Recognition: 2 theorem links
· Lean TheoremControlling Distributional Bias in Multi-Round LLM Generation via KL-Optimized Fine-Tuning
Pith reviewed 2026-05-10 19:26 UTC · model grok-4.3
The pith
A hybrid fine-tuning method anchors steering tokens with KL divergence and binds them semantically to let LLMs match target distributions over many generations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
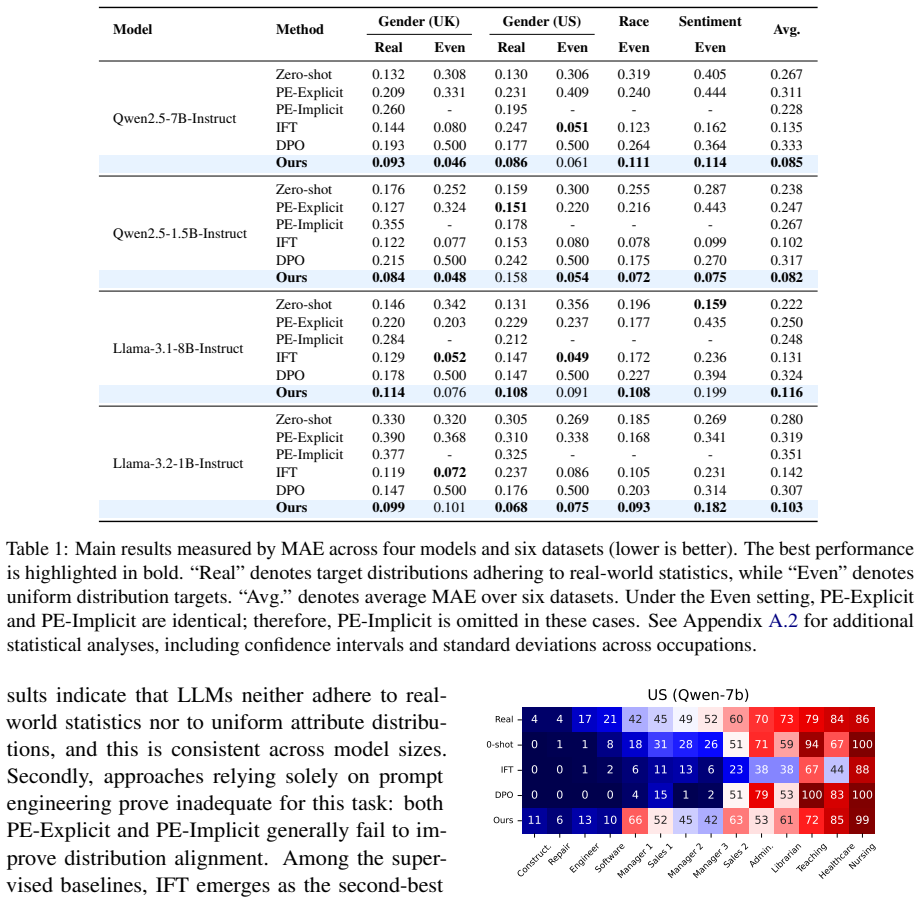
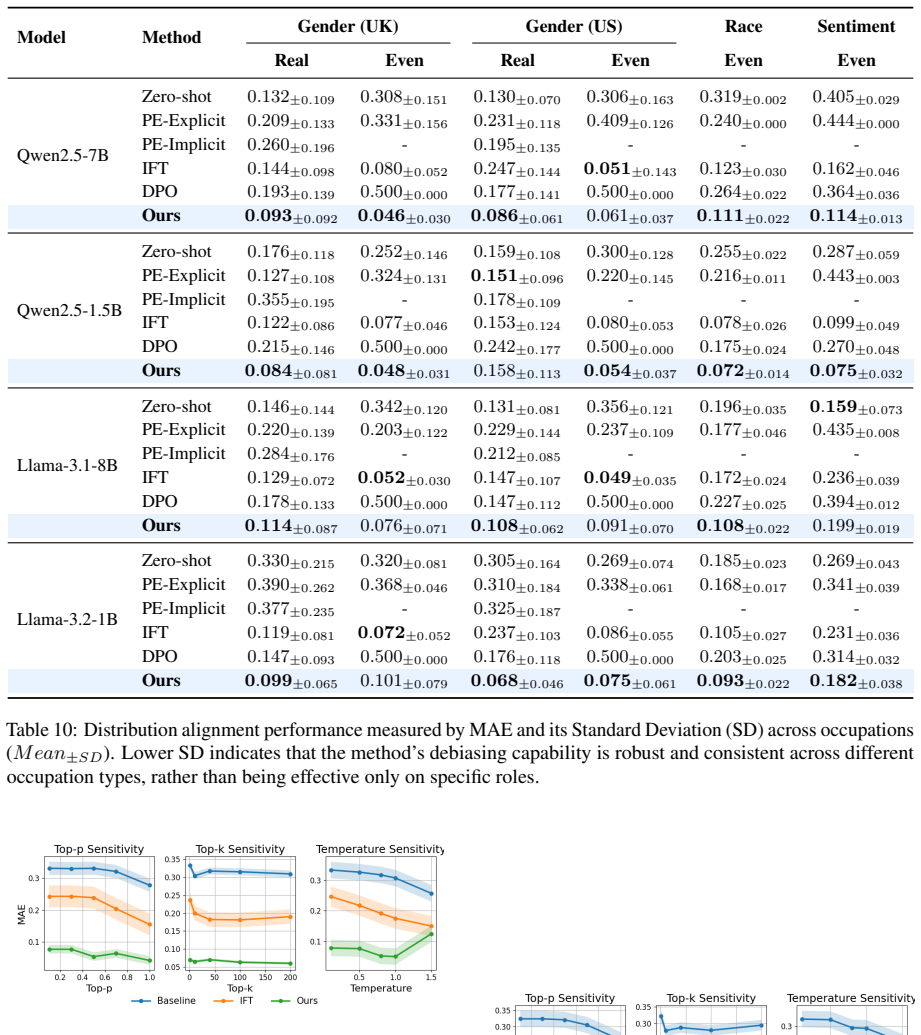
Off-the-shelf LLMs and common alignment methods fail to produce outputs whose attribute distributions stay close to chosen targets across repeated generations; a new fine-tuning framework that couples steering-token calibration (via KL divergence on latent token probabilities) with semantic alignment (via Kahneman-Tversky optimization) achieves precise distributional control on gender, race, and sentiment within occupational contexts.
What carries the argument
Hybrid objective that applies Kullback-Leibler divergence to anchor the probability mass of latent steering tokens while using Kahneman-Tversky optimization to bind those tokens to semantically consistent responses.
If this is right
- LLMs can be trained to reflect chosen real-world or uniform statistics in the aggregate of many outputs rather than in single responses.
- Distributional control for attributes such as gender, race, and sentiment becomes feasible in occupational generation tasks.
- The method outperforms prompt engineering and Direct Preference Optimization across six diverse datasets.
- Precise control is achieved while the underlying model continues to generate coherent text.
Where Pith is reading between the lines
- The same steering-token approach could be tested on distributions over other properties such as factual correctness or safety levels.
- Evaluation protocols that sample many generations per prompt may become necessary to verify alignment in stochastic settings.
- If the method scales, it could reduce the risk that repeated LLM use amplifies unwanted demographic skews in applications like hiring or content recommendation.
Load-bearing premise
The hybrid objective of KL-anchored steering tokens plus Kahneman-Tversky semantic binding will produce stable distributional control without harming general model capabilities or introducing new inconsistencies.
What would settle it
Apply the fine-tuned model to a fresh collection of occupation prompts and measure whether the empirical frequencies of generated gender, race, and sentiment attributes fall within a small tolerance of the specified target distribution while baseline models do not.
Figures






read the original abstract
While the real world is inherently stochastic, Large Language Models (LLMs) are predominantly evaluated on single-round inference against fixed ground truths. In this work, we shift the lens to distribution alignment: assessing whether LLMs, when prompted repeatedly, can generate outputs that adhere to a desired target distribution, e.g. reflecting real-world statistics or a uniform distribution. We formulate distribution alignment using the attributes of gender, race, and sentiment within occupational contexts. Our empirical analysis reveals that off-the-shelf LLMs and standard alignment techniques, including prompt engineering and Direct Preference Optimization, fail to reliably control output distributions. To bridge this gap, we propose a novel fine-tuning framework that couples Steering Token Calibration with Semantic Alignment. We introduce a hybrid objective function combining Kullback-Leibler divergence to anchor the probability mass of latent steering tokens and Kahneman-Tversky Optimization to bind these tokens to semantically consistent responses. Experiments across six diverse datasets demonstrate that our approach significantly outperforms baselines, achieving precise distributional control in attribute generation tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that off-the-shelf LLMs and standard alignment methods (prompt engineering, DPO) fail to produce outputs matching target distributions over multiple rounds for attributes such as gender, race, and sentiment in occupational contexts. It introduces a fine-tuning framework called Steering Token Calibration coupled with Semantic Alignment, using a hybrid objective that combines KL divergence to anchor steering-token probabilities and Kahneman-Tversky Optimization to enforce semantic consistency, and reports that this approach achieves precise distributional control and significantly outperforms baselines across six diverse datasets.
Significance. If the empirical claims are substantiated, the work would address a practically important gap between single-turn evaluation and multi-round distributional fidelity, offering a concrete fine-tuning recipe for bias control that preserves general capabilities. The hybrid objective construction is a potentially reusable idea, but its value hinges on the missing quantitative evidence and stability checks.
major comments (2)
- [Experiments] The central empirical claim (abstract and Experiments section) asserts significant outperformance on six datasets yet supplies no numerical results, tables, error bars, statistical tests, or per-attribute KL divergences; without these data the magnitude and reliability of the improvement cannot be assessed.
- [Method / Experiments] The hybrid objective is presented as simultaneously anchoring probability mass via KL and binding semantics via KTO without side-effects, but no post-training perplexity, MMLU-style benchmarks, round-to-round consistency metrics, or ablations that isolate the KL term from the KTO term are reported; these measurements are load-bearing for the claim that distributional control is achieved without capability degradation or new inconsistencies.
minor comments (2)
- [Abstract] The abstract refers to 'precise distributional control' without defining the metric (e.g., target KL threshold, Wasserstein distance, or statistical test) used to declare success.
- [Method] Notation for the steering tokens and the exact form of the hybrid loss (Eq. numbers if present) should be introduced earlier and cross-referenced consistently.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. The two major comments highlight important gaps in the empirical presentation and validation of our method. We agree that these elements are essential for substantiating the claims and will revise the manuscript accordingly to include the requested quantitative evidence, metrics, and ablations.
read point-by-point responses
-
Referee: [Experiments] The central empirical claim (abstract and Experiments section) asserts significant outperformance on six datasets yet supplies no numerical results, tables, error bars, statistical tests, or per-attribute KL divergences; without these data the magnitude and reliability of the improvement cannot be assessed.
Authors: We acknowledge that the initial submission summarized the experimental outcomes at a high level without including the full numerical tables, error bars, statistical tests, or per-attribute KL divergence values. This omission limits the ability to evaluate the magnitude and reliability of the improvements. In the revised manuscript, we will add detailed tables reporting mean performance metrics (including KL divergences) across all six datasets, standard deviations from multiple random seeds, and p-values from statistical significance tests against the baselines. Per-attribute breakdowns for gender, race, and sentiment will also be included. revision: yes
-
Referee: [Method / Experiments] The hybrid objective is presented as simultaneously anchoring probability mass via KL and binding semantics via KTO without side-effects, but no post-training perplexity, MMLU-style benchmarks, round-to-round consistency metrics, or ablations that isolate the KL term from the KTO term are reported; these measurements are load-bearing for the claim that distributional control is achieved without capability degradation or new inconsistencies.
Authors: We agree that the absence of these supporting measurements weakens the claim that the hybrid objective achieves distributional control without degrading general capabilities or introducing inconsistencies. In the revision, we will report post-training perplexity on held-out corpora, MMLU benchmark scores pre- and post-fine-tuning, and explicit round-to-round consistency metrics (e.g., variance in attribute distributions over successive generations). We will also add ablation studies that isolate the contribution of the KL term versus the KTO term, with corresponding performance tables. revision: yes
Circularity Check
No circularity: novel hybrid objective presented as new construction with empirical support only
full rationale
The provided abstract and description introduce a new fine-tuning framework coupling Steering Token Calibration with Semantic Alignment via a hybrid KL + Kahneman-Tversky objective. No equations, derivations, self-citations, or fitted parameters are shown that reduce any claimed prediction or result to the inputs by construction. The central claim rests on empirical outperformance across datasets rather than any self-referential mathematical step, rendering the derivation chain self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption KL divergence can be used to anchor probability mass of latent steering tokens to a target distribution
invented entities (1)
-
Steering Token Calibration
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
hybrid objective function combining Kullback-Leibler divergence to anchor the probability mass of latent steering tokens and Kahneman-Tversky Optimization to bind these tokens to semantically consistent responses
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Ltotal = L_KTO + L_KL
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Hritik Bansal, Da Yin, Masoud Monajatipoor, and Kai-Wei Chang. 2022. https://doi.org/10.18653/v1/2022.emnlp-main.88 How well can text-to-image generative models understand ethical natural language interventions? In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 1358--1370, Abu Dhabi, United Arab Emirates. Ass...
-
[2]
Maria De-Arteaga, Alexey Romanov, Hanna Wallach, Jennifer Chayes, Christian Borgs, Alexandra Chouldechova, Sahin Geyik, Krishnaram Kenthapadi, and Adam Tauman Kalai. 2019. Bias in bios: A case study of semantic representation bias in a high-stakes setting. In proceedings of the Conference on Fairness, Accountability, and Transparency, pages 120--128
2019
-
[3]
Karin De Langis, Ryan Koo, and Dongyeop Kang. 2024. https://doi.org/10.18653/v1/2024.emnlp-main.386 Dynamic multi-reward weighting for multi-style controllable generation . In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 6783--6800, Miami, Florida, USA. Association for Computational Linguistics
-
[4]
Mingkai Deng, Jianyu Wang, Cheng-Ping Hsieh, Yihan Wang, Han Guo, Tianmin Shu, Meng Song, Eric Xing, and Zhiting Hu. 2022. https://doi.org/10.18653/v1/2022.emnlp-main.222 RLP rompt: Optimizing discrete text prompts with reinforcement learning . In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 3369--3391, Abu...
-
[5]
Emily Dinan, Angela Fan, Adina Williams, Jack Urbanek, Douwe Kiela, and Jason Weston. 2020. https://doi.org/10.18653/v1/2020.emnlp-main.656 Queens are powerful too: Mitigating gender bias in dialogue generation . In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 8173--8188, Online. Association for Com...
-
[6]
Kawin Ethayarajh, Winnie Xu, Niklas Muennighoff, Dan Jurafsky, and Douwe Kiela. 2024. KTO : Model alignment as prospect theoretic optimization. arXiv preprint arXiv:2402.01306
work page internal anchor Pith review arXiv 2024
-
[7]
Angela Fan and Claire Gardent. 2022. https://doi.org/10.18653/v1/2022.acl-long.586 Generating biographies on W ikipedia: The impact of gender bias on the retrieval-based generation of women biographies . In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 8561--8576, Dublin, Ireland. As...
-
[8]
Zhiting Fan, Ruizhe Chen, and Zuozhu Liu. 2025. https://doi.org/10.18653/v1/2025.findings-acl.506 B ias G uard: A reasoning-enhanced bias detection tool for large language models . In Findings of the Association for Computational Linguistics: ACL 2025, pages 9753--9764, Vienna, Austria. Association for Computational Linguistics
-
[9]
Biaoyan Fang, Ritvik Dinesh, Xiang Dai, and Sarvnaz Karimi. 2024. https://doi.org/10.18653/v1/2024.acl-short.39 Born differently makes a difference: Counterfactual study of bias in biography generation from a data-to-text perspective . In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), page...
-
[10]
Isabel O. Gallegos, Ryan A. Rossi, Joe Barrow, Md Mehrab Tanjim, Sungchul Kim, Franck Dernoncourt, Tong Yu, Ruiyi Zhang, and Nesreen K. Ahmed. 2024. https://doi.org/10.1162/coli_a_00524 Bias and fairness in large language models: A survey . Computational Linguistics, 50(3):1097--1179
-
[11]
Michael Gira, Ruisu Zhang, and Kangwook Lee. 2022. https://doi.org/10.18653/v1/2022.ltedi-1.8 Debiasing pre-trained language models via efficient fine-tuning . In Proceedings of the Second Workshop on Language Technology for Equality, Diversity and Inclusion, pages 59--69, Dublin, Ireland. Association for Computational Linguistics
-
[12]
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, and 1 others. 2022. Lora: Low-rank adaptation of large language models. ICLR, 1(2):3
2022
-
[13]
Dong Huang, Jie M Zhang, Qingwen Bu, Xiaofei Xie, Junjie Chen, and Heming Cui. 2024. Bias testing and mitigation in llm-based code generation. ACM Transactions on Software Engineering and Methodology
2024
-
[14]
Yanbei Jiang, Yihao Ding, Chao Lei, Jiayang Ao, Jey Han Lau, and Krista A Ehinger. 2025 a . Beyond perception: Evaluating abstract visual reasoning through multi-stage task. In Findings of the Association for Computational Linguistics: ACL 2025, pages 13--45
2025
- [15]
-
[16]
Renlong Jie, Xiaojun Meng, Lifeng Shang, Xin Jiang, and Qun Liu. 2024. https://doi.org/10.18653/v1/2024.findings-acl.63 Prompt-based length controlled generation with multiple control types . In Findings of the Association for Computational Linguistics: ACL 2024, pages 1067--1085, Bangkok, Thailand. Association for Computational Linguistics
-
[17]
Kai Konen, Sophie Jentzsch, Diaoul \'e Diallo, Peer Sch \"u tt, Oliver Bensch, Roxanne El Baff, Dominik Opitz, and Tobias Hecking. 2024. https://doi.org/10.18653/v1/2024.findings-eacl.52 Style vectors for steering generative large language models . In Findings of the Association for Computational Linguistics: EACL 2024, pages 782--802, St. Julian ' s, Mal...
-
[18]
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica. 2023. Efficient memory management for large language model serving with pagedattention. In Proceedings of the 29th symposium on operating systems principles, pages 611--626
2023
-
[19]
Xun Liang, Hanyu Wang, Shichao Song, Mengting Hu, Xunzhi Wang, Zhiyu Li, Feiyu Xiong, and Bo Tang. 2024. https://doi.org/10.18653/v1/2024.findings-acl.345 Controlled text generation for large language model with dynamic attribute graphs . In Findings of the Association for Computational Linguistics: ACL 2024, pages 5797--5814, Bangkok, Thailand. Associati...
-
[20]
Robert Litschko, Max M \"u ller-Eberstein, Rob van der Goot, Leon Weber-Genzel, and Barbara Plank. 2023. https://doi.org/10.18653/v1/2023.emnlp-main.14 Establishing trustworthiness: Rethinking tasks and model evaluation . In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 193--203, Singapore. Association for C...
-
[21]
Pusheng Liu, Lianwei Wu, Linyong Wang, Sensen Guo, and Yang Liu. 2024. https://aclanthology.org/2024.lrec-main.1328/ Step-by-step: Controlling arbitrary style in text with large language models . In Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024), pages 15285--15295,...
2024
-
[22]
Michela Lorandi and Anya Belz. 2023. https://doi.org/10.18653/v1/2023.wassa-1.30 How to control sentiment in text generation: A survey of the state-of-the-art in sentiment-control techniques . In Proceedings of the 13th Workshop on Computational Approaches to Subjectivity, Sentiment, & Social Media Analysis , pages 341--353, Toronto, Canada. Association f...
-
[23]
Huiyu Mai, Wenhao Jiang, and Zhi-Hong Deng. 2023. https://doi.org/10.18653/v1/2023.findings-emnlp.990 Prefix-tuning based unsupervised text style transfer . In Findings of the Association for Computational Linguistics: EMNLP 2023, pages 14847--14856, Singapore. Association for Computational Linguistics
-
[24]
Takuto Miura, Kiyoaki Shirai, and Natthawut Kertkeidkachorn. 2025. https://aclanthology.org/2025.icnlsp-1.6/ Style-controlled response generation for dialog systems with intimacy interpretation . In Proceedings of the 8th International Conference on Natural Language and Speech Processing (ICNLSP-2025), pages 50--59, Southern Denmark University, Odense, De...
2025
-
[25]
Pranav Narayanan Venkit, Sanjana Gautam, Ruchi Panchanadikar, Ting-Hao Huang, and Shomir Wilson. 2023. https://doi.org/10.18653/v1/2023.eacl-main.9 Nationality bias in text generation . In Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics, pages 116--122, Dubrovnik, Croatia. Association for Computa...
-
[26]
OpenAI. 2025. https://openai.com/index/gpt-5-1/
2025
-
[27]
Birong Pan, Yongqi Li, Weiyu Zhang, Wenpeng Lu, Mayi Xu, Shen Zhou, Yuanyuan Zhu, Ming Zhong, and Tieyun Qian. 2025. https://doi.org/10.18653/v1/2025.findings-emnlp.238 A survey on training-free alignment of large language models . In Findings of the Association for Computational Linguistics: EMNLP 2025, pages 4445--4461, Suzhou, China. Association for Co...
-
[28]
Kaiyi Pang, Minhao Bai, Jinshuai Yang, Yue Gao, Minghu Jiang, and Yongfeng Huang. 2025. A plug-and-play method for linguistic alignment in language models. Knowledge-Based Systems, page 113597
2025
- [29]
-
[30]
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. 2023. Direct preference optimization: Your language model is secretly a reward model. Advances in neural information processing systems, 36:53728--53741
2023
-
[31]
Donya Rooein, Vil \'e m Zouhar, Debora Nozza, and Dirk Hovy. 2025. https://doi.org/10.18653/v1/2025.emnlp-main.3 Biased tales: Cultural and topic bias in generating children ' s stories . In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 52--72, Suzhou, China. Association for Computational Linguistics
-
[32]
Alireza Salemi, Sheshera Mysore, Michael Bendersky, and Hamed Zamani. 2024. https://doi.org/10.18653/v1/2024.acl-long.399 L a MP : When large language models meet personalization . In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 7370--7392, Bangkok, Thailand. Association for Computa...
-
[33]
Ingroj Shrestha and Padmini Srinivasan. 2025. https://doi.org/10.18653/v1/2025.emnlp-main.76 LLM bias detection and mitigation through the lens of desired distributions . In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 1464--1480, Suzhou, China. Association for Computational Linguistics
-
[34]
Velizar Shulev and Khalil Sima ' an. 2024. https://aclanthology.org/2024.lrec-main.343/ Continual reinforcement learning for controlled text generation . In Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024), pages 3881--3889, Torino, Italia. ELRA and ICCL
2024
-
[35]
Shweta Soundararajan and Sarah Jane Delany. 2024. https://aclanthology.org/2024.icnlsp-1.42/ Investigating gender bias in large language models through text generation . In Proceedings of the 7th International Conference on Natural Language and Speech Processing (ICNLSP 2024), pages 410--424, Trento. Association for Computational Linguistics
2024
-
[36]
UK Occupation Statistics. 2023. https://assets.publishing.service.gov.uk/media/5a7f3952ed915d74e622924b/Working_Futures_Headline_Report_final_for_web__PG.pdf
2023
-
[37]
US Occupation Statistics. 2025. https://www.bls.gov/cps/cpsaat39.htm
2025
- [38]
-
[39]
Qwen Team and 1 others. 2024. Qwen2 technical report. arXiv preprint arXiv:2407.10671, 2(3)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[40]
Martina Toshevska and Sonja Gievska. 2025. Llm-based text style transfer: Have we taken a step forward? IEEE Access
2025
-
[41]
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timoth \'e e Lacroix, Baptiste Rozi \`e re, Naman Goyal, Eric Hambro, Faisal Azhar, and 1 others. 2023. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[42]
Ra \'u l V \'a zquez, Hande Celikkanat, Dennis Ulmer, J \"o rg Tiedemann, Swabha Swayamdipta, Wilker Aziz, Barbara Plank, Joris Baan, and Marie-Catherine de Marneffe, editors. 2024. https://doi.org/10.18653/v1/2024.uncertainlp-1.0 Proceedings of the 1st Workshop on Uncertainty-Aware NLP (UncertaiNLP 2024) . Association for Computational Linguistics, St Ju...
-
[43]
Yixin Wan and Kai-Wei Chang. 2025. https://doi.org/10.18653/v1/2025.acl-long.445 White men lead, black women help? benchmarking and mitigating language agency social biases in LLM s . In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 9082--9108, Vienna, Austria. Association for Comput...
-
[44]
Xiaoyuan Wu, Weiran Lin, Omer Akgul, and Lujo Bauer. 2025. https://doi.org/10.18653/v1/2025.emnlp-main.1554 Estimating LLM consistency: A user baseline vs surrogate metrics . In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 30530--30544, Suzhou, China. Association for Computational Linguistics
-
[45]
Yu Xia, Tong Yu, Zhankui He, Handong Zhao, Julian McAuley, and Shuai Li. 2024. https://doi.org/10.18653/v1/2024.naacl-long.262 Aligning as debiasing: Causality-aware alignment via reinforcement learning with interventional feedback . In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human...
-
[46]
Jingyuan Yang, Dapeng Chen, Yajing Sun, Rongjun Li, Zhiyong Feng, and Wei Peng. 2024. https://doi.org/10.18653/v1/2024.findings-acl.199 Enhancing semantic consistency of large language models through model editing: An interpretability-oriented approach . In Findings of the Association for Computational Linguistics: ACL 2024, pages 3343--3353, Bangkok, Tha...
-
[47]
Binwei Yao, Zefan Cai, Yun-Shiuan Chuang, Shanglin Yang, Ming Jiang, Diyi Yang, and Junjie Hu. 2025. https://openreview.net/forum?id=bgpNJBD6Va No preference left behind: Group distributional preference optimization . In The Thirteenth International Conference on Learning Representations
2025
-
[48]
Mahdi Zakizadeh and Mohammad Taher Pilehvar. 2025. https://doi.org/10.18653/v1/2025.trustnlp-main.31 Gender encoding patterns in pretrained language model representations . In Proceedings of the 5th Workshop on Trustworthy NLP (TrustNLP 2025), pages 489--500, Albuquerque, New Mexico. Association for Computational Linguistics
-
[49]
online" 'onlinestring :=
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint eprinttype howpublished institution journal key month note number organization pages publisher school series title type volume year doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRING...
-
[50]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.