Recognition: 2 theorem links
· Lean TheoremPDMP: Rethinking Balanced Multimodal Learning via Performance-Dominant Modality Prioritization
Pith reviewed 2026-05-10 20:23 UTC · model grok-4.3
The pith
Multimodal models achieve better performance by prioritizing the stronger-performing modality instead of balancing all modalities equally.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
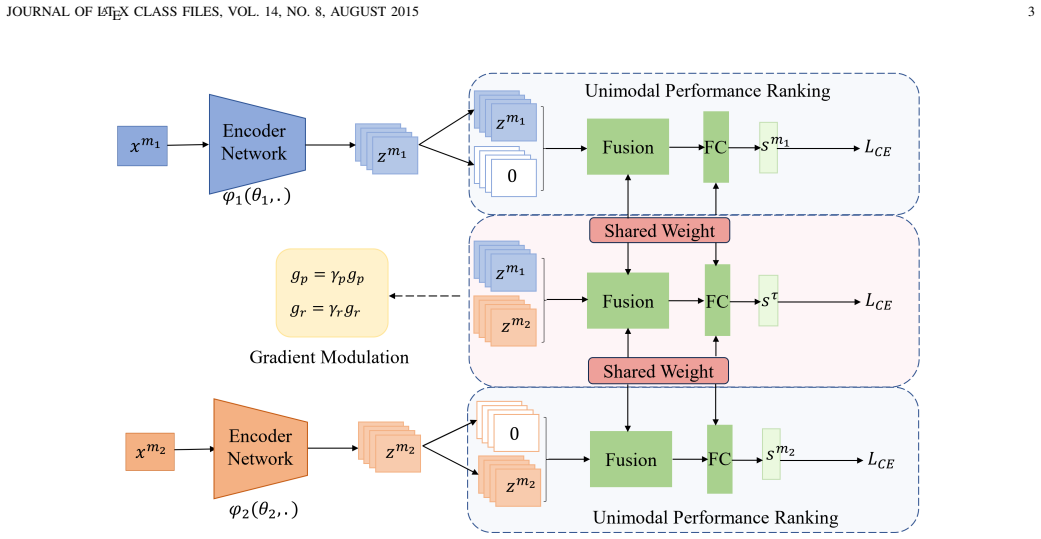
Balanced learning is not the optimal setting for multimodal learning. Imbalanced learning driven by the performance-dominant modality, which has superior unimodal performance, contributes to better multimodal performance. The under-optimization problem is caused by insufficient learning of the performance-dominant modality. PDMP mines this modality from unimodal training rankings and uses asymmetric gradient modulation to let it dominate the optimization process.
What carries the argument
The Performance-Dominant Modality Prioritization (PDMP) strategy, which identifies the top-performing modality from separate unimodal trainings and applies asymmetric coefficients to modulate its gradients higher during joint training.
Load-bearing premise
The modality that performs best in isolation will also be the one whose under-optimization harms the joint model, and modulating its gradients asymmetrically will improve results without causing instability.
What would settle it
Running PDMP on a dataset where forcing the unimodal winner to dominate leads to worse multimodal accuracy than balanced training, or where the ranking from unimodal runs does not match the optimal priority in joint training.
Figures



read the original abstract
Multimodal learning has attracted increasing attention due to its practicality. However, it often suffers from insufficient optimization, where the multimodal model underperforms even compared to its unimodal counterparts. Existing methods attribute this problem to the imbalanced learning between modalities and solve it by gradient modulation. This paper argues that balanced learning is not the optimal setting for multimodal learning. On the contrary, imbalanced learning driven by the performance-dominant modality that has superior unimodal performance can contribute to better multimodal performance. And the under-optimization problem is caused by insufficient learning of the performance-dominant modality. To this end, we propose the Performance-Dominant Modality Prioritization (PDMP) strategy to assist multimodal learning. Specifically, PDMP firstly mines the performance-dominant modality via the performance ranking of the independently trained unimodal model. Then PDMP introduces asymmetric coefficients to modulate the gradients of each modality, enabling the performance-dominant modality to dominate the optimization. Since PDMP only relies on the unimodal performance ranking, it is independent of the structures and fusion methods of the multimodal model and has great potential for practical scenarios. Finally, extensive experiments on various datasets validate the superiority of PDMP.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that balanced multimodal learning is suboptimal and that under-optimization arises from insufficient learning of the performance-dominant modality (identified by superior unimodal performance from independent training). It proposes PDMP, which ranks modalities via separate unimodal models and applies asymmetric gradient coefficients to let the dominant modality drive joint optimization, yielding better multimodal performance. The method is presented as independent of model architecture and fusion strategy, with superiority shown via extensive experiments across datasets.
Significance. If the central claim holds, the work offers a simple, structure-agnostic alternative to existing gradient-modulation approaches for multimodal optimization, potentially improving performance in practical settings where fusion methods vary. The explicit separation of unimodal ranking from the joint training loop avoids circularity and supports broad applicability. Credit is due for the reproducible ranking step and the focus on falsifiable predictions about modality prioritization.
major comments (3)
- [Abstract and §3] Abstract and §3: The core assertion that under-optimization is caused specifically by insufficient learning of the performance-dominant modality (rather than fusion interactions) is load-bearing but lacks direct support. The manuscript should include analysis of per-modality gradient norms or loss contributions during standard joint training to confirm that the unimodal-ranked modality is indeed the bottleneck.
- [§3] §3 (PDMP description): The asymmetric coefficients are introduced to modulate gradients, yet the text does not clarify whether they are fixed a priori, derived from unimodal accuracies, or tuned as hyperparameters. This detail is necessary to evaluate reproducibility and whether the approach truly remains free of additional fitting parameters that could interact with the fusion operator.
- [§4] §4 (Experiments): While 'extensive experiments on various datasets' are cited to validate superiority, the absence of reported baseline details (specific gradient-modulation competitors), ablation on the ranking step versus random prioritization, and statistical significance measures leaves the evidential support for the central claim incomplete and difficult to assess.
minor comments (1)
- The abstract would be strengthened by briefly naming the datasets and reporting the magnitude of improvements over baselines to give readers immediate context for the claimed gains.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below, providing clarifications and committing to revisions that strengthen the evidential basis and reproducibility of the work without altering its core claims.
read point-by-point responses
-
Referee: [Abstract and §3] The core assertion that under-optimization is caused specifically by insufficient learning of the performance-dominant modality (rather than fusion interactions) is load-bearing but lacks direct support. The manuscript should include analysis of per-modality gradient norms or loss contributions during standard joint training to confirm that the unimodal-ranked modality is indeed the bottleneck.
Authors: We agree that direct visualization of per-modality gradient norms and loss contributions during standard joint training would provide stronger, falsifiable support for identifying the performance-dominant modality as the primary bottleneck. While the performance gains from PDMP across datasets offer indirect evidence, we will add this analysis (including gradient norm plots under balanced training) to §3 in the revised manuscript to isolate the effect from fusion interactions. revision: yes
-
Referee: [§3] The asymmetric coefficients are introduced to modulate gradients, yet the text does not clarify whether they are fixed a priori, derived from unimodal accuracies, or tuned as hyperparameters. This detail is necessary to evaluate reproducibility and whether the approach truly remains free of additional fitting parameters that could interact with the fusion operator.
Authors: We appreciate this observation on clarity. The asymmetric coefficients are derived deterministically from the unimodal performance ranking (specifically, scaled proportionally to the accuracy gap between the top-ranked and other modalities) and are not tuned as additional hyperparameters. This keeps the method free of extra fitting parameters beyond the initial ranking. We will revise §3 to include the precise computation formula and confirm its independence from the fusion strategy. revision: yes
-
Referee: [§4] While 'extensive experiments on various datasets' are cited to validate superiority, the absence of reported baseline details (specific gradient-modulation competitors), ablation on the ranking step versus random prioritization, and statistical significance measures leaves the evidential support for the central claim incomplete and difficult to assess.
Authors: We acknowledge that greater experimental transparency is needed. In the revised §4, we will: explicitly name the gradient-modulation baselines (with citations), add an ablation comparing the unimodal ranking step against random prioritization to isolate its contribution, and report statistical significance (e.g., p-values over multiple random seeds). These changes will make the superiority claims more rigorously assessable. revision: yes
Circularity Check
No circularity: prioritization derived from external unimodal ranking independent of joint optimization
full rationale
The paper's core derivation identifies the performance-dominant modality via separate unimodal training and performance ranking, then applies asymmetric gradient modulation in the multimodal phase. This ranking step is external to the joint loss and fusion interactions, with no reduction of the claimed benefit to a quantity defined by the multimodal model's own fitted parameters or self-citations. The argument that imbalanced learning driven by this modality improves performance is presented as an empirical finding validated across datasets, not as a definitional or fitted equivalence. No load-bearing self-citation chains, ansatzes smuggled via prior work, or renaming of known results appear in the provided text.
Axiom & Free-Parameter Ledger
free parameters (1)
- asymmetric coefficients
axioms (1)
- domain assumption Unimodal performance ranking from independently trained models identifies the modality that should dominate multimodal optimization.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
u1/u2 ∝ M1/M2 where Mi := I(si;y) ... optimal modality contribution should allocate larger weights to modalities with stronger predictive relevance
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
PDMP mines the performance-dominant modality via the performance ranking of the independently trained unimodal model ... asymmetric coefficients to modulate the gradients
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Learnable irrelevant modality dropout for multimodal action recognition on modality-specific anno- tated videos,
S. Alfasly, J. Lu, C. Xu, and Y . Zou, “Learnable irrelevant modality dropout for multimodal action recognition on modality-specific anno- tated videos,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 20 208–20 217
2022
-
[2]
One-stage modality distillation for incomplete multimodal learning,
S. Wei, Y . Luo, and C. Luo, “One-stage modality distillation for incomplete multimodal learning,”CoRR, vol. abs/2309.08204, 2023. [Online]. Available: https://doi.org/10.48550/arXiv.2309.08204
-
[3]
S. Wei, C. Luo, and Y . Luo, “MMANet: Margin-aware distillation and modality-aware regularization for incomplete multimodal learning,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023, pp. 20 039–20 049. [Online]. Available: https://doi.org/10.1109/CVPR52729.2023.01919
- [4]
-
[5]
Deep rgb-d saliency detection with depth-sensitive attention and automatic multi-modal fu- sion,
P. Sun, W. Zhang, H. Wang, S. Li, and X. Li, “Deep rgb-d saliency detection with depth-sensitive attention and automatic multi-modal fu- sion,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 1407–1417
2021
-
[6]
Cdnet: Complementary depth network for rgb-d salient object detection,
W.-D. Jin, J. Xu, Q. Han, Y . Zhang, and M.-M. Cheng, “Cdnet: Complementary depth network for rgb-d salient object detection,”IEEE Transactions on Image Processing, vol. 30, pp. 3376–3390, 2021
2021
-
[7]
Unimf: A unified multimodal framework for multimodal sentiment analysis in missing modalities and unaligned multimodal sequences,
R. Huan, G. Zhong, P. Chen, and R. Liang, “Unimf: A unified multimodal framework for multimodal sentiment analysis in missing modalities and unaligned multimodal sequences,”IEEE Transactions on Multimedia, vol. 26, pp. 5753–5768, 2023
2023
-
[8]
Image-text multimodal emotion classification via multi-view attentional network,
X. Yang, S. Feng, D. Wang, and Y . Zhang, “Image-text multimodal emotion classification via multi-view attentional network,”IEEE Trans- actions on Multimedia, vol. 23, pp. 4014–4026, 2020
2020
-
[9]
Dynamically shifting multimodal representations via hybrid-modal attention for multimodal sentiment analysis,
R. Lin and H. Hu, “Dynamically shifting multimodal representations via hybrid-modal attention for multimodal sentiment analysis,”IEEE Transactions on Multimedia, vol. 26, pp. 2740–2755, 2023
2023
-
[10]
Balanced multimodal learning via on-the-fly gradient modulation,
X. Peng, Y . Wei, A. Deng, D. Wang, and D. Hu, “Balanced multimodal learning via on-the-fly gradient modulation,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 8238–8247
2022
-
[11]
Im- proving multi-modal learning with uni-modal teachers,
C. Du, T. Li, Y . Liu, Z. Wen, T. Hua, Y . Wang, and H. Zhao, “Im- proving multi-modal learning with uni-modal teachers,”arXiv preprint arXiv:2106.11059, 2021
-
[12]
Pmr: Prototypical modal rebalance for multimodal learning,
Y . Fan, W. Xu, H. Wang, J. Wang, and S. Guo, “Pmr: Prototypical modal rebalance for multimodal learning,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 20 029–20 038
2023
-
[13]
What makes training multi- modal classification networks hard?
W. Wang, D. Tran, and M. Feiszli, “What makes training multi- modal classification networks hard?” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 12 695–12 705
2020
-
[14]
Boosting multi-modal model performance with adaptive gradient modulation,
H. Li, X. Li, P. Hu, Y . Lei, C. Li, and Y . Zhou, “Boosting multi-modal model performance with adaptive gradient modulation,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 22 214–22 224
2023
-
[15]
Multimodal represen- tation learning by alternating unimodal adaptation,
X. Zhang, J. Yoon, M. Bansal, and H. Yao, “Multimodal represen- tation learning by alternating unimodal adaptation,”arXiv preprint arXiv:2311.10707, 2023
-
[16]
Enhancing multi-modal cooperation via fine-grained modality valuation,
Y . Wei, R. Feng, Z. Wang, and D. Hu, “Enhancing multi-modal cooperation via fine-grained modality valuation,”arXiv preprint arXiv:2309.06255, 2023
-
[17]
S. Wei, C. Luo, X. Ma, and Y . Luo, “Gradient decoupled learning with unimodal regularization for multimodal remote sensing classification,” IEEE Transactions on Geoscience and Remote Sensing, vol. 62, pp. 1–12, 2024. [Online]. Available: https://doi.org/10.1109/TGRS.2024. 3478393
-
[18]
Privileged modality learning via multimodal hallucination,
S. Wei, C. Luo, Y . Luo, and J. Xu, “Privileged modality learning via multimodal hallucination,”IEEE Transactions on Multimedia, vol. 26, pp. 1516–1527, 2024. [Online]. Available: https://doi.org/10. 1109/TMM.2023.3282874
-
[19]
S. Wei, Y . Luo, and C. Luo, “Diversity-guided distillation with modality-center regularization for robust multimodal remote sensing image classification,”IEEE Transactions on Geoscience and Remote Sensing, vol. 61, pp. 1–14, 2023. [Online]. Available: https: //doi.org/10.1109/TGRS.2023.3336297
-
[20]
S. Wei, Y . Luo, X. Ma, P. Ren, and C. Luo, “MSH-Net: Modality- shared hallucination with joint adaptation distillation for remote sensing image classification using missing modalities,”IEEE Transactions on JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2015 10 Geoscience and Remote Sensing, vol. 61, pp. 1–15, 2023. [Online]. Available: https://doi....
-
[21]
Dynamic-hierarchical attention distillation with synergetic instance selection for land cover classification using missing heterogeneity images,
X. Li, L. Lei, Y . Sun, and G. Kuang, “Dynamic-hierarchical attention distillation with synergetic instance selection for land cover classification using missing heterogeneity images,”IEEE Transactions on Geoscience and Remote Sensing, vol. 60, pp. 1–16, 2021
2021
-
[22]
Mars: Motion- augmented rgb stream for action recognition,
N. Crasto, P. Weinzaepfel, K. Alahari, and C. Schmid, “Mars: Motion- augmented rgb stream for action recognition,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 7882–7891
2019
-
[23]
Modality distillation with multiple stream networks for action recognition,
N. C. Garcia, P. Morerio, and V . Murino, “Modality distillation with multiple stream networks for action recognition,” inProceedings of the European Conference on Computer Vision, 2018, pp. 103–118
2018
-
[24]
Shapeconv: Shape-aware convolutional layer for indoor rgb-d semantic segmentation,
J. Cao, H. Leng, D. Lischinski, D. Cohen-Or, C. Tu, and Y . Li, “Shapeconv: Shape-aware convolutional layer for indoor rgb-d semantic segmentation,” inProceedings of the IEEE/CVF International Confer- ence on Computer Vision, 2021, pp. 7088–7097
2021
-
[25]
Acnet: Attention based network to exploit complementary features for rgbd semantic segmentation,
X. Hu, K. Yang, L. Fei, and K. Wang, “Acnet: Attention based network to exploit complementary features for rgbd semantic segmentation,” in2019 IEEE International Conference on Image Processing (ICIP). IEEE, 2019, pp. 1440–1444
2019
-
[26]
Efficient rgb-d semantic segmentation for indoor scene analysis,
D. Seichter, M. K ¨ohler, B. Lewandowski, T. Wengefeld, and H.-M. Gross, “Efficient rgb-d semantic segmentation for indoor scene analysis,” in2021 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2021, pp. 13 525–13 531
2021
-
[27]
Deep audio-visual speech recognition,
T. Afouras, J. S. Chung, A. Senior, O. Vinyals, and A. Zisserman, “Deep audio-visual speech recognition,”IEEE transactions on pattern analysis and machine intelligence, vol. 44, no. 12, pp. 8717–8727, 2018
2018
-
[28]
Multimodal sparse transformer network for audio-visual speech recognition,
Q. Song, B. Sun, and S. Li, “Multimodal sparse transformer network for audio-visual speech recognition,”IEEE Transactions on Neural Networks and Learning Systems, 2022
2022
-
[29]
Mmcosine: Multi-modal cosine loss towards balanced audio-visual fine-grained learning,
R. Xu, R. Feng, S.-X. Zhang, and D. Hu, “Mmcosine: Multi-modal cosine loss towards balanced audio-visual fine-grained learning,” in ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2023, pp. 1–5
2023
-
[30]
Classifier-guided gradient modulation for enhanced multimodal learning,
Z. Guo, T. Jin, J. Chen, and Z. Zhao, “Classifier-guided gradient modulation for enhanced multimodal learning,”Advances in Neural Information Processing Systems, vol. 37, pp. 133 328–133 344, 2024
2024
-
[31]
Facilitating multimodal classification via dynamically learning modality gap,
Y . Yang, F. Wan, Q. Y . Jiang, and Y . Xu, “Facilitating multimodal classification via dynamically learning modality gap,” inAdvances in Neural Information Processing Systems, vol. 37, 2024, pp. 62 108– 62 122
2024
-
[32]
Gmml: Gradient- modulated robustness for imbalance-aware multimodal learning,
Z. Zhang, X. Zhang, Z. Li, Y . Li, and Y . Cao, “Gmml: Gradient- modulated robustness for imbalance-aware multimodal learning,” in Proceedings of the 33rd ACM International Conference on Multimedia, 2025, pp. 7922–7930
2025
-
[33]
Geometric gradient divergence modulation for imbalanced multimodal learning,
D. Hu, X. Jiang, Z. Sun, H. Yang, C. Peng, P. Yan, H. T. Shen, and X. Xu, “Geometric gradient divergence modulation for imbalanced multimodal learning,” inProceedings of the 33rd ACM International Conference on Multimedia, 2025, pp. 1337–1345
2025
-
[34]
Y . Wei and D. Hu, “Mmpareto: Boosting multimodal learning with innocent unimodal assistance,”arXiv preprint arXiv:2405.17730, 2024
-
[35]
Reconboost: Boosting can achieve modality reconcilement,
C. Hua, Q. Xu, S. Bao, Z. Yang, and Q. Huang, “Reconboost: Boosting can achieve modality reconcilement,”arXiv preprint arXiv:2405.09321, 2024
-
[36]
Diagnosing and re-learning for balanced multimodal learning,
Y . Wei, S. Li, R. Feng, and D. Hu, “Diagnosing and re-learning for balanced multimodal learning,” inEuropean Conference on Computer Vision. Springer, 2025, pp. 71–86
2025
-
[37]
Boosting multimodal learning via disentan- gled gradient learning,
S. Wei, C. Luo, and Y . Luo, “Boosting multimodal learning via disentan- gled gradient learning,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2025, pp. 22 879–22 888
2025
-
[38]
Improving multimodal learning via imbalanced learning,
——, “Improving multimodal learning via imbalanced learning,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2025, pp. 2250–2259
2025
-
[39]
T. M. Cover and J. A. Thomas,Elements of Information Theory. Wiley, 2006
2006
-
[40]
The information bottleneck method
N. Tishby, F. C. Pereira, and W. Bialek, “The information bottleneck method,”arXiv preprint physics/0004057, 1999
work page Pith review arXiv 1999
-
[41]
A closer look at memorization in deep networks,
D. Arpit, S. Jastrzebski, N. Ballas, D. Krueger, E. Bengio, M. S. Kanwal, T. Maharaj, A. Fischer, A. Courville, Y . Bengioet al., “A closer look at memorization in deep networks,” inInternational conference on machine learning. PMLR, 2017, pp. 233–242
2017
-
[42]
Co-teaching: Robust training of deep neural networks with extremely noisy labels,
B. Han, Q. Yao, X. Yu, G. Niu, M. Xu, W. Hu, I. Tsang, and M. Sugiyama, “Co-teaching: Robust training of deep neural networks with extremely noisy labels,”Advances in neural information processing systems, vol. 31, 2018
2018
-
[43]
Un- derstanding deep learning (still) requires rethinking generalization,
C. Zhang, S. Bengio, M. Hardt, B. Recht, and O. Vinyals, “Un- derstanding deep learning (still) requires rethinking generalization,” Communications of the ACM, vol. 64, no. 3, pp. 107–115, 2021
2021
-
[44]
Crema-d: Crowd-sourced emotional multimodal actors dataset,
H. Cao, D. G. Cooper, M. K. Keutmann, R. C. Gur, A. Nenkova, and R. Verma, “Crema-d: Crowd-sourced emotional multimodal actors dataset,”IEEE transactions on affective computing, vol. 5, no. 4, pp. 377–390, 2014
2014
-
[45]
Audio-visual event localization in unconstrained videos,
Y . Tian, J. Shi, B. Li, Z. Duan, and C. Xu, “Audio-visual event localization in unconstrained videos,” inProceedings of the European conference on computer vision (ECCV), 2018, pp. 247–263
2018
-
[46]
Look, listen and learn,
R. Arandjelovic and A. Zisserman, “Look, listen and learn,” inProceed- ings of the IEEE international conference on computer vision, 2017, pp. 609–617
2017
-
[47]
Casia-surf cefa: A benchmark for multi-modal cross-ethnicity face anti-spoofing,
A. Liu, Z. Tan, J. Wan, S. Escalera, G. Guo, and S. Z. Li, “Casia-surf cefa: A benchmark for multi-modal cross-ethnicity face anti-spoofing,” inProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, 2021, pp. 1179–1187
2021
-
[48]
UCF101: A Dataset of 101 Human Actions Classes From Videos in The Wild
K. Soomro, A. R. Zamir, and M. Shah, “Ucf101: A dataset of 101 human actions classes from videos in the wild,”arXiv preprint arXiv:1212.0402, 2012
work page internal anchor Pith review arXiv 2012
-
[49]
Vggsound: A large- scale audio-visual dataset,
H. Chen, W. Xie, A. Vedaldi, and A. Zisserman, “Vggsound: A large- scale audio-visual dataset,” inICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2020, pp. 721–725
2020
-
[50]
librosa: Audio and music signal analysis in python,
B. McFee, C. Raffel, D. Liang, D. P. Ellis, M. McVicar, E. Battenberg, and O. Nieto, “librosa: Audio and music signal analysis in python,” in Proceedings of the 14th python in science conference, vol. 8, 2015, pp. 18–25
2015
-
[51]
A dataset and benchmark for large-scale multi- modal face anti-spoofing,
S. Zhang, X. Wang, A. Liu, C. Zhao, J. Wan, S. Escalera, H. Shi, Z. Wang, and S. Z. Li, “A dataset and benchmark for large-scale multi- modal face anti-spoofing,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 919–928
2019
-
[52]
Y . Zhang, N. He, J. Yang, Y . Li, D. Wei, Y . Huang, Y . Zhang, Z. He, and Y . Zheng, “mmformer: Multimodal medical transformer for incomplete multimodal learning of brain tumor segmentation,”arXiv preprint arXiv:2206.02425, 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.