Recognition: no theorem link
Learn to Rank: Visual Attribution by Learning Importance Ranking
Pith reviewed 2026-05-10 19:48 UTC · model grok-4.3
The pith
A method learns to rank pixel importance by directly optimizing deletion and insertion scores using a differentiable relaxation of sorting.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors claim that framing visual attribution as importance ranking and replacing hard sorting with the Gumbel-Sinkhorn differentiable relaxation allows direct optimization of deletion and insertion metrics. This produces an end-to-end trainable explainer that perturbs the target model during training and yields sharper, boundary-aligned, pixel-level attributions at inference time, with measured quantitative gains especially on transformer-based vision models.
What carries the argument
The Gumbel-Sinkhorn relaxation of sorting, which converts the discrete ranking operation into a differentiable soft permutation matrix that supports gradient flow when computing deletion and insertion metrics.
If this is right
- Attribution maps can be produced in a single forward pass after training instead of repeated expensive perturbations.
- Explanations become denser and more pixel-precise rather than limited to patch-level outputs on transformers.
- The same trained explainer works across different target models once the ranking-based training is complete.
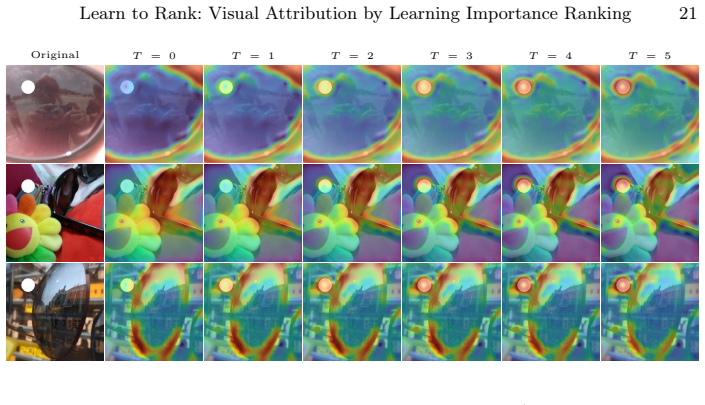
- Optional few-step gradient refinement can be applied post hoc to further sharpen the maps without retraining.
Where Pith is reading between the lines
- The ranking formulation might transfer to explanation tasks in other domains where ordered feature importance is meaningful.
- If the relaxation remains stable, the approach could reduce the cost barrier that currently separates perturbation-based causal methods from fast learning-based ones.
- Wider adoption would depend on whether the learned attributions remain reliable when the target model is updated or fine-tuned.
Load-bearing premise
The Gumbel-Sinkhorn relaxation must be accurate enough that gradients through the relaxed ranking can effectively drive optimization of the original non-differentiable deletion and insertion metrics.
What would settle it
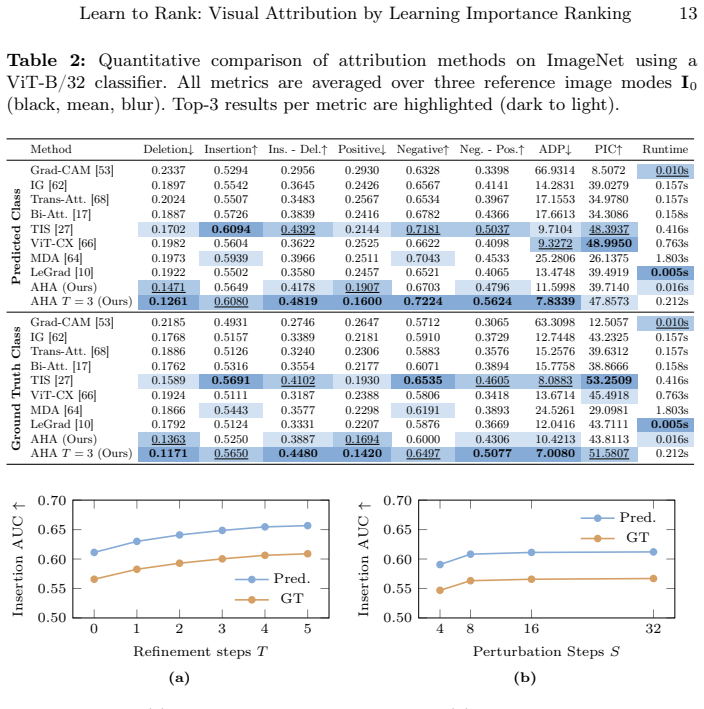
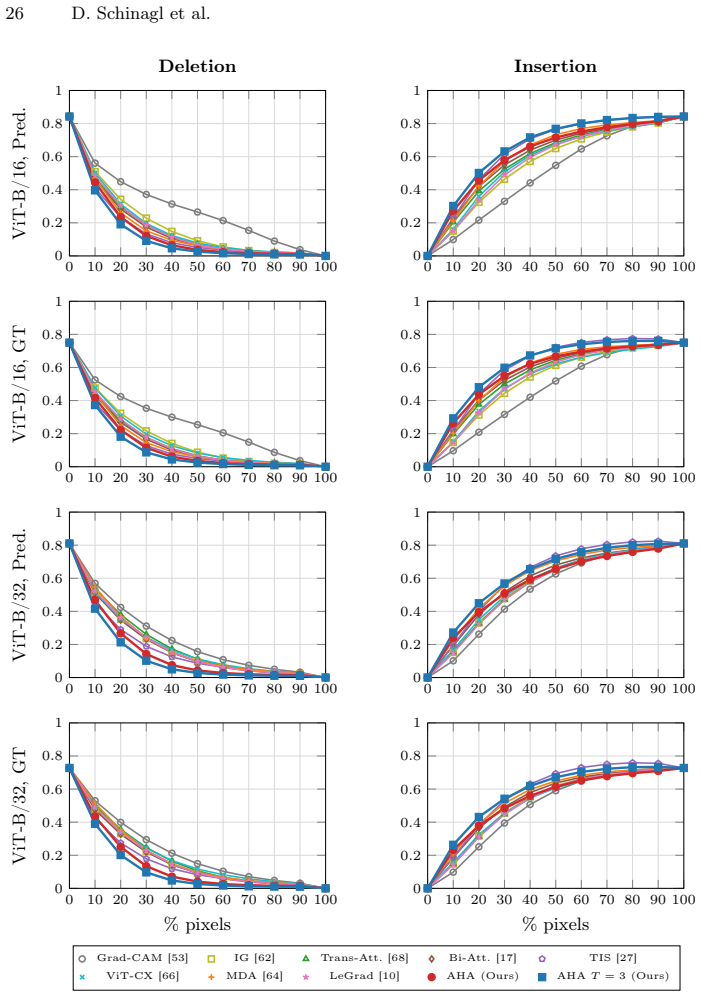
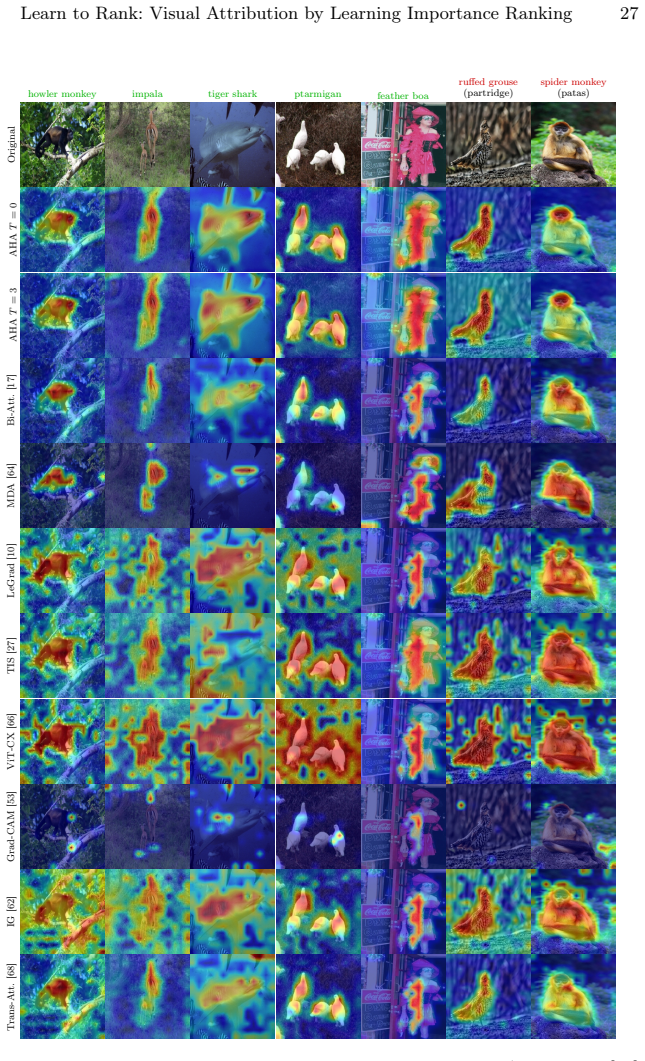
Measure deletion and insertion scores of the learned attributions against existing baselines on a held-out ImageNet validation set using vision transformer backbones; the claim is falsified if no consistent improvement in those scores or in boundary alignment appears.
Figures





read the original abstract
Interpreting the decisions of complex computer vision models is crucial to establish trust and accountability, especially in safety-critical domains. An established approach to interpretability is generating visual attribution maps that highlight regions of the input most relevant to the model's prediction. However, existing methods face a three-way trade-off. Propagation-based approaches are efficient, but they can be biased and architecture-specific. Meanwhile, perturbation-based methods are causally grounded, yet they are expensive and for vision transformers often yield coarse, patch-level explanations. Learning-based explainers are fast but usually optimize surrogate objectives or distill from heuristic teachers. We propose a learning scheme that instead optimizes deletion and insertion metrics directly. Since these metrics depend on non-differentiable sorting and ranking, we frame them as permutation learning and replace the hard sorting with a differentiable relaxation using Gumbel-Sinkhorn. This enables end-to-end training through attribution-guided perturbations of the target model. During inference, our method produces dense, pixel-level attributions in a single forward pass with optional, few-step gradient refinement. Our experiments demonstrate consistent quantitative improvements and sharper, boundary-aligned explanations, particularly for transformer-based vision models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a learning-based visual attribution method that directly optimizes deletion and insertion metrics by framing ranking as a permutation learning problem. It replaces hard sorting with a Gumbel-Sinkhorn differentiable relaxation to enable end-to-end training of an attribution network via attribution-guided perturbations. At inference, it produces dense pixel-level attributions in a single forward pass (with optional few-step gradient refinement) and claims consistent quantitative improvements plus sharper, boundary-aligned explanations, especially for transformer-based vision models.
Significance. If the Gumbel-Sinkhorn relaxation proves accurate at scale, the approach would usefully combine the speed of learned explainers with the causal grounding of perturbation methods, addressing a noted weakness of current ViT attribution techniques. The direct optimization of the target metrics (rather than surrogates) is a conceptually strong contribution, and the focus on dense pixel-level output for transformers fills a practical gap. However, the absence of any quantitative results, baselines, or ablation details in the abstract makes the magnitude of improvement impossible to assess from the provided text.
major comments (2)
- [Method (Gumbel-Sinkhorn relaxation and training objective)] The central claim depends on the Gumbel-Sinkhorn relaxation yielding gradients that meaningfully optimize the non-differentiable deletion/insertion scores for dense pixel rankings (~50k elements for 224×224 images). No equation or experiment in the manuscript demonstrates that the soft permutation matrix correlates tightly with the hard metric or that the learned attributions remain stable under temperature annealing; this is load-bearing for the end-to-end training argument.
- [Abstract and Experiments section] The abstract asserts 'consistent quantitative improvements' and 'sharper, boundary-aligned explanations' yet supplies no numbers, baseline comparisons, statistical tests, ablation studies, or dataset details. Without these, the support for the central claim cannot be evaluated.
minor comments (1)
- [Abstract] The abstract would be strengthened by including at least one key quantitative result (e.g., deletion/insertion AUC deltas versus a standard baseline) to substantiate the improvement claims.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the potential of our end-to-end optimization approach. We address each major comment below and will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Method (Gumbel-Sinkhorn relaxation and training objective)] The central claim depends on the Gumbel-Sinkhorn relaxation yielding gradients that meaningfully optimize the non-differentiable deletion/insertion scores for dense pixel rankings (~50k elements for 224×224 images). No equation or experiment in the manuscript demonstrates that the soft permutation matrix correlates tightly with the hard metric or that the learned attributions remain stable under temperature annealing; this is load-bearing for the end-to-end training argument.
Authors: We agree that explicit validation of the relaxation's fidelity is important for the end-to-end claim. The manuscript already defines the Gumbel-Sinkhorn operator and its temperature-controlled soft permutation matrix in Section 3.2 (Equation 4), drawing on its established convergence properties to the hard permutation as temperature approaches zero. However, to directly address the referee's concern, we will add a new subsection with an empirical study: we will report Pearson correlation between soft and hard deletion/insertion scores across a range of temperatures on held-out images, plus stability plots under annealing schedules. This addition will be placed in the Experiments section and will not alter the core method. revision: yes
-
Referee: [Abstract and Experiments section] The abstract asserts 'consistent quantitative improvements' and 'sharper, boundary-aligned explanations' yet supplies no numbers, baseline comparisons, statistical tests, ablation studies, or dataset details. Without these, the support for the central claim cannot be evaluated.
Authors: We acknowledge that the current abstract is high-level and does not contain numerical results. The full manuscript already reports these details in Section 4, including deletion/insertion AUC improvements over baselines (e.g., Grad-CAM, RISE, and learned explainers) on ImageNet and additional datasets, with statistical significance via paired t-tests, ablations on temperature and refinement steps, and qualitative boundary-alignment metrics. To resolve the referee's valid point, we will revise the abstract to include the key quantitative gains, mention the primary datasets, and briefly note the ablation findings. This change will make the claims evaluable from the abstract while preserving its length constraints. revision: yes
Circularity Check
No circularity: derivation introduces independent relaxation and objective
full rationale
The paper's chain frames deletion/insertion metrics as a permutation-learning problem and substitutes hard ranking with the Gumbel-Sinkhorn relaxation to enable end-to-end gradient training. This is presented as a new scheme rather than a re-derivation of prior fitted quantities. No equation reduces the learned attributions or the optimized metrics back to the inputs by construction, and no load-bearing uniqueness theorem or self-citation is invoked to force the result. The central claim therefore remains an independent modeling choice whose validity rests on empirical correlation between the relaxed and hard objectives, not on definitional equivalence.
Axiom & Free-Parameter Ledger
free parameters (1)
- Gumbel-Sinkhorn temperature
axioms (2)
- domain assumption Deletion and insertion metrics are appropriate causal proxies for attribution quality.
- domain assumption The differentiable relaxation preserves sufficient gradient signal for end-to-end training.
Reference graph
Works this paper leans on
-
[1]
In: ACL (2020)
Abnar, S., Zuidema, W.: Quantifying Attention Flow in Transformers. In: ACL (2020)
2020
-
[2]
In: NeurIPS (2018)
Adebayo, J., Gilmer, J., Muelly, M., Goodfellow, I., Hardt, M., Kim, B.: Sanity Checks for Saliency Maps. In: NeurIPS (2018)
2018
-
[3]
In: ICCV (2025)
Alshami, E., Agnihotri, S., Schiele, B., Keuper, M.: AIM: Amending Inherent In- terpretability via Self-Supervised Masking. In: ICCV (2025)
2025
-
[4]
Anders, C.J., Weber, L., Neumann, D., Samek, W., Müller, K.R., Lapuschkin, S.: Finding and Removing Clever Hans: Using Explanation Methods to Debug and Improve Deep Models. Inf. Fusion77, 261–295 (Jan 2022)
2022
-
[5]
In: NeurIPS (2024)
Arya, S., Rao, S., Böhle, M., Schiele, B.: B-cosification: Transforming Deep Neural Networks to be Inherently Interpretable. In: NeurIPS (2024)
2024
-
[6]
PLOS ONE10(7), 1–46 (2015)
Bach, S., Binder, A., Montavon, G., Klauschen, F., Müller, K.R., Samek, W.: On Pixel-Wise Explanations for Non-Linear Classifier Decisions by Layer-Wise Relevance Propagation. PLOS ONE10(7), 1–46 (2015)
2015
-
[7]
In: ICML Work- shops (2023)
Bhalla, U., Srinivas, S., Lakkaraju, H.: Verifiable Feature Attributions: A Bridge between Post Hoc Explainability and Inherent Interpretability. In: ICML Work- shops (2023)
2023
-
[8]
In: ICML (2020)
Blondel, M., Teboul, O., Berthet, Q., Djolonga, J.: Fast differentiable sorting and ranking. In: ICML (2020)
2020
-
[9]
In: CVPR (2022)
Böhle, M., Fritz, M., Schiele, B.: B-Cos Networks: Alignment Is All We Need for Interpretability. In: CVPR (2022)
2022
-
[10]
In: ICCV (2025)
Bousselham, W., Boggust, A., Chaybouti, S., Strobelt, H., Kuehne, H.: LeGrad: An Explainability Method for Vision Transformers via Feature Formation Sensitivity. In: ICCV (2025)
2025
-
[11]
In: WACV (2022)
Boyd, A., Bowyer, K.W., Czajka, A.: Human-Aided Saliency Maps Improve Gen- eralization of Deep Learning. In: WACV (2022)
2022
-
[12]
In: ICCV (2021) 16 D
Caron, M., Touvron, H., Misra, I., Jégou, H., Mairal, J., Bojanowski, P., Joulin, A.: Emerging Properties in Self-Supervised Vision Transformers. In: ICCV (2021) 16 D. Schinagl et al
2021
-
[13]
In: WACV (2018)
Chattopadhay, A., Sarkar, A., Howlader, P., Balasubramanian, V.N.: Grad- CAM++:GeneralizedGradient-BasedVisualExplanationsforDeepConvolutional Networks. In: WACV (2018)
2018
-
[14]
In: ICCV (2021)
Chefer, H., Gur, S., Wolf, L.: Generic Attention-Model Explainability for Inter- preting Bi-Modal and Encoder-Decoder Transformers. In: ICCV (2021)
2021
-
[15]
In: CVPR (2021)
Chefer, H., Gur, S., Wolf, L.: Transformer Interpretability Beyond Attention Vi- sualization. In: CVPR (2021)
2021
-
[16]
In: NeurIPS (2019)
Chen, C., Li, O., Tao, D., Barnett, A., Rudin, C., Su, J.K.: This Looks Like That: Deep Learning for Interpretable Image Recognition. In: NeurIPS (2019)
2019
-
[17]
TMLR (2023)
Chen, J., Li, X., Yu, L., Dou, D., Xiong, H.: Beyond Intuition: Rethinking Token Attributions inside Transformers. TMLR (2023)
2023
-
[18]
In: ICML (2018)
Chen, J., Song, L., Wainwright, M.J., Jordan, M.I.: Learning to explain: An information-theoretic perspective on model interpretation. In: ICML (2018)
2018
-
[19]
In: CVPR (2025)
Chen, R., Liang, S., Li, J., Liu, S., Li, M., Huang, Z., Zhang, H., Cao, X.: In- terpreting Object-level Foundation Models via Visual Precision Search. In: CVPR (2025)
2025
-
[20]
In: ICLR (2024)
Chen, R., Zhang, H., Liang, S., Li, J., Cao, X.: Less is More: Fewer Interpretable Region via Submodular Subset Selection. In: ICLR (2024)
2024
-
[21]
In: Advances in Neural Information Processing Systems (2024)
Covert, I., Kim, C., Lee, S.I., Zou, J., Hashimoto, T.: Stochastic Amortization: A Unified Approach to Accelerate Feature and Data Attribution. In: Advances in Neural Information Processing Systems (2024)
2024
-
[22]
In: CVPR (2009)
Deng, J., Dong, W., Socher, R., Li, L.J., Li, K., Fei-Fei, L.: ImageNet: A Large- Scale Hierarchical Image Database. In: CVPR (2009)
2009
-
[23]
In: WACV (2020)
Desai, S., Ramaswamy, H.G.: Ablation-CAM: Visual Explanations for Deep Con- volutional Network via Gradient-free Localization. In: WACV (2020)
2020
-
[24]
In: CVPR (2022)
Donnelly, J., Barnett, A.J., Chen, C.: Deformable ProtoPNet: An Interpretable Image Classifier Using Deformable Prototypes. In: CVPR (2022)
2022
-
[25]
In: ICLR (2021)
Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., Uszkoreit, J., Houlsby, N.: An image is worth 16x16 words: Transformers for image recognition at scale. In: ICLR (2021)
2021
-
[26]
Use hirescam instead of grad-cam for faithful explanations of convolutional neural networks,
Draelos, R.L., Carin, L.: Use HiResCAM instead of Grad-CAM for faithful expla- nations of convolutional neural networks. arXiv:2011.08891 (2020)
-
[27]
In: ICCV Workshops (2023)
Englebert, A., Stassin, S., Nanfack, G., Mahmoudi, S.A., Siebert, X., Cornu, O., De Vleeschouwer, C.: Explaining Through Transformer Input Sampling. In: ICCV Workshops (2023)
2023
-
[28]
In: CVPR (2023)
Fel, T., Ducoffe, M., Vigouroux, D., Cadène, R., Capelle, M., Nicodème, C., Serre, T.: Don’t Lie to Me! Robust and Efficient Explainability With Verified Perturba- tion Analysis. In: CVPR (2023)
2023
-
[29]
In: ICCV (2019)
Fong, R., Patrick, M., Vedaldi, A.: Understanding Deep Networks via Extremal Perturbations and Smooth Masks. In: ICCV (2019)
2019
-
[30]
In: ICCV (2017)
Fong, R.C., Vedaldi, A.: Interpretable Explanations of Black Boxes by Meaningful Perturbation. In: ICCV (2017)
2017
-
[31]
In: CVPR (2022)
He, K., Chen, X., Xie, S., Li, Y., Dollár, P., Girshick, R.: Masked Autoencoders Are Scalable Vision Learners. In: CVPR (2022)
2022
-
[32]
In: CVPR (2016)
He, K., Zhang, X., Ren, S., Sun, J.: Deep Residual Learning for Image Recognition. In: CVPR (2016)
2016
-
[33]
In: ICLR (2022) Learn to Rank: Visual Attribution by Learning Importance Ranking 17
Jethani, N., Sudarshan, M., Covert, I.C., Lee, S.I., Ranganath, R.: FastSHAP: Real-Time Shapley Value Estimation. In: ICLR (2022) Learn to Rank: Visual Attribution by Learning Importance Ranking 17
2022
-
[34]
IEEE Transactions on Image Processing30, 5875–5888 (2021)
Jiang, P.T., Zhang, C.B., Hou, Q., Cheng, M.M., Wei, Y.: LayerCAM: Exploring Hierarchical Class Activation Maps for Localization. IEEE Transactions on Image Processing30, 5875–5888 (2021)
2021
-
[35]
In: ICCV (2021)
Jung, H., Oh, Y.: Towards Better Explanations of Class Activation Mapping. In: ICCV (2021)
2021
-
[36]
In: ICCV (2019)
Kapishnikov, A., Bolukbasi, T., Viegas, F., Terry, M.: XRAI: Better Attributions Through Regions. In: ICCV (2019)
2019
-
[37]
In: CVPR (2021)
Kapishnikov, A., Venugopalan, S., Avci, B., Wedin, B., Terry, M., Bolukbasi, T.: Guided Integrated Gradients: An Adaptive Path Method for Removing Noise. In: CVPR (2021)
2021
-
[38]
In: ICML (2020)
Koh, Pang Wei and Nguyen, Thao and Tang, Yew Siang and Mussmann, Stephen and Pierson, Emma and Kim, Been and Liang, Percy: Concept Bottleneck Models. In: ICML (2020)
2020
-
[39]
In: AAAI (2018)
Li, O., Liu, H., Chen, C., Rudin, C.: Deep Learning for Case-Based Reasoning through Prototypes: A Neural Network that Explains Its Predictions. In: AAAI (2018)
2018
-
[40]
In: ICCV (2021)
Liu, Z., Lin, Y., Cao, Y., Hu, H., Wei, Y., Zhang, Z., Lin, S., Guo, B.: Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. In: ICCV (2021)
2021
-
[41]
In: CVPR (2022)
Liu, Z., Mao, H., Wu, C.Y., Feichtenhofer, C., Darrell, T., Xie, S.: A ConvNet for the 2020s. In: CVPR (2022)
2022
-
[42]
In: NeurIPS (2017)
Lundberg, S.M., Lee, S.I.: A Unified Approach to Interpreting Model Predictions. In: NeurIPS (2017)
2017
-
[43]
In: ICLR (2018)
Mena, G., Belanger, D., Linderman, S., Snoek, J.: Learning Latent Permutations with Gumbel-Sinkhorn Networks. In: ICLR (2018)
2018
-
[44]
In: ICML (2024)
Muzellec, S., Fel, T., Boutin, V., Andéol, L., VanRullen, R., Serre, T.: Saliency strikes back: how filtering out high frequencies improves white-box explanations. In: ICML (2024)
2024
-
[45]
In: CVPR (2021)
Nauta, M., van Bree, R., Seifert, C.: Neural Prototype Trees for Interpretable Fine-Grained Image Recognition. In: CVPR (2021)
2021
-
[46]
In: ICLR (2023)
Oikarinen, T., Das, S., Nguyen, L.M., Weng, T.W.: Label-free Concept Bottleneck Models. In: ICLR (2023)
2023
-
[47]
In: BMVC (2018)
Petsiuk, V., Das, A., Saenko, K.: RISE: Randomized Input Sampling for Explana- tion of Black-box Models. In: BMVC (2018)
2018
-
[48]
In: ICML (2020)
Prillo, S., Eisenschlos, J.M.: SoftSort: A Continuous Relaxation for the argsort Operator. In: ICML (2020)
2020
-
[49]
In: ICML (2021)
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., Krueger, G., Sutskever, I.: Learning Transferable Visual Models From Natural Language Supervision. In: ICML (2021)
2021
-
[50]
In: ICCV (2021)
Ranftl, R., Bochkovskiy, A., Koltun, V.: Vision Transformers for Dense Prediction. In: ICCV (2021)
2021
-
[51]
Why Should I Trust You?
Ribeiro, M.T., Singh, S., Guestrin, C.: "Why Should I Trust You?": Explaining the Predictions of Any Classifier. In: KDD (2016)
2016
-
[52]
IEEE Transactions on Neural Networks and Learning Systems28(11), 2660–2673 (2016)
Samek, W., Binder, A., Montavon, G., Lapuschkin, S., Müller, K.R.: Evaluating the visualization of what a Deep Neural Network has learned. IEEE Transactions on Neural Networks and Learning Systems28(11), 2660–2673 (2016)
2016
-
[53]
In: ICCV (2017)
Selvaraju, R.R., Cogswell, M., Das, A., Vedantam, R., Parikh, D., Batra, D.: Grad- CAM: Visual Explanations from Deep Networks via Gradient-based Localization. In: ICCV (2017)
2017
-
[54]
In: ICML (2017) 18 D
Shrikumar, A., Greenside, P., Kundaje, A.: Learning Important Features Through Propagating Activation Differences. In: ICML (2017) 18 D. Schinagl et al
2017
-
[55]
Siméoni, O., Vo, H.V., Seitzer, M., Baldassarre, F., Oquab, M., Jose, C., Khalidov, V., Szafraniec, M., Yi, S., Ramamonjisoa, M., Massa, F., Haziza, D., Wehrstedt, L., Wang, J., Darcet, T., Moutakanni, T., Sentana, L., Roberts, C., Vedaldi, A., Tolan, J., Brandt, J., Couprie, C., Mairal, J., Jégou, H., Labatut, P., Bojanowski, P.: DINOv3. arXiv:2508.10104 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[56]
Simonyan, K., Vedaldi, A., Zisserman, A.: Deep inside Convolutional Networks: VisualisingImageClassificationModelsandSaliencyMaps.arXiv:1312.6034(2013)
work page Pith review arXiv 2013
-
[57]
Pacific Journal of Mathematics21(2), 343–348 (1967)
Sinkhorn, R., Knopp, P.: Concerning nonnegative matrices and doubly stochastic matrices. Pacific Journal of Mathematics21(2), 343–348 (1967)
1967
-
[58]
In: ACL (2021)
Situ, X., Zukerman, I., Paris, C., Maruf, S., Haffari, G.: Learning to Explain: Generating Stable Explanations Fast". In: ACL (2021)
2021
-
[59]
In: ICML (2020)
Sixt, L., Granz, M., Landgraf, T.: When explanations lie: why many modified BP attributions fail. In: ICML (2020)
2020
-
[60]
In: ICLR (2015)
Springenberg, J.T., Dosovitskiy, A., Brox, T., Riedmiller, M.A.: Striving for Sim- plicity: The All Convolutional Net. In: ICLR (2015)
2015
-
[61]
In: NeurIPS (2019)
Srinivas, S., Fleuret, F.: Full-Gradient Representation for Neural Network Visual- ization. In: NeurIPS (2019)
2019
-
[62]
In: ICML (2017)
Sundararajan, M., Taly, A., Yan, Q.: Axiomatic Attribution for Deep Networks. In: ICML (2017)
2017
-
[63]
In: MICCAI (2023)
Tran, M., Lahiani, A., Dicente Cid, Y., Boxberg, M., Lienemann, P., Matek, C., Wagner, S.J., Theis, F.J., Klaiman, E., Peng, T.: B-Cos Aligned Transformers Learn Human-Interpretable Features. In: MICCAI (2023)
2023
-
[64]
In: ICLR (2025)
Walker, C., Jha, S.K., Ewetz, R.: Metric-Driven Attributions for Vision Transform- ers. In: ICLR (2025)
2025
-
[65]
In: CVPR Workshops (2020)
Wang, H., Wang, Z., Du, M., Yang, F., Zhang, Z., Ding, S., Mardziel, P., Hu, X.: Score-CAM: Score-weighted visual explanations for convolutional neural networks. In: CVPR Workshops (2020)
2020
-
[66]
In: IJCAI (2023)
Xie, W., Li, X.H., Cao, C.C., Zhang, N.L.: ViT-CX: Causal Explanation of Vision Transformers. In: IJCAI (2023)
2023
-
[67]
In: CVPR (2020)
Xu, S., Venugopalan, S., Sundararajan, M.: Attribution in Scale and Space. In: CVPR (2020)
2020
-
[68]
In: NeurIPS Workshop XAI4Debugging (2021)
Yuan, T., Li, X., Xiong, H., Cao, H., Dou, D.: Explaining Information Flow Inside Vision Transformers Using Markov Chain. In: NeurIPS Workshop XAI4Debugging (2021)
2021
-
[69]
In: ECCV (2014)
Zeiler, M.D., Fergus, R.: Visualizing and Understanding Convolutional Networks. In: ECCV (2014)
2014
-
[70]
IJCV126(10), 1084–1102 (2018)
Zhang, J., Bargal, S.A., Lin, Z., Brandt, J., Shen, X., Sclaroff, S.: Top-Down Neural Attention by Excitation Backprop. IJCV126(10), 1084–1102 (2018)
2018
-
[71]
In: CVPR (2016)
Zhou, B., Khosla, A., Lapedriza, A., Oliva, A., Torralba, A.: Learning Deep Fea- tures for Discriminative Localization. In: CVPR (2016)
2016
-
[72]
Zintgraf, L.M., Cohen, T.S., Adel, T., Welling, M.: Visualizing Deep Neural Net- work Decisions: Prediction Difference Analysis. In: ICLR (2017) Learn to Rank: Visual Attribution by Learning Importance Ranking 19 A Appendix We present the detailed architecture of the explainer model (Sec. A.1) and com- prehensive evaluations. In particular, we demonstrate...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.