Recognition: 1 theorem link
· Lean TheoremAgentGL: Towards Agentic Graph Learning with LLMs via Reinforcement Learning
Pith reviewed 2026-05-10 18:46 UTC · model grok-4.3
The pith
Reinforcement learning lets LLMs act as agents that explore text-attributed graphs with specialized tools, producing large gains on node classification and link prediction.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
AgentGL is the first RL-driven framework for agentic graph learning. It supplies an LLM agent with graph-native tools for multi-scale exploration, regulates those tools through search-constrained thinking, and trains the agent with a graph-conditioned curriculum RL strategy that stabilizes long-horizon policy learning without requiring step-wise supervision. On diverse text-attributed graph benchmarks the method outperforms strong GraphLLM and GraphRAG baselines by absolute margins of up to 17.5 percent in node classification and 28.4 percent in link prediction.
What carries the argument
AgentGL, the RL-trained LLM agent that interleaves topology-aware navigation with LLM inference through graph-native tools, search-constrained thinking, and graph-conditioned curriculum learning.
If this is right
- Graph learning can be treated as an interleaved sequence of tool calls and inferences rather than a single forward pass over the full graph.
- Long-horizon agent policies on graphs can be learned from sparse terminal rewards alone when a curriculum is provided.
- LLMs equipped with graph tools can exceed the performance of both static GraphLLM fine-tuning and retrieval-augmented baselines on node classification and link prediction.
- Agentic graph navigation offers a scalable path for LLMs to operate on relational data whose size or complexity exceeds direct context windows.
Where Pith is reading between the lines
- The same tool-plus-RL pattern could be tested on graphs without text attributes or on dynamic graphs that change over time.
- Integration with existing retrieval systems might let a single agent switch between unstructured text and structured graph navigation within one trajectory.
- Removing the curriculum and measuring degradation in policy stability would quantify how much the proposed RL design contributes versus the tools alone.
Load-bearing premise
A graph-conditioned curriculum RL strategy can stabilize long-horizon policy learning for graph navigation without step-wise supervision while also balancing accuracy and efficiency via search constraints.
What would settle it
Training an otherwise identical LLM agent on the same tasks and tools but without the curriculum RL component or the search constraints, then checking whether the absolute gains of 17.5 percent and 28.4 percent disappear on the reported benchmarks.
Figures










read the original abstract
Large Language Models (LLMs) increasingly rely on agentic capabilities-iterative retrieval, tool use, and decision-making-to overcome the limits of static, parametric knowledge. Yet existing agentic frameworks treat external information as unstructured text and fail to leverage the topological dependencies inherent in real-world data. To bridge this gap, we introduce Agentic Graph Learning (AGL), a paradigm that reframes graph learning as an interleaved process of topology-aware navigation and LLM-based inference. Specifically, we propose AgentGL, the first reinforcement learning (RL)-driven framework for AGL. AgentGL equips an LLM agent with graph-native tools for multi-scale exploration, regulates tool usage via search-constrained thinking to balance accuracy and efficiency, and employs a graph-conditioned curriculum RL strategy to stabilize long-horizon policy learning without step-wise supervision. Across diverse Text-Attributed Graph (TAG) benchmarks and multiple LLM backbones, AgentGL substantially outperforms strong GraphLLMs and GraphRAG baselines, achieving absolute improvements of up to 17.5% in node classification and 28.4% in link prediction. These results demonstrate that AGL is a promising frontier for enabling LLMs to autonomously navigate and reason over complex relational environments. The code is publicly available at https://github.com/sunyuanfu/AgentGL.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces AgentGL, the first RL-driven framework for Agentic Graph Learning (AGL). It equips an LLM agent with graph-native tools for multi-scale exploration on text-attributed graphs (TAGs), uses search-constrained thinking to regulate tool usage, and applies a graph-conditioned curriculum RL strategy to stabilize long-horizon policy learning without step-wise supervision. The central empirical claim is that AgentGL substantially outperforms strong GraphLLM and GraphRAG baselines across diverse TAG benchmarks and multiple LLM backbones, with absolute gains of up to 17.5% in node classification and 28.4% in link prediction.
Significance. If the results and underlying mechanisms hold after proper validation, the work could meaningfully advance the integration of LLMs with structured relational data by enabling autonomous, topology-aware reasoning. Public code release is a clear strength for reproducibility. However, the absence of detailed experimental controls, ablations, and policy analysis currently limits the ability to assess whether the claimed gains stem from the proposed AGL paradigm or from unaccounted factors.
major comments (3)
- [Abstract and experimental results section] Abstract and experimental results section: The reported absolute improvements (17.5% node classification, 28.4% link prediction) are presented without accompanying details on experimental setup, baseline re-implementations, controls for confounding variables such as prompt engineering or temperature settings, number of random seeds, or statistical significance testing. This directly affects the load-bearing claim of substantial outperformance.
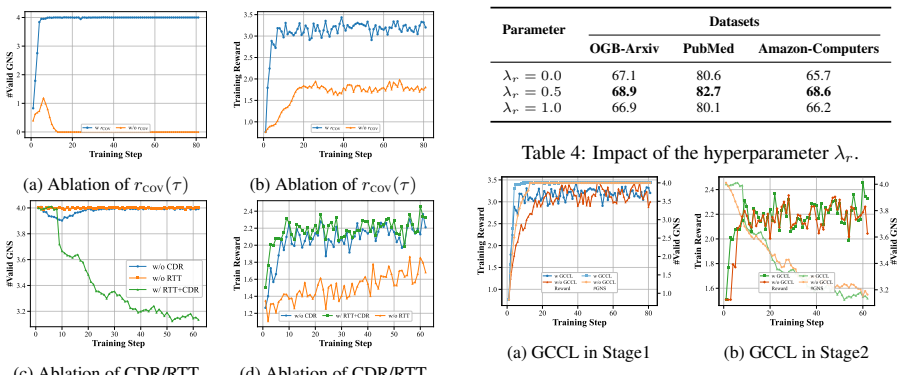
- [Method section describing the graph-conditioned curriculum RL] Method section describing the graph-conditioned curriculum RL: No ablation, policy rollout analysis, or reward-variance study is provided to demonstrate that the curriculum strategy successfully mitigates credit-assignment problems in long-horizon, sparse-reward graph navigation. Standard RL considerations indicate high risk of collapse to short trajectories; the manuscript contains no evidence that meaningful exploration occurs.
- [Method section on search-constrained thinking] Method section on search-constrained thinking: The interaction between the search constraint and the RL policy for balancing accuracy versus efficiency is described at a high level but lacks any formalization, equation, or empirical measurement showing how it prevents inefficiency or instability. This leaves the weakest assumption untested.
minor comments (2)
- [Abstract] The abstract states results across 'multiple LLM backbones' but does not list the specific models or sizes used; this information should appear in the experimental setup.
- [Method section] Notation for graph-native tools and curriculum stages could be introduced more explicitly with a table or diagram early in the method section to improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments correctly identify areas where greater experimental transparency, ablation studies, and formalization are needed to strengthen the validation of AgentGL. We will revise the manuscript to incorporate these elements, improving reproducibility and addressing the concerns about the source of the reported gains.
read point-by-point responses
-
Referee: [Abstract and experimental results section] Abstract and experimental results section: The reported absolute improvements (17.5% node classification, 28.4% link prediction) are presented without accompanying details on experimental setup, baseline re-implementations, controls for confounding variables such as prompt engineering or temperature settings, number of random seeds, or statistical significance testing. This directly affects the load-bearing claim of substantial outperformance.
Authors: We agree that the initial submission lacked sufficient detail on these controls, which is a valid concern for assessing the robustness of the results. In the revised manuscript, we will expand the experimental setup subsection to explicitly describe: baseline re-implementations (including exact prompt templates and any adaptations for GraphLLM and GraphRAG), hyperparameter controls (temperature fixed at 0.7 across all models, top-p=1.0), number of random seeds (5 seeds with mean and standard deviation reported), and statistical significance testing (paired t-tests yielding p<0.05 for the key gains). A dedicated table will summarize these settings to eliminate ambiguity around confounding factors. revision: yes
-
Referee: [Method section describing the graph-conditioned curriculum RL] Method section describing the graph-conditioned curriculum RL: No ablation, policy rollout analysis, or reward-variance study is provided to demonstrate that the curriculum strategy successfully mitigates credit-assignment problems in long-horizon, sparse-reward graph navigation. Standard RL considerations indicate high risk of collapse to short trajectories; the manuscript contains no evidence that meaningful exploration occurs.
Authors: We acknowledge the absence of these analyses, which leaves the curriculum's contribution under-validated. We will add a new ablation subsection in the revised manuscript that includes: (1) performance comparison with and without the graph-conditioned curriculum (demonstrating drops in both accuracy and trajectory length without it); (2) policy rollout statistics (average trajectory lengths, subgraph coverage, and exploration depth across episodes); and (3) reward-variance curves over training, showing reduced variance and avoidance of short-trajectory collapse. These will provide direct evidence that the curriculum enables stable long-horizon learning. revision: yes
-
Referee: [Method section on search-constrained thinking] Method section on search-constrained thinking: The interaction between the search constraint and the RL policy for balancing accuracy versus efficiency is described at a high level but lacks any formalization, equation, or empirical measurement showing how it prevents inefficiency or instability. This leaves the weakest assumption untested.
Authors: We agree that the description was high-level and requires formalization and empirical support. In the revision, we will add a formal definition in Section 3.2: the constrained policy is π_θ(a_t | s_t) = softmax(Q(s_t, a_t)) where a_t is restricted to the output of graph-native tools within the searched local subgraph (i.e., a_t ∈ A_search(s_t)). We will also include empirical measurements comparing constrained vs. unconstrained variants, reporting reductions in average tool calls (efficiency) and lower reward variance (stability), confirming the mechanism's role in balancing accuracy and efficiency. revision: yes
Circularity Check
No circularity: empirical framework with benchmark results
full rationale
The paper introduces AgentGL as an RL-based agentic framework for graph learning, describing components like graph-native tools, search-constrained thinking, and graph-conditioned curriculum RL. All load-bearing claims are empirical performance numbers on TAG benchmarks (node classification and link prediction improvements), not derivations, predictions, or first-principles results that reduce to inputs by construction. No equations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text to support a mathematical claim. The approach is self-contained as an engineering proposal validated externally via experiments.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
employs a graph-conditioned curriculum RL strategy to stabilize long-horizon policy learning without step-wise supervision
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Retrieval-Augmented Generation for Large Language Models: A Survey
Gaugllm: Improving graph contrastive learn- ing for text-attributed graphs with large language models. InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Min- ing, pages 747–758. Yunfan Gao, Yun Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Yuxi Bi, Yixin Dai, Jiawei Sun, Haofen Wang, and Haofen Wang. 2023. Retrieval-augmented ...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
REINFORCE++: Stabilizing Critic-Free Policy Optimization with Global Advantage Normalization
Reinforce++: Stabilizing critic-free policy optimization with global advantage normalization. Preprint, arXiv:2501.03262. Weihua Hu, Matthias Fey, Marinka Zitnik, Yuxiao Dong, Hongyu Ren, Bowen Liu, Michele Catasta, and Jure Leskovec. 2020. Open graph benchmark: Datasets for machine learning on graphs.Advances in neural information processing systems, 33:...
work page internal anchor Pith review arXiv 2020
-
[3]
arXiv preprint arXiv:2404.07103 , year=
Graph chain-of-thought: Augmenting large language models by reasoning on graphs.arXiv preprint arXiv:2404.07103. Bowen Jin, Hansi Zeng, Zhenrui Yue, Jinsung Yoon, Sercan Arik, Dong Wang, Hamed Zamani, and Jiawei Han. 2025. Search-r1: Training llms to reason and leverage search engines with reinforcement learning. arXiv preprint arXiv:2503.09516. Thomas N ...
-
[4]
Yuyan Liu, Sirui Ding, Sheng Zhou, Wenqi Fan, and Qiaoyu Tan
Graphsearch: Agentic search-augmented rea- soning for zero-shot graph learning.arXiv preprint arXiv:2601.08621. Yuyan Liu, Sirui Ding, Sheng Zhou, Wenqi Fan, and Qiaoyu Tan. 2024a. Moleculargpt: Open large lan- guage model (llm) for few-shot molecular property prediction.arXiv preprint arXiv:2406.12950. Zheyuan Liu, Xiaoxin He, Yijun Tian, and Nitesh V Ch...
-
[5]
Qwen3 technical report.arXiv preprint arXiv:2505.09388. An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayi- heng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Ji- axi Yang, Jingren Zhou, Junyang Lin, Kai Dang, and 22 others. 2024. Qwen2.5 technical report.CoRR, abs/2412.15...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
Graphtext: Graph rea- soning in text space.arXiv preprint arXiv:2310.01089,
Graphtext: Graph reasoning in text space. arXiv preprint arXiv:2310.01089. Jiong Zhu, Yujun Yan, Lingxiao Zhao, Mark Heimann, Leman Akoglu, and Danai Koutra. 2020. Beyond homophily in graph neural networks: Current lim- itations and effective designs.Advances in neural information processing systems, 33:7793–7804. Luyao Zhuang, Shengyuan Chen, Yilin Xiao,...
-
[7]
Heavy duty
have explored agentic GraphRAG, this is not equivalent to agentic graph learning, as the two lines of research focus on fundamentally differ- ent objectives. Nevertheless, given their high-level similarities, we select representative (canonical) GraphRAG baselines and adapt them to perform graph reasoning, and we provide a detailed empiri- cal comparison ...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.