Recognition: 2 theorem links
· Lean TheoremEfficient machine unlearning with minimax optimality
Pith reviewed 2026-05-10 19:18 UTC · model grok-4.3
The pith
Unlearning Least Squares achieves minimax optimality for estimating remaining data model parameters under squared loss using only the pre-trained estimator, forget samples, and a small subsample.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
For squared loss, Unlearning Least Squares (ULS) is minimax optimal for estimating the model parameter of the remaining data when only the pre-trained estimator, forget samples, and a small subsample of the remaining data are available. The estimation error decomposes into an oracle term and an unlearning cost determined by the forget proportion and the forget model bias. Asymptotically valid inference procedures are established without requiring full retraining.
What carries the argument
Unlearning Least Squares (ULS), a procedure that adjusts the pre-trained estimator with forget-set information and a subsample of retained data to recover the optimal parameter estimate for the remaining data.
Load-bearing premise
The minimax optimality result requires squared loss together with access to a small subsample of the remaining data in addition to the pre-trained model and forget set.
What would settle it
If the estimation error of ULS exceeds the derived minimax lower bound by more than a constant factor in experiments with squared loss, or if it fails to approach full-retraining performance when the forget proportion and bias are varied, the optimality claim would be refuted.
Figures


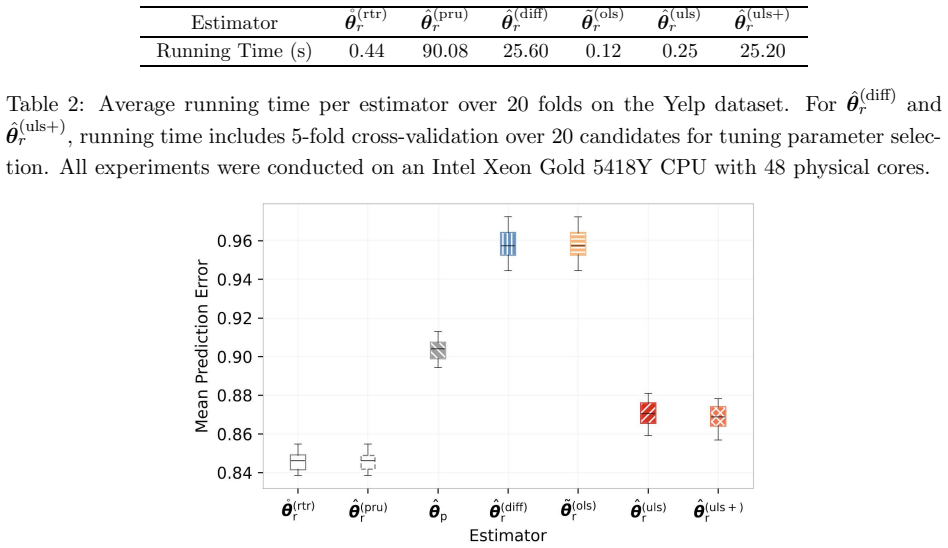
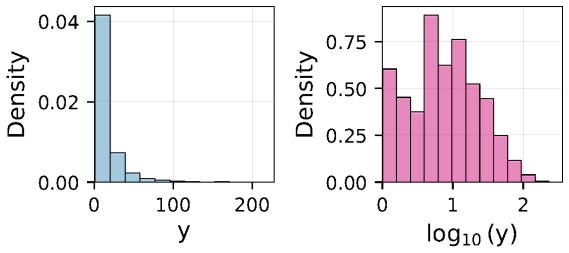







read the original abstract
There is a growing demand for efficient data removal to comply with regulations like the GDPR and to mitigate the influence of biased or corrupted data. This has motivated the field of machine unlearning, which aims to eliminate the influence of specific data subsets without the cost of full retraining. In this work, we propose a statistical framework for machine unlearning with generic loss functions and establish theoretical guarantees. For squared loss, especially, we develop Unlearning Least Squares (ULS) and establish its minimax optimality for estimating the model parameter of remaining data when only the pre-trained estimator, forget samples, and a small subsample of the remaining data are available. Our results reveal that the estimation error decomposes into an oracle term and an unlearning cost determined by the forget proportion and the forget model bias. We further establish asymptotically valid inference procedures without requiring full retraining. Numerical experiments and real-data applications demonstrate that the proposed method achieves performance close to retraining while requiring substantially less data access.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript develops a statistical framework for machine unlearning applicable to generic loss functions. For squared loss it introduces Unlearning Least Squares (ULS), which uses only the pre-trained estimator, the forget set, and a small subsample of the remaining data to estimate the parameter on the remaining data. The paper claims minimax optimality for this estimator, an error decomposition into an oracle term plus an unlearning cost governed by forget proportion and forget-model bias, asymptotically valid inference without retraining, and empirical performance close to full retraining.
Significance. If the minimax optimality holds after correctly treating the dependence structure, the work would be a notable contribution to efficient unlearning: it supplies both a practical algorithm with limited data access and strong theoretical rates, together with inference procedures. The explicit error decomposition and the generic-loss extension are useful organizing ideas. The manuscript provides theoretical guarantees and reproducible-style numerical experiments.
major comments (1)
- The central minimax-optimality claim for ULS (stated in the abstract and developed in the theoretical sections) requires that the joint distribution of the pre-trained estimator and the subsample of remaining data be properly characterized. Because the pre-trained estimator was fit on the entire training set, it is statistically dependent on every point in the subsample. The error decomposition into oracle term plus unlearning cost, as well as the matching upper and lower bounds, must therefore condition on or recenter for this dependence (e.g., via leave-one-out adjustments or influence-function corrections inside the subsample). If the analysis proceeds under an implicit independence assumption, both the claimed rate and the minimax lower bound are at risk of being invalid under the stated data-access model. Please supply the precise conditioning argument or adjustment used in the main
minor comments (2)
- Clarify the precise subsample size (as a fraction of remaining data) required for the optimality result to hold; the abstract only says “small subsample.”
- In the generic-loss section, list all regularity conditions (e.g., strong convexity, smoothness, bounded moments) in one place so that the scope of the non-squared-loss guarantees is immediately visible.
Simulated Author's Rebuttal
We thank the referee for their careful reading and constructive comments, which identify an important technical point about dependence in the data-access model. We address the major comment below and will revise the manuscript accordingly to strengthen the theoretical presentation.
read point-by-point responses
-
Referee: The central minimax-optimality claim for ULS (stated in the abstract and developed in the theoretical sections) requires that the joint distribution of the pre-trained estimator and the subsample of remaining data be properly characterized. Because the pre-trained estimator was fit on the entire training set, it is statistically dependent on every point in the subsample. The error decomposition into oracle term plus unlearning cost, as well as the matching upper and lower bounds, must therefore condition on or recenter for this dependence (e.g., via leave-one-out adjustments or influence-function corrections inside the subsample). If the analysis proceeds under an implicit independence assumption, both the claimed rate and the minimax lower bound are at risk of being invalid under the stated data-access model. Please supply the precise conditioning argument or adjustment used in the main
Authors: We agree that the dependence between the pre-trained estimator and the subsample must be handled explicitly and thank the referee for this observation. In the current analysis the error decomposition and rates are derived conditionally on the pre-trained estimator, with the ULS correction term formed from the forget set and the small subsample of remaining data. The oracle term corresponds to the estimation error that would be achieved by retraining on the remaining data, while the unlearning cost isolates the additional error arising from limited access. To make the joint distribution fully rigorous, we will revise the theoretical sections to incorporate an explicit influence-function recentering step inside the subsample (or an equivalent leave-one-out adjustment). This adjustment removes the first-order dependence on each subsample point and yields the same asymptotic rates. The minimax lower bound will be restated under the same conditional information structure. These changes clarify the argument without altering the main claims or rates. revision: yes
Circularity Check
No significant circularity; derivation rests on external statistical benchmarks
full rationale
The paper develops a generic-loss framework and, for squared loss, the ULS estimator whose error is decomposed into an oracle term plus an unlearning cost governed by forget proportion and bias. The minimax optimality claim is asserted via this decomposition and standard lower-bound arguments rather than any self-definitional reduction, fitted-input-as-prediction, or load-bearing self-citation chain. No equations in the provided text equate the target optimality rate to a quantity defined from the same fitted objects by construction. The dependence between pre-trained estimator and subsample is a potential correctness issue but does not trigger any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
estimation error decomposes into an oracle term and an unlearning cost determined by the forget proportion and the forget model bias
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
ULS achieves minimax optimality for estimating the model parameter of remaining data
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
A. Anjarlekar and S. Pombra. Llm unlearning using gradient ratio-based influence estimation and noise injection. arXiv preprint arXiv:2508.06467, 2025
-
[2]
Balakrishnan, M
S. Balakrishnan, M. J. Wainwright, and B. Yu. Statistical guarantees for the em algorithm: From population to sample-based analysis. The Annals of Statistics, 45 0 (1): 0 77--120, 2017
2017
-
[3]
Brophy and D
J. Brophy and D. Lowd. Machine unlearning for random forests. In International Conference on Machine Learning, pages 1092--1104. PMLR, 2021
2021
-
[4]
T. T. Cai and H. Wei. Transfer learning for nonparametric classification. The Annals of Statistics, 49 0 (1): 0 100--128, 2021
2021
-
[5]
Cao and J
Y. Cao and J. Yang. Towards making systems forget with machine unlearning. In 2015 IEEE symposium on security and privacy, pages 463--480. IEEE, 2015
2015
-
[6]
R. D. Cook and S. Weisberg. Residuals and influence in regression. 1982
1982
-
[7]
F. M. Dekking. A Modern Introduction to Probability and Statistics: Understanding why and how. Springer Science & Business Media, 2005
2005
- [8]
-
[9]
Ginart, M
A. Ginart, M. Guan, G. Valiant, and J. Y. Zou. Making ai forget you: Data deletion in machine learning. Advances in neural information processing systems, 32, 2019
2019
-
[10]
Graves, V
L. Graves, V. Nagisetty, and V. Ganesh. Amnesiac machine learning. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 35, pages 11516--11524, 2021
2021
-
[11]
C. Guo, T. Goldstein, A. Hannun, and L. Van Der Maaten. Certified data removal from machine learning models. In International Conference on Machine Learning, pages 3832--3842. PMLR, 2020
2020
-
[12]
Z. He, T. Li, X. Cheng, Z. Huang, and X. Huang. Towards natural machine unlearning. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
2025
-
[13]
Z. Izzo, M. A. Smart, K. Chaudhuri, and J. Zou. Approximate data deletion from machine learning models. In International conference on artificial intelligence and statistics, pages 2008--2016. PMLR, 2021
2008
- [14]
-
[15]
A. K. Kuchibhotla and A. Chakrabortty. Moving beyond sub-gaussianity in high-dimensional statistics: Applications in covariance estimation and linear regression. Information and Inference: A Journal of the IMA, 11 0 (4): 0 1389--1456, 2022
2022
-
[16]
N. Li, A. Pan, A. Gopal, S. Yue, D. Berrios, A. Gatti, J. D. Li, A.-K. Dombrowski, S. Goel, L. Phan, et al. The wmdp benchmark: Measuring and reducing malicious use with unlearning. arXiv preprint arXiv:2403.03218, 2024 a
work page internal anchor Pith review arXiv 2024
-
[17]
S. Li, T. T. Cai, and H. Li. Transfer learning for high-dimensional linear regression: Prediction, estimation and minimax optimality. Journal of the Royal Statistical Society Series B: Statistical Methodology, 84 0 (1): 0 149--173, 2022
2022
-
[18]
S. Li, L. Zhang, T. T. Cai, and H. Li. Estimation and inference for high-dimensional generalized linear models with knowledge transfer. Journal of the American Statistical Association, 119 0 (546): 0 1274--1285, 2024 b
2024
-
[19]
H. Lin, J. W. Chung, Y. Lao, and W. Zhao. Machine unlearning in gradient boosting decision trees. In Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pages 1374--1383, 2023
2023
-
[20]
B. Liu, Q. Liu, and P. Stone. Continual learning and private unlearning. In Conference on Lifelong Learning Agents, pages 243--254. PMLR, 2022
2022
-
[21]
S. Liu, Y. Yao, J. Jia, S. Casper, N. Baracaldo, P. Hase, Y. Yao, C. Y. Liu, X. Xu, H. Li, et al. Rethinking machine unlearning for large language models. Nature Machine Intelligence, pages 1--14, 2025 a
2025
-
[22]
Y. Liu, H. Chen, W. Huang, Y. Ni, and M. Imani. Recover-to-forget: Gradient reconstruction from lo RA for efficient LLM unlearning. In Socially Responsible and Trustworthy Foundation Models at NeurIPS 2025, 2025 b . URL https://openreview.net/forum?id=n7peBaPUmk
2025
-
[24]
The right to be forgotten in federated learning: An efficient realization with rapid retraining
P. Maini, Z. Feng, A. Schwarzschild, Z. C. Lipton, and J. Z. Kolter. Tofu: A task of fictitious unlearning for llms. arXiv preprint arXiv:2401.06121, 2024
-
[25]
S. Neel, A. Roth, and S. Sharifi-Malvajerdi. Descent-to-delete: Gradient-based methods for machine unlearning. In Algorithmic Learning Theory, pages 931--962. PMLR, 2021
2021
-
[26]
Nesterov et al
Y. Nesterov et al. Lectures on convex optimization, volume 137. Springer, 2018
2018
-
[27]
Nguyen, H.-P
T.-H. Nguyen, H.-P. Vu, D. T. Nguyen, T. M. Nguyen, K. D. Doan, and K.-S. Wong. Empirical study of federated unlearning: Efficiency and effectiveness. In Asian Conference on Machine Learning, pages 959--974. PMLR, 2024
2024
-
[28]
H. W. Reeve, T. I. Cannings, and R. J. Samworth. Adaptive transfer learning. The Annals of Statistics, 49 0 (6): 0 3618--3649, 2021
2021
-
[29]
Sekhari, J
A. Sekhari, J. Acharya, G. Kamath, and A. T. Suresh. Remember what you want to forget: Algorithms for machine unlearning. Advances in Neural Information Processing Systems, 34: 0 18075--18086, 2021
2021
-
[30]
Shaik, X
T. Shaik, X. Tao, H. Xie, L. Li, X. Zhu, and Q. Li. Exploring the landscape of machine unlearning: A comprehensive survey and taxonomy. IEEE Transactions on Neural Networks and Learning Systems, 2024
2024
-
[31]
Sudlow, J
C. Sudlow, J. Gallacher, N. Allen, V. Beral, P. Burton, J. Danesh, P. Downey, P. Elliott, J. Green, M. Landray, et al. Uk biobank: an open access resource for identifying the causes of a wide range of complex diseases of middle and old age. PLoS medicine, 12 0 (3): 0 e1001779, 2015
2015
-
[32]
Tian and Y
Y. Tian and Y. Feng. Transfer learning under high-dimensional generalized linear models. Journal of the American Statistical Association, 118 0 (544): 0 2684--2697, 2023
2023
-
[33]
Tibshirani
R. Tibshirani. Regression shrinkage and selection via the lasso. Journal of the Royal Statistical Society Series B: Statistical Methodology, 58 0 (1): 0 267--288, 1996
1996
-
[34]
Vershynin
R. Vershynin. High-dimensional probability: An introduction with applications in data science, volume 47. Cambridge university press, 2018
2018
-
[35]
Q. Wang, J. P. Zhou, Z. Zhou, S. Shin, B. Han, and K. Q. Weinberger. Rethinking LLM unlearning objectives: A gradient perspective and go beyond. In The Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net/forum?id=huo8MqVH6t
2025
-
[36]
Y. Wu, E. Dobriban, and S. Davidson. Deltagrad: Rapid retraining of machine learning models. In International Conference on Machine Learning, pages 10355--10366. PMLR, 2020
2020
-
[37]
P. Yang, Q. Wang, Z. Huang, T. Liu, C. Zhang, and B. Han. Exploring criteria of loss reweighting to enhance LLM unlearning. In Forty-second International Conference on Machine Learning, 2025. URL https://openreview.net/forum?id=mGOugCZlAq
2025
-
[38]
Y. Yao, X. Xu, and Y. Liu. Large language model unlearning. Advances in Neural Information Processing Systems, 37: 0 105425--105475, 2024
2024
-
[39]
Zhang, L
R. Zhang, L. Lin, Y. Bai, and S. Mei. Negative preference optimization: From catastrophic collapse to effective unlearning. CoRR, 2024
2024
-
[40]
Zhang, J
X. Zhang, J. Zhao, and Y. LeCun. Character-level convolutional networks for text classification. Advances in neural information processing systems, 28, 2015
2015
-
[41]
Statistical guarantees for the em algorithm: From population to sample-based analysis
Sivaraman Balakrishnan, Martin J Wainwright, and Bin Yu. Statistical guarantees for the em algorithm: From population to sample-based analysis. The Annals of Statistics, 45 0 (1): 0 77--120, 2017
2017
-
[42]
Lectures on convex optimization, volume 137
Yurii Nesterov et al. Lectures on convex optimization, volume 137. Springer, 2018
2018
-
[43]
High-dimensional probability: An introduction with applications in data science, volume 47
Roman Vershynin. High-dimensional probability: An introduction with applications in data science, volume 47. Cambridge university press, 2018
2018
-
[44]
Moving beyond sub-gaussianity in high-dimensional statistics: Applications in covariance estimation and linear regression
Arun Kumar Kuchibhotla and Abhishek Chakrabortty. Moving beyond sub-gaussianity in high-dimensional statistics: Applications in covariance estimation and linear regression. Information and Inference: A Journal of the IMA, 11 0 (4): 0 1389--1456, 2022
2022
-
[45]
High-probability minimax lower bounds,
Tianyi Ma, Kabir A Verchand, and Richard J Samworth. High-probability minimax lower bounds. arXiv preprint arXiv:2406.13447, 2024
-
[46]
Regression shrinkage and selection via the lasso
Robert Tibshirani. Regression shrinkage and selection via the lasso. Journal of the Royal Statistical Society Series B: Statistical Methodology, 58 0 (1): 0 267--288, 1996
1996
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.