Recognition: no theorem link
Multiscale Physics-Informed Neural Network for Complex Fluid Flows with Long-Range Dependencies
Pith reviewed 2026-05-10 19:09 UTC · model grok-4.3
The pith
Localized networks linked by one global loss solve turbulent Navier-Stokes flows with under 0.3 percent domain data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
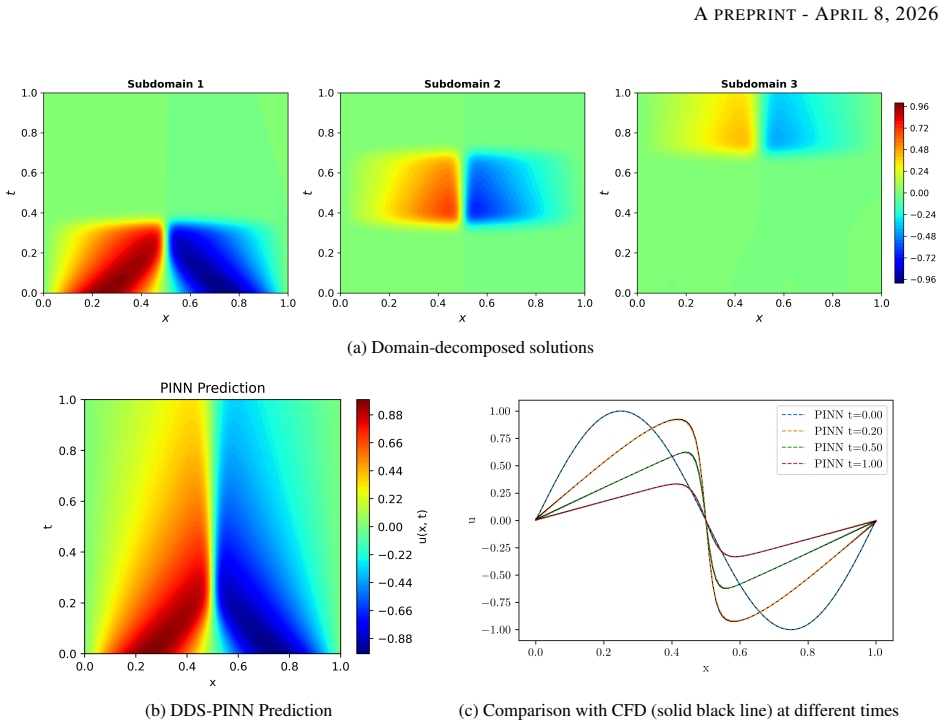
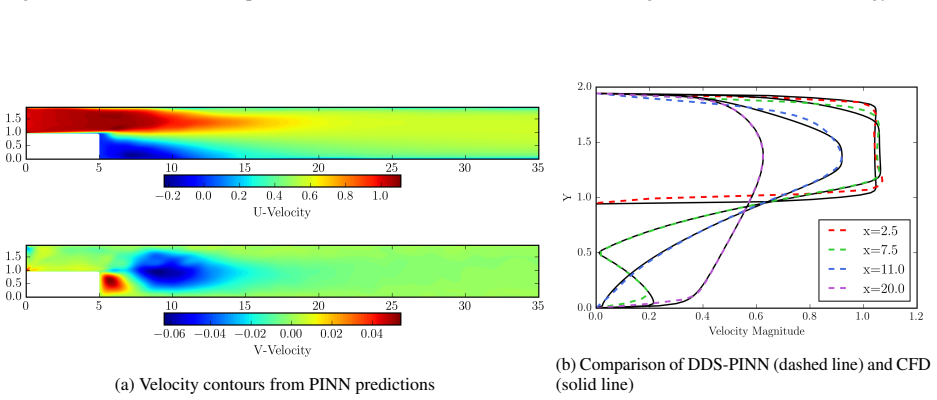
DDS-PINN resolves multiscale and long-range dependencies in the Navier-Stokes equations by training localized networks under one global physics loss. For laminar backward-facing step flow at Re=100 the method produces boundary-layer, separation, and reattachment results comparable to CFD with no data at all. For turbulent flow at Re=10,000 it reaches O(10^-4) error using only 500 randomly chosen supervision points, fewer than 0.3 percent of the domain, and exceeds the accuracy of Residual-based Attention-PINN on the same task.
What carries the argument
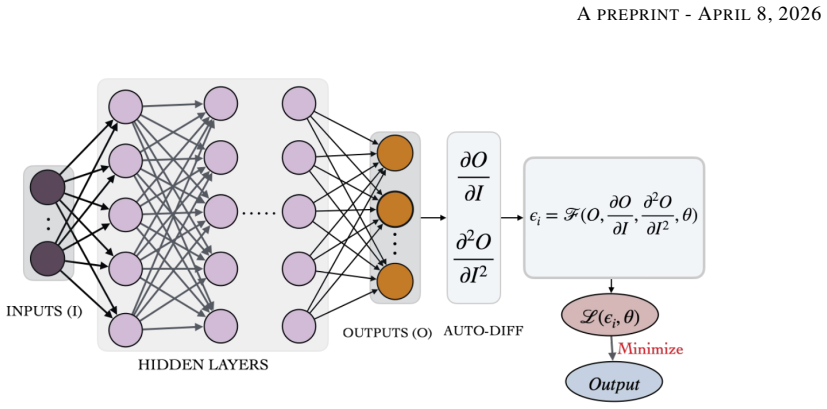
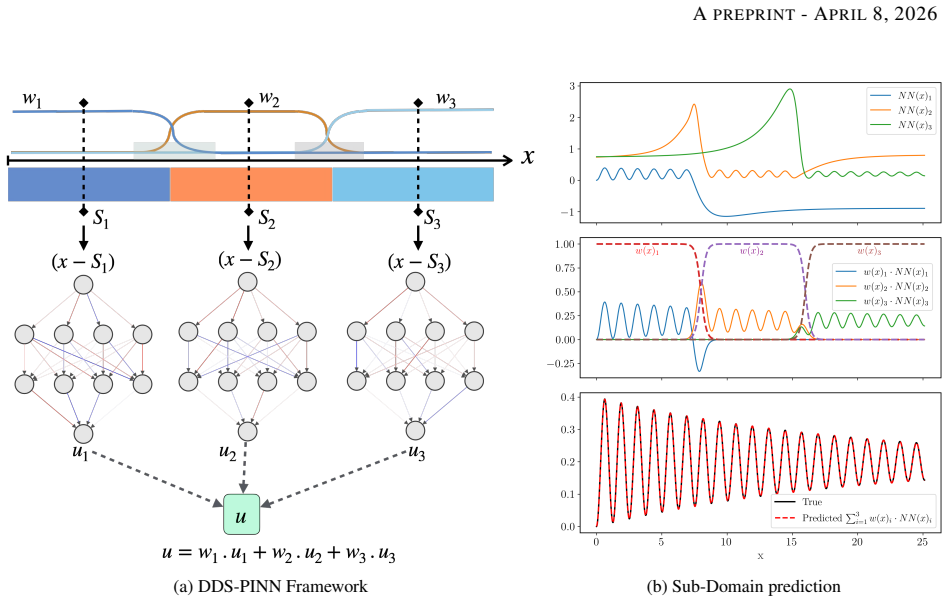
The Domain-Decomposed and Shifted Physics-Informed Neural Network (DDS-PINN), which places separate neural networks on sub-domains and couples them exclusively through a single unified global loss that enforces the governing equations everywhere.
If this is right
- Laminar Navier-Stokes problems can be solved to CFD accuracy without any labeled data.
- Turbulent cases converge to engineering tolerances with randomly placed supervision points amounting to less than 0.3 percent of the domain.
- Accuracy surpasses that of residual-attention PINN variants on the same backward-facing step benchmark.
- The framework opens a route to super-resolving complex flows from sparse experimental measurements.
Where Pith is reading between the lines
- The same decomposition pattern could be applied to other multiscale PDEs such as reacting flows or magnetohydrodynamics with only minor changes to the loss.
- Performance on flows whose longest-range effects exceed the size of individual sub-domains would directly test how far the global-loss coupling can stretch.
- Because the method is mesh-free, it could serve as a fast surrogate inside optimization loops that currently require repeated CFD solves.
Load-bearing premise
Localized networks joined only by one global loss term can capture the long-range spatial interactions that arise in turbulent Navier-Stokes flows without creating artifacts or needing heavy tuning.
What would settle it
Run DDS-PINN on the turbulent backward-facing step at Re=10,000 with the stated 500 points; if the predicted reattachment length or wall-shear distribution deviates by more than a few percent from well-validated CFD, the claim that the unified loss alone transmits long-range information fails.
Figures

read the original abstract
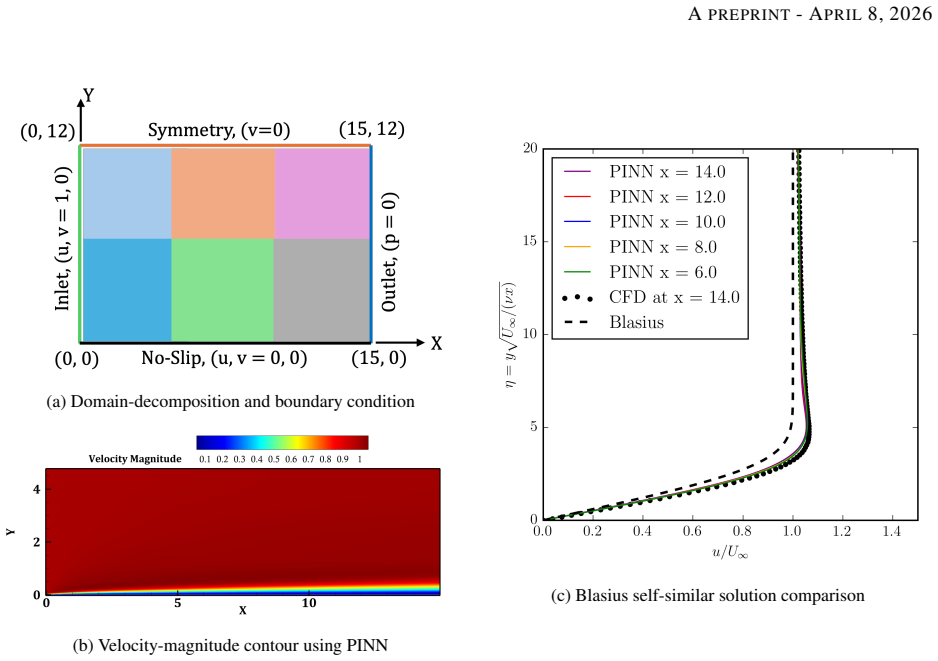
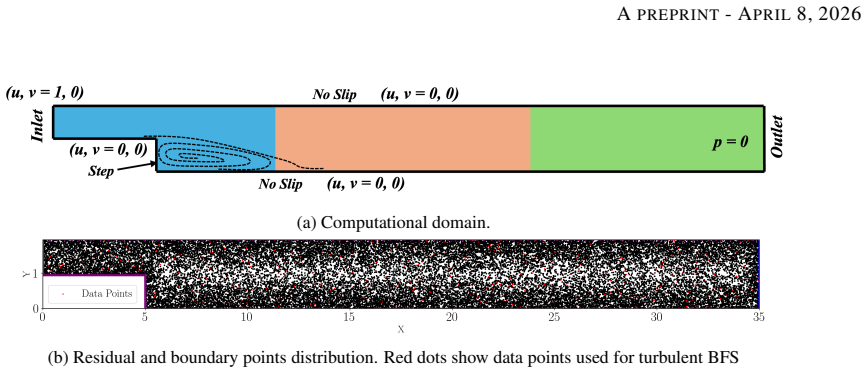
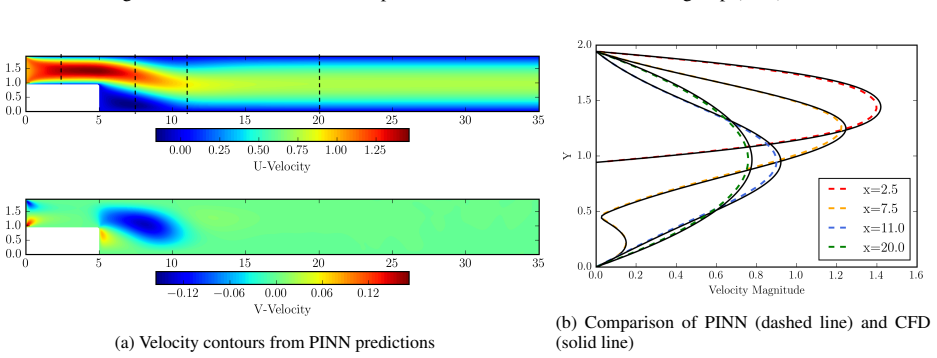
Fluid flows are governed by the nonlinear Navier-Stokes equations, which can manifest multiscale dynamics even from predictable initial conditions. Predicting such phenomena remains a formidable challenge in scientific machine learning, particularly regarding convergence speed, data requirements, and solution accuracy. In complex fluid flows, these challenges are exacerbated by long-range spatial dependencies arising from distant boundary conditions, which typically necessitate extensive supervision data to achieve acceptable results. We propose the Domain-Decomposed and Shifted Physics-Informed Neural Network (DDS-PINN), a framework designed to resolve such multiscale interactions with minimal supervision. By utilizing localized networks with a unified global loss, DDS-PINN captures global dependencies while maintaining local precision. The robustness of the approach is demonstrated across a suite of benchmarks, including a multiscale linear differential equation, the nonlinear Burgers' equation, and data-free Navier-Stokes simulations of flat-plate boundary layers. Finally, DDS-PINN is applied to the computationally challenging backward-facing step (BFS) problem; for laminar regimes (Re = 100), the model yields results comparable to computational fluid dynamics (CFD) without the need for any data, accurately predicting boundary layer thickness, separation, and reattachment lengths. For turbulent BFS flow at Re = 10,000, the framework achieves convergence to O(10^-4) using only 500 random supervision points (< 0.3 % of the total domain), outperforming established methods like Residual-based Attention-PINN in accuracy. This approach demonstrates strong potential for the super-resolution of complex turbulent flows from sparse experimental measurements.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Domain-Decomposed and Shifted Physics-Informed Neural Network (DDS-PINN), which employs localized sub-networks connected via a single unified global loss to address multiscale dynamics and long-range spatial dependencies in Navier-Stokes flows. It reports results on a multiscale linear ODE, Burgers' equation, data-free flat-plate boundary layers, and the backward-facing step (BFS) at Re=100 (data-free, comparable to CFD) and Re=10,000 (O(10^{-4}) error with 500 random points, outperforming Residual-based Attention-PINN).
Significance. If the performance claims are substantiated, the approach could meaningfully extend PINN applicability to turbulent flows with sparse supervision by reducing data needs while preserving global consistency, with potential value for super-resolution from experimental measurements.
major comments (3)
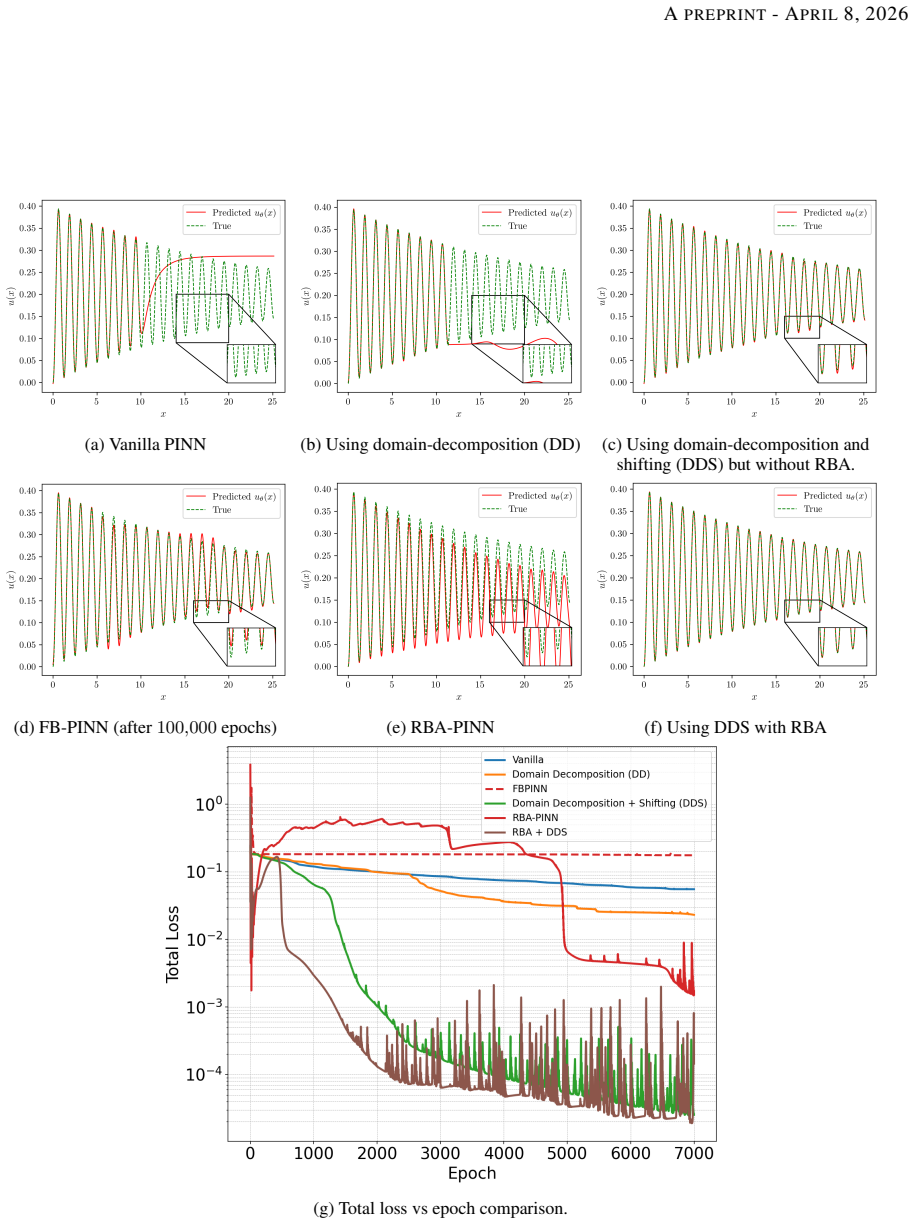
- [Abstract / BFS application] Abstract and BFS results section: The central claim that DDS-PINN reaches O(10^{-4}) error on turbulent BFS at Re=10,000 using only 500 random points (<0.3% of domain) and outperforms Residual-based Attention-PINN lacks any reported L2 errors, reattachment-length comparisons, velocity profiles, or verification that the recirculation bubble topology is recovered. Random collocation points have low probability of sampling the thin shear layer that controls reattachment, so the global loss may be satisfied without enforcing the correct long-range structure.
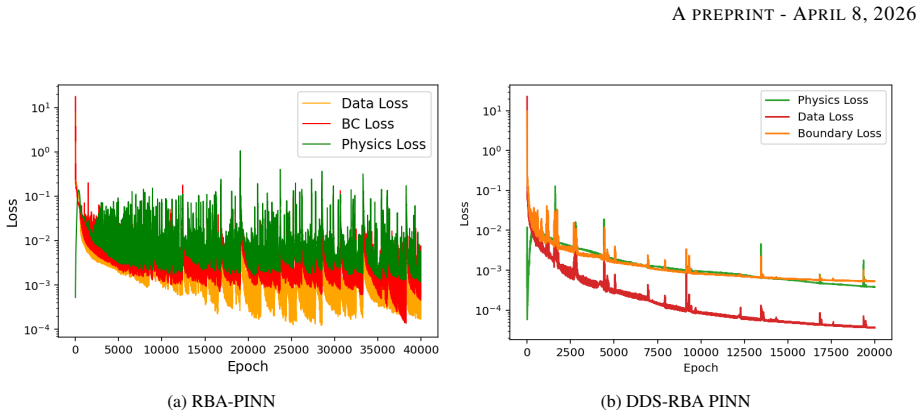
- [Method / DDS-PINN definition] DDS-PINN framework description: No explicit equations are given for the domain decomposition, the shifting operator, the precise form of the unified global loss (including any interface or continuity penalties), or the number and size of sub-networks. Without these, it is impossible to assess whether the architecture actually transmits long-range information or merely fits local residuals.
- [Laminar BFS case] Laminar BFS results: The statement that the model yields results 'comparable to CFD without any data' is not accompanied by quantitative metrics (boundary-layer thickness, separation/reattachment lengths, or error norms) or a direct side-by-side comparison, making the data-free claim unverifiable.
minor comments (2)
- [Abstract / Introduction] The abstract and introduction would benefit from a brief schematic of the DDS-PINN architecture and a table summarizing the benchmark cases with reported error norms.
- [Introduction] Standard PINN references (e.g., Raissi et al. 2019) and recent domain-decomposition PINN works should be cited to situate the novelty of the shifting mechanism.
Simulated Author's Rebuttal
We thank the referee for their thorough and constructive review. We address each major comment below and will revise the manuscript to provide the requested details, equations, and quantitative comparisons.
read point-by-point responses
-
Referee: [Abstract / BFS application] Abstract and BFS results section: The central claim that DDS-PINN reaches O(10^{-4}) error on turbulent BFS at Re=10,000 using only 500 random points (<0.3% of domain) and outperforms Residual-based Attention-PINN lacks any reported L2 errors, reattachment-length comparisons, velocity profiles, or verification that the recirculation bubble topology is recovered. Random collocation points have low probability of sampling the thin shear layer that controls reattachment, so the global loss may be satisfied without enforcing the correct long-range structure.
Authors: We agree that the abstract and results would be strengthened by explicit quantitative metrics. In the revised manuscript we will report L2 error norms for the velocity and pressure fields, provide direct comparisons of reattachment lengths against CFD benchmarks, and include velocity profiles at several streamwise stations. To address the sampling concern, we will add visualizations of the predicted recirculation bubble and error fields, together with a brief analysis showing how the unified global loss and shifting operator couple information across sub-domains, enabling recovery of the shear-layer structure even from sparse random points. revision: yes
-
Referee: [Method / DDS-PINN definition] DDS-PINN framework description: No explicit equations are given for the domain decomposition, the shifting operator, the precise form of the unified global loss (including any interface or continuity penalties), or the number and size of sub-networks. Without these, it is impossible to assess whether the architecture actually transmits long-range information or merely fits local residuals.
Authors: We acknowledge that the method section is insufficiently explicit. The revised manuscript will include the mathematical definitions of the domain decomposition into overlapping sub-domains, the coordinate-shifting operator, the exact expression for the unified global loss (with residual terms summed over all sub-networks and any interface continuity penalties), and the architecture details (number of sub-networks, layers, and neurons per network). These additions will clarify how long-range dependencies are enforced through the single global loss. revision: yes
-
Referee: [Laminar BFS case] Laminar BFS results: The statement that the model yields results 'comparable to CFD without any data' is not accompanied by quantitative metrics (boundary-layer thickness, separation/reattachment lengths, or error norms) or a direct side-by-side comparison, making the data-free claim unverifiable.
Authors: We will expand the laminar BFS section to include quantitative metrics: boundary-layer thickness, separation and reattachment lengths, and L2 error norms relative to CFD reference solutions. A table and/or figure providing direct side-by-side comparisons will be added so that the data-free performance can be verified. revision: yes
Circularity Check
No significant circularity; DDS-PINN is an architectural proposal whose performance claims rest on empirical benchmarks rather than self-referential definitions or fitted inputs.
full rationale
The paper introduces Domain-Decomposed and Shifted PINN (DDS-PINN) via localized sub-networks connected by a single global loss. Abstract and described benchmarks (multiscale linear DE, Burgers, laminar/turbulent BFS) present this as a structural modification to standard PINN training, with reported errors (O(10^{-4}) at Re=10,000 using 500 random points) treated as experimental outcomes. No equations reduce the claimed accuracy or data efficiency to a fitted parameter renamed as prediction, nor does any uniqueness theorem or self-citation chain serve as the sole justification for the architecture. Self-citations, if present for prior PINN variants, are not load-bearing for the central multiscale/long-range claim. The derivation chain is therefore self-contained against external CFD benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Fluid flows are governed by the nonlinear Navier-Stokes equations, which can manifest multiscale dynamics even from predictable initial conditions.
invented entities (1)
-
DDS-PINN (Domain-Decomposed and Shifted Physics-Informed Neural Network)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Physics informed deep learning (part ii): Data-driven discovery of nonlinear partial differential equations.arXiv e-prints, pages arXiv–1711, 2017
Maziar Raissi, Paris Perdikaris, and George Em Karniadakis. Physics informed deep learning (part ii): Data-driven discovery of nonlinear partial differential equations.arXiv e-prints, pages arXiv–1711, 2017
2017
-
[2]
Hidden fluid mechanics: Learning velocity and pressure fields from flow visualizations.Science, 367(6481):1026–1030, 2020
Maziar Raissi, Alireza Yazdani, and George Em Karniadakis. Hidden fluid mechanics: Learning velocity and pressure fields from flow visualizations.Science, 367(6481):1026–1030, 2020
2020
-
[3]
A comprehensive review of advances in physics-informed neural networks and their applications in complex fluid dynamics.Physics of Fluids, 36(10), 2024
Chi Zhao, Feifei Zhang, Wenqiang Lou, Xi Wang, and Jianyong Yang. A comprehensive review of advances in physics-informed neural networks and their applications in complex fluid dynamics.Physics of Fluids, 36(10), 2024
2024
-
[4]
Evaluation of physics-informed machine learning approach for computation of fluid flows
Prashant Kumar and Rajesh Ranjan. Evaluation of physics-informed machine learning approach for computation of fluid flows. InConference on Fluid Mechanics and Fluid Power, pages 429–440. Springer, 2025
2025
-
[5]
Physics-informed neural networks for low reynolds number flows over cylinder.Energies, 16(12):4558, 2023
Elijah Hao Wei Ang, Guangjian Wang, and Bing Feng Ng. Physics-informed neural networks for low reynolds number flows over cylinder.Energies, 16(12):4558, 2023. 14 APREPRINT- APRIL8, 2026
2023
-
[6]
Yubiao Sun, Ushnish Sengupta, and Matthew Juniper. Physics-informed deep learning for simultaneous surrogate modeling and pde-constrained optimization of an airfoil geometry.Computer Methods in Applied Mechanics and Engineering, 411: 116042, 2023
2023
-
[7]
Flow predictions behind naca 2412 aerofoil using physics-informed machine learning
Prashant Kumar and Rajesh Ranjan. Flow predictions behind naca 2412 aerofoil using physics-informed machine learning. In Proceedings of 12th International Conference on Computational Fluid Dynamics (ICCFD12), 2024
2024
-
[8]
A robust data-free physics-informed neural network for compressible flows with shocks
Prashant Kumar and Rajesh Ranjan. A robust data-free physics-informed neural network for compressible flows with shocks. Computers & Fluids, page 106975, 2026
2026
-
[9]
Surrogate modeling for fluid flows based on physics-constrained deep learning without simulation data.Computer Methods in Applied Mechanics and Engineering, 361:112732, 2020
Luning Sun, Han Gao, Shaowu Pan, and Jian-Xun Wang. Surrogate modeling for fluid flows based on physics-constrained deep learning without simulation data.Computer Methods in Applied Mechanics and Engineering, 361:112732, 2020
2020
-
[10]
On the spectral bias of neural networks
Nasim Rahaman, Aristide Baratin, Devansh Arpit, Felix Draxler, Min Lin, Fred Hamprecht, Yoshua Bengio, and Aaron Courville. On the spectral bias of neural networks. InInternational conference on machine learning, pages 5301–5310. PMLR, 2019
2019
-
[11]
Benjamin Sanderse, Panos Stinis, Romit Maulik, and Shady E Ahmed. Scientific machine learning for closure models in multiscale problems: A review.arXiv preprint arXiv:2403.02913, 2024
-
[12]
Nsfnets (Navier-Stokes flow nets): Physics-informed neural networks for the incompressible navier-stokes equations.Journal of Computational Physics, 426:109951, 2021
Xiaowei Jin, Shengze Cai, Hui Li, and George Em Karniadakis. Nsfnets (Navier-Stokes flow nets): Physics-informed neural networks for the incompressible navier-stokes equations.Journal of Computational Physics, 426:109951, 2021
2021
-
[13]
Physics-informed neural networks for solving reynolds-averaged Navier–Stokes equations.Physics of Fluids, 34(7), 2022
Hamidreza Eivazi, Mojtaba Tahani, Philipp Schlatter, and Ricardo Vinuesa. Physics-informed neural networks for solving reynolds-averaged Navier–Stokes equations.Physics of Fluids, 34(7), 2022
2022
-
[14]
Studying turbulent flows with physics-informed neural networks and sparse data.International Journal of Heat and Fluid Flow, 104:109232, 2023
Sean Hanrahan, Melissa Kozul, and Richard D Sandberg. Studying turbulent flows with physics-informed neural networks and sparse data.International Journal of Heat and Fluid Flow, 104:109232, 2023
2023
-
[15]
Data-driven discovery of turbulent flow equations using physics-informed neural networks.Physics of Fluids, 36(3), 2024
Shirindokht Yazdani and Mojtaba Tahani. Data-driven discovery of turbulent flow equations using physics-informed neural networks.Physics of Fluids, 36(3), 2024
2024
-
[16]
Jan Hauke Harmening, Franz-Josef Peitzmann, and Ould el Moctar. Effect of network architecture on physics-informed deep learning of the reynolds-averaged turbulent flow field around cylinders without training data.Frontiers in Physics, 12:1385381, 2024
2024
-
[17]
Turbulence model augmented physics-informed neural networks for mean-flow reconstruction.Physical Review Fluids, 9(3):034605, 2024
Yusuf Patel, Vincent Mons, Olivier Marquet, and Georgios Rigas. Turbulence model augmented physics-informed neural networks for mean-flow reconstruction.Physical Review Fluids, 9(3):034605, 2024
2024
-
[18]
Reconstruction of the turbulent flow field with sparse measurements using physics-informed neural network.Physics of Fluids, 36(8), 2024
Nagendra Kumar Chaurasia and Shubhankar Chakraborty. Reconstruction of the turbulent flow field with sparse measurements using physics-informed neural network.Physics of Fluids, 36(8), 2024
2024
-
[19]
High reynolds number flow over a backward-facing step: structure of the mean separation bubble.Experiments in fluids, 55(1):1657, 2014
Pankaj M Nadge and RN Govardhan. High reynolds number flow over a backward-facing step: structure of the mean separation bubble.Experiments in fluids, 55(1):1657, 2014
2014
-
[20]
Turbulence modeling for physics-informed neural networks: Comparison of different rans models for the backward-facing step flow.Fluids, 8(2):43, 2023
Fabian Pioch, Jan Hauke Harmening, Andreas Maximilian Müller, Franz-Josef Peitzmann, Dieter Schramm, and Ould el Moctar. Turbulence modeling for physics-informed neural networks: Comparison of different rans models for the backward-facing step flow.Fluids, 8(2):43, 2023
2023
-
[21]
Neural operator: Learning maps between function spaces with applications to pdes.Journal of Machine Learning Research, 24(89):1–97, 2023
Nikola Kovachki, Zongyi Li, Burigede Liu, Kamyar Azizzadenesheli, Kaushik Bhattacharya, Andrew Stuart, and Anima Anandkumar. Neural operator: Learning maps between function spaces with applications to pdes.Journal of Machine Learning Research, 24(89):1–97, 2023
2023
-
[22]
Fourier neural operator with learned deformations for pdes on general geometries.Journal of Machine Learning Research, 24(388):1–26, 2023
Zongyi Li, Daniel Zhengyu Huang, Burigede Liu, and Anima Anandkumar. Fourier neural operator with learned deformations for pdes on general geometries.Journal of Machine Learning Research, 24(388):1–26, 2023
2023
-
[23]
Zongyi Li, Nikola Kovachki, Kamyar Azizzadenesheli, Burigede Liu, Kaushik Bhattacharya, Andrew Stuart, and Anima Anandkumar. Neural operator: Graph kernel network for partial differential equations.arXiv preprint arXiv:2003.03485, 2020
-
[24]
Huakun Luo, Haixu Wu, Hang Zhou, Lanxiang Xing, Yichen Di, Jianmin Wang, and Mingsheng Long. Transolver++: An accurate neural solver for pdes on million-scale geometries.arXiv preprint arXiv:2502.02414, 2025
-
[25]
doi:https://doi.org/10.1016/j.jcp.2022.111722
Levi D. McClenny and Ulisses M. Braga-Neto. Self-adaptive physics-informed neural networks.Journal of Computational Physics, 474:111722, February 2023. ISSN 0021-9991. doi: 10.1016/j.jcp.2022.111722. URL http://dx.doi.org/10. 1016/j.jcp.2022.111722
-
[26]
Residual-based attention in physics-informed neural networks.Computer Methods in Applied Mechanics and Engineering, 421:116805, 2024
Sokratis J Anagnostopoulos, Juan Diego Toscano, Nikolaos Stergiopulos, and George Em Karniadakis. Residual-based attention in physics-informed neural networks.Computer Methods in Applied Mechanics and Engineering, 421:116805, 2024
2024
-
[27]
Distributed learning machines for solving forward and inverse problems in partial differential equations.Neurocomputing, 420:299–316, 2021
Vikas Dwivedi, Nishant Parashar, and Balaji Srinivasan. Distributed learning machines for solving forward and inverse problems in partial differential equations.Neurocomputing, 420:299–316, 2021
2021
-
[28]
Ben Moseley, Andrew Markham, and Tarje Nissen-Meyer. Finite basis physics-informed neural networks (fbpinns): a scalable domain decomposition approach for solving differential equations.Advances in Computational Mathematics, 49(4):62, 2023
2023
-
[29]
Neural tangent kernel: Convergence and generalization in neural networks
Arthur Jacot, Franck Gabriel, and Clément Hongler. Neural tangent kernel: Convergence and generalization in neural networks. Advances in neural information processing systems, 31, 2018. 15 APREPRINT- APRIL8, 2026
2018
-
[30]
Spectral bias in physics-informed and operator learning: Analysis and mitigation guidelines
Siavash Khodakarami, Vivek Oommen, Nazanin Ahmadi Daryakenari, Maxim Beekenkamp, and George Em Karniadakis. Spectral bias in physics-informed and operator learning: Analysis and mitigation guidelines.arXiv preprint arXiv:2602.19265, 2026
-
[31]
The numerical computation of turbulent flows
Brian Edward Launder and Dudley Brian Spalding. The numerical computation of turbulent flows. InNumerical prediction of flow, heat transfer, turbulence and combustion, pages 96–116. Elsevier, 1983. A 2D steady, Incompressible RANS equations withk-ϵturbulence model Reynolds-Averaged Navier-Stokes (RANS) equations for 2D steady, incompressible flow solve me...
1983
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.