93%) solely by loosing the verifica- tion. (ii) SPECVLM’s acceleration relies heavily on the draft tree structure, whereas LVS...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.