Recognition: no theorem link
Graph Topology Information Enhanced Heterogeneous Graph Representation Learning
Pith reviewed 2026-05-10 19:23 UTC · model grok-4.3
The pith
ToGRL learns refined graph structures for heterogeneous graphs by extracting task-relevant topology information to build smoother inputs for representation learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
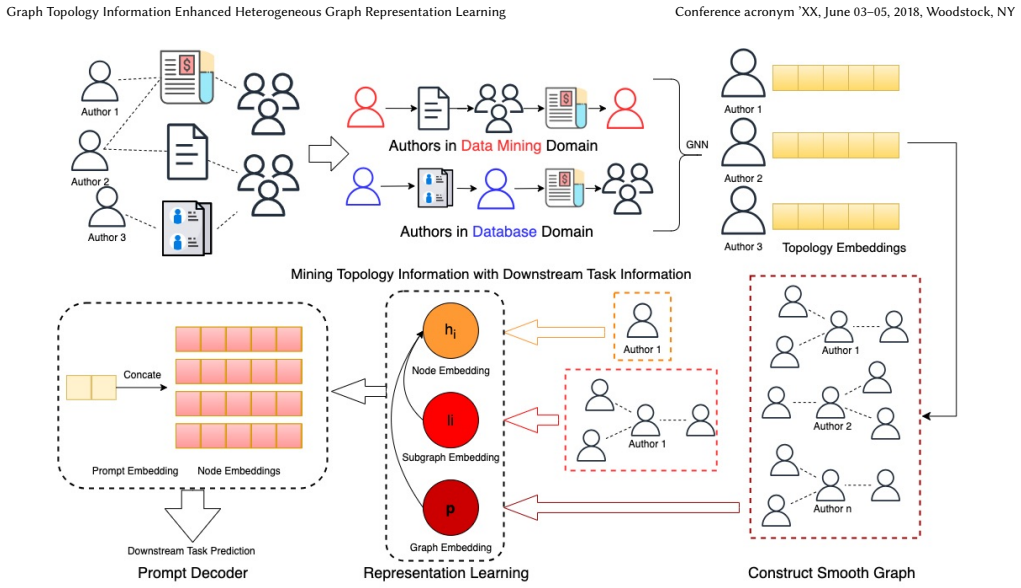
We propose ToGRL, a framework that learns high-quality graph structures and representations for downstream tasks by incorporating task-relevant latent topology information. A novel graph structure learning module extracts downstream task-related topology information from the raw graph structure and projects it into topology embeddings; these embeddings construct a new graph with smooth graph signals. The representation learning module then takes this new graph as input to learn embeddings, with prompt tuning applied to better utilize the knowledge in the representations. This two-stage separation of adjacency optimization from node representation learning also reduces memory consumption.
What carries the argument
The graph structure learning module that extracts downstream task-related topology information from the raw graph and projects it into topology embeddings used to construct a new graph with smooth signals.
If this is right
- Separating the optimization of the adjacency matrix from node representation learning reduces memory consumption when handling heterogeneous graphs.
- The constructed graph with smoother signals produces higher-quality node embeddings for downstream tasks.
- Prompt tuning allows the learned representations to adapt more effectively to varying downstream tasks without retraining the full model.
- The overall approach yields measurable gains over prior heterogeneous graph representation learning methods on multiple real-world datasets.
Where Pith is reading between the lines
- If the topology extraction step succeeds across datasets, the same separation of structure learning from embedding learning could be tested on homogeneous graphs to check whether the memory savings generalize.
- The learned topology embeddings might serve as an interpretable signal for identifying which original graph patterns are most useful for a given task.
- Applying the same two-stage process to dynamic or temporal heterogeneous graphs could reveal whether the smoothing effect holds when edges change over time.
Load-bearing premise
That extracting task-relevant topology information from the raw graph and projecting it into embeddings will reliably produce a new graph with smoother signals that improves downstream performance without losing critical heterogeneous relations or introducing artifacts.
What would settle it
On the five real-world datasets used in the experiments, compare node classification or link prediction accuracy of ToGRL against the reported state-of-the-art baselines; if ToGRL does not exceed those baselines by a noticeable margin, the performance improvement claim would be contradicted.
Figures




read the original abstract
Real-world heterogeneous graphs are inherently noisy and usually not in the optimal graph structures for downstream tasks, which often adversely affects the performance of GRL models in downstream tasks. Although Graph Structure Learning (GSL) methods have been proposed to learn graph structures and downstream tasks simultaneously, existing methods are predominantly designed for homogeneous graphs, while GSL for heterogeneous graphs remains largely unexplored. Two challenges arise in this context. Firstly, the quality of the input graph structure has a more profound impact on GNN-based heterogeneous GRL models compared to their homogeneous counterparts. Secondly, most existing homogenous GRL models encounter memory consumption issues when applied directly to heterogeneous graphs. In this paper, we propose a novel Graph Topology learning Enhanced Heterogeneous Graph Representation Learning framework (ToGRL).ToGRL learns high-quality graph structures and representations for downstream tasks by incorporating task-relevant latent topology information. Specifically, a novel GSL module is first proposed to extract downstream task-related topology information from a raw graph structure and project it into topology embeddings. These embeddings are utilized to construct a new graph with smooth graph signals. This two-stage approach to GSL separates the optimization of the adjacency matrix from node representation learning to reduce memory consumption. Following this, a representation learning module takes the new graph as input to learn embeddings for downstream tasks. ToGRL also leverages prompt tuning to better utilize the knowledge embedded in learned representations, thus enhancing adaptability to downstream tasks. Extensive experiments on five real-world datasets show that our ToGRL outperforms state-of-the-art methods by a large margin.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes ToGRL, a two-stage framework for heterogeneous graph representation learning. A novel GSL module first extracts task-relevant latent topology information from the raw heterogeneous graph and projects it into topology embeddings, which are then used to construct a new graph with smoother signals. A subsequent representation learning module operates on this new graph to produce embeddings for downstream tasks, with prompt tuning applied to enhance adaptability. The central empirical claim is that this approach outperforms state-of-the-art methods by a large margin on five real-world datasets while mitigating memory issues associated with direct application of homogeneous GSL techniques to heterogeneous graphs.
Significance. If the empirical results prove robust, this work would be significant for extending graph structure learning to heterogeneous graphs, where input structure quality has a more pronounced effect on GNN performance than in homogeneous cases. The explicit two-stage separation of adjacency optimization from representation learning offers a practical solution to memory consumption, and the integration of prompt tuning provides a lightweight way to adapt learned representations. These elements could serve as a useful template for handling noisy real-world heterogeneous graphs, provided the topology projection step demonstrably preserves meta-relation semantics.
major comments (1)
- [GSL module description (framework overview)] GSL module description (framework overview): the projection of topology embeddings into a new graph is stated to yield smooth signals while incorporating task-relevant topology, yet no equation, regularization term, or constraint is supplied to ensure preservation of distinct edge-type semantics and meta-path relations during construction. This is load-bearing for the central claim, because downstream gains cannot be attributed to improved topology if the projection step averages across or erases heterogeneous distinctions (as opposed to merely smoothing).
minor comments (2)
- [Abstract] Abstract: reports outperformance on five datasets but omits the specific evaluation metrics, baseline methods, statistical significance tests, and dataset characteristics, making it harder for readers to gauge the strength of the empirical claims without immediately consulting the experiments section.
- The two-stage memory-reduction benefit is asserted but would be strengthened by a brief complexity analysis or memory-footprint comparison against direct heterogeneous GSL baselines.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We have carefully reviewed the major comment and provide a point-by-point response below. We agree that additional formalization is needed and will incorporate revisions to strengthen the presentation of the GSL module.
read point-by-point responses
-
Referee: [GSL module description (framework overview)] GSL module description (framework overview): the projection of topology embeddings into a new graph is stated to yield smooth signals while incorporating task-relevant topology, yet no equation, regularization term, or constraint is supplied to ensure preservation of distinct edge-type semantics and meta-path relations during construction. This is load-bearing for the central claim, because downstream gains cannot be attributed to improved topology if the projection step averages across or erases heterogeneous distinctions (as opposed to merely smoothing).
Authors: We agree with the referee that the current description of the projection step in the GSL module lacks explicit mathematical details, which is necessary to rigorously support the claim that performance gains arise from task-relevant topology that preserves heterogeneous structure. In the revised manuscript, we will add the full formulation of the topology embedding projection, including the specific regularization term and constraints used to maintain distinct edge-type semantics and meta-path relations (rather than averaging or erasing them). This will include the objective function for constructing the new graph from the embeddings and an explanation of how the two-stage separation ensures smoother signals without loss of meta-relation information. We will also include additional analysis or ablation results demonstrating that the learned topology retains these distinctions. revision: yes
Circularity Check
No significant circularity; modular pipeline is self-contained
full rationale
The paper describes ToGRL as a two-stage framework in which a GSL module first extracts task-relevant topology information from the raw heterogeneous graph and projects it into embeddings used to construct a new graph, after which a separate representation learning module operates on that graph. No equations or definitions are shown that reduce the output graph or embeddings directly to fitted parameters or self-referential inputs by construction. Topology extraction is presented as an independent preprocessing step whose quality is validated empirically on external datasets rather than derived tautologically. Any self-citations are peripheral and not load-bearing for the central claims.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Yu Chen, Lingfei Wu, and Mohammed Zaki. 2020. Iterative deep graph learning for graph neural networks: Better and robust node embeddings.Advances in neural information processing systems33 (2020), 19314–19326
2020
-
[2]
Joe Davison, Joshua Feldman, and Alexander M Rush. 2019. Commonsense knowledge mining from pretrained models. InProceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP). 1173–1178
2019
-
[3]
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2018. Bert: Pre-training of deep bidirectional transformers for language understanding.arXiv preprint arXiv:1810.04805(2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[4]
Xiaowen Dong, Dorina Thanou, Michael Rabbat, and Pascal Frossard. 2019. Learn- ing graphs from data: A signal representation perspective.IEEE Signal Processing Magazine36, 3 (2019), 44–63
2019
-
[5]
Yuxiao Dong, Nitesh V Chawla, and Ananthram Swami. 2017. metapath2vec: Scalable representation learning for heterogeneous networks. InProceedings of the 23rd ACM SIGKDD international conference on knowledge discovery and data mining. 135–144
2017
-
[6]
Bahare Fatemi, Layla El Asri, and Seyed Mehran Kazemi. 2021. SLAPS: Self- supervision improves structure learning for graph neural networks.Advances in Neural Information Processing Systems34 (2021), 22667–22681
2021
-
[7]
Luca Franceschi, Mathias Niepert, Massimiliano Pontil, and Xiao He. 2019. Learn- ing discrete structures for graph neural networks. InInternational conference on machine learning. PMLR, 1972–1982
2019
-
[8]
Xinyu Fu, Jiani Zhang, Ziqiao Meng, and Irwin King. 2020. Magnn: Metap- ath aggregated graph neural network for heterogeneous graph embedding. In Proceedings of The Web Conference 2020. 2331–2341
2020
- [9]
-
[10]
Spyros Gidaris and Nikos Komodakis. 2019. Generating classification weights with gnn denoising autoencoders for few-shot learning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 21–30
2019
-
[11]
Aditya Grover and Jure Leskovec. 2016. node2vec: Scalable feature learning for networks. InProceedings of the 22nd ACM SIGKDD international conference on Knowledge discovery and data mining. 855–864
2016
- [12]
- [13]
-
[14]
Ziniu Hu, Yuxiao Dong, Kuansan Wang, and Yizhou Sun. 2020. Heterogeneous graph transformer. InProceedings of The Web Conference 2020. 2704–2710
2020
-
[15]
Pierre Humbert, Batiste Le Bars, Laurent Oudre, Argyris Kalogeratos, and Nicolas Vayatis. 2021. Learning laplacian matrix from graph signals with sparse spectral representation.Journal of Machine Learning Research(2021)
2021
-
[16]
Zhengbao Jiang, Frank F Xu, Jun Araki, and Graham Neubig. 2020. How can we know what language models know?Transactions of the Association for Computa- tional Linguistics8 (2020), 423–438
2020
-
[17]
Thomas N Kipf and Max Welling. 2016. Semi-supervised classification with graph convolutional networks.arXiv preprint arXiv:1609.02907(2016)
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[18]
Xiang Lisa Li and Percy Liang. 2021. Prefix-tuning: Optimizing continuous prompts for generation.arXiv preprint arXiv:2101.00190(2021)
work page internal anchor Pith review arXiv 2021
-
[19]
Nian Liu, Xiao Wang, Lingfei Wu, Yu Chen, Xiaojie Guo, and Chuan Shi. 2022. Compact Graph Structure Learning via Mutual Information Compression. In Proceedings of the ACM Web Conference 2022. 1601–1610
2022
- [20]
-
[21]
Pengfei Liu, Weizhe Yuan, Jinlan Fu, Zhengbao Jiang, Hiroaki Hayashi, and Graham Neubig. 2023. Pre-train, prompt, and predict: A systematic survey of prompting methods in natural language processing.Comput. Surveys55, 9 (2023), 1–35
2023
- [22]
-
[23]
Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. 2019. Roberta: A robustly optimized bert pretraining approach.arXiv preprint arXiv:1907.11692 (2019)
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[24]
Yixin Liu, Yu Zheng, Daokun Zhang, Hongxu Chen, Hao Peng, and Shirui Pan
-
[25]
InProceedings of the ACM Web Conference 2022
Towards unsupervised deep graph structure learning. InProceedings of the ACM Web Conference 2022. 1392–1403
2022
-
[26]
Qingsong Lv, Ming Ding, Qiang Liu, Yuxiang Chen, Wenzheng Feng, Siming He, Chang Zhou, Jianguo Jiang, Yuxiao Dong, and Jie Tang. 2021. Are we really making much progress? Revisiting, benchmarking and refining heterogeneous graph neural networks. InProceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining. 1150–1160
2021
- [27]
- [28]
-
[29]
Laurens Van der Maaten and Geoffrey Hinton. 2008. Visualizing data using t-SNE. Journal of machine learning research9, 11 (2008)
2008
-
[30]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need.Advances in neural information processing systems30 (2017)
2017
-
[31]
Petar Veličković, Guillem Cucurull, Arantxa Casanova, Adriana Romero, Pietro Lio, and Yoshua Bengio. 2017. Graph attention networks.arXiv preprint arXiv:1710.10903(2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[32]
Can Wang, Sheng Zhou, Kang Yu, Defang Chen, Bolang Li, Yan Feng, and Chun Chen. 2022. Collaborative Knowledge Distillation for Heterogeneous Information Network Embedding. InProceedings of the ACM Web Conference 2022. 1631–1639
2022
-
[33]
Xiao Wang, Houye Ji, Chuan Shi, Bai Wang, Yanfang Ye, Peng Cui, and Philip S Yu
-
[34]
InThe world wide web conference
Heterogeneous graph attention network. InThe world wide web conference. 2022–2032
2022
-
[35]
Xiao Wang, Nian Liu, Hui Han, and Chuan Shi. 2021. Self-supervised heteroge- neous graph neural network with co-contrastive learning. InProceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining. 1726–1736
2021
-
[36]
Yongwei Wang, Yong Liu, and Zhiqi Shen. 2023. Revisiting item promotion in GNN-based collaborative filtering: a masked targeted topological attack per- spective. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 37. 15206–15214
2023
-
[37]
Zhen Wang, Jianwen Zhang, Jianlin Feng, and Zheng Chen. 2014. Knowledge graph embedding by translating on hyperplanes. InProceedings of the AAAI conference on artificial intelligence, Vol. 28
2014
-
[38]
Keyulu Xu, Weihua Hu, Jure Leskovec, and Stefanie Jegelka. 2018. How powerful are graph neural networks?arXiv preprint arXiv:1810.00826(2018)
work page internal anchor Pith review arXiv 2018
-
[39]
Liang Yang, Fan Wu, Zichen Zheng, Bingxin Niu, Junhua Gu, Chuan Wang, Xiaochun Cao, and Yuanfang Guo. 2021. Heterogeneous Graph Information Bottleneck.. InIJCAI. 1638–1645
2021
-
[40]
Xiaocheng Yang, Mingyu Yan, Shirui Pan, Xiaochun Ye, and Dongrui Fan. 2023. Simple and efficient heterogeneous graph neural network. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 37. 10816–10824
2023
-
[41]
Seongjun Yun, Minbyul Jeong, Raehyun Kim, Jaewoo Kang, and Hyunwoo J Kim
-
[42]
Graph transformer networks.Advances in neural information processing systems32 (2019)
2019
-
[43]
Mengmei Zhang, Xiao Wang, Meiqi Zhu, Chuan Shi, Zhiqiang Zhang, and Jun Zhou. 2022. Robust heterogeneous graph neural networks against adversarial Graph Topology Information Enhanced Heterogeneous Graph Representation Learning Conference acronym ’XX, June 03–05, 2018, Woodstock, NY attacks. InProceedings of the AAAI Conference on Artificial Intelligence, ...
2022
-
[44]
Jianan Zhao, Xiao Wang, Chuan Shi, Binbin Hu, Guojie Song, and Yanfang Ye
-
[45]
In Proceedings of the AAAI Conference on Artificial Intelligence, Vol
Heterogeneous graph structure learning for graph neural networks. In Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 35. 4697–4705
- [46]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.