Recognition: no theorem link
Improving Controllable Generation: Faster Training and Better Performance via x₀-Supervision
Pith reviewed 2026-05-10 18:33 UTC · model grok-4.3
The pith
Direct supervision on clean target images accelerates training of controllable diffusion models by up to 2x while improving quality and control accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
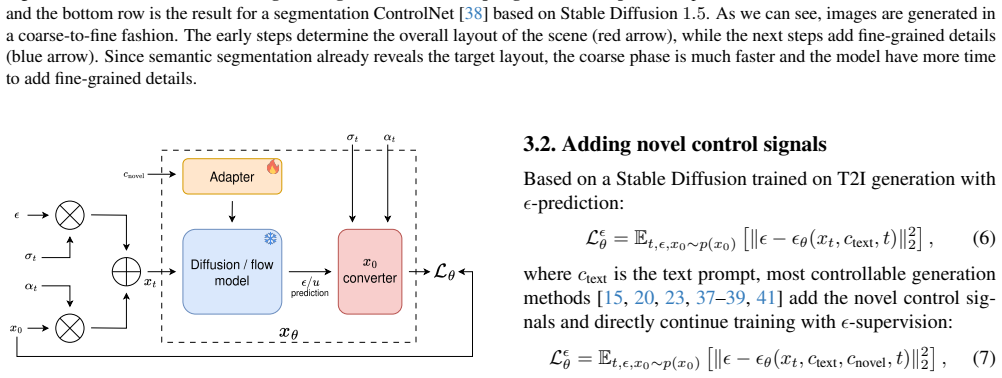
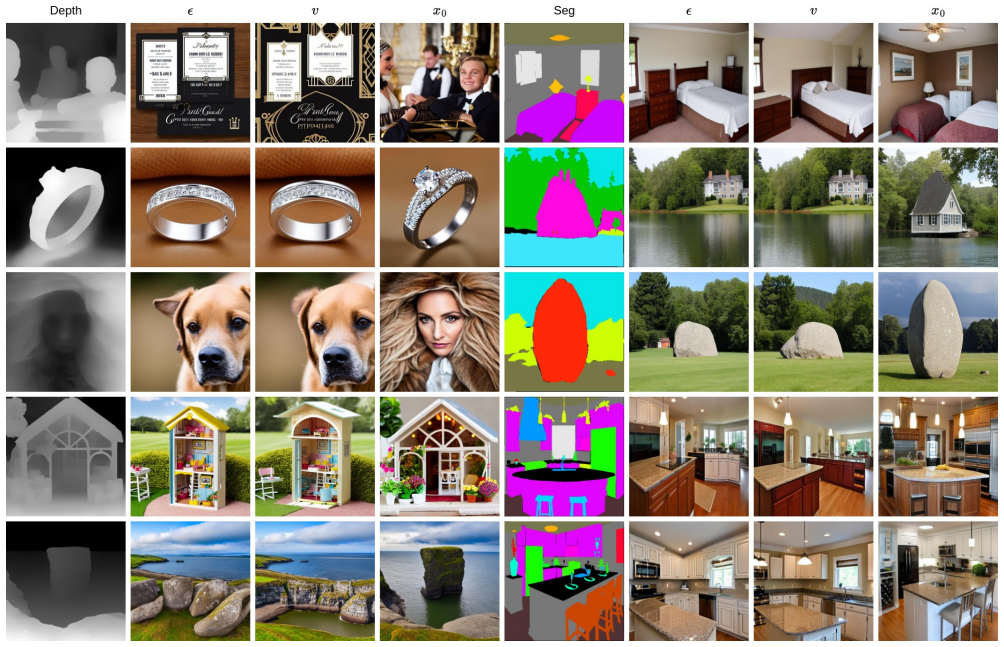
Analysis of the denoising process in models with extra control conditions reveals that the standard training objective creates a mismatch in how the model learns to predict under controls. Switching to direct x0-supervision on the clean target image aligns the training signal better with the control-augmented inputs, resulting in faster convergence up to 2 times faster according to the mean Area Under the Convergence Curve metric and higher visual quality plus conditioning accuracy across multiple control settings.
What carries the argument
x0-supervision, a direct loss on the predicted clean image rather than noise, which reweights the diffusion training objective to better suit additional control signals.
If this is right
- Convergence measured by mAUCC improves by up to 2x in controllable settings.
- Generated images show better visual quality under the same control inputs.
- Accuracy in satisfying additional conditions such as layouts increases.
- The approach works across various control types without needing model-specific changes.
Where Pith is reading between the lines
- The same supervision shift might apply to other generative frameworks like flow models mentioned in the abstract.
- Lower training times could enable more rapid iteration when developing new control mechanisms for image synthesis.
- Reweighting the loss equivalently suggests the benefit comes from emphasizing the clean image prediction in the objective.
Load-bearing premise
The dynamics of denoising with added control conditions are similar enough across signals and architectures that a single change in supervision works universally.
What would settle it
An experiment comparing standard loss training to x0-supervision on identical controllable model setups, tracking mAUCC scores and qualitative control adherence until convergence, to check for the reported speedup and quality gains.
Figures





















read the original abstract
Text-to-Image (T2I) diffusion/flow models have recently achieved remarkable progress in visual fidelity and text alignment. However, they remain limited when users need to precisely control image layouts, something that natural language alone cannot reliably express. Controllable generation methods augment the initial T2I model with additional conditions that more easily describe the scene. Prior works straightforwardly train the augmented network with the same loss as the initial network. Although natural at first glance, this can lead to very long training times in some cases before convergence. In this work, we revisit the training objective of controllable diffusion models through a detailed analysis of their denoising dynamics. We show that direct supervision on the clean target image, dubbed $x_0$-supervision, or an equivalent re-weighting of the diffusion loss, yields faster convergence. Experiments on multiple control settings demonstrate that our formulation accelerates convergence by up to 2$\times$ according to our novel metric (mean Area Under the Convergence Curve - mAUCC), while also improving both visual quality and conditioning accuracy. Our code is available at https://github.com/CEA-LIST/x0-supervision
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that standard training of controllable text-to-image diffusion models is suboptimal due to the denoising dynamics under additional control signals. It proposes x0-supervision (direct supervision on the clean target image x0) or an equivalent re-weighting of the diffusion loss, which accelerates convergence by up to 2x (measured by the new mAUCC metric), while also improving visual quality and conditioning accuracy. This is supported by analysis of the reverse process and experiments across multiple control settings, with code released.
Significance. If the central result holds, the work offers a simple, architecture-agnostic change to the training objective that addresses a practical bottleneck in controllable generation. The denoising-dynamics analysis provides explanatory insight, the mAUCC metric is a useful addition for convergence evaluation, and the empirical gains (faster training plus better metrics) are directly actionable. Releasing code supports reproducibility and adoption.
major comments (1)
- [§3] §3 (Denoising Dynamics Analysis): The claimed equivalence between x0-supervision and the re-weighted loss is derived under the assumption that the control signal modulates the clean-image prediction with timestep-independent scaling. This assumption does not obviously extend to cross-attention injection or cases where control features are themselves diffused; the paper's experiments test only a narrow subset of injection styles, so the generality of the 2× mAUCC gain remains unproven and load-bearing for the central claim.
minor comments (2)
- The abstract and introduction should explicitly list the control-injection mechanisms used in the experiments (e.g., concatenation, cross-attention, etc.) so readers can immediately assess the scope.
- [Experiments] Table or figure captions for the convergence curves should include the exact definition or pseudocode for mAUCC to make the metric self-contained.
Simulated Author's Rebuttal
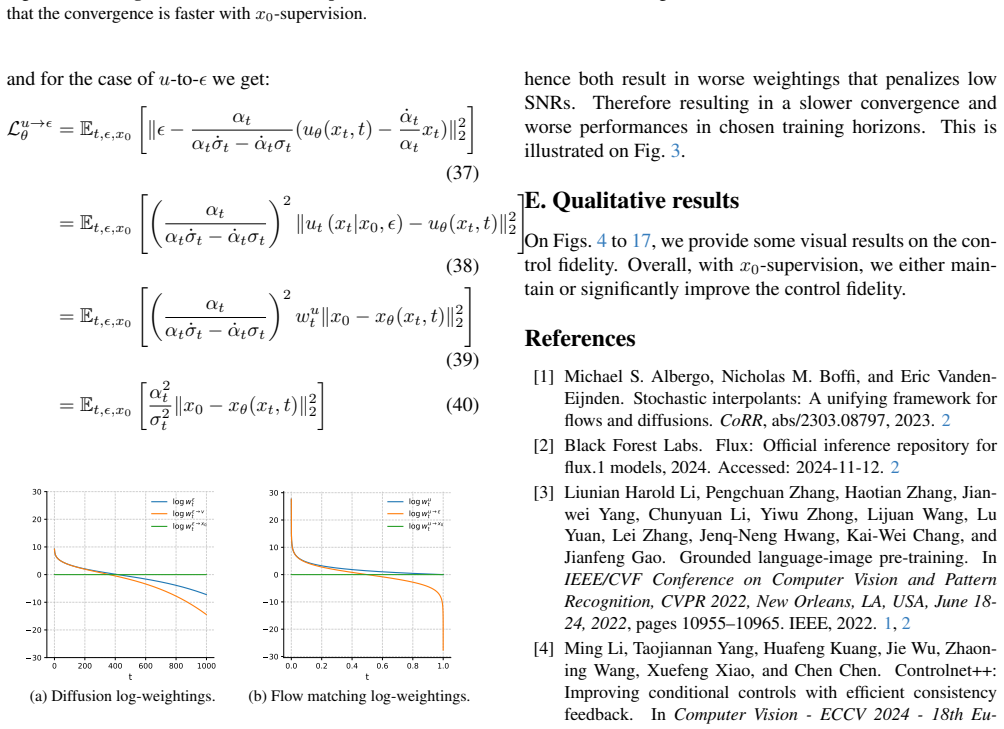
We thank the referee for the positive overall assessment of our work and for the constructive comment regarding the scope of our analysis. We address the concern point by point below.
read point-by-point responses
-
Referee: [§3] §3 (Denoising Dynamics Analysis): The claimed equivalence between x0-supervision and the re-weighted loss is derived under the assumption that the control signal modulates the clean-image prediction with timestep-independent scaling. This assumption does not obviously extend to cross-attention injection or cases where control features are themselves diffused; the paper's experiments test only a narrow subset of injection styles, so the generality of the 2× mAUCC gain remains unproven and load-bearing for the central claim.
Authors: We appreciate the referee's identification of the central assumption underlying the equivalence in §3. The derivation does rely on the control signal providing a timestep-independent modulation to the clean-image prediction, which enables showing that x0-supervision is equivalent to a re-weighted diffusion loss. We agree that this assumption may not hold exactly for all possible injection mechanisms, such as certain forms of cross-attention or when control features are themselves noised. Our experiments do cover multiple control settings that include cross-attention-based conditioning (in addition to other injection styles), and we observe consistent gains in convergence speed according to mAUCC as well as improved quality and accuracy. While the strict equivalence may be architecture-dependent, the practical advantage of direct x0-supervision appears to hold more broadly in the tested cases. To address the concern, we will revise §3 to explicitly state the assumptions and discuss their applicability to different injection styles, thereby clarifying the scope of the claimed gains. revision: partial
Circularity Check
No circularity: x0-supervision derived from independent denoising-dynamics analysis and validated empirically
full rationale
The paper's central derivation analyzes the denoising dynamics of controllable diffusion models to motivate direct x0-supervision or an equivalent loss re-weighting. This analysis is presented as first-principles reasoning on how control signals affect clean-image versus noise prediction, followed by empirical demonstration of faster convergence (via mAUCC) and improved quality across multiple control settings. No step reduces by construction to a fitted parameter, self-citation chain, or tautological renaming; the claimed acceleration is not forced by the objective definition itself but shown through experiments. The derivation remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The denoising dynamics of diffusion models under additional control conditions can be analyzed to derive an improved training objective.
Reference graph
Works this paper leans on
-
[1]
Stochastic Interpolants: A Unifying Framework for Flows and Diffusions
Michael S. Albergo, Nicholas M. Boffi, and Eric Vanden- Eijnden. Stochastic interpolants: A unifying framework for flows and diffusions.CoRR, abs/2303.08797, 2023. 2
work page internal anchor Pith review arXiv 2023
-
[2]
Flux: Official inference repository for flux.1 models, 2024
Black Forest Labs. Flux: Official inference repository for flux.1 models, 2024. Accessed: 2024-11-12. 2
2024
-
[3]
Grounded language-image pre-training
Liunian Harold Li, Pengchuan Zhang, Haotian Zhang, Jian- wei Yang, Chunyuan Li, Yiwu Zhong, Lijuan Wang, Lu Yuan, Lei Zhang, Jenq-Neng Hwang, Kai-Wei Chang, and Jianfeng Gao. Grounded language-image pre-training. In IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2022, New Orleans, LA, USA, June 18- 24, 2022, pages 10955–10965. IEEE, ...
2022
-
[4]
Controlnet++: Improving conditional controls with efficient consistency feedback
Ming Li, Taojiannan Yang, Huafeng Kuang, Jie Wu, Zhaon- ing Wang, Xuefeng Xiao, and Chen Chen. Controlnet++: Improving conditional controls with efficient consistency feedback. InComputer Vision - ECCV 2024 - 18th Eu- ropean Conference, Milan, Italy, September 29-October 4, 2024, Proceedings, Part VII, pages 129–147. Springer, 2024. 2
2024
-
[5]
GLIGEN: open-set grounded text-to-image generation
Yuheng Li, Haotian Liu, Qingyang Wu, Fangzhou Mu, Jianwei Yang, Jianfeng Gao, Chunyuan Li, and Yong Jae Lee. GLIGEN: open-set grounded text-to-image generation. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2023, Vancouver, BC, Canada, June 17- 24, 2023, pages 22511–22521. IEEE, 2023. 1, 2
2023
-
[6]
Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Doll ´ar, and C
Tsung-Yi Lin, Michael Maire, Serge J. Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Doll ´ar, and C. Lawrence Zitnick. Microsoft COCO: common objects in context. InComputer Vision - ECCV 2014 - 13th Eu- ropean Conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part V, pages 740–755. Springer, 2014. 1, 2
2014
-
[7]
Yaron Lipman, Marton Havasi, Peter Holderrieth, Neta Shaul, Matt Le, Brian Karrer, Ricky T. Q. Chen, David Lopez-Paz, Heli Ben-Hamu, and Itai Gat. Flow matching guide and code, 2024. 2
2024
-
[8]
Pseudo numerical methods for diffusion models on manifolds
Luping Liu, Yi Ren, Zhijie Lin, and Zhou Zhao. Pseudo numerical methods for diffusion models on manifolds. In The Tenth International Conference on Learning Represen- tations, ICLR 2022, Virtual Event, April 25-29, 2022. Open- Review.net, 2022. 1
2022
-
[9]
T2i-adapter: Learning adapters to dig out more controllable ability for text-to-image diffusion models
Chong Mou, Xintao Wang, Liangbin Xie, Yanze Wu, Jian Zhang, Zhongang Qi, and Ying Shan. T2i-adapter: Learning adapters to dig out more controllable ability for text-to-image diffusion models. InThirty-Eighth AAAI Conference on Ar- tificial Intelligence, AAAI 2024, Thirty-Sixth Conference on Innovative Applications of Artificial Intelligence, IAAI 2024, Fo...
2024
-
[10]
Vicente Ordonez, Girish Kulkarni, and Tamara L. Berg. Im2text: Describing images using 1 million captioned pho- tographs. InAdvances in Neural Information Processing Systems 24: 25th Annual Conference on Neural Informa- tion Processing Systems 2011. Proceedings of a meeting held 12-14 December 2011, Granada, Spain, pages 1143–1151,
2011
-
[11]
High-resolution image syn- thesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj¨orn Ommer. High-resolution image syn- thesis with latent diffusion models. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2022, New Orleans, LA, USA, June 18-24, 2022, pages 10674– 10685. IEEE, 2022. 2
2022
-
[12]
Progressive distillation for fast sampling of diffusion models
Tim Salimans and Jonathan Ho. Progressive distillation for fast sampling of diffusion models. InThe Tenth International Conference on Learning Representations, ICLR 2022, Vir- tual Event, April 25-29, 2022. OpenReview.net, 2022. 2, 3, 4
2022
-
[13]
Objects365: A large-scale, high-quality dataset for object detection
Shuai Shao, Zeming Li, Tianyuan Zhang, Chao Peng, Gang Yu, Xiangyu Zhang, Jing Li, and Jian Sun. Objects365: A large-scale, high-quality dataset for object detection. In2019 IEEE/CVF International Conference on Computer Vision, ICCV 2019, Seoul, Korea (South), October 27 - November 2, 2019, pages 8429–8438. IEEE, 2019. 1, 2
2019
-
[14]
Conceptual captions: A cleaned, hypernymed, image alt-text dataset for automatic image captioning
Piyush Sharma, Nan Ding, Sebastian Goodman, and Radu Soricut. Conceptual captions: A cleaned, hypernymed, image alt-text dataset for automatic image captioning. In Proceedings of the 56th Annual Meeting of the Associa- tion for Computational Linguistics, ACL 2018, Melbourne, Australia, July 15-20, 2018, Volume 1: Long Papers, pages 2556–2565. Association ...
2018
-
[15]
Score-based generative modeling through stochastic differential equa- tions
Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Ab- hishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equa- tions. InInternational Conference on Learning Represen- tations, 2021. 4
2021
-
[16]
Ominicontrol: Minimal and univer- sal control for diffusion transformer
Zhenxiong Tan, Songhua Liu, Xingyi Yang, Qiaochu Xue, and Xinchao Wang. Ominicontrol: Minimal and univer- sal control for diffusion transformer. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 14940–14950, 2025. 2
2025
-
[17]
Instancediffusion: Instance- level control for image generation
Xudong Wang, Trevor Darrell, Sai Saketh Rambhatla, Ro- hit Girdhar, and Ishan Misra. Instancediffusion: Instance- level control for image generation. InIEEE/CVF Confer- ence on Computer Vision and Pattern Recognition, CVPR 2024, Seattle, WA, USA, June 16-22, 2024, pages 6232–
2024
-
[18]
Florence-2: Advancing a unified representation for a vari- ety of vision tasks
Bin Xiao, Haiping Wu, Weijian Xu, Xiyang Dai, Houdong Hu, Yumao Lu, Michael Zeng, Ce Liu, and Lu Yuan. Florence-2: Advancing a unified representation for a vari- ety of vision tasks. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2024, Seattle, WA, USA, June 16-22, 2024, pages 4818–4829. IEEE, 2024. 1
2024
-
[19]
Adding conditional control to text-to-image diffusion models
Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. Adding conditional control to text-to-image diffusion models. In IEEE/CVF International Conference on Computer Vision, ICCV 2023, Paris, France, October 1-6, 2023, pages 3813–
2023
-
[20]
Scene parsing through ade20k dataset
Bolei Zhou, Hang Zhao, Xavier Puig, Sanja Fidler, Adela Barriuso, and Antonio Torralba. Scene parsing through ade20k dataset. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017. 1, 2 Figure 4. Qualitative results on depth and segmentation ControlNet with the three supervision signals after10k training steps. Figure 5. Qu...
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.