Recognition: no theorem link
When Do We Need LLMs? A Diagnostic for Language-Driven Bandits
Pith reviewed 2026-05-10 18:25 UTC · model grok-4.3
The pith
Text embeddings let lightweight numerical bandits match or exceed LLM accuracy in contextual decisions at far lower cost.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
In non-episodic contextual bandits whose arms are described by mixed numerical and textual features, numerical algorithms that operate on dense or Matryoshka embeddings produce regret and reward outcomes comparable to or better than those obtained by an LLM that reasons over the text at each step; embedding dimensionality itself can be varied to tune the exploration-exploitation trade-off, and a simple geometric diagnostic computed from the embeddings predicts when the LLM route is necessary.
What carries the argument
Geometric diagnostic on the arms' embedding that compares their spread to decide between LLM reasoning and a lightweight numerical bandit.
If this is right
- Embedding dimensionality can be adjusted directly to control exploration without rewriting prompts or increasing model calls.
- Uncertainty estimates for the bandit can be obtained from an LLM by drawing multiple independent inferences rather than relying on internal token probabilities.
- The same embedding-based numerical approach extends to other sequential text tasks such as offer selection or dynamic pricing.
- Practitioners obtain a concrete, low-cost test that tells them when to invoke LLM reasoning instead of defaulting to it on every round.
Where Pith is reading between the lines
- The diagnostic could be recomputed periodically if the underlying text corpus or arm set drifts, allowing the system to switch modes automatically.
- Domains outside finance, such as news recommendation or medical triage, could adopt the same embedding check to limit LLM usage.
- If future embedding models capture finer pragmatic distinctions, the region where the diagnostic recommends LLMs would shrink further.
Load-bearing premise
The particular contexts, reward functions, and embedding models used in the experiments capture the decision-relevant structure that appears in real applications such as finance.
What would settle it
Run the same bandit instances with a new text corpus whose subtle distinctions are known to be lost under the chosen embeddings; if the numerical bandit then falls measurably behind the LLM baseline while the geometric diagnostic still recommends the numerical route, the central claim is falsified.
Figures













read the original abstract
We study Contextual Multi-Armed Bandits (CMABs) for non-episodic sequential decision making problems where the context includes both textual and numerical information (e.g., recommendation systems, dynamic portfolio adjustments, offer selection; all frequent problems in finance). While Large Language Models (LLMs) are increasingly applied to these settings, utilizing LLMs for reasoning at every decision step is computationally expensive and uncertainty estimates are difficult to obtain. To address this, we introduce LLMP-UCB, a bandit algorithm that derives uncertainty estimates from LLMs via repeated inference. However, our experiments demonstrate that lightweight numerical bandits operating on text embeddings (dense or Matryoshka) match or exceed the accuracy of LLM-based solutions at a fraction of their cost. We further show that embedding dimensionality is a practical lever on the exploration-exploitation balance, enabling cost--performance tradeoffs without prompt complexity. Finally, to guide practitioners, we propose a geometric diagnostic based on the arms' embedding to decide when to use LLM-driven reasoning versus a lightweight numerical bandit. Our results provide a principled deployment framework for cost-effective, uncertainty-aware decision systems with broad applicability across AI use cases in financial services.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
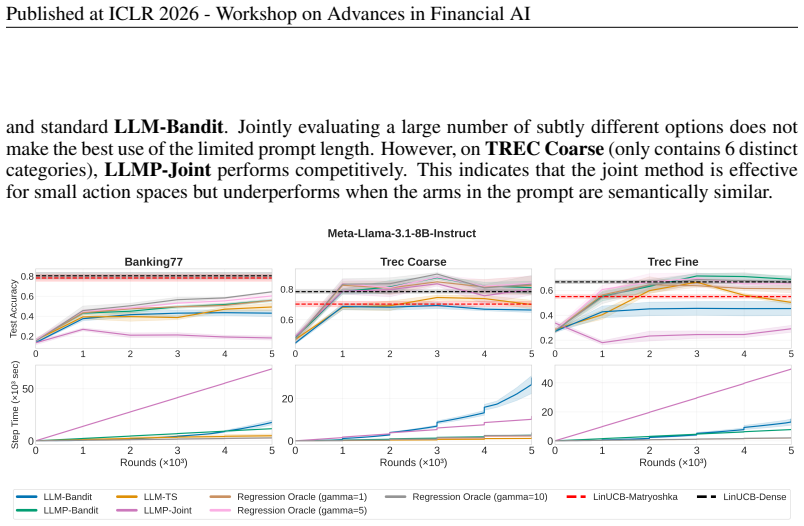
Summary. The paper studies contextual multi-armed bandits (CMABs) with mixed textual and numerical contexts, as in finance applications like offer selection. It introduces LLMP-UCB, which obtains uncertainty estimates from LLMs via repeated inference. Experiments are claimed to show that numerical bandits on dense or Matryoshka text embeddings match or exceed LLM performance at far lower cost; embedding dimensionality is presented as a lever for exploration-exploitation tradeoffs, and a geometric diagnostic on arm embeddings is proposed to decide when LLM reasoning is required versus lightweight numerical bandits.
Significance. If the empirical claims hold under scrutiny, the work supplies a practical, cost-aware deployment framework for language-driven bandits. The diagnostic and the demonstration that embedding-based methods can suffice would be useful for practitioners in AI-driven financial services and similar domains, reducing reliance on expensive LLMs while retaining uncertainty awareness. The introduction of LLMP-UCB and the explicit cost-performance analysis are constructive contributions.
major comments (2)
- [Experiments] Experiments section: The central empirical claim—that embedding-based numerical bandits match or exceed LLMP-UCB—requires verification of datasets, baselines, statistical tests, and error bars. The abstract asserts superiority without these details, leaving open the possibility of post-hoc context selection or unrepresentative reward structures; this directly undermines assessment of the performance parity result.
- [Geometric diagnostic] Geometric diagnostic (proposed in §5 or equivalent): The diagnostic assumes embeddings retain all decision-relevant textual features that determine arm rewards. If the tested reward functions depend on textual nuances (e.g., implicit risk factors) that current embeddings compress away, the diagnostic may misclassify when LLMs are needed. The manuscript should include an explicit test or ablation for information loss in embeddings under the chosen reward structures.
minor comments (3)
- [Abstract] Abstract: The claim of 'broad applicability across AI use cases in financial services' would be strengthened by a one-sentence indication of the number of contexts or trials supporting the embedding results.
- [Method] Notation: Define 'Matryoshka' embeddings on first use and clarify how dimensionality reduction interacts with the UCB-style uncertainty estimates.
- [Experiments] Figures: Ensure all performance plots include error bars or confidence intervals and label the axes with the exact metric (e.g., cumulative regret or accuracy).
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. The comments have prompted us to strengthen the experimental reporting and add targeted validation for the diagnostic. We address each major comment below and indicate the revisions made to the manuscript.
read point-by-point responses
-
Referee: [Experiments] Experiments section: The central empirical claim—that embedding-based numerical bandits match or exceed LLMP-UCB—requires verification of datasets, baselines, statistical tests, and error bars. The abstract asserts superiority without these details, leaving open the possibility of post-hoc context selection or unrepresentative reward structures; this directly undermines assessment of the performance parity result.
Authors: We agree that greater transparency is required to substantiate the central empirical claim. In the revised manuscript we have expanded Section 4 to provide: explicit descriptions of the datasets (synthetic environments plus real-world-inspired financial offer-selection tasks with fixed reward structures), a complete enumeration of baselines (standard contextual UCB variants together with dense and Matryoshka embedding-based bandits), paired t-tests with reported p-values for all key comparisons, and error bars (mean ± standard error) computed over ten independent runs in every performance figure. The contexts and reward functions were defined prior to any experimentation, as stated in the original Section 3; no post-hoc selection occurred. We have also revised the abstract to state that embedding-based methods “match or exceed” LLM performance rather than claiming unqualified superiority. These additions directly address the referee’s concerns and allow independent verification of the reported performance parity. revision: yes
-
Referee: [Geometric diagnostic] Geometric diagnostic (proposed in §5 or equivalent): The diagnostic assumes embeddings retain all decision-relevant textual features that determine arm rewards. If the tested reward functions depend on textual nuances (e.g., implicit risk factors) that current embeddings compress away, the diagnostic may misclassify when LLMs are needed. The manuscript should include an explicit test or ablation for information loss in embeddings under the chosen reward structures.
Authors: The referee correctly identifies a potential limitation of any embedding-based diagnostic. To address it we have added an explicit ablation study in the revised Section 5. The study introduces controlled textual nuances (implicit risk indicators and subtle semantic qualifiers in offer descriptions) that are known to be only partially preserved by the embeddings. We then compare the geometric diagnostic’s classification against LLMP-UCB decisions on the same instances. Results show that when embeddings lose decision-critical information the diagnostic reliably flags the need for LLM reasoning, and the observed performance gaps align with the diagnostic’s predictions. We discuss the scope of this validation in the updated text, noting that while the ablation is not exhaustive for every conceivable nuance, it supports the diagnostic’s utility under the reward structures examined in the paper. revision: yes
Circularity Check
No circularity; central claims rest on independent empirical comparisons
full rationale
The paper presents LLMP-UCB as an introduced algorithm and then reports experimental results showing that numerical bandits on dense or Matryoshka embeddings match or exceed its performance, together with a proposed geometric diagnostic on arm embeddings. No equations, fitted parameters, or self-citations are shown to reduce the performance claims or the diagnostic to quantities defined by the same data or prior author results. The evaluation is framed as data-driven rather than a closed derivation, leaving the findings self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Text embeddings preserve sufficient information for accurate bandit decisions in the target domains
invented entities (1)
-
LLMP-UCB algorithm
no independent evidence
Reference graph
Works this paper leans on
-
[1]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
-
[2]
Agrawal, P., Craig, N., Madden, A., and Lombera, I
Rishabh Agarwal, Avi Singh, Lei M. Zhang, Bernd Bohnet, Luis Rosias, Stephanie Chan, Biao Zhang, Ankesh Anand, Zaheer Abbas, Azade Nova, John D. Co-Reyes, Eric Chu, Feryal Behbahani, Aleksandra Faust, and Hugo Larochelle. Many-shot in-context learning, 2024. URL https://arxiv.org/abs/2404.11018
-
[3]
arXiv preprint arXiv:2506.09659 , year=
Eltayeb Ahmed, Uljad Berdica, Martha Elliott, Danijela Horak, and Jakob N Foerster. Intent factored generation: Unleashing the diversity in your language model. arXiv preprint arXiv:2506.09659, 2025
-
[4]
Alamdari, Yanshuai Cao, and Kevin H
Parand A. Alamdari, Yanshuai Cao, and Kevin H. Wilson. Jump starting bandits with llm-generated prior knowledge, 2024. URL https://arxiv.org/abs/2406.19317
- [5]
-
[6]
A review of llm agent applications in finance and banking
Devesh Batra, Conor Hamill, John Hartley, Ramin Okhrati, Dale Seddon, Harvey Miller, Raad Khraishi, and Greig Cowan. A review of llm agent applications in finance and banking. Available at SSRN 5381584, 2025
2025
-
[7]
Survey: Multi-armed bandits meet large language models, 2025
Djallel Bouneffouf and Raphael Feraud. Survey: Multi-armed bandits meet large language models, 2025. URL https://arxiv.org/abs/2505.13355
-
[8]
Openai gym, 2016
Greg Brockman, Vicki Cheung, Ludwig Pettersson, Jonas Schneider, John Schulman, Jie Tang, and Wojciech Zaremba. Openai gym, 2016
2016
-
[9]
Language models are few-shot learners
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. Advances in neural information processing systems, 33: 0 1877--1901, 2020 a
1901
-
[10]
Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwin...
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[11]
Efficient intent detection with dual sentence encoders
I \ n igo Casanueva, Tadas Tem c inas, Daniela Gerz, Matthew Henderson, and Ivan Vuli \'c . Efficient intent detection with dual sentence encoders. arXiv preprint arXiv:2003.04807, 2020
-
[12]
Efficient sequential decision making with large language models, 2025
Dingyang Chen, Qi Zhang, and Yinglun Zhu. Efficient sequential decision making with large language models, 2025. URL https://arxiv.org/abs/2406.12125
-
[13]
PonderNet: Learning to ponder.arXiv preprint arXiv:2106.01345,
Lili Chen, Kevin Lu, Aravind Rajeswaran, Kimin Lee, Aditya Grover, Michael Laskin, Pieter Abbeel, Aravind Srinivas, and Igor Mordatch. Decision transformer: Reinforcement learning via sequence modeling, 2021. URL https://arxiv.org/abs/2106.01345
-
[14]
Julian Coda-Forno, Marcel Binz, Zeynep Akata, Matthew Botvinick, Jane X. Wang, and Eric Schulz. Meta-in-context learning in large language models, 2023. URL https://arxiv.org/abs/2305.12907
-
[15]
arXiv preprint arXiv:2405.21015 , author =
Ben Cottier, Robi Rahman, Loredana Fattorini, Nestor Maslej, Tamay Besiroglu, and David Owen. The rising costs of training frontier ai models, 2025. URL https://arxiv.org/abs/2405.21015
-
[16]
Maxence Faldor, Jenny Zhang, Antoine Cully, and Jeff Clune. Omni-epic: Open-endedness via models of human notions of interestingness with environments programmed in code, 2025. URL https://arxiv.org/abs/2405.15568
-
[17]
Practical contextual bandits with regression oracles
Dylan Foster, Alekh Agarwal, Miroslav Dud \' k, Haipeng Luo, and Robert Schapire. Practical contextual bandits with regression oracles. In International Conference on Machine Learning, pp.\ 1539--1548. PMLR, 2018
2018
-
[18]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, Amy Yang, Angela Fan, Anirudh Goyal, Anthony Hartshorn, Aobo Yang, Archi Mitra, Archie Sravankumar, Artem Korenev, Arthur Hinsvark, Arun Rao, Aston Zhang, Aurelien Rodriguez, Austen Gregerson, Ava S...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
Large language models are zero-shot time series forecasters
Nate Gruver, Marc Finzi, Shikai Qiu, and Andrew G Wilson. Large language models are zero-shot time series forecasters. Advances in neural information processing systems, 36: 0 19622--19635, 2023
2023
-
[20]
DanHendrycks, CollinBurns, StevenBasart, AndyZou, MantasMazeika, DawnSong, andJacobSteinhardt
Sophia Hager, David Mueller, Kevin Duh, and Nicholas Andrews. Uncertainty distillation: Teaching language models to express semantic confidence. arXiv preprint arXiv:2503.14749, 2025
-
[21]
Systematic evaluation of uncertainty estimation methods in large language models
Christian Hobelsberger, Theresa Winner, Andreas Nawroth, Oliver Mitevski, and Anna-Carolina Haensch. Systematic evaluation of uncertainty estimation methods in large language models. arXiv preprint arXiv:2510.20460, 2025
-
[22]
Toward semantics-based answer pinpointing
Eduard Hovy, Laurie Gerber, Ulf Hermjakob, Chin-Yew Lin, and Deepak Ravichandran. Toward semantics-based answer pinpointing. In Proceedings of the first international conference on Human language technology research, 2001
2001
-
[23]
A clean slate for offline reinforcement learning
Matthew Thomas Jackson, Uljad Berdica, Jarek Liesen, Shimon Whiteson, and Jakob Nicolaus Foerster. A clean slate for offline reinforcement learning. arXiv preprint arXiv:2504.11453, 2025
-
[24]
Aditya Kusupati, Gantavya Bhatt, Aniket Rege, Matthew Wallingford, Aditya Sinha, Vivek Ramanujan, William Howard-Snyder, Kaifeng Chen, Sham Kakade, Prateek Jain, and Ali Farhadi. Matryoshka representation learning, 2024. URL https://arxiv.org/abs/2205.13147
-
[25]
Gonzalez, Hao Zhang, and Ion Stoica
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with pagedattention. In Proceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles, 2023
2023
-
[26]
arXiv preprint arXiv:2210.14215 , year=
Michael Laskin, Luyu Wang, Junhyuk Oh, Emilio Parisotto, Stephen Spencer, Richie Steigerwald, DJ Strouse, Steven Hansen, Angelos Filos, Ethan Brooks, Maxime Gazeau, Himanshu Sahni, Satinder Singh, and Volodymyr Mnih. In-context reinforcement learning with algorithm distillation, 2022. URL https://arxiv.org/abs/2210.14215
-
[27]
Bandit algorithms
Tor Lattimore and Csaba Szepesv \'a ri. Bandit algorithms. Cambridge University Press, 2020
2020
-
[28]
Contextual-bandit approach to personalized news article recommendation, January 19 2012
Lihong Li, Wei Chu, John Langford, and Robert Schapire. Contextual-bandit approach to personalized news article recommendation, January 19 2012. US Patent App. 12/836,188
2012
-
[29]
Hyperband: A novel bandit-based approach to hyperparameter optimization
Lisha Li, Kevin Jamieson, Giulia DeSalvo, Afshin Rostamizadeh, and Ameet Talwalkar. Hyperband: A novel bandit-based approach to hyperparameter optimization. Journal of Machine Learning Research, 18 0 (185): 0 1--52, 2018
2018
-
[30]
Learning question classifiers
Xin Li and Dan Roth. Learning question classifiers. In COLING 2002: The 19th International Conference on Computational Linguistics, 2002
2002
-
[31]
Large language models in finance: A survey
Yinheng Li, Shaofei Wang, Han Ding, and Hang Chen. Large language models in finance: A survey. In Proceedings of the fourth ACM international conference on AI in finance, pp.\ 374--382, 2023
2023
-
[32]
Contextual multi-armed bandits
Tyler Lu, D \'a vid P \'a l, and Martin P \'a l. Contextual multi-armed bandits. In Proceedings of the Thirteenth international conference on Artificial Intelligence and Statistics, pp.\ 485--492. JMLR Workshop and Conference Proceedings, 2010
2010
-
[33]
Fantastically ordered prompts and where to find them: Overcoming few-shot prompt order sensitivity
Yao Lu, Max Bartolo, Alastair Moore, Sebastian Riedel, and Pontus Stenetorp. Fantastically ordered prompts and where to find them: Overcoming few-shot prompt order sensitivity, 2022. URL https://arxiv.org/abs/2104.08786
-
[34]
Review of social media sentiment and contextual bandit models in stock market investment
Ruicheng Miao. Review of social media sentiment and contextual bandit models in stock market investment. In ITM Web of Conferences, volume 73, pp.\ 01022. EDP Sciences, 2025
2025
-
[35]
arXiv preprint arXiv:2502.07978 , year=
Amir Moeini, Jiuqi Wang, Jacob Beck, Ethan Blaser, Shimon Whiteson, Rohan Chandra, and Shangtong Zhang. A survey of in-context reinforcement learning, 2025. URL https://arxiv.org/abs/2502.07978
-
[36]
Llms are in-context bandit reinforcement learners, 2025
Giovanni Monea, Antoine Bosselut, Kianté Brantley, and Yoav Artzi. Llms are in-context bandit reinforcement learners, 2025. URL https://arxiv.org/abs/2410.05362
-
[37]
Contextual combinatorial bandit on portfolio management
He Ni, Hao Xu, Dan Ma, and Jun Fan. Contextual combinatorial bandit on portfolio management. Expert Systems with Applications, 221: 0 119677, 2023
2023
-
[38]
OpenAI, Aaron Hurst, Adam Lerer, Adam P. Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, Aleksander Mądry, Alex Baker-Whitcomb, Alex Beutel, Alex Borzunov, Alex Carney, Alex Chow, Alex Kirillov, Alex Nichol, Alex Paino, Alex Renzin, Alex Tachard Passos, Alexander Kirillov, Alexi Christakis, Alexis ...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[39]
Qwen, :, An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, Junyang Lin, Kai Dang, Keming Lu, Keqin Bao, Kexin Yang, Le Yu, Mei Li, Mingfeng Xue, Pei Zhang, Qin Zhu, Rui Men, Runji Lin, Tianhao Li,...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[40]
James Requeima, John Bronskill, Dami Choi, Richard E. Turner, and David Duvenaud. Llm processes: Numerical predictive distributions conditioned on natural language, 2024. URL https://arxiv.org/abs/2405.12856
-
[41]
Llms are greedy agents: Effects of rl fine-tuning on decision-making abilities
Thomas Schmied, J \"o rg Bornschein, Jordi Grau-Moya, Markus Wulfmeier, and Razvan Pascanu. Llms are greedy agents: Effects of rl fine-tuning on decision-making abilities. arXiv preprint arXiv:2504.16078, 2025
-
[42]
Prompting strategies for enabling large language models to infer causation from correlation, 2024
Eleni Sgouritsa, Virginia Aglietti, Yee Whye Teh, Arnaud Doucet, Arthur Gretton, and Silvia Chiappa. Prompting strategies for enabling large language models to infer causation from correlation, 2024. URL https://arxiv.org/abs/2412.13952
-
[43]
Haochen Song, Dominik Hofer, Rania Islambouli, Laura Hawkins, Ananya Bhattacharjee, Meredith Franklin, and Joseph Jay Williams. Investigating the relationship between physical activity and tailored behavior change messaging: Connecting contextual bandit with large language models, 2025 a . URL https://arxiv.org/abs/2506.07275
-
[44]
Reward Is Enough: LLMs Are In-Context Reinforcement Learners
Kefan Song, Amir Moeini, Peng Wang, Lei Gong, Rohan Chandra, Yanjun Qi, and Shangtong Zhang. Reward is enough: Llms are in-context reinforcement learners, 2025 b . URL https://arxiv.org/abs/2506.06303
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[45]
Gaussian process optimization in the bandit setting: No regret and experimental design,
Niranjan Srinivas, Andreas Krause, Sham M Kakade, and Matthias Seeger. Gaussian process optimization in the bandit setting: No regret and experimental design. arXiv preprint arXiv:0912.3995, 2009
- [46]
-
[47]
Sutton and Andrew G
Richard S. Sutton and Andrew G. Barto. Reinforcement Learning: An Introduction. The MIT Press, second edition, 2018. URL http://incompleteideas.net/book/the-book-2nd.html
2018
-
[48]
Tim Tomov, Dominik Fuchsgruber, Tom Wollschl \"a ger, and Stephan G \"u nnemann. The illusion of certainty: Uncertainty quantification for llms fails under ambiguity. arXiv preprint arXiv:2511.04418, 2025
-
[49]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[50]
Anthropomimetic uncertainty: What verbalized uncertainty in language models is missing
Dennis Ulmer, Alexandra Lorson, Ivan Titov, and Christian Hardmeier. Anthropomimetic uncertainty: What verbalized uncertainty in language models is missing. arXiv preprint arXiv:2507.10587, 2025
-
[51]
Overview of the trec-9 question answering track report
Ellen Voorhees. Overview of the trec-9 question answering track report. In Proceedings of the 9th Text Retrieval Conference (TREC9), 2000, pp.\ 71--80, 2000
2000
-
[52]
Context is key: A benchmark for forecasting with essential textual information
Andrew Robert Williams, Arjun Ashok, Étienne Marcotte, Valentina Zantedeschi, Jithendaraa Subramanian, Roland Riachi, James Requeima, Alexandre Lacoste, Irina Rish, Nicolas Chapados, and Alexandre Drouin. Context is key: A benchmark for forecasting with essential textual information, 2025. URL https://arxiv.org/abs/2410.18959
-
[53]
Omni: Open-endedness via models of human notions of interestingness, 2024
Jenny Zhang, Joel Lehman, Kenneth Stanley, and Jeff Clune. Omni: Open-endedness via models of human notions of interestingness, 2024. URL https://arxiv.org/abs/2306.01711
-
[54]
Exposing product bias in llm investment recommendation
Yuhan Zhi, Xiaoyu Zhang, Longtian Wang, Shumin Jiang, Shiqing Ma, Xiaohong Guan, and Chao Shen. Exposing product bias in llm investment recommendation. arXiv preprint arXiv:2503.08750, 2025
-
[55]
@esa (Ref
\@ifxundefined[1] #1\@undefined \@firstoftwo \@secondoftwo \@ifnum[1] #1 \@firstoftwo \@secondoftwo \@ifx[1] #1 \@firstoftwo \@secondoftwo [2] @ #1 \@temptokena #2 #1 @ \@temptokena \@ifclassloaded agu2001 natbib The agu2001 class already includes natbib coding, so you should not add it explicitly Type <Return> for now, but then later remove the command n...
-
[56]
\@lbibitem[] @bibitem@first@sw\@secondoftwo \@lbibitem[#1]#2 \@extra@b@citeb \@ifundefined br@#2\@extra@b@citeb \@namedef br@#2 \@nameuse br@#2\@extra@b@citeb \@ifundefined b@#2\@extra@b@citeb @num @parse #2 @tmp #1 NAT@b@open@#2 NAT@b@shut@#2 \@ifnum @merge>\@ne @bibitem@first@sw \@firstoftwo \@ifundefined NAT@b*@#2 \@firstoftwo @num @NAT@ctr \@secondoft...
-
[57]
a ger, and G \
@open @close @open @close and [1] URL: #1 \@ifundefined chapter * \@mkboth \@ifxundefined @sectionbib * \@mkboth * \@mkboth\@gobbletwo \@ifclassloaded amsart * \@ifclassloaded amsbook * \@ifxundefined @heading @heading NAT@ctr thebibliography [1] @ \@biblabel @NAT@ctr \@bibsetup #1 @NAT@ctr @ @openbib .11em \@plus.33em \@minus.07em 4000 4000 `\.\@m @bibit...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.