Publish and Perish: How AI-Accelerated Writing Without Proportional Verification Investment Degrades Scientific Knowledge
Pith reviewed 2026-05-10 18:49 UTC · model grok-4.3
The pith
AI-accelerated writing without matching review acceleration degrades scientific knowledge output after a brief peak.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that writing AI adoption increases submissions and review queue size, which endogenously drives reviewer AI adoption under pressure, degrading verification quality and causing knowledge output to peak temporarily before settling at a lower steady state when review acceleration lags writing acceleration.
What carries the argument
A minimal two-variable ordinary differential equation model coupling review queue evolution to verification quality degradation via an endogenous, queue-pressure-driven review AI adoption mechanism.
Load-bearing premise
The assumption that review quality will degrade endogenously as queue pressure causes reviewers to adopt AI tools at rates that reduce verification effectiveness.
What would settle it
Tracking of submission volumes, error rates in published work, and net knowledge indicators through 2030 showing sustained rise or stability past the predicted 2028 onset instead of the modeled decline.
Figures


read the original abstract
Artificial intelligence tools are accelerating manuscript production far faster than peer review capacity can expand. Applying the theory of constraints from manufacturing science, we formalize this asymmetry through a minimal two-variable ordinary differential equation model coupling review queue evolution and verification quality degradation via an endogenous, queue-pressure-driven review AI adoption mechanism. The causal chain is: writing AI adoption increases submissions, growing the review queue, which drives reviewer AI adoption under pressure, degrading verification quality and reducing net knowledge output. Under empirically informed parameters (writing acceleration {\gamma} = 2.0, review acceleration {\delta} = 0.5), the model predicts a deceptive honeymoon where knowledge output peaks at 1.10K0 (circa 2026), followed by paradox onset at t = 6 years (2028) and long-term degradation to 0.68K0 (32% loss), approaching a steady state of 0.60K0 (40% loss). The critical condition for net benefit is {\delta} > {\gamma}; the current operating point lies deep in the paradox regime. Empirical validation against NeurIPS, ICLR, arXiv, and bioRxiv submission data shows qualitative consistency with observed post-ChatGPT acceleration patterns. Policy analysis reveals that only combined interventions such as review infrastructure investment paired with institutional quality standards can restore positive knowledge production.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
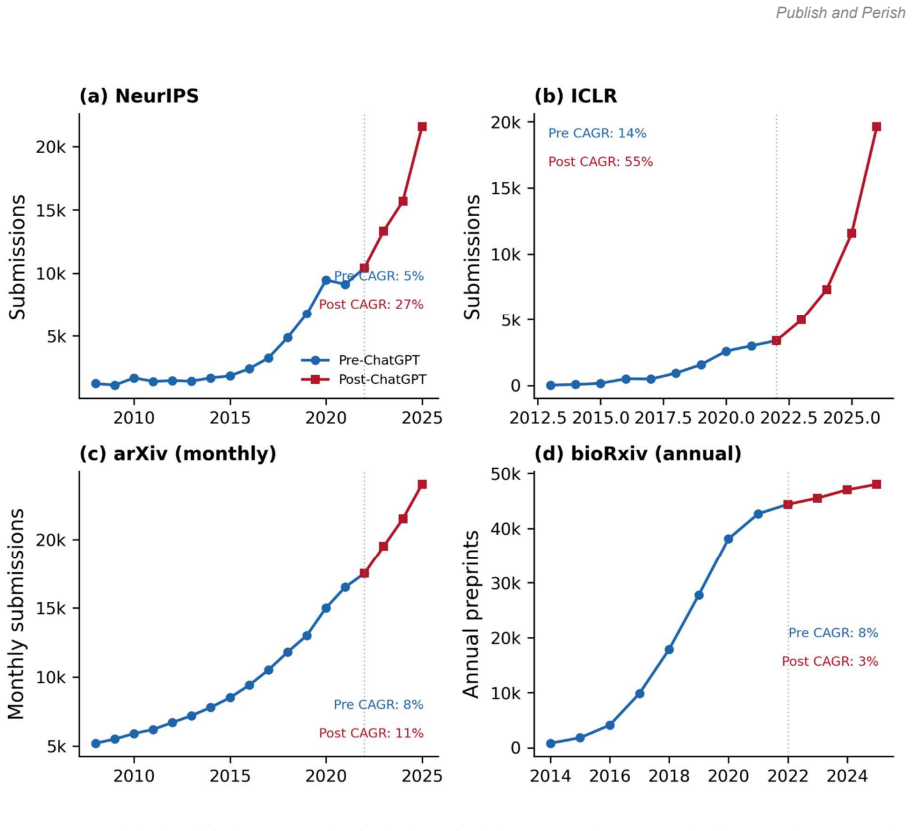
Summary. The paper claims that AI-accelerated writing outpaces verification capacity, creating a 'publish and perish' dynamic that degrades net scientific knowledge. It formalizes this via a minimal two-variable ODE model coupling submission queue growth to endogenous review-quality degradation through queue-pressure-driven reviewer AI adoption. With parameters γ=2.0 (writing acceleration) and δ=0.5 (review acceleration), the model predicts a short-term 'honeymoon' peak in knowledge output at 1.10K0 circa 2026, followed by paradox onset at t=6 years and long-term decline to a steady state of 0.60K0 (40% loss). Qualitative consistency is shown with post-ChatGPT submission trends from NeurIPS, ICLR, arXiv, and bioRxiv; the critical condition for net benefit is stated as δ > γ, with current parameters deep in the paradox regime. Policy conclusions favor combined infrastructure investment and quality standards.
Significance. If the modeling assumptions hold, the work supplies a transparent, minimal dynamical framework that isolates the asymmetry between writing and review acceleration and identifies a clear threshold condition (δ > γ) for sustained knowledge production. The approach is a strength in its use of theory-of-constraints logic to generate falsifiable trajectories and policy implications. However, the significance is tempered by the absence of empirical grounding for the key endogenous degradation term and lack of sensitivity or uncertainty quantification around the 40% loss prediction.
major comments (4)
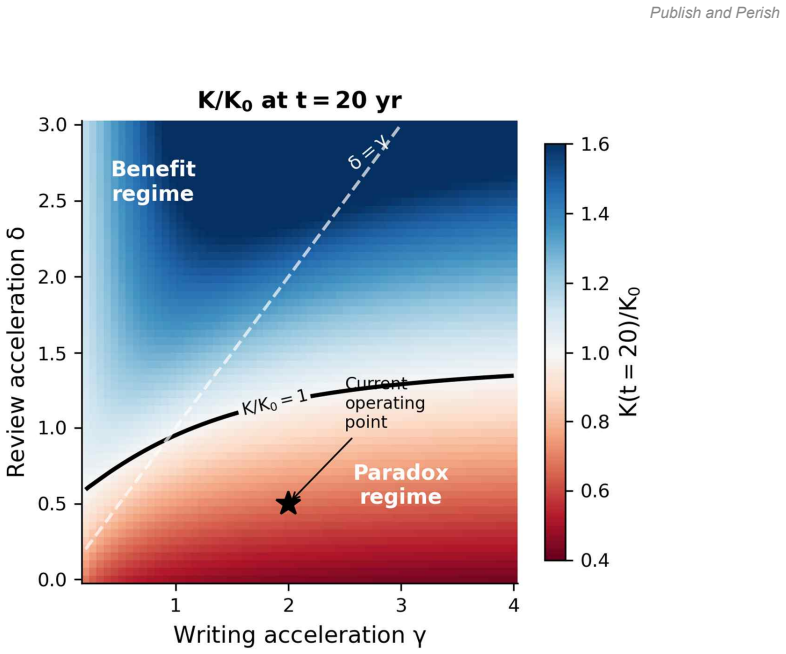
- [ODE model] The two-variable ODE system (model equations in the main text): the verification-quality degradation term is introduced by assumption as an endogenous, queue-pressure-driven reviewer AI adoption mechanism rather than derived from data on review times, rejection rates, or post-publication quality metrics. This functional form and the specific value δ=0.5 are load-bearing for the central claim of long-term degradation to 0.60K0; if the mapping from queue length to quality loss is weaker or absent, the critical condition δ > γ is satisfied and the 40% loss does not occur.
- [Results and parameter selection] Parameter choice and results section: γ=2.0 and δ=0.5 are described as 'empirically informed' yet no data sources, fitting procedure, or calibration against review-quality indicators are supplied. The quantitative predictions (peak at 1.10K0, steady state 0.60K0) are generated directly by the same equations that embed these hand-chosen values, creating circularity; no sensitivity analysis or error bounds on the 40% loss figure are reported.
- [Empirical validation] Empirical validation paragraph: consistency with NeurIPS, ICLR, arXiv, and bioRxiv submission-volume trends is stated as qualitative only, with no quantitative fit statistics, statistical tests, or comparison to alternative models. This leaves the support for the predicted honeymoon and degradation trajectories weak relative to the strength of the policy conclusions drawn.
- [Abstract] Abstract: the text reports both 'degradation to 0.68K0 (32% loss)' and 'steady state of 0.60K0 (40% loss)' without clarifying the distinction or reconciling the two figures; this internal inconsistency affects the precision of the headline claim.
minor comments (2)
- [Model setup] The baseline notation K0 is used throughout but should be defined explicitly on first use in the main text for readers unfamiliar with the normalization.
- [Abstract and results] The abstract and results use slightly varying loss percentages (32% vs 40%); a single consistent figure or explicit explanation of the difference would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each of the major comments point by point below, indicating where revisions will be made to strengthen the paper.
read point-by-point responses
-
Referee: [ODE model] The verification-quality degradation term is introduced by assumption as an endogenous, queue-pressure-driven reviewer AI adoption mechanism rather than derived from data on review times, rejection rates, or post-publication quality metrics. This functional form and the specific value δ=0.5 are load-bearing for the central claim of long-term degradation to 0.60K0.
Authors: As a minimal model in the spirit of sociophysics, the degradation term is posited to encapsulate the theory-of-constraints logic without claiming empirical derivation. We will revise the text to more explicitly label this as a core modeling assumption, discuss its sensitivity to alternative forms, and outline potential empirical validation strategies using review time or quality data. The threshold condition δ > γ is a structural result of the model. revision: partial
-
Referee: [Results and parameter selection] γ=2.0 and δ=0.5 are described as 'empirically informed' yet no data sources, fitting procedure, or calibration against review-quality indicators are supplied. No sensitivity analysis or error bounds on the 40% loss figure are reported.
Authors: We agree that the parameters are illustrative choices informed by observed submission growth rates rather than a formal fit. We will add a dedicated sensitivity analysis subsection varying γ and δ around these values and report the resulting range of steady-state knowledge levels to provide uncertainty bounds. revision: yes
-
Referee: [Empirical validation] Consistency with NeurIPS, ICLR, arXiv, and bioRxiv submission-volume trends is stated as qualitative only, with no quantitative fit statistics, statistical tests, or comparison to alternative models.
Authors: The validation is deliberately qualitative to demonstrate consistency with post-ChatGPT trends in multiple venues. We will expand this section with additional descriptive statistics on the trends and explicitly note the absence of quantitative model fitting due to the focus on dynamical insight rather than prediction. revision: partial
-
Referee: [Abstract] The text reports both 'degradation to 0.68K0 (32% loss)' and 'steady state of 0.60K0 (40% loss)' without clarifying the distinction or reconciling the two figures.
Authors: This is an oversight in the abstract wording. The 0.68K0 represents the knowledge level at the onset of the paradox phase, while 0.60K0 is the long-term steady state. We will revise the abstract to clearly distinguish these and use consistent figures. revision: yes
Circularity Check
No circularity: model outputs are forward simulations under explicit parameter choices
full rationale
The paper constructs an explicit two-variable ODE model whose outputs (honeymoon peak, onset time, steady-state value) are obtained by integrating the system forward under the stated parameter values γ=2.0 and δ=0.5. These numerical results are not equivalent to the inputs by construction; they depend on the specific functional forms chosen for queue growth and quality degradation. The critical condition δ > γ is stated separately as a model property, and the parameter values are presented as externally informed rather than fitted to the target degradation metric. No self-definitional loop, fitted-input-as-prediction, or self-citation load-bearing step is exhibited in the quoted material. The derivation chain therefore remains self-contained.
Axiom & Free-Parameter Ledger
free parameters (2)
- γ (writing acceleration) =
2.0
- δ (review acceleration) =
0.5
axioms (1)
- domain assumption Writing AI adoption increases submissions, which grows the review queue and endogenously drives reviewer AI adoption under pressure, which in turn degrades verification quality.
Reference graph
Works this paper leans on
-
[1]
Publish and Perish 1 Publish and Perish: How AI-Accelerated Writing Without Proportional Verification Investment Degrades Scientific Knowledge S. Joon Kwon1 School of Chemical Engineering, Department of Semiconductor Convergence Engineering, Department of Future Energy Engineering, Department of Quantum Information Engineering, & SKKU Institute of Energy ...
work page 2026
-
[2]
Model Formulation 2.1. Causal chain and design philosophy The model is deliberately minimal: two state variables (review queue Q and verification quality q), one external input (writing AI penetration φw(t)), and one endogenous coupling (review AI penetration φr(t)). The one-directional causal chain can be described as φw(t)↑ → S↑ → Q↑ → φr(Q)↑ → q↓ → K↓ ...
work page 2025
-
[3]
Model parameters, values, and justifications Symbol Value Definition Justification γ 2.0 Writing acceleration factor Amdahl lower bound = 0.3-0.7; empirical NeurIPS CAGR supports = 2.0 (includes community growth) δ 0.5 Review acceleration factor AI automates approximately 30% of review mechanics leading to net 50% speedup on that fraction Qc 2.0 Queue hal...
work page 2020
-
[4]
Results 3.1. System dynamics Figure 1 presents the baseline simulation over a 20-year horizon (initial point t = 0 at November 2022 (ChatGPT release date)). Under baseline parameters (Q0 = 0, q0 = 1.0, representing the pre-AI equilibrium), the model predicts a two-phase trajectory. The first phase is about deceptive honeymoon (t = 0-6 yr, 2022-2028). In t...
work page 2022
-
[5]
A definitive causal test would require within-venue variation in AI tool access, which is not currently available. The model’s γ = 2.0 likely overstates the AI-tool-specific contribution; however, the qualitative prediction of differential acceleration by AI-tool-adoption intensity is supported. On the review side, the model predicts φr = 0.15-0.20 by yea...
work page 2024
-
[6]
incentivize thorough reviews, since reviewing is currently uncompensated labor. Open peer review (publishing reviews alongside papers) deters low-effort AI-generated reviews, as several journals (i.e., eLife, EMBO, F1000Research) already demonstrate [26]. For funders and institutions, the model reveals that volume-based quantitative metrics (papers per ye...
work page 2020
-
[7]
The critical condition is δ > γ: review acceleration must exceed writing acceleration
before declining to 0.68K0 at 20 years (32% knowledge loss) and approaching an analytical steady state of 0.60K0 (40% loss). The critical condition is δ > γ: review acceleration must exceed writing acceleration. Currently, γ = 2.0 while δ = 0.5, placing academic publishing firmly in the paradox regime leading to knowledge degradation. The paradox is not i...
work page 2008
-
[8]
ICLR submissions: 2013-2026 data from Paper Copilot and OpenReview [21]
and Paper Copilot [20]. ICLR submissions: 2013-2026 data from Paper Copilot and OpenReview [21]. arXiv submissions: monthly rates from arxiv.org [22]. bioRxiv preprints: annual totals [23]. ICLR AI review detection rates from [1, 2]. Nature AI usage survey from [4]. Peer review crisis reports from [16-18]. Code availability. Model implementation: Python 3...
work page 2013
-
[9]
Liang, W. et al. Monitoring AI-modified content at scale: a case study on the impact of ChatGPT on AI conference peer reviews. arXiv 2403.07183 (2024)
work page internal anchor Pith review arXiv 2024
- [10]
-
[11]
Checco, A. et al. AI-assisted peer review. Humanit. Soc. Sci. Commun. 8, 25 (2021)
work page 2021
-
[12]
More than half of researchers now use AI for peer review—often against guidance
Nature News. More than half of researchers now use AI for peer review—often against guidance. Nature 648, 16 (2025)
work page 2025
-
[13]
Huang, J. et al. The rise of AI-generated scientific text. Science 382, 1316–1318 (2023)
work page 2023
-
[14]
Barnett, A. et al. Mass-manufactured research on UK Biobank overwhelms legitimate work. J. Clin. Epidemiol. (2026)
work page 2026
-
[15]
Barnett, A. & Spick, M. Research integrity is locked into an arms race with agentic AI slop. LSE Impact Blog (2026)
work page 2026
-
[16]
Goldratt, E. M. The Goal: A Process of Ongoing Improvement (North River Press, 1984)
work page 1984
-
[17]
AI reviewers are here—we are not ready
Nature News. AI reviewers are here—we are not ready. Nature 648, 9 (2025)
work page 2025
-
[18]
The WyCash portfolio management system
Cunningham, W. The WyCash portfolio management system. OOPSLA ’92 Experience Report (1992)
work page 1992
-
[19]
Kruchten, P., Nord, R. L. & Ozkaya, I. Managing Technical Debt (Addison-Wesley, 2019)
work page 2019
- [20]
-
[21]
Ioannidis, J. P. A. Why most published research findings are false. PLoS Med. 2, e124 (2005)
work page 2005
-
[22]
1,500 scientists lift the lid on reproducibility
Baker, M. 1,500 scientists lift the lid on reproducibility. Nature 533, 452–454 (2016)
work page 2016
-
[23]
Errington, T. M. et al. Investigating the replicability of preclinical cancer biology. eLife 10, e71601 (2021)
work page 2021
-
[24]
The peer-review crisis: how to fix an overloaded system
Nature News. The peer-review crisis: how to fix an overloaded system. Nature 631, 7 (2025)
work page 2025
-
[25]
Prophy.ai Blog (2025)
work page 2025
- [26]
-
[27]
Reflections on the 2025 review process from the program committee chairs (2025)
NeurIPS Blog. Reflections on the 2025 review process from the program committee chairs (2025)
work page 2025
-
[28]
Paper Copilot. NeurIPS statistics. https://papercopilot.com/statistics/neurips-statistics/ (accessed Publish and Perish 14 2026)
work page 2026
-
[29]
Paper Copilot. ICLR statistics. https://papercopilot.com/statistics/iclr-statistics/ (accessed 2026)
work page 2026
-
[30]
arXiv. Submission rate statistics. https://arxiv.org/stats/monthly_submissions (accessed 2026)
work page 2026
-
[31]
How bioRxiv changed the way biologists share ideas—in numbers
Nature News. How bioRxiv changed the way biologists share ideas—in numbers. Nature 637, 412 (2026)
work page 2026
-
[32]
Kaltenbrunner, W. & Birch, K. Post-publication peer review: challenges and opportunities. Learn. Publ. 35, 274–282 (2022)
work page 2022
-
[33]
Open evaluation: a vision for entirely transparent post-publication peer review
Kriegeskorte, N. Open evaluation: a vision for entirely transparent post-publication peer review. Front. Comput. Neurosci. 6, 79 (2012)
work page 2012
-
[34]
AI is transforming peer review—and many scientists are worried
Nature News. AI is transforming peer review—and many scientists are worried. Nature 629, 14 (2025)
work page 2025
-
[35]
Munafò, M. R. et al. A manifesto for reproducible science. Nat. Hum. Behav. 1, 0021 (2017). Publish and Perish 15 Figure Captions Figure
work page 2017
-
[36]
(a) AI adoption in writing (φw, external logistic) and in review (φr, endogenous, queue-driven)
Model dynamics of the Publish and Perish paradox. (a) AI adoption in writing (φw, external logistic) and in review (φr, endogenous, queue-driven). (b) Submission rate S(t), review throughput R(t), and review queue Q(t) (right axis, dashed). (c) Verification quality q(t), with analytical steady state qss = 0.40 and quality floor qmin = 0.20 marked. (d) Nor...
work page 2026
-
[37]
Empirical validation. Annual submissions for (a) NeurIPS (2008-2025), (b) ICLR (2013-2026), (c) arXiv monthly (2008-2025), and (d) bioRxiv annual (2014-2025). Circles: pre-ChatGPT data; squares: post-ChatGPT data. CAGR shown for each period. AI-intensive venues (a-c) accelerated post-ChatGPT; bioRxiv (d) decelerated, providing a suggestive comparison. Dat...
work page 2008
-
[38]
(a) Effect of review acceleration δ on K(t)/K0 over 20 years (year 2022-2042)
Policy lever analysis. (a) Effect of review acceleration δ on K(t)/K0 over 20 years (year 2022-2042). Baseline δ = 0.5 (bold red); critical threshold δ = 2.0 (green) restores K ≈ K0. (b) Effect of quality floor qmin on K(t)/K0. Higher institutional standards (qmin = 0.4-0.6) significantly mitigate knowledge loss
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.