Recognition: no theorem link
RHVI-FDD: A Hierarchical Decoupling Framework for Low-Light Image Enhancement
Pith reviewed 2026-05-10 20:12 UTC · model grok-4.3
The pith
A hierarchical decoupling framework using RHVI transform and frequency separation improves low-light image enhancement by independently correcting color, noise, and details.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
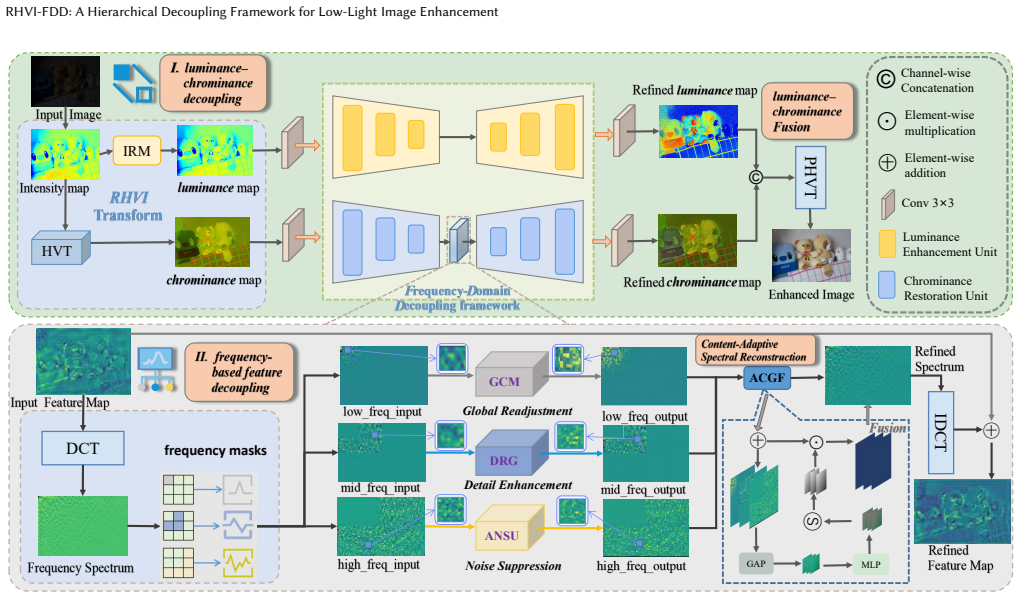
The central claim is that the RHVI-FDD framework mitigates complex coupled degradations in low-light images: the RHVI transform enables robust luminance-chrominance decoupling despite input noise, while the Frequency-Domain Decoupling module decomposes chrominance features via Discrete Cosine Transform into low-, mid-, and high-frequency bands that predominantly represent global tone, local details, and noise, which are then processed independently by tailored expert networks and fused content-aware via an adaptive gating module, yielding consistent gains over prior methods.
What carries the argument
The RHVI transform for macro-level luminance-chrominance decoupling combined with the Frequency-Domain Decoupling module that applies Discrete Cosine Transform for micro-level band separation and expert-network processing.
If this is right
- Consistent outperformance over state-of-the-art methods on multiple low-light datasets in both objective metrics and subjective visual quality.
- Simultaneous correction of color distortion, noise suppression, and detail preservation without the usual trade-offs.
- Improved suitability for downstream multimedia analysis and retrieval tasks that rely on clear low-light inputs.
- The divide-and-conquer frequency handling reduces cross-contamination between tone, details, and noise components.
Where Pith is reading between the lines
- The same hierarchical separation idea could extend to other restoration tasks such as underwater or hazy image enhancement where multiple degradations overlap.
- If the frequency isolation holds, replacing DCT with alternative transforms might yield further gains on datasets with non-standard noise spectra.
- The adaptive gating step suggests that content-aware fusion could be tested in real-time video pipelines to maintain temporal consistency.
Load-bearing premise
That Discrete Cosine Transform decomposition of chrominance features into low-, mid-, and high-frequency bands predominantly isolates global tone, local details, and noise respectively without significant cross-contamination.
What would settle it
If enhanced outputs on test images with known ground-truth low-light versions still exhibit mixed color shifts and residual noise in the same spatial regions where mid-frequency details appear, or if objective metrics fail to improve over baselines on datasets with strong frequency-overlapped noise.
Figures







read the original abstract
Low-light images often suffer from severe noise, detail loss, and color distortion, which hinder downstream multimedia analysis and retrieval tasks. The degradation in low-light images is complex: luminance and chrominance are coupled, while within the chrominance, noise and details are deeply entangled, preventing existing methods from simultaneously correcting color distortion, suppressing noise, and preserving fine details. To tackle the above challenges, we propose a novel hierarchical decoupling framework (RHVI-FDD). At the macro level, we introduce the RHVI transform, which mitigates the estimation bias caused by input noise and enables robust luminance-chrominance decoupling. At the micro level, we design a Frequency-Domain Decoupling (FDD) module with three branches for further feature separation. Using the Discrete Cosine Transform, we decompose chrominance features into low, mid, and high-frequency bands that predominantly represent global tone, local details, and noise components, which are then processed by tailored expert networks in a divide-and-conquer manner and fused via an adaptive gating module for content-aware fusion. Extensive experiments on multiple low-light datasets demonstrate that our method consistently outperforms existing state-of-the-art approaches in both objective metrics and subjective visual quality.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes RHVI-FDD, a hierarchical decoupling framework for low-light image enhancement. At the macro level, the RHVI transform is introduced to achieve robust luminance-chrominance decoupling despite input noise. At the micro level, the Frequency-Domain Decoupling (FDD) module applies the Discrete Cosine Transform to chrominance features, decomposing them into low-, mid-, and high-frequency bands claimed to predominantly represent global tone, local details, and noise, respectively; these are processed by tailored expert networks and fused via an adaptive gating module. The central claim is that this divide-and-conquer strategy enables simultaneous color correction, noise suppression, and detail preservation, with extensive experiments on multiple datasets showing consistent outperformance over state-of-the-art methods in objective metrics and subjective visual quality.
Significance. If the frequency-based separation in the FDD module can be shown to function without substantial cross-contamination, the work would offer a structured approach to handling the coupled degradations (luminance-chrominance coupling and intra-chrominance entanglement) that limit existing low-light enhancement techniques. The hierarchical design and explicit use of DCT for content-aware expert routing could represent a methodological advance over purely empirical CNN or transformer baselines, provided the performance gains are reproducible and the separation assumption holds.
major comments (2)
- [FDD module description] FDD module (micro-level decoupling): The claim that DCT decomposition of chrominance features into low/mid/high-frequency bands 'predominantly represent global tone, local details, and noise components' is load-bearing for the divide-and-conquer premise, yet the manuscript provides no frequency-domain energy analysis, band visualizations, or ablation removing individual experts to quantify cross-contamination. The abstract itself notes that 'within the chrominance, noise and details are deeply entangled,' creating a direct tension with the separation assumption that must be resolved with concrete evidence.
- [Experiments section] Experimental validation: The central claim of 'consistent outperformance' over SOTA methods rests on experiments across multiple datasets, but no details are supplied on baseline implementations, hyperparameter tuning protocols, ablation studies isolating the RHVI and FDD contributions, or statistical significance tests (e.g., paired t-tests on PSNR/SSIM). Without these, it is impossible to rule out post-hoc tuning or dataset-specific effects that would undermine the hierarchical decoupling contribution.
minor comments (1)
- [Abstract] The abstract would benefit from naming the specific low-light datasets used and the primary metrics (PSNR, SSIM, etc.) to allow immediate contextualization of the reported gains.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments. We address each major point below, acknowledging where the manuscript requires strengthening and outlining specific revisions to provide the requested evidence and details.
read point-by-point responses
-
Referee: [FDD module description] FDD module (micro-level decoupling): The claim that DCT decomposition of chrominance features into low/mid/high-frequency bands 'predominantly represent global tone, local details, and noise components' is load-bearing for the divide-and-conquer premise, yet the manuscript provides no frequency-domain energy analysis, band visualizations, or ablation removing individual experts to quantify cross-contamination. The abstract itself notes that 'within the chrominance, noise and details are deeply entangled,' creating a direct tension with the separation assumption that must be resolved with concrete evidence.
Authors: We agree that the frequency separation assumption requires explicit validation to support the divide-and-conquer premise. The abstract's reference to entanglement describes the core challenge that motivates the FDD design, where DCT provides an approximate decomposition into bands that predominantly (not perfectly) align with global tone, details, and noise; the expert networks and adaptive gating are intended to manage residual mixing. To resolve the tension with concrete evidence, the revised manuscript will add: (i) frequency-domain energy distribution analysis showing the predominant content of each band, (ii) visualizations of the decomposed chrominance features, and (iii) ablation studies that remove individual expert branches to quantify performance impact and cross-contamination. These additions will directly substantiate the hierarchical decoupling contribution. revision: yes
-
Referee: [Experiments section] Experimental validation: The central claim of 'consistent outperformance' over SOTA methods rests on experiments across multiple datasets, but no details are supplied on baseline implementations, hyperparameter tuning protocols, ablation studies isolating the RHVI and FDD contributions, or statistical significance tests (e.g., paired t-tests on PSNR/SSIM). Without these, it is impossible to rule out post-hoc tuning or dataset-specific effects that would undermine the hierarchical decoupling contribution.
Authors: We concur that greater experimental transparency is essential for reproducibility and to rigorously support the performance claims. The current manuscript reports results on multiple datasets but omits the requested implementation details. In the revision we will expand the Experiments section to include: full specifications of baseline implementations and hyperparameter tuning protocols, comprehensive ablation studies that isolate the RHVI transform and FDD module contributions, and statistical significance testing (paired t-tests on PSNR/SSIM) across datasets. These changes will eliminate ambiguity regarding post-hoc tuning and strengthen the evidence for the proposed hierarchical approach. revision: yes
Circularity Check
No circularity: empirical NN architecture with external validation
full rationale
The paper describes a hierarchical neural architecture (RHVI transform + FDD module using DCT decomposition of chrominance features) motivated by the stated degradation model. The claim that low/mid/high-frequency bands 'predominantly represent global tone, local details, and noise' is presented as a design premise rather than a derived result. No equations, fitted parameters, or self-citations are shown that reduce any central claim to its own inputs by construction. Validation is performed on standard external low-light datasets, satisfying the criteria for a self-contained empirical contribution. The skeptic concern about cross-contamination is a question of empirical effectiveness, not circularity in the derivation chain.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Melkamu Hunegnaw Asmare, Vijanth Sagayan Asirvadam, and Lila Iznita. 2009. Color space selection for color image enhancement applications. InInternational Conference on Signal Acquisition and Processing. 208–212
2009
-
[2]
Jiesong Bai, Yuhao Yin, Qiyuan He, Yuanxian Li, and Xiaofeng Zhang. 2024. RetinexMamba: Retinex-based mamba for low-light image enhancement. In International Conference on Neural Information Processing. 427–442
2024
-
[3]
Jianrui Cai, Shuhang Gu, and Lei Zhang. 2018. Learning a deep single image contrast enhancer from multi-exposure images.IEEE TIP27, 4 (2018), 2049–2062
2018
-
[4]
Yuanhao Cai, Hao Bian, Jing Lin, Haoqian Wang, Radu Timofte, and Yulun Zhang
-
[5]
Retinexformer: One-stage retinex-based transformer for low-light image enhancement. InICCV. 12504–12513
-
[6]
Chen Chen, Qifeng Chen, Jia Xu, and Vladlen Koltun. 2018. Learning to see in the dark. InCVPR. 3291–3300
2018
-
[7]
Guo-Dong Fan, Bi Fan, Min Gan, Guang-Yong Chen, and CL Philip Chen. 2022. Multiscale low-light image enhancement network with illumination constraint. IEEE TCSVT32, 11 (2022), 7403–7417
2022
-
[8]
2012.Color in Computer Vision: Fundamentals and Applications
Theo Gevers, Arjan Gijsenij, Joost Van de Weijer, and Jan-Mark Geusebroek. 2012.Color in Computer Vision: Fundamentals and Applications. John Wiley & Sons
2012
-
[9]
Michaël Gharbi, Jiawen Chen, Jonathan T Barron, Samuel W Hasinoff, and Frédo Durand. 2017. Deep bilateral learning for real-time image enhancement.ACM TOG36, 4 (2017), 1–12
2017
-
[10]
Chunle Guo, Chongyi Li, Jichang Guo, Chen Change Loy, Junhui Hou, Sam Kwong, and Runmin Cong. 2020. Zero-reference deep curve estimation for low-light image enhancement. InCVPR. 1780–1789
2020
-
[11]
Xiaojie Guo and Qiming Hu. 2023. Low-light image enhancement via breaking down the darkness.IJCV131, 1 (2023), 48–66
2023
-
[12]
Xiaojie Guo, Yu Li, and Haibin Ling. 2016. LIME: Low-light image enhancement via illumination map estimation.IEEE TIP26, 2 (2016), 982–993
2016
-
[13]
Zhiquan He, Wu Ran, Shulin Liu, Kehua Li, Jiawen Lu, Changyong Xie, Yong Liu, and Hong Lu. 2023. Low-light image enhancement with multi-scale attention and frequency-domain optimization.IEEE TCSVT34, 4 (2023), 2861–2875
2023
-
[14]
Sébastien Herbreteau and Charles Kervrann. 2022. DCT2net: An interpretable shallow CNN for image denoising.IEEE TIP31 (2022), 4292–4305
2022
-
[15]
Jinhui Hou, Zhiyu Zhu, Junhui Hou, Hui Liu, Huanqiang Zeng, and Hui Yuan
-
[16]
InNeurIPS, Vol
Global structure-aware diffusion process for low-light image enhancement. InNeurIPS, Vol. 36. 79734–79747
-
[17]
Jie Huang, Yajing Liu, Feng Zhao, Keyu Yan, Jinghao Zhang, Yukun Huang, Man Zhou, and Zhiwei Xiong. 2022. Deep Fourier-based exposure correction network with spatial-frequency interaction. InECCV. 163–180
2022
-
[18]
Patrick Jattke, Victor Van Der Veen, Pietro Frigo, Stijn Gunter, and Kaveh Razavi
-
[19]
InIEEE Symposium on Security and Privacy (SP)
Blacksmith: Scalable rowhammering in the frequency domain. InIEEE Symposium on Security and Privacy (SP). 716–734
-
[20]
Yifan Jiang, Xinyu Gong, Ding Liu, Yu Cheng, Chen Fang, Xiaohui Shen, Jian- chao Yang, Pan Zhou, and Zhangyang Wang. 2021. EnlightenGAN: Deep light enhancement without paired supervision.IEEE TIP30 (2021), 2340–2349
2021
-
[21]
George H Joblove and Donald Greenberg. 1978. Color spaces for computer graph- ics. In5th Annual Conference on Computer Graphics and Interactive Techniques. 20–25
1978
-
[22]
Hasan Huseyin Karaoglu and Ender Mete Eksioglu. 2023. DCTNet: deep shrink- age denoising via DCT filterbanks.Signal, Image and Video Processing17, 7 (2023), 3665–3676
2023
-
[23]
Peter Kellman and Elliot R McVeigh. 2005. Image reconstruction in SNR units: a general method for SNR measurement.Magnetic Resonance in Medicine54, 6 (2005), 1439–1447
2005
-
[24]
Edwin H Land and John J McCann. 1971. Lightness and retinex theory.Journal of the Optical Society of America61, 1 (1971), 1–11
1971
-
[25]
Chulwoo Lee, Chul Lee, and Chang-Su Kim. 2013. Contrast enhancement based on layered difference representation of 2D histograms.IEEE TIP22, 12 (2013), 5372–5384
2013
-
[26]
Michael S Lew, Nicu Sebe, Chabane Djeraba, and Ramesh Jain. 2006. Content- based multimedia information retrieval: State of the art and challenges.ACM Transactions on Multimedia Computing, Communications, and Applications (TOMM)2, 1 (2006), 1–19
2006
-
[27]
Aitor Lewkowycz and Guy Gur-Ari. 2020. On the training dynamics of deep networks with𝐿_2regularization. InNeurIPS, Vol. 33. 4790–4799
2020
-
[28]
Chongyi Li, Chunle Guo, Linghao Han, Jun Jiang, Ming-Ming Cheng, Jinwei Gu, and Chen Change Loy. 2021. Low-Light Image and Video Enhancement Using Deep Learning: A Survey.IEEE TPAMI44, 12 (2021), 9396–9416
2021
-
[29]
Lin Li, Ronggang Wang, Wenmin Wang, and Wen Gao. 2015. A low-light image enhancement method for both denoising and contrast enlarging. InICIP. 3730– 3734
2015
-
[30]
Mading Li, Jiaying Liu, Wenhan Yang, Xiaoyan Sun, and Zongming Guo. 2018. Structure-revealing low-light image enhancement via robust retinex model.IEEE TIP27, 6 (2018), 2828–2841
2018
-
[31]
Xiwen Liang, Xiaoyan Chen, Keying Ren, Xia Miao, Zhihui Chen, and Yutao Jin. 2023. Low-light image enhancement via adaptive frequency decomposition network.Scientific Reports13, 1 (2023), 14107
2023
-
[32]
Jiaying Liu, Dejia Xu, Wenhan Yang, Minhao Fan, and Haofeng Huang. 2021. Benchmarking low-light image enhancement and beyond.IJCV129, 4 (2021), 1153–1184
2021
-
[33]
Risheng Liu, Long Ma, Jiaao Zhang, Xin Fan, and Zhongxuan Luo. 2021. Retinex- inspired unrolling with cooperative prior architecture search for low-light image enhancement. InCVPR. 10561–10570
2021
-
[34]
Kin Gwn Lore, Adedotun Akintayo, and Soumik Sarkar. 2017. LLNet: A deep autoencoder approach to natural low-light image enhancement.PR61 (2017), 650–662
2017
-
[35]
Kede Ma, Kai Zeng, and Zhou Wang. 2015. Perceptual quality assessment for multi-exposure image fusion.IEEE TIP24, 11 (2015), 3345–3356
2015
-
[36]
David Middleton. 2002. Non-Gaussian noise models in signal processing for telecommunications: new methods and results for class A and class B noise models.IEEE Transactions on Information Theory45, 4 (2002), 1129–1149
2002
-
[37]
completely blind
Anish Mittal, Rajiv Soundararajan, and Alan C Bovik. 2012. Making a “completely blind” image quality analyzer.IEEE Sign. Process. Letters20, 3 (2012), 209–212
2012
-
[38]
Asim Niaz, Sareer Ul Amin, Shafiullah Soomro, Hamza Zia, and Kwang Nam Choi. 2024. Spatially aware fusion in 3D convolutional autoencoders for video anomaly detection.IEEE Access(2024)
2024
-
[39]
David R Pauluzzi and Norman C Beaulieu. 2002. A comparison of SNR estimation techniques for the AWGN channel.IEEE Transactions on Communications48, 10 (2002), 1681–1691
2002
-
[40]
Mohammad Saeed Rad, Behzad Bozorgtabar, Urs-Viktor Marti, Max Basler, Hazim Kemal Ekenel, and Jean-Philippe Thiran. 2019. SROBB: Targeted percep- tual loss for single image super-resolution. InICCV. 2710–2719
2019
-
[41]
Ehab Salahat and Murad Qasaimeh. 2017. Recent advances in features extraction and description algorithms: A comprehensive survey. In2017 IEEE international conference on industrial technology (ICIT). IEEE, 1059–1063
2017
-
[42]
Eli Schwartz, Raja Giryes, and Alex M Bronstein. 2018. DeepISP: Toward learning an end-to-end image processing pipeline.IEEE TIP28, 2 (2018), 912–923
2018
-
[43]
George Seif and Dimitrios Androutsos. 2018. Edge-based loss function for single image super-resolution. InICASSP. 1468–1472
2018
-
[44]
Khamar Basha Shaik, P Ganesan, V Kalist, BS Sathish, and J Merlin Mary Jenitha
-
[45]
Comparative study of skin color detection and segmentation in HSV and YCbCr color space.Procedia Computer Science57 (2015), 41–48
2015
-
[46]
Shamik Sural, Gang Qian, and Sakti Pramanik. 2002. Segmentation and histogram generation using the HSV color space for image retrieval. InICIP, Vol. 2. II–II
2002
-
[47]
Zhen Tian, Peixin Qu, Jielin Li, Yukun Sun, Guohou Li, Zheng Liang, and Weidong Zhang. 2023. A survey of deep learning-based low-light image enhancement. Sensors23, 18 (2023), 7763
2023
-
[48]
Vassilios Vonikakis, Rigas Kouskouridas, and Antonios Gasteratos. 2018. On the evaluation of illumination compensation algorithms.Multimedia Tools and Applications77, 8 (2018), 9211–9231
2018
-
[49]
Cong Wang, Jinshan Pan, Wei Wang, Gang Fu, Siyuan Liang, Mengzhu Wang, Xiao-Ming Wu, and Jun Liu. 2024. Correlation matching transformation trans- formers for UHD image restoration. InAAAI, Vol. 38. 5336–5344
2024
-
[50]
Chenxi Wang, Hongjun Wu, and Zhi Jin. 2023. FourLLIE: Boosting low-light image enhancement by fourier frequency information. InACM MM. 7459–7469
2023
-
[51]
Huake Wang, Xiaoyang Yan, Xingsong Hou, Junhui Li, Yujie Dun, and Kaibing Zhang. 2024. Division gets better: Learning brightness-aware and detail-sensitive representations for low-light image enhancement.Knowledge-Based Systems299 (2024), 111958
2024
-
[52]
Li-Wen Wang, Zhi-Song Liu, Wan-Chi Siu, and Daniel PK Lun. 2020. Lightening network for low-light image enhancement.IEEE TIP29 (2020), 7984–7996
2020
-
[53]
Shuhang Wang, Jin Zheng, Hai-Miao Hu, and Bo Li. 2013. Naturalness preserved enhancement algorithm for non-uniform illumination images.IEEE TIP22, 9 (2013), 3538–3548
2013
-
[54]
Tao Wang, Kaihao Zhang, Tianrun Shen, Wenhan Luo, Bjorn Stenger, and Tong Lu. 2023. Ultra-high-definition low-light image enhancement: A benchmark and transformer-based method. InAAAI, Vol. 37. 2654–2662
2023
-
[55]
Wencheng Wang, Xiaojin Wu, Xiaohui Yuan, and Zairui Gao. 2020. An experiment-based review of low-light image enhancement methods.IEEE Access 8 (2020), 87884–87917
2020
-
[56]
Yao Wang and Debargha Mukherjee. 2023. The discrete cosine transform and its impact on visual compression: Fifty years from its invention [perspectives]. IEEE Signal Processing Magazine40, 6 (2023), 14–17
2023
-
[57]
Yufei Wang, Renjie Wan, Wenhan Yang, Haoliang Li, Lap-Pui Chau, and Alex Kot. 2022. Low-light image enhancement with normalizing flow. InAAAI, Vol. 36. 2604–2612
2022
-
[58]
Yu Wang, Quan Zhou, Jia Liu, Jian Xiong, Guangwei Gao, Xiaofu Wu, and Longin Jan Latecki. 2019. LEDNet: A lightweight encoder-decoder network for real-time semantic segmentation. InICIP. 1860–1864
2019
-
[59]
Zhou Wang, Alan C Bovik, Hamid R Sheikh, and Eero P Simoncelli. 2004. Image quality assessment: from error visibility to structural similarity.IEEE TIP13, 4 (2004), 600–612. Yang, et al
2004
-
[60]
Chen Wei, Wenjing Wang, Wenhan Yang, and Jiaying Liu. 2018. Deep retinex de- composition for low-light enhancement.arXiv preprint arXiv:1808.04560(2018)
work page Pith review arXiv 2018
-
[61]
Kaixuan Wei, Ying Fu, Yinqiang Zheng, and Jiaolong Yang. 2021. Physics-based noise modeling for extreme low-light photography.IEEE TPAMI44, 11 (2021), 8520–8537
2021
-
[62]
Wenhui Wu, Jian Weng, Pingping Zhang, Xu Wang, Wenhan Yang, and Jianmin Jiang. 2022. URetinex-Net: Retinex-based deep unfolding network for low-light image enhancement. InCVPR. 5901–5910
2022
-
[63]
Kai Xu, Huaian Chen, Chunmei Xu, Yi Jin, and Changan Zhu. 2022. Structure- texture aware network for low-light image enhancement.IEEE TCSVT32, 8 (2022), 4983–4996
2022
-
[64]
Ke Xu, Xin Yang, Baocai Yin, and Rynson WH Lau. 2020. Learning to restore low-light images via decomposition-and-enhancement. InCVPR. 2281–2290
2020
-
[65]
Xiaogang Xu, Ruixing Wang, Chi-Wing Fu, and Jiaya Jia. 2022. SNR-aware low-light image enhancement. InCVPR. 17714–17724
2022
-
[66]
Xiaogang Xu, Ruixing Wang, and Jiangbo Lu. 2023. Low-light image enhance- ment via structure modeling and guidance. InCVPR. 9893–9903
2023
-
[67]
Yuhao Xu and Hideki Nakayama. 2021. DCT-based fast spectral convolution for deep convolutional neural networks. InInternational Joint Conference on Neural Networks (IJCNN). 1–8
2021
-
[68]
Qingsen Yan, Yixu Feng, Cheng Zhang, Guansong Pang, Kangbiao Shi, Peng Wu, Wei Dong, Jinqiu Sun, and Yanning Zhang. 2025. HVI: A new color space for low-light image enhancement. InCVPR. 5678–5687
2025
-
[69]
Shaoliang Yang, Dongming Zhou, Jinde Cao, and Yanbu Guo. 2023. LightingNet: An integrated learning method for low-light image enhancement.IEEE Transac- tions on Computational Imaging9 (2023), 29–42
2023
-
[70]
Wenhan Yang, Wenjing Wang, Haofeng Huang, Shiqi Wang, and Jiaying Liu
-
[71]
Sparse gradient regularized deep retinex network for robust low-light image enhancement.IEEE TIP30 (2021), 2072–2086
2021
-
[72]
Xunpeng Yi, Han Xu, Hao Zhang, Linfeng Tang, and Jiayi Ma. 2023. Diff-Retinex: Rethinking low-light image enhancement with a generative diffusion model. In ICCV. 12302–12311
2023
-
[73]
Syed Waqas Zamir, Aditya Arora, Salman Khan, Munawar Hayat, Fahad Shahbaz Khan, Ming-Hsuan Yang, and Ling Shao. 2020. Learning enriched features for real image restoration and enhancement. InECCV. 492–511
2020
-
[74]
Syed Waqas Zamir, Aditya Arora, Salman Khan, Munawar Hayat, Fahad Shahbaz Khan, Ming-Hsuan Yang, and Ling Shao. 2022. Learning enriched features for fast image restoration and enhancement.IEEE TPAMI45, 2 (2022), 1934–1948
2022
-
[75]
Kai Zhang, Wangmeng Zuo, and Lei Zhang. 2018. FFDNet: Toward a fast and flexible solution for CNN-based image denoising.IEEE TIP27, 9 (2018), 4608– 4622
2018
-
[76]
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang
-
[77]
The unreasonable effectiveness of deep features as a perceptual metric. In CVPR. 586–595
-
[78]
Yonghua Zhang, Xiaojie Guo, Jiayi Ma, Wei Liu, and Jiawan Zhang. 2021. Beyond brightening low-light images.IJCV129, 4 (2021), 1013–1037
2021
-
[79]
Yonghua Zhang, Jiawan Zhang, and Xiaojie Guo. 2019. Kindling the darkness: A practical low-light image enhancer. InACM MM. 1632–1640
2019
-
[80]
Yuxing Zhao, Yue Li, Xintong Dong, and Baojun Yang. 2018. Low-frequency noise suppression method based on improved DnCNN in desert seismic data. IEEE Geoscience and Remote Sensing Letters16, 5 (2018), 811–815
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.