Recognition: 2 theorem links
· Lean TheoremLearning Shared Sentiment Prototypes for Adaptive Multimodal Sentiment Analysis
Pith reviewed 2026-05-10 19:03 UTC · model grok-4.3
The pith
Multimodal sentiment models preserve the structure of conflicting or complementary cues by keeping evidence in a shared prototype space and refining modality weights as reasoning deepens.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
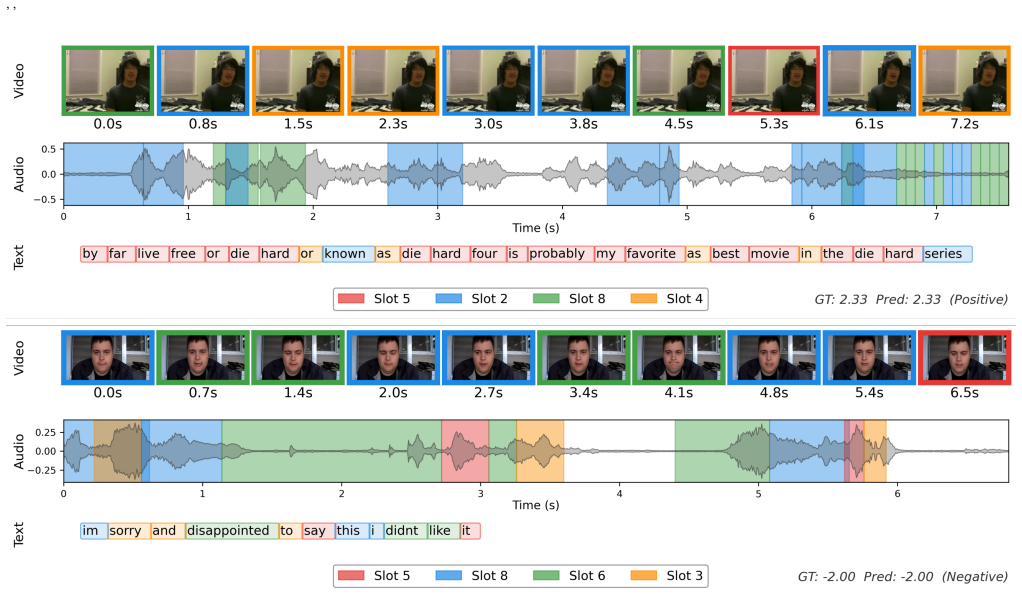
PRISM unifies structured affective extraction and adaptive modality evaluation by placing multimodal evidence in a shared prototype space. This organization enables structured cross-modal comparison and adaptive fusion while dynamic modality reweighting during reasoning continuously refines each modality's contribution as semantic interactions deepen. On three benchmark datasets the method outperforms representative baselines.
What carries the argument
The shared prototype space that maintains separate sentiment cues for structured cross-modal comparison, adaptive fusion, and ongoing dynamic modality reweighting throughout reasoning.
If this is right
- Sentiment cues from text, audio, and video can be compared directly without losing their distinct structures of support or conflict.
- Modality importance is no longer fixed after initial fusion but can be revised as semantic interactions become deeper.
- The final sentiment prediction can draw on a richer accounting of cue reliability and complementarity.
- Performance on standard multimodal sentiment benchmarks exceeds that of early-aggregation baselines.
Where Pith is reading between the lines
- The same prototype-space approach could be tested on other multimodal tasks where cues conflict, such as emotion recognition from conversation video.
- It suggests that explicit prototype maintenance might reduce the need for ever-larger fusion networks by enabling direct structured comparisons.
- Real-world deployment might gain robustness when one modality drops out or becomes noisy, since reweighting can continue after initial fusion.
Load-bearing premise
That keeping sentiment cues separate in a shared prototype space until later reasoning better preserves their internal relationships than early compression into a single representation.
What would settle it
An ablation on the three benchmark datasets in which removing the shared prototype space and dynamic reweighting produces accuracy equal to or higher than the full model would falsify the claimed benefit.
Figures



read the original abstract
Multimodal sentiment analysis (MSA) aims to predict human sentiment from textual, acoustic, and visual information in videos. Recent studies improve multimodal fusion by modeling modality interaction and assigning different modality weights. However, they usually compress diverse sentiment cues into a single compact representation before sentiment reasoning. This early aggregation makes it difficult to preserve the internal structure of sentiment evidence, where different cues may complement, conflict with, or differ in reliability from each other. In addition, modality importance is often determined only once during fusion, so later reasoning cannot further adjust modality contributions. To address these issues, we propose PRISM, a framework that unifies structured affective extraction and adaptive modality evaluation. PRISM organizes multimodal evidence in a shared prototype space, which supports structured cross-modal comparison and adaptive fusion. It further applies dynamic modality reweighting during reasoning, allowing modality contributions to be continuously refined as semantic interactions become deeper. Experiments on three benchmark datasets show that PRISM outperforms representative baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes PRISM, a framework for multimodal sentiment analysis that organizes textual, acoustic, and visual evidence into a shared sentiment prototype space. This design is intended to enable structured cross-modal comparisons and adaptive fusion while avoiding the loss of internal cue structure that occurs with early aggregation. The framework additionally incorporates dynamic modality reweighting that is applied iteratively during the reasoning stage, allowing modality contributions to be refined as semantic interactions deepen. Experiments on three benchmark datasets are reported to show that PRISM outperforms representative baselines.
Significance. If the empirical results and architectural claims hold, the work addresses two recurring limitations in multimodal sentiment analysis: premature compression of heterogeneous cues and one-shot modality weighting. The shared-prototype mechanism offers a concrete way to maintain cue-level structure for later comparison, while the dynamic reweighting provides a pathway for refinement after initial fusion. These elements are internally consistent with the stated goals and could support more robust handling of complementary or conflicting modality signals in video data.
minor comments (3)
- The abstract would be strengthened by naming the three benchmark datasets and reporting the primary quantitative gains (e.g., accuracy or F1 deltas) so readers can immediately gauge the scale of improvement.
- In the method description, the precise formulation of how prototypes are learned and how the dynamic reweighting is computed (including any temperature or gating parameters) should be presented with explicit equations to facilitate reproduction and theoretical analysis.
- The experimental section should include standard deviations across multiple random seeds and, where possible, statistical significance tests against the strongest baselines to substantiate the outperformance claims.
Simulated Author's Rebuttal
We thank the referee for the positive summary and significance assessment of our work on PRISM. The recommendation for minor revision is noted, and we will use the revision to improve clarity, presentation, and any minor details as appropriate. No specific major comments were raised in the report.
Circularity Check
No significant circularity in derivation chain
full rationale
The paper introduces PRISM as a new framework with shared prototype space for structured cross-modal comparison and dynamic modality reweighting during reasoning. These are presented as direct architectural responses to the stated problems of early aggregation losing cue structure and static weights preventing later refinement. No equations, fitted parameters, or self-citations are shown reducing any prediction or claim back to its own inputs by construction. The abstract and description remain self-contained, with independent mechanisms that do not rely on redefining terms or smuggling ansatzes via prior self-work.
Axiom & Free-Parameter Ledger
invented entities (1)
-
shared sentiment prototypes
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation (headline theorem, 8-tick period)reality_from_one_distinction (8-tick periodicity) echoeswe set the number of sentiment prototypes to K=8... all three datasets perform best at K=8. A small K makes the prototype space too coarse... The consistent optimum across datasets suggests that a moderate prototype granularity is sufficient.
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure, Cost (J-cost uniqueness)absolute_floor_iff_bare_distinguishability; washburn_uniqueness_aczel echoesRather than directly collapsing each modality into a single summary vector, PRISM first decomposes multimodal evidence into a small set of shared sentiment prototypes... This early aggregation makes it difficult to preserve the internal structure of sentiment evidence
Reference graph
Works this paper leans on
-
[1]
Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katherine Millican, Malcolm Reynolds, et al
-
[2]
Flamingo: a visual language model for few-shot learning.Advances in neural information processing systems35 (2022), 23716–23736
2022
-
[3]
Relja Arandjelovic, Petr Gronat, Akihiko Torii, Tomas Pajdla, and Josef Sivic
-
[4]
In Proceedings of the IEEE conference on computer vision and pattern recognition
NetVLAD: CNN architecture for weakly supervised place recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition. 5297–5307
-
[5]
Tadas Baltrušaitis, Chaitanya Ahuja, and Louis-Philippe Morency. 2018. Multi- modal machine learning: A survey and taxonomy.IEEE transactions on pattern analysis and machine intelligence41, 2 (2018), 423–443
2018
-
[6]
Tadas Baltrusaitis, Amir Zadeh, Yao Chong Lim, and Louis-Philippe Morency
-
[7]
InIEEE International Conference on Automatic Face and Gesture Recognition
OpenFace 2.0: Facial Behavior Analysis Toolkit. InIEEE International Conference on Automatic Face and Gesture Recognition
-
[8]
Erik Cambria. 2016. Affective Computing and Sentiment Analysis.IEEE Intelligent Systems31, 2 (2016), 102–107
2016
-
[9]
Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexan- der Kirillov, and Sergey Zagoruyko. 2020. End-to-end object detection with transformers. InEuropean conference on computer vision. Springer, 213–229
2020
-
[10]
Wenliang Dai, Junnan Li, Dongxu Li, Anthony Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale N Fung, and Steven Hoi. 2023. Instructblip: Towards general-purpose vision-language models with instruction tuning.Advances in neural information processing systems36 (2023), 49250–49267
2023
-
[11]
Laurence Devillers. 2021. Human–robot interactions and affective computing: The ethical implications. InRobotics, AI, and humanity: Science, ethics, and policy. Springer, 205–211
2021
-
[12]
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers). 4171–4186
2019
-
[13]
Sidney K D’mello and Jacqueline Kory. 2015. A review and meta-analysis of multimodal affect detection systems.ACM computing surveys (CSUR)47, 3 (2015), 1–36
2015
-
[14]
Faiyaz Doctor, Charalampos Karyotis, Rahat Iqbal, and Anne James. 2016. An intelligent framework for emotion aware e-healthcare support systems. In2016 IEEE Symposium Series on Computational Intelligence (SSCI). IEEE, 1–8
2016
-
[15]
Kaouther Ezzameli and Hela Mahersia. 2023. Emotion recognition from unimodal to multimodal analysis: A review.Information Fusion99 (2023), 101847
2023
-
[16]
Xinyu Feng, Yuming Lin, Lihua He, You Li, Liang Chang, and Ya Zhou. 2024. Knowledge-guided dynamic modality attention fusion framework for multimodal sentiment analysis. InFindings of the Association for Computational Linguistics: EMNLP 2024. 14755–14766
2024
-
[17]
AV Geetha, T Mala, D Priyanka, and EJIF Uma. 2024. Multimodal emotion recognition with deep learning: advancements, challenges, and future directions. Information Fusion105 (2024), 102218
2024
-
[18]
Tianrui Guan, Fuxiao Liu, Xiyang Wu, Ruiqi Xian, Zongxia Li, Xiaoyu Liu, Xijun Wang, Lichang Chen, Furong Huang, Yaser Yacoob, et al. 2024. Hallusionbench: an advanced diagnostic suite for entangled language hallucination and visual illusion in large vision-language models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognitio...
2024
-
[19]
Jiwei Guo, Jiajia Tang, Weichen Dai, Yu Ding, and Wanzeng Kong. 2022. Dynam- ically adjust word representations using unaligned multimodal information. In Proceedings of the 30th ACM international conference on multimedia. 3394–3402
2022
-
[20]
Wei Han, Hui Chen, and Soujanya Poria. 2021. Improving multimodal fusion with hierarchical mutual information maximization for multimodal sentiment analysis. InProceedings of the 2021 conference on empirical methods in natural language processing. 9180–9192
2021
-
[21]
Devamanyu Hazarika, Roger Zimmermann, and Soujanya Poria. 2020. Misa: Modality-invariant and-specific representations for multimodal sentiment analy- sis. InProceedings of the 28th ACM international conference on multimedia. 1122– 1131
2020
-
[22]
Jian Huang, Yanli Ji, Zhen Qin, Yang Yang, and Heng Tao Shen. 2023. Dominant single-modal supplementary fusion (SIMSUF) for multimodal sentiment analysis. IEEE Transactions on Multimedia26 (2023), 8383–8394
2023
-
[23]
Andrew Jaegle, Sebastian Borgeaud, Jean-Baptiste Alayrac, Carl Doersch, Catalin Ionescu, David Ding, Skanda Koppula, Daniel Zoran, Andrew Brock, Evan Shel- hamer, et al. 2021. Perceiver io: A general architecture for structured inputs & outputs.arXiv preprint arXiv:2107.14795(2021)
-
[24]
Andrew Jaegle, Felix Gimeno, Andy Brock, Oriol Vinyals, Andrew Zisserman, and Joao Carreira. 2021. Perceiver: General perception with iterative attention. InInternational conference on machine learning. PMLR, 4651–4664
2021
-
[25]
Shenjie Jiang, Zhuoyu Wang, Xuecheng Wu, Hongru Ji, Mingxin Li, Xianghua Li, and Chao Gao. 2025. DDSE: A Decoupled Dual-Stream Enhanced Framework for Multimodal Sentiment Analysis with Text-Centric SSM. InProceedings of the 33rd ACM International Conference on Multimedia. 5893–5902
2025
-
[26]
Yingying Jiang, Wei Li, M Shamim Hossain, Min Chen, Abdulhameed Alelaiwi, and Muneer Al-Hammadi. 2020. A snapshot research and implementation of multimodal information fusion for data-driven emotion recognition.Information Fusion53 (2020), 209–221
2020
-
[27]
Juho Lee, Yoonho Lee, Jungtaek Kim, Adam Kosiorek, Seungjin Choi, and Yee Whye Teh. 2019. Set transformer: A framework for attention-based permutation-invariant neural networks. InInternational conference on machine learning. PMLR, 3744–3753
2019
-
[28]
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. 2023. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. InInternational conference on machine learning. PMLR, 19730–19742
2023
-
[29]
Tao Liang, Guosheng Lin, Lei Feng, Yan Zhang, and Fengmao Lv. 2021. Attention is not enough: Mitigating the distribution discrepancy in asynchronous multi- modal sequence fusion. InProceedings of the IEEE/CVF International Conference on Computer Vision. 8148–8156
2021
- [30]
-
[31]
Yihe Liu, Ziqi Yuan, Huisheng Mao, Zhiyun Liang, Wanqiuyue Yang, Yuanzhe Qiu, Tie Cheng, Xiaoteng Li, Hua Xu, and Kai Gao. 2022. Make acoustic and visual cues matter: Ch-sims v2. 0 dataset and av-mixup consistent module. InProceedings of the 2022 international conference on multimodal interaction. 247–258
2022
-
[32]
Zhun Liu, Ying Shen, Varun Bharadhwaj Lakshminarasimhan, Paul Pu Liang, AmirAli Bagher Zadeh, and Louis-Philippe Morency. 2018. Efficient low-rank multimodal fusion with modality-specific factors. InProceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2247–2256
2018
-
[33]
Francesco Locatello, Dirk Weissenborn, Thomas Unterthiner, Aravindh Mahen- dran, Georg Heigold, Jakob Uszkoreit, Alexey Dosovitskiy, and Thomas Kipf
-
[34]
Object-centric learning with slot attention.Advances in neural information processing systems33 (2020), 11525–11538
2020
-
[35]
Ilya Loshchilov and Frank Hutter. 2016. Sgdr: Stochastic gradient descent with warm restarts.arXiv preprint arXiv:1608.03983(2016)
work page internal anchor Pith review arXiv 2016
-
[36]
Ilya Loshchilov and Frank Hutter. 2017. Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101(2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[37]
Fengmao Lv, Xiang Chen, Yanyong Huang, Lixin Duan, and Guosheng Lin. 2021. Progressive modality reinforcement for human multimodal emotion recognition from unaligned multimodal sequences. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2554–2562
2021
-
[38]
Huisheng Mao, Ziqi Yuan, Hua Xu, Wenmeng Yu, Yihe Liu, and Kai Gao. 2022. M- SENA: An integrated platform for multimodal sentiment analysis. InProceedings of the 60th Annual Meeting of the Association for Computational Linguistics: System Demonstrations. 204–213
2022
-
[39]
Brian McFee, Colin Raffel, Dawen Liang, Daniel PW Ellis, Matt McVicar, Eric Battenberg, Oriol Nieto, et al. 2015. librosa: Audio and music signal analysis in python.SciPy2015, 18-24 (2015), 7
2015
-
[40]
Prem Melville, Wojciech Gryc, and Richard D Lawrence. 2009. Sentiment analysis of blogs by combining lexical knowledge with text classification. InProceedings of the 15th ACM SIGKDD international conference on Knowledge discovery and data mining. 1275–1284
2009
-
[41]
Maja Pantic, Roderick Cowie, Francesca D’Errico, Dirk Heylen, Marc Mehu, Catherine Pelachaud, Isabella Poggi, Marc Schroeder, and Alessandro Vinciarelli
-
[42]
InVisual analysis of humans: Looking at people
Social signal processing: the research agenda. InVisual analysis of humans: Looking at people. Springer, 511–538
-
[43]
2000.Affective computing
Rosalind W Picard. 2000.Affective computing. MIT press
2000
-
[44]
Soujanya Poria, Erik Cambria, Rajiv Bajpai, and Amir Hussain. 2017. A Review of Affective Computing: From Unimodal Analysis to Multimodal Fusion.Information Fusion37 (2017), 98–125
2017
-
[45]
Wasifur Rahman, Md Kamrul Hasan, Sangwu Lee, AmirAli Bagher Zadeh, Chengfeng Mao, Louis-Philippe Morency, and Ehsan Hoque. 2020. Integrat- ing multimodal information in large pretrained transformers. InProceedings of the 58th annual meeting of the association for computational linguistics. 2359–2369
2020
-
[46]
Björn Schuller, Stefan Steidl, Anton Batliner, Felix Burkhardt, Laurence Devillers, Christian MüLler, and Shrikanth Narayanan. 2013. Paralinguistics in speech and language—state-of-the-art and the challenge.Computer Speech & Language27, 1 (2013), 4–39
2013
-
[47]
Jake Snell, Kevin Swersky, and Richard Zemel. 2017. Prototypical networks for few-shot learning.Advances in neural information processing systems30 (2017)
2017
-
[48]
Yao-Hung Hubert Tsai, Shaojie Bai, Paul Pu Liang, J Zico Kolter, Louis-Philippe Morency, and Ruslan Salakhutdinov. 2019. Multimodal transformer for unaligned multimodal language sequences. InProceedings of the 57th annual meeting of the association for computational linguistics. 6558–6569
2019
-
[49]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need.Advances in neural information processing systems30 (2017)
2017
-
[50]
Oriol Vinyals, Charles Blundell, Timothy Lillicrap, Daan Wierstra, et al . 2016. Matching networks for one shot learning.Advances in neural information pro- cessing systems29 (2016). , ,
2016
-
[51]
Di Wang, Shuai Liu, Quan Wang, Yumin Tian, Lihuo He, and Xinbo Gao. 2022. Cross-modal enhancement network for multimodal sentiment analysis.IEEE Transactions on Multimedia25 (2022), 4909–4921
2022
-
[52]
Haoyu Wang, Bengong Yu, Zhonghao Xi, Shuping Zhao, and Ying Yang. 2026. Multimodal Emotion Recognition with Temporal Slicing Encoder and Attention- Enhanced Synergy Integration.IEEE Transactions on Multimedia(2026)
2026
-
[53]
Zilong Wang, Zhaohong Wan, and Xiaojun Wan. 2020. Transmodality: An end2end fusion method with transformer for multimodal sentiment analysis. In Proceedings of the web conference 2020. 2514–2520
2020
-
[54]
Yuhua Wen, Qifei Li, Yingying Zhou, Yingming Gao, Zhengqi Wen, Jianhua Tao, and Ya Li. 2025. DashFusion: Dual-Stream Alignment With Hierarchical Bottleneck Fusion for Multimodal Sentiment Analysis.IEEE Transactions on Neural Networks and Learning Systems(2025)
2025
-
[55]
Shaoxiang Wu, Damai Dai, Ziwei Qin, Tianyu Liu, Binghuai Lin, Yunbo Cao, and Zhifang Sui. 2023. Denoising bottleneck with mutual information maximization for video multimodal fusion. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2231–2243
2023
-
[56]
Yang Wu, Zijie Lin, Yanyan Zhao, Bing Qin, and Li-Nan Zhu. 2021. A text- centered shared-private framework via cross-modal prediction for multimodal sentiment analysis. InFindings of the association for computational linguistics: ACL-IJCNLP 2021. 4730–4738
2021
-
[57]
Dingkang Yang, Zhaoyu Chen, Yuzheng Wang, Shunli Wang, Mingcheng Li, Siao Liu, Xiao Zhao, Shuai Huang, Zhiyan Dong, Peng Zhai, et al . 2023. Context de-confounded emotion recognition. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 19005–19015
2023
-
[58]
Jiuding Yang, Yakun Yu, Di Niu, Weidong Guo, and Yu Xu. 2023. Confede: Con- trastive feature decomposition for multimodal sentiment analysis. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 7617–7630
2023
-
[59]
Kaicheng Yang, Hua Xu, and Kai Gao. 2020. Cm-bert: Cross-modal bert for text- audio sentiment analysis. InProceedings of the 28th ACM international conference on multimedia. 521–528
2020
-
[60]
Wenmeng Yu, Hua Xu, Fanyang Meng, Yilin Zhu, Yixiao Ma, Jiele Wu, Jiyun Zou, and Kaicheng Yang. 2020. Ch-sims: A chinese multimodal sentiment analysis dataset with fine-grained annotation of modality. InProceedings of the 58th annual meeting of the association for computational linguistics. 3718–3727
2020
-
[61]
Wenmeng Yu, Hua Xu, Ziqi Yuan, and Jiele Wu. 2021. Learning modality-specific representations with self-supervised multi-task learning for multimodal senti- ment analysis. InProceedings of the AAAI conference on artificial intelligence, Vol. 35. 10790–10797
2021
-
[62]
Amir Zadeh, Minghai Chen, Soujanya Poria, Erik Cambria, and Louis-Philippe Morency. 2017. Tensor fusion network for multimodal sentiment analysis. InPro- ceedings of the 2017 conference on empirical methods in natural language processing. 1103–1114
2017
-
[63]
Amir Zadeh, Paul Pu Liang, Navonil Mazumder, Soujanya Poria, Erik Cambria, and Louis-Philippe Morency. 2018. Memory fusion network for multi-view sequential learning. InProceedings of the AAAI conference on artificial intelligence, Vol. 32
2018
-
[64]
Amir Zadeh, Rowan Zellers, Eli Pincus, and Louis-Philippe Morency. 2016. Multi- modal sentiment intensity analysis in videos: Facial gestures and verbal messages. IEEE Intelligent Systems31, 6 (2016), 82–88
2016
-
[65]
AmirAli Bagher Zadeh, Paul Pu Liang, Soujanya Poria, Erik Cambria, and Louis- Philippe Morency. 2018. Multimodal language analysis in the wild: Cmu-mosei dataset and interpretable dynamic fusion graph. InProceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2236–2246
2018
-
[66]
Zhihong Zeng, Maja Pantic, Glenn I Roisman, and Thomas S Huang. 2007. A survey of affect recognition methods: audio, visual and spontaneous expressions. InProceedings of the 9th international conference on Multimodal interfaces. 126– 133
2007
-
[67]
Haoyu Zhang, Yu Wang, Guanghao Yin, Kejun Liu, Yuanyuan Liu, and Tianshu Yu. 2023. Learning language-guided adaptive hyper-modality representation for multimodal sentiment analysis. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 756–767
2023
-
[68]
Miao Zhou, Lina Yang, Thomas Wu, Dongnan Yang, and Xinru Zhang. 2025. Dual-Path Dynamic Fusion with Learnable Query for Multimodal Sentiment Analysis. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 11366–11376
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.