Measuring What Matters!! Assessing Therapeutic Principles in Mental-Health Conversation
Pith reviewed 2026-05-10 19:04 UTC · model grok-4.3
The pith
CARE framework scores AI mental health responses on six therapeutic principles with 64 percent F1 gain over baseline
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
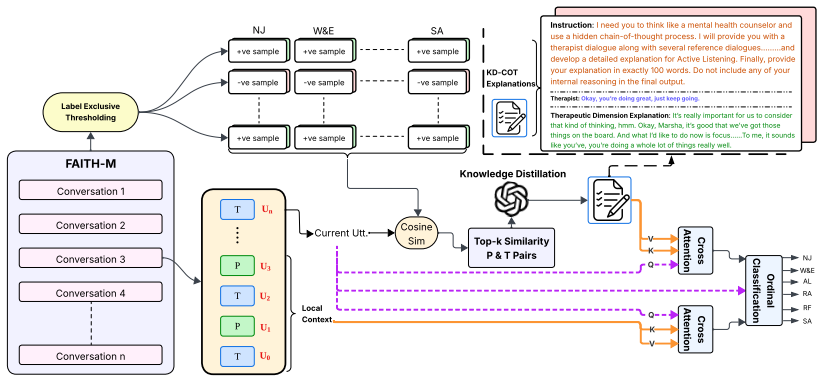
We assess each therapist utterance along six therapeutic principles using a fine-grained ordinal scale. We introduce FAITH-M, a benchmark annotated with expert-assigned ordinal ratings, and propose CARE, a multi-stage evaluation framework that integrates intra-dialogue context, contrastive exemplar retrieval, and knowledge-distilled chain-of-thought reasoning. Experiments show that CARE achieves an F-1 score of 63.34 versus the strong baseline Qwen3 F-1 score of 38.56 which is a 64.26 improvement, indicating that gains arise from structured reasoning and contextual modeling rather than backbone capacity alone.
What carries the argument
The CARE multi-stage evaluation framework, which integrates intra-dialogue context, contrastive exemplar retrieval, and knowledge-distilled chain-of-thought reasoning to measure alignment with therapeutic principles.
Load-bearing premise
That the six selected therapeutic principles adequately and without bias represent clinically grounded appropriateness, with expert ratings serving as trustworthy ground truth.
What would settle it
A calculation showing that the baseline Qwen3 model augmented only with prompting but without CARE's specific stages reaches comparable F1 scores on FAITH-M, or fresh expert annotations that contradict the original ratings on a substantial portion of the benchmark.
Figures






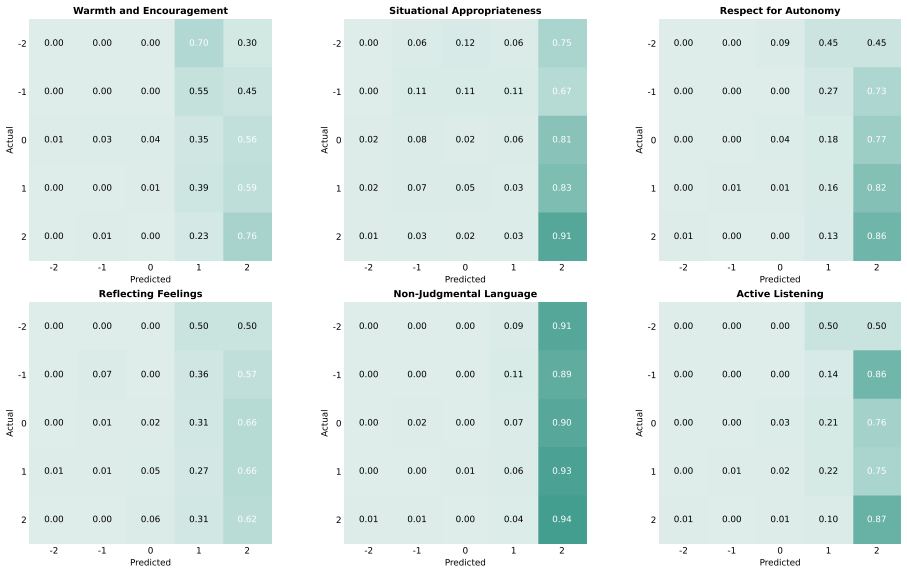
read the original abstract
The increasing use of large language models in mental health applications calls for principled evaluation frameworks that assess alignment with psychotherapeutic best practices beyond surface-level fluency. While recent systems exhibit conversational competence, they lack structured mechanisms to evaluate adherence to core therapeutic principles. In this paper, we study the problem of evaluating AI-generated therapist-like responses for clinically grounded appropriateness and effectiveness. We assess each therapists utterance along six therapeutic principles: non-judgmental acceptance, warmth, respect for autonomy, active listening, reflective understanding, and situational appropriateness using a fine-grained ordinal scale. We introduce FAITH-M, a benchmark annotated with expert-assigned ordinal ratings, and propose CARE, a multi-stage evaluation framework that integrates intra-dialogue context, contrastive exemplar retrieval, and knowledge-distilled chain-of-thought reasoning. Experiments show that CARE achieves an F-1 score of 63.34 versus the strong baseline Qwen3 F-1 score of 38.56 which is a 64.26 improvement, which also serves as its backbone, indicating that gains arise from structured reasoning and contextual modeling rather than backbone capacity alone. Expert assessment and external dataset evaluations further demonstrate robustness under domain shift, while highlighting challenges in modelling implicit clinical nuance. Overall, CARE provides a clinically grounded framework for evaluating therapeutic fidelity in AI mental health systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces FAITH-M, a benchmark of expert-annotated ordinal ratings on six therapeutic principles (non-judgmental acceptance, warmth, respect for autonomy, active listening, reflective understanding, situational appropriateness) for evaluating AI therapist responses, and proposes CARE, a multi-stage framework using intra-dialogue context, contrastive exemplar retrieval, and knowledge-distilled chain-of-thought reasoning. The central result is that CARE achieves an F1 score of 63.34 versus 38.56 for the Qwen3 baseline (a 64% relative improvement), with the gains attributed to the structured components rather than backbone capacity; additional claims include robustness under domain shift via expert assessment and external datasets.
Significance. If the expert ordinal labels prove reliable, this work fills a timely gap by shifting evaluation of mental-health LLMs from surface fluency to adherence to established therapeutic principles. The substantial F1 lift while reusing the same backbone provides evidence that context and reasoning stages can improve fidelity modeling. The creation of FAITH-M as a dedicated benchmark is a concrete contribution that could support future reproducible research in this area.
major comments (2)
- [Abstract] Abstract: The headline claim of a 64.26% relative F1 improvement (63.34 vs. 38.56) is presented as evidence that gains arise from CARE's structured reasoning and contextual modeling. However, the abstract supplies no annotation protocol, number of experts, inter-rater agreement statistics, or disagreement-resolution procedure for the ordinal ratings on FAITH-M. Without these, it is impossible to determine whether the ground-truth labels are stable enough to support the reported numerical gains or whether annotation variance could account for a substantial portion of the difference.
- [Abstract] Abstract and experimental claims: The paper states that the six principles together constitute a sufficient and unbiased measure of clinically grounded appropriateness. No references to clinical validation studies, expert consensus processes, or coverage analysis are provided to justify this selection, which directly affects whether the F1 metric can be interpreted as measuring therapeutic fidelity rather than an ad-hoc proxy.
minor comments (3)
- [Abstract] Abstract: 'therapists utterance' should be 'therapist's utterances' for grammatical correctness.
- [Abstract] Abstract: The phrase '64.26 improvement' is missing the percent sign and should read '64.26% improvement'.
- [Title] Title: The double exclamation marks ('!!') are unconventional in formal academic titles and should be removed.
Simulated Author's Rebuttal
We appreciate the referee's feedback on the abstract and the justification of our therapeutic principles. We have revised the manuscript to incorporate additional details and references as suggested. Our responses to the major comments are provided below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline claim of a 64.26% relative F1 improvement (63.34 vs. 38.56) is presented as evidence that gains arise from CARE's structured reasoning and contextual modeling. However, the abstract supplies no annotation protocol, number of experts, inter-rater agreement statistics, or disagreement-resolution procedure for the ordinal ratings on FAITH-M. Without these, it is impossible to determine whether the ground-truth labels are stable enough to support the reported numerical gains or whether annotation variance could account for a substantial portion of the difference.
Authors: We agree that the abstract would benefit from including these key details to allow readers to evaluate the stability of the ground-truth labels. The annotation protocol, number of experts, inter-rater agreement, and disagreement resolution procedure are described in detail in Section 3 of the manuscript. In the revised version, we have added a summary of this information to the abstract. We have also included an additional experiment in the appendix to assess the robustness of our results to annotation variance, confirming that the reported gains are not primarily driven by label noise. revision: yes
-
Referee: [Abstract] Abstract and experimental claims: The paper states that the six principles together constitute a sufficient and unbiased measure of clinically grounded appropriateness. No references to clinical validation studies, expert consensus processes, or coverage analysis are provided to justify this selection, which directly affects whether the F1 metric can be interpreted as measuring therapeutic fidelity rather than an ad-hoc proxy.
Authors: We thank the referee for raising this important point about the justification of our chosen principles. Although the manuscript draws on established therapeutic literature, we have strengthened the abstract and introduction by adding references to clinical validation studies and expert consensus processes. A brief coverage analysis has been incorporated to demonstrate how these six principles provide a comprehensive yet focused measure of therapeutic appropriateness. This revision helps clarify that the F1 score reflects adherence to clinically grounded principles rather than an arbitrary selection. revision: yes
Circularity Check
No significant circularity; empirical comparison is externally grounded
full rationale
The paper's derivation chain consists of expert-annotated ground truth on FAITH-M (six therapeutic principles rated on an ordinal scale) followed by an empirical F1 comparison of the CARE multi-stage framework against a direct Qwen3 baseline. The benchmark labels are supplied by external experts and are independent of CARE's internal stages or any fitted parameters derived from the same data. The reported 64% relative lift is measured against an external model and attributed to added context, retrieval, and reasoning modules rather than backbone capacity. No equation, self-citation, or uniqueness theorem reduces the final metric to a re-expression of the inputs; the evaluation remains falsifiable against the held-out expert annotations.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The six therapeutic principles (non-judgmental acceptance, warmth, respect for autonomy, active listening, reflective understanding, situational appropriateness) are the appropriate dimensions for assessing clinical appropriateness of therapist utterances.
invented entities (2)
-
FAITH-M benchmark
no independent evidence
-
CARE framework
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We assess each therapist utterance along six therapeutic principles... using a fine-grained ordinal scale. We introduce FAITH-M... and propose CARE, a multi-stage evaluation framework that integrates intra-dialogue context, contrastive exemplar retrieval, and knowledge-distilled chain-of-thought reasoning.
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Experiments show that CARE achieves an F-1 score of 63.34 versus the strong baseline Qwen3 F-1 score of 38.56
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Empcrl: Controllable empathetic response generation via in-context commonsense reasoning and reinforcement learning. InProceedings of the 2024 Joint International Conference on Computa- tional Linguistics, Language Resources and Evalua- tion (LREC-COLING 2024), pages 5734–5746. J. Cha, S. Kim, and E. Park. 2022. A lexicon-based approach to examine depress...
work page 2024
-
[2]
The distress analysis interview corpus of human and computer interviews. InProceedings of the Ninth International Conference on Language Resources and Evaluation (LREC‘14), pages 3123– 3128, Reykjavik, Iceland. European Language Re- sources Association (ELRA). Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al- D...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
Figurative-cum-commonsense knowledge in- fusion for multimodal mental health meme classifica- tion. InProceedings of the ACM on Web Conference 2025, WWW ’25, page 637–648, New York, NY , USA. Association for Computing Machinery. Nils Reimers and Iryna Gurevych. 2019. Sentence- BERT: Sentence embeddings using Siamese BERT- networks. InProceedings of the 20...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Empbot: A t5-based empathetic chatbot focusing on sentiments. Appendix A Baseline Methods We benchmarkCARE against a diverse set of prompt- based and trainable baselines under a unified ex- perimental setup. All baselines use the same local context window (k= 2 ) and, where applicable, are trained with the same ordinal-aware loss function (Equation 1). (a...
work page 2024
-
[5]
are evaluated without task-specific fine- tuning to gauge the upper bound of out-of-the-box performance.(b) Few-shot LLMs:We further extend this by evaluating GPT-4o under few-shot prompting 8, using carefully constructed in-context examples (Appendix 6) to examine whether per- formance improves with light in-context supervi- sion. A detailed analysis of ...
work page 2021
-
[6]
and its domain-adapted variant MentalBART (Yang et al., 2023) assess the utility of sequence-to- sequence pretraining for dialogue-level classifica- tion tasks;(e) Decoder-only LLMs:Qwen3 (Yang et al., 2025), LLaMA 3.1/3.2 (Grattafiori et al., 2024), Phi-4 (Abdin et al., 2025), and Gemma (Team et al., 2024) probe the limits of autoregres- sive generators ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.