Recognition: 3 theorem links
· Lean TheoremFoleyDesigner: Immersive Stereo Foley Generation with Precise Spatio-Temporal Alignment for Film Clips
Pith reviewed 2026-05-10 18:53 UTC · model grok-4.3
The pith
FoleyDesigner generates stereo Foley audio with precise spatial and temporal alignment to film clips using multi-agent analysis and diffusion models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors claim that a multi-agent architecture for extracting spatio-temporal information from video, combined with latent diffusion models conditioned on those cues and LLM-driven hybrid mechanisms, produces immersive stereo Foley audio that achieves better alignment with film actions than prior methods while remaining compatible with professional standards including ITU-R BS.775 5.1-channel systems and allowing interactive user control.
What carries the argument
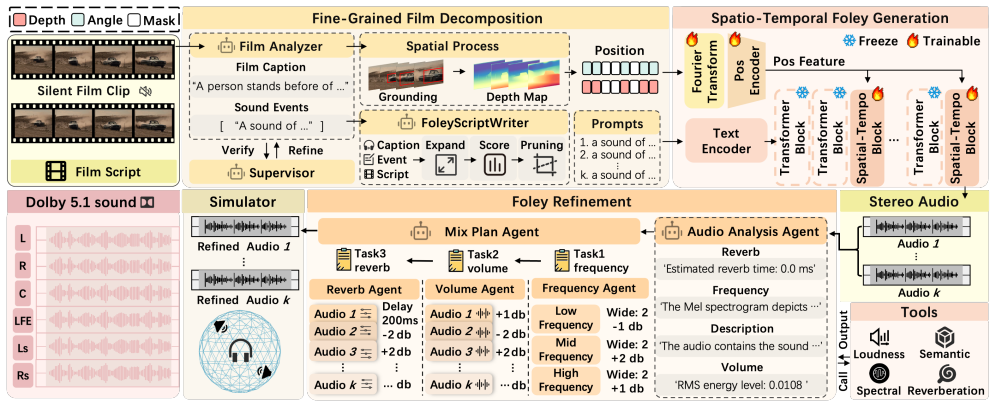
Multi-agent architecture for film clip analysis paired with latent diffusion models trained on spatio-temporal cues extracted from video frames and LLM hybrid mechanisms for generation and mixing.
If this is right
- Superior spatio-temporal alignment relative to existing baselines in experiments.
- Direct compatibility with professional film pipelines including 5.1 Dolby Atmos output.
- Support for interactive user adjustments during generation.
- Release of the FilmStereo dataset with spatial metadata, timestamps, and semantic labels for eight Foley categories.
Where Pith is reading between the lines
- The approach could shorten the post-production timeline for sound teams by handling initial alignment automatically.
- Techniques for conditioning audio generation on video cues may transfer to other synchronized media such as games or live events.
- The dataset could serve as a benchmark for testing future models on spatial audio quality and alignment accuracy.
Load-bearing premise
The multi-agent analysis and diffusion models trained on video cues will reliably output high-quality stereo Foley without artifacts or the need for substantial manual fixes to meet professional alignment standards.
What would settle it
A side-by-side listening test by professional sound engineers on identical film clips, comparing generated tracks against manually produced Foley for measurable timing or position mismatches and audible artifacts.
Figures









read the original abstract
Foley art plays a pivotal role in enhancing immersive auditory experiences in film, yet manual creation of spatio-temporally aligned audio remains labor-intensive. We propose FoleyDesigner, a novel framework inspired by professional Foley workflows, integrating film clip analysis, spatio-temporally controllable Foley generation, and professional audio mixing capabilities. FoleyDesigner employs a multi-agent architecture for precise spatio-temporal analysis. It achieves spatio-temporal alignment through latent diffusion models trained on spatio-temporal cues extracted from video frames, combined with large language model (LLM)-driven hybrid mechanisms that emulate post-production practices in film industry. To address the lack of high-quality stereo audio datasets in film, we introduce FilmStereo, the first professional stereo audio dataset containing spatial metadata, precise timestamps, and semantic annotations for eight common Foley categories. For applications, the framework supports interactive user control while maintaining seamless integration with professional pipelines, including 5.1-channel Dolby Atmos systems compliant with ITU-R BS.775 standards, thereby offering extensive creative flexibility. Extensive experiments demonstrate that our method achieves superior spatio-temporal alignment compared to existing baselines, with seamless compatibility with professional film production standards. The project page is available at https://gekiii996.github.io/FoleyDesigner/ .
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes FoleyDesigner, a multi-agent framework for generating immersive stereo Foley audio with precise spatio-temporal alignment to film clips. It integrates video analysis, latent diffusion models conditioned on spatio-temporal cues from frames, and LLM-driven hybrid mechanisms to emulate professional post-production practices. The authors introduce the FilmStereo dataset, the first professional stereo audio collection with spatial metadata, precise timestamps, and semantic annotations for eight common Foley categories. The central claim is that the method achieves superior spatio-temporal alignment over baselines while maintaining seamless compatibility with professional pipelines, including 5.1-channel Dolby Atmos systems compliant with ITU-R BS.775.
Significance. If the performance claims hold under rigorous evaluation, the work could meaningfully reduce the labor intensity of manual Foley creation in film while preserving creative control and industry-standard output quality. The FilmStereo dataset addresses a clear gap in high-quality, annotated stereo audio-visual data and could serve as a reusable benchmark for future audio generation research. The multi-agent design and explicit support for professional mixing tools represent a practical strength that aligns the technical approach with real-world workflows.
major comments (1)
- [Experiments section] Experiments section: No objective, reproducible metric for spatio-temporal alignment is defined (e.g., onset timing error in ms combined with azimuth error derived from stereo intensity ratios or binaural cues). No numerical results, baseline comparisons, error bars, or statistical tests are reported, which directly undermines the load-bearing claim of superior alignment and professional-standard compatibility.
Simulated Author's Rebuttal
We thank the referee for their thorough review and constructive feedback on our manuscript. We address the major comment below and will revise the paper to strengthen the experimental section with more rigorous quantitative evaluation.
read point-by-point responses
-
Referee: [Experiments section] Experiments section: No objective, reproducible metric for spatio-temporal alignment is defined (e.g., onset timing error in ms combined with azimuth error derived from stereo intensity ratios or binaural cues). No numerical results, baseline comparisons, error bars, or statistical tests are reported, which directly undermines the load-bearing claim of superior alignment and professional-standard compatibility.
Authors: We agree that the current Experiments section lacks explicit objective and reproducible metrics for spatio-temporal alignment, as well as numerical results, baseline comparisons, error bars, and statistical tests. This is a valid criticism that weakens the support for our central claims. In the revised manuscript, we will introduce specific metrics such as onset timing error (in ms) and azimuth error derived from stereo intensity ratios or binaural cues. We will report numerical results comparing our method against baselines, include error bars, and apply appropriate statistical tests to demonstrate superior alignment and compatibility with professional standards. revision: yes
Circularity Check
No significant circularity; claims rest on new dataset and external experiments
full rationale
The paper introduces FilmStereo as a new dataset and a multi-agent + latent diffusion architecture for Foley generation. The central claims of superior spatio-temporal alignment are asserted via 'extensive experiments' against baselines rather than any derivation that reduces by construction to fitted parameters, self-defined metrics, or a self-citation chain. No equations or sections in the provided text exhibit self-definitional loops, fitted-input-as-prediction, or uniqueness imported from prior author work. The derivation chain is therefore self-contained against external benchmarks.
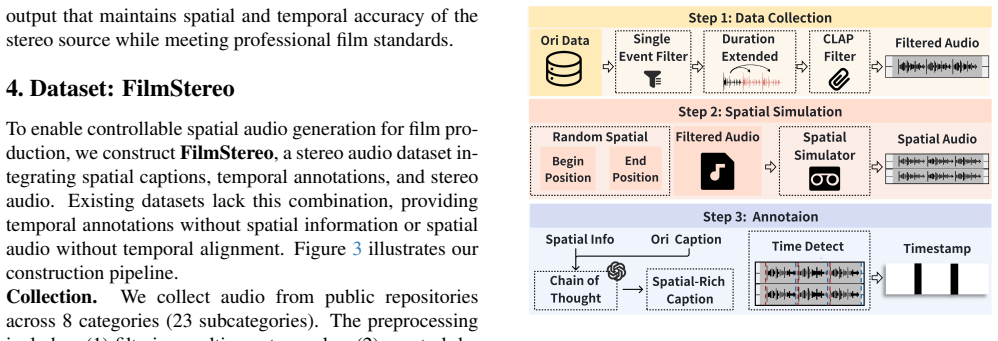
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We introduce a novel spatio-temporal injection mechanism that conditions a Diffusion Transformer on sound event trajectories extracted from visual tracking, achieving frame-accurate spatio-temporal alignment with visual motion.
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
FoleyDesigner employs a multi-agent architecture for precise spatio-temporal analysis... multi-agent framework with Tree-of-Thought reasoning
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We build upon Stable Audio Open, a DiT-based latent diffusion model, conditioning it on text prompt and spatio-temporal cues P... Fourier feature transformation
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Qwen2.5-vl technical report, 2025
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhao- hai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Junyang Lin. Qwen2.5-vl technical report,...
2025
-
[2]
An improved event- independent network for polyphonic sound event localiza- tion and detection
Yin Cao, Turab Iqbal, Qiuqiang Kong, Fengyan An, Wenwu Wang, and Mark D Plumbley. An improved event- independent network for polyphonic sound event localiza- tion and detection. InProceedings of the IEEE Interna- tional Conference on Acoustics, Speech and Signal Process- ing (ICASSP), pages 885–889. IEEE, 2021. 3
2021
-
[3]
Video-guided foley sound generation with multimodal con- trols
Ziyang Chen, Prem Seetharaman, Bryan Russell, Oriol Ni- eto, David Bourgin, Andrew Owens, and Justin Salamon. Video-guided foley sound generation with multimodal con- trols. In2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 18770–18781, 2025. 2
2025
-
[4]
Ho Kei Cheng, Masato Ishii, Akio Hayakawa, Takashi Shibuya, Alexander Schwing, and Yuki Mitsufuji. Tam- ing multimodal joint training for high-quality video-to-audio synthesis.arXiv preprint arXiv:2412.15322, 2024. 2
-
[5]
Qwen-Audio: Advancing Universal Audio Understanding via Unified Large-Scale Audio-Language Models
Yunfei Chu, Jin Xu, Xiaohuan Zhou, Qian Yang, Shil- iang Zhang, Zhijie Yan, Chang Zhou, and Jingren Zhou. Qwen-audio: Advancing universal audio understanding via unified large-scale audio-language models.arXiv preprint arXiv:2311.07919, 2023. 5, 6
work page internal anchor Pith review arXiv 2023
-
[6]
Sim- ple and controllable music generation.Advances in Neural Information Processing Systems, 36:47704–47720, 2023
Jade Copet, Felix Kreuk, Itai Gat, Tal Remez, David Kant, Gabriel Synnaeve, Yossi Adi, and Alexandre D´efossez. Sim- ple and controllable music generation.Advances in Neural Information Processing Systems, 36:47704–47720, 2023. 3
2023
-
[7]
SEE-2-SOUND: Zero-shot spatial environment-to-spatial sound.arXiv preprint arXiv:2406.06612, 2024
Rishit Dagli, Shivesh Prakash, Robert Wu, and Houman Khosravani. SEE-2-SOUND: Zero-shot spatial environment-to-spatial sound.arXiv preprint arXiv:2406.06612, 2024. 2, 3, 7, 8
-
[8]
David Diaz-Guerra, Antonio Miguel, and Jose R. Beltran. gpurir: A python library for room impulse response simula- tion with gpu acceleration.Multimedia Tools and Applica- tions, 80(4):5653–5671, 2020. 6
2020
-
[9]
CLIPSonic: Text-to-audio synthesis with unlabeled videos and pretrained language- vision models
Hao-Wen Dong, Xiaoyu Liu, Jordi Pons, Gautam Bhat- tacharya, Santiago Pascual, Joan Serr `a, Taylor Berg- Kirkpatrick, and Julian McAuley. CLIPSonic: Text-to-audio synthesis with unlabeled videos and pretrained language- vision models. In2023 IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA), pages 1–5. IEEE, 2023. 2
2023
-
[10]
Conditional generation of audio from video via foley analogies
Yuexi Du, Ziyang Chen, Justin Salamon, Bryan Russell, and Andrew Owens. Conditional generation of audio from video via foley analogies. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 2426–2436, 2023. 2
2023
-
[11]
Stable audio open
Zach Evans, Julian D Parker, CJ Carr, Zack Zukowski, Josiah Taylor, and Jordi Pons. Stable audio open. InProceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1–5. IEEE, 2025. 2, 3, 5, 6, 7, 8
2025
-
[12]
Rishabh Garg, Ruohan Gao, and Kristen Grauman. Geometry-aware multi-task learning for binaural audio gen- eration from video.arXiv preprint arXiv:2111.10882, 2021. 3
-
[13]
Imagebind one embedding space to bind them all
Rohit Girdhar, Alaaeldin El-Nouby, Zhuang Liu, Mannat Singh, Kalyan Vasudev Alwala, Armand Joulin, and Ishan Misra. Imagebind one embedding space to bind them all. In 2023 IEEE/CVF Conference on Computer Vision and Pat- tern Recognition (CVPR), pages 15180–15190, 2023. 6
2023
-
[14]
Gans trained by a two time-scale update rule converge to a local nash equilib- rium, 2018
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilib- rium, 2018. 6
2018
-
[15]
Spotlight- ing partially visible cinematic language for video-to-audio generation via self-distillation
Feizhen Huang, Yu Wu, Yutian Lin, and Bo Du. Spotlight- ing partially visible cinematic language for video-to-audio generation via self-distillation. InProceedings of the Thirty- Fourth International Joint Conference on Artificial Intelli- gence, IJCAI-25, pages 1170–1178. International Joint Con- ferences on Artificial Intelligence Organization, 2025. Ma...
2025
-
[16]
Make-an-audio 2: Temporal-enhanced text-to-audio generation.arXiv preprint arXiv:2305.18474, 2023a
Jia-Bin Huang, Yi Ren, Rongjie Huang, Dongchao Yang, Zhenhui Ye, Chen Zhang, Jinglin Liu, Xiang Yin, Zejun Ma, and Zhou Zhao. Make-an-audio 2: Temporal-enhanced text- to-audio generation.ArXiv, abs/2305.18474, 2023. 2
-
[17]
Synchformer: Efficient synchronization from sparse cues
Vladimir Iashin, Weidi Xie, Esa Rahtu, and Andrew Zisser- man. Synchformer: Efficient synchronization from sparse cues. InProceedings of the IEEE International Confer- ence on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2024. 6
2024
-
[18]
Multichannel stereophonic sound system with and without accompanying picture
ITU-R. Multichannel stereophonic sound system with and without accompanying picture. Technical report, Interna- tional Telecommunication Union, 2012. Recommendation ITU-R BS.775-3. 5
2012
-
[19]
Fr\’echet audio distance: A metric for evaluating music enhancement algo- rithms,
Kevin Kilgour, Mauricio Zuluaga, Dominik Roblek, and Matthew Sharifi. Fr ´echet audio distance: A metric for evaluating music enhancement algorithms.ArXiv, abs/1812.08466, 2018. 6
-
[20]
Audiogen: Textually guided audio gen- eration.arXiv preprint arXiv:2209.15352, 2022
Felix Kreuk, Gabriel Synnaeve, Adam Polyak, Uriel Singer, Alexandre D ´efossez, Jade Copet, Devi Parikh, Yaniv Taig- man, and Yossi Adi. Audiogen: Textually guided audio gen- eration.arXiv preprint arXiv:2209.15352, 2022. 2
-
[21]
Junwon Lee, Jaekwon Im, Dabin Kim, and Juhan Nam. Video-Foley: Two-Stage Video-To-Sound generation via temporal event condition for foley sound.arXiv preprint arXiv:2408.11915, 2024. 2
-
[22]
Audioldm: Text-to-audio generation with latent diffusion models,
Haohe Liu, Zehua Chen, Yi Yuan, Xinhao Mei, Xubo Liu, Danilo Mandic, Wenwu Wang, and Mark D Plumbley. Audi- oLDM: Text-to-audio generation with latent diffusion mod- els.arXiv preprint arXiv:2301.12503, 2023. 2
-
[23]
Plumbley
Haohe Liu, Yi Yuan, Xubo Liu, Xinhao Mei, Qiuqiang Kong, Qiao Tian, Yuping Wang, Wenwu Wang, Yuxuan Wang, and Mark D. Plumbley. AudioLDM 2: Learning Holistic Audio Generation With Self-Supervised Pretraining.IEEE/ACM Transactions on Audio, Speech, and Language Processing, 32:2871–2883, 2024. 2
2024
-
[24]
Omniaudio: Generating spatial audio from 360-degree video.ArXiv, abs/2504.14906, 2025
Huadai Liu, Tianyi Luo, Qikai Jiang, Kaicheng Luo, Peiwen Sun, Jialei Wan, Rongjie Huang, Qian Chen, Wen Wang, Xi- angtai Li, Shiliang Zhang, Zhijie Yan, Zhou Zhao, and Wei Xue. Omniaudio: Generating spatial audio from 360-degree video.ArXiv, abs/2504.14906, 2025. 3
-
[25]
Visu- ally guided binaural audio generation with cross-modal con- sistency
Miao Liu, Jing Wang, Xinyuan Qian, and Xiang Xie. Visu- ally guided binaural audio generation with cross-modal con- sistency. InProceedings of the IEEE International Confer- ence on Acoustics, Speech and Signal Processing (ICASSP), pages 7980–7984. IEEE, 2024. 3
2024
-
[26]
Diff-Foley: Synchronized video-to-audio synthesis with la- tent diffusion models.Advances in Neural Information Pro- cessing Systems, 36:48855–48876, 2023
Simian Luo, Chuanhao Yan, Chenxu Hu, and Hang Zhao. Diff-Foley: Synchronized video-to-audio synthesis with la- tent diffusion models.Advances in Neural Information Pro- cessing Systems, 36:48855–48876, 2023. 3
2023
-
[27]
Tango 2: Aligning diffusion-based text-to-audio generations through direct preference optimization
Navonil Majumder, Chia-Yu Hung, Deepanway Ghosal, Wei-Ning Hsu, Rada Mihalcea, and Soujanya Poria. Tango 2: Aligning diffusion-based text-to-audio generations through direct preference optimization. InProceedings of the 32nd ACM International Conference on Multimedia, pages 564–572, 2024. 2
2024
-
[28]
A probabilistic model for robust localization based on a binau- ral auditory front-end.IEEE Transactions on Audio, Speech, and Language Processing, 19(1):1–13, 2010
Tobias May, Steven Van De Par, and Armin Kohlrausch. A probabilistic model for robust localization based on a binau- ral auditory front-end.IEEE Transactions on Audio, Speech, and Language Processing, 19(1):1–13, 2010. 3
2010
-
[29]
Beyond mono to binaural: Generating binaural audio from mono audio with depth and cross modal atten- tion
Kranti Kumar Parida, Siddharth Srivastava, and Gaurav Sharma. Beyond mono to binaural: Generating binaural audio from mono audio with depth and cross modal atten- tion. In2022 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), pages 2151–2160, 2022. 2, 3
2022
-
[30]
Improved techniques for training gans
Tim Salimans, Ian Goodfellow, Wojciech Zaremba, Vicki Cheung, Alec Radford, and Xi Chen. Improved techniques for training gans. InProceedings of the 30th International Conference on Neural Information Processing Systems, page 2234–2242, Red Hook, NY , USA, 2016. Curran Associates Inc. 6
2016
-
[31]
I hear your true colors: Image guided audio generation
Roy Sheffer and Yossi Adi. I hear your true colors: Image guided audio generation. InProceedings of the 2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1–5. IEEE, 2023. 2
2023
-
[32]
Peiwen Sun, Sitong Cheng, Xiangtai Li, Zhen Ye, Huadai Liu, Honggang Zhang, Wei Xue, and Yike Guo. Both ears wide open: Towards language-driven spatial audio genera- tion.arXiv preprint arXiv:2410.10676, 2024. 2, 3, 6, 7, 8
-
[33]
Fourier features let networks learn high frequency functions in low dimen- sional domains.Advances in Neural Information Processing Systems, 33:7537–7547, 2020
Matthew Tancik, Pratul Srinivasan, Ben Mildenhall, Sara Fridovich-Keil, Nithin Raghavan, Utkarsh Singhal, Ravi Ra- mamoorthi, Jonathan Barron, and Ren Ng. Fourier features let networks learn high frequency functions in low dimen- sional domains.Advances in Neural Information Processing Systems, 33:7537–7547, 2020. 5
2020
-
[34]
V2a-mapper: A lightweight solution for vision-to-audio generation by connecting foun- dation models
Heng Wang, Jianbo Ma, Santiago Pascual, Richard Cartwright, and Weidong Cai. V2a-mapper: A lightweight solution for vision-to-audio generation by connecting foun- dation models. InProceedings of the AAAI Conference on Artificial Intelligence, pages 15492–15501, 2024. 2
2024
-
[35]
Frieren: Efficient video-to-audio generation network with rectified flow matching.Advances in Neural Information Processing Systems, 37:128118–128138, 2024
Yongqi Wang, Wenxiang Guo, Rongjie Huang, Jiawei Huang, Zehan Wang, Fuming You, Ruiqi Li, and Zhou Zhao. Frieren: Efficient video-to-audio generation network with rectified flow matching.Advances in Neural Information Processing Systems, 37:128118–128138, 2024. 2
2024
-
[36]
Large-scale con- trastive language-audio pretraining with feature fusion and keyword-to-caption augmentation
Yusong Wu, Ke Chen, Tianyu Zhang, Yuchen Hui, Taylor Berg-Kirkpatrick, and Shlomo Dubnov. Large-scale con- trastive language-audio pretraining with feature fusion and keyword-to-caption augmentation. InProceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1–5, 2023. 6
2023
-
[37]
Son- icVisionLM: Playing sound with vision language models
Zhifeng Xie, Shengye Yu, Qile He, and Mengtian Li. Son- icVisionLM: Playing sound with vision language models. In Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition, pages 26866–26875, 2024. 4
2024
-
[38]
Depth any- thing v2.Advances in Neural Information Processing Sys- tems, 37:21875–21911, 2024
Lihe Yang, Bingyi Kang, Zilong Huang, Zhen Zhao, Xiao- gang Xu, Jiashi Feng, and Hengshuang Zhao. Depth any- thing v2.Advances in Neural Information Processing Sys- tems, 37:21875–21911, 2024. 4
2024
-
[39]
Deepear: Sound local- ization with binaural microphones.IEEE Transactions on Mobile Computing, 23(1):359–375, 2022
Qiang Yang and Yuanqing Zheng. Deepear: Sound local- ization with binaural microphones.IEEE Transactions on Mobile Computing, 23(1):359–375, 2022. 3
2022
-
[40]
Griffiths, Yuan Cao, and Karthik Narasimhan
Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Thomas L. Griffiths, Yuan Cao, and Karthik Narasimhan. Tree of thoughts: deliberate problem solving with large lan- guage models. InProceedings of the 37th International Conference on Neural Information Processing Systems, Red Hook, NY , USA, 2023. Curran Associates Inc. 3
2023
-
[41]
Foleycrafter: Bring silent videos to life with lifelike and synchronized sounds
Yiming Zhang, Yicheng Gu, Yanhong Zeng, Zhening Xing, Yuancheng Wang, Zhizheng Wu, and Kai Chen. Foley- crafter: Bring silent videos to life with lifelike and synchro- nized sounds.ArXiv, abs/2407.01494, 2024. 2
-
[42]
Sep-stereo: Visually guided stereophonic audio generation by associating source separation
Hang Zhou, Xudong Xu, Dahua Lin, Xiaogang Wang, and Ziwei Liu. Sep-stereo: Visually guided stereophonic audio generation by associating source separation. InComputer Vision – ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XII, page 52–69, Berlin, Heidelberg, 2020. Springer-Verlag. 2 FoleyDesigner: Immersive Stereo ...
2020
-
[43]
As summarized in Table 1, ex- isting datasets typically lack stereophonic recordings or pre- cise temporal annotations
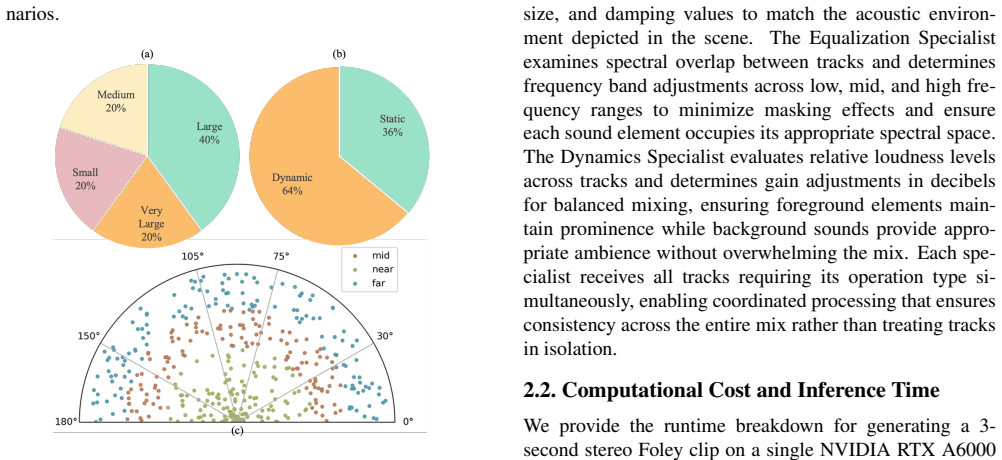
FilmStereo Dataset Current audio datasets predominantly focus on monaural sound, overlooking the pivotal role of stereophonic audio in enhancing film immersion. As summarized in Table 1, ex- isting datasets typically lack stereophonic recordings or pre- cise temporal annotations. This limitation compels sound designers to manually craft spatial effects fr...
-
[44]
Multi-Agent Refinement The complete pseudocode for our multi-agent Foley refine- ment pipeline is presented in Algorithm 2
Implementation Details 2.1. Multi-Agent Refinement The complete pseudocode for our multi-agent Foley refine- ment pipeline is presented in Algorithm 2. This algorithm implements the professional mixing framework described in Section 3.3 of the main paper, emulating the collaborative workflow of professional Foley teams through a four-stage process. Mixing...
-
[45]
Visual Analysis 2s VLM
-
[46]
Script Decomposition 34s LLM Agents
-
[47]
Audio Generation 8s DiT Diffusion
-
[48]
End-to-End (∼5s)
Foley Refinement 64s LLM Agents Total 108s vs. End-to-End (∼5s)
-
[49]
Additional Quantitative Evaluations To provide a more comprehensive understanding of Foley- Designer’s capabilities, we present additional quantitative experiments including extended baseline comparisons and an ablation study on our multi-agent framework. 3.1. Extended Baseline Comparisons We evaluated additional state-of-the-art models, specifically Diff...
-
[50]
Experimental Setup Our user study was conducted through both offline and on- line evaluations to comprehensively assess the perceived quality of generated foley audio
User Study Details 4.1. Experimental Setup Our user study was conducted through both offline and on- line evaluations to comprehensively assess the perceived quality of generated foley audio. Offline Evaluation.We recruited 12 participants with normal hearing to conduct perceptual evaluation in a pro- fessional audio mixing studio with controlled acoustic...
-
[51]
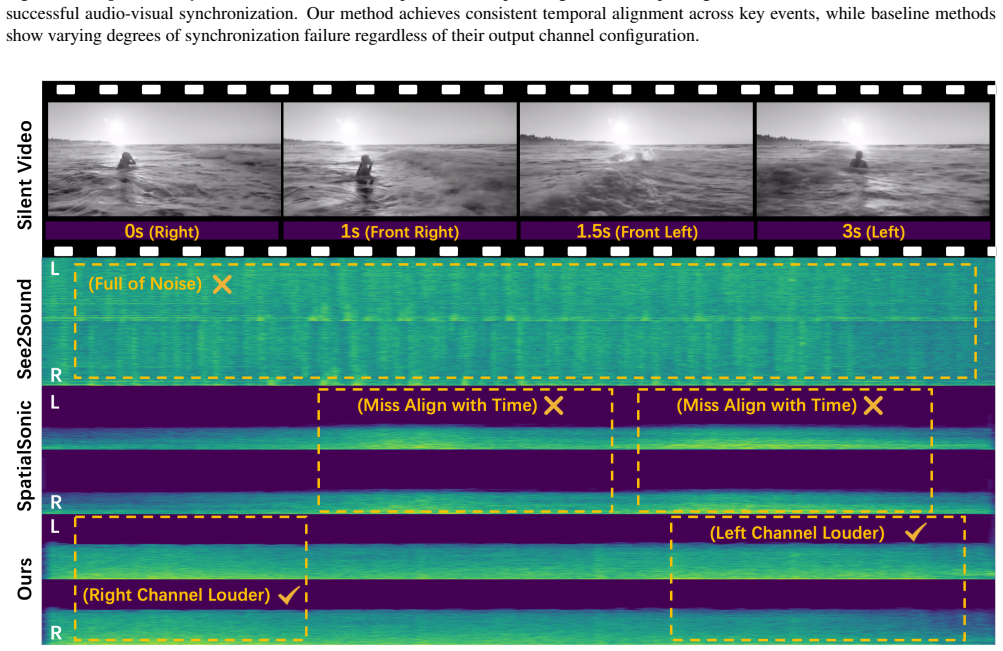
Case Study We conduct comprehensive qualitative analysis through two distinct case studies to evaluate temporal synchronization and spatial audio positioning capabilities across methods with different output channel configurations. 5.1. Temporal Synchronization Analysis Figure 6 demonstrates the temporal alignment performance across different methods prod...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.