Recognition: no theorem link
FEEL: Quantifying Heterogeneity in Physiological Signals for Generalizable Emotion Recognition
Pith reviewed 2026-05-10 18:20 UTC · model grok-4.3
The pith
Evaluating 16 model types on 19 datasets shows that contrastive pretraining plus handcrafted features handles variation in devices and settings best for physiological emotion recognition.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Through the FEEL benchmark we show that fine-tuned contrastive signal-language pretraining models achieve the highest F1 scores across arousal and valence tasks in 71 of 114 evaluations, simpler models such as Random Forests, LDA, and MLP stay competitive in 36 evaluations, and handcrafted-feature models outperform raw-segment models in 107 of 114 cases. Cross-dataset tests further establish that models trained on real-life recordings transfer to laboratory and constraint-based data with F1 scores of 0.79 and 0.78, expert-labeled training transfers to stimulus-labeled and self-reported data with F1 scores of 0.72 and 0.76, and lab-device models transfer to custom wearables and the Empatica E
What carries the argument
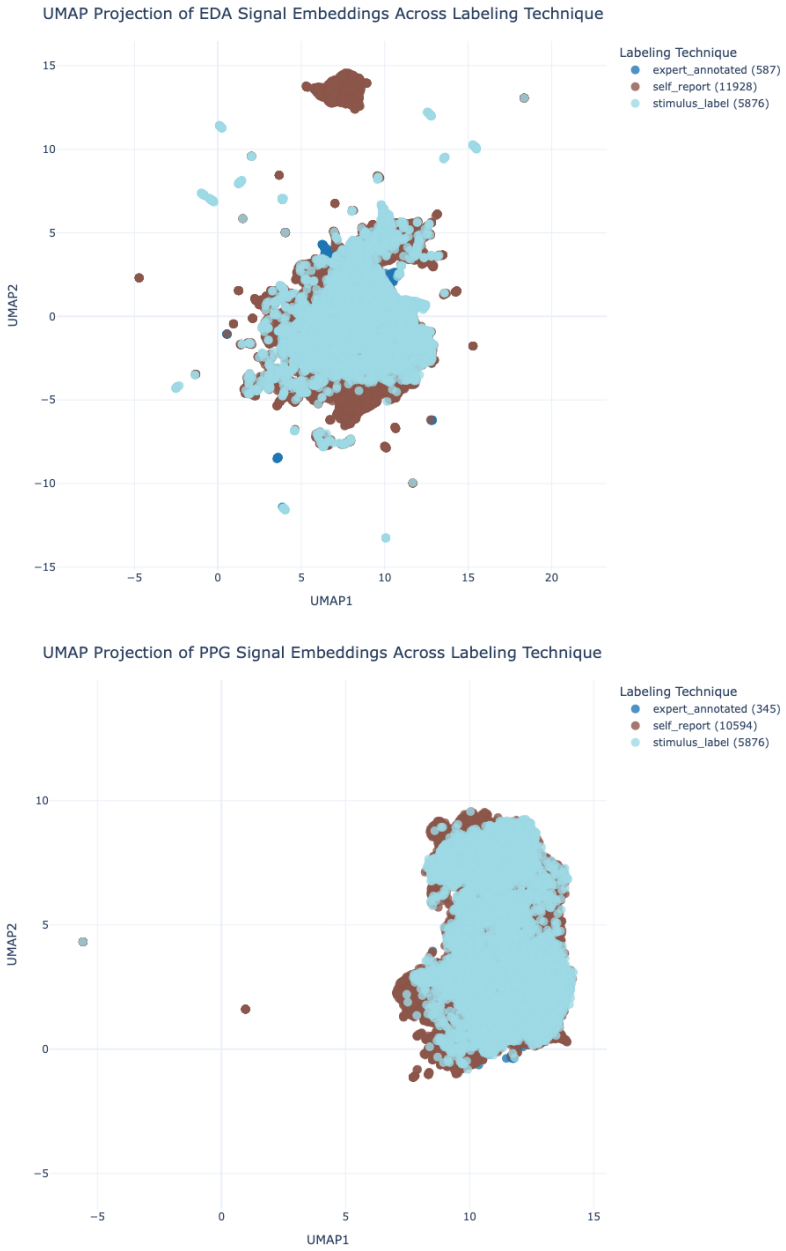
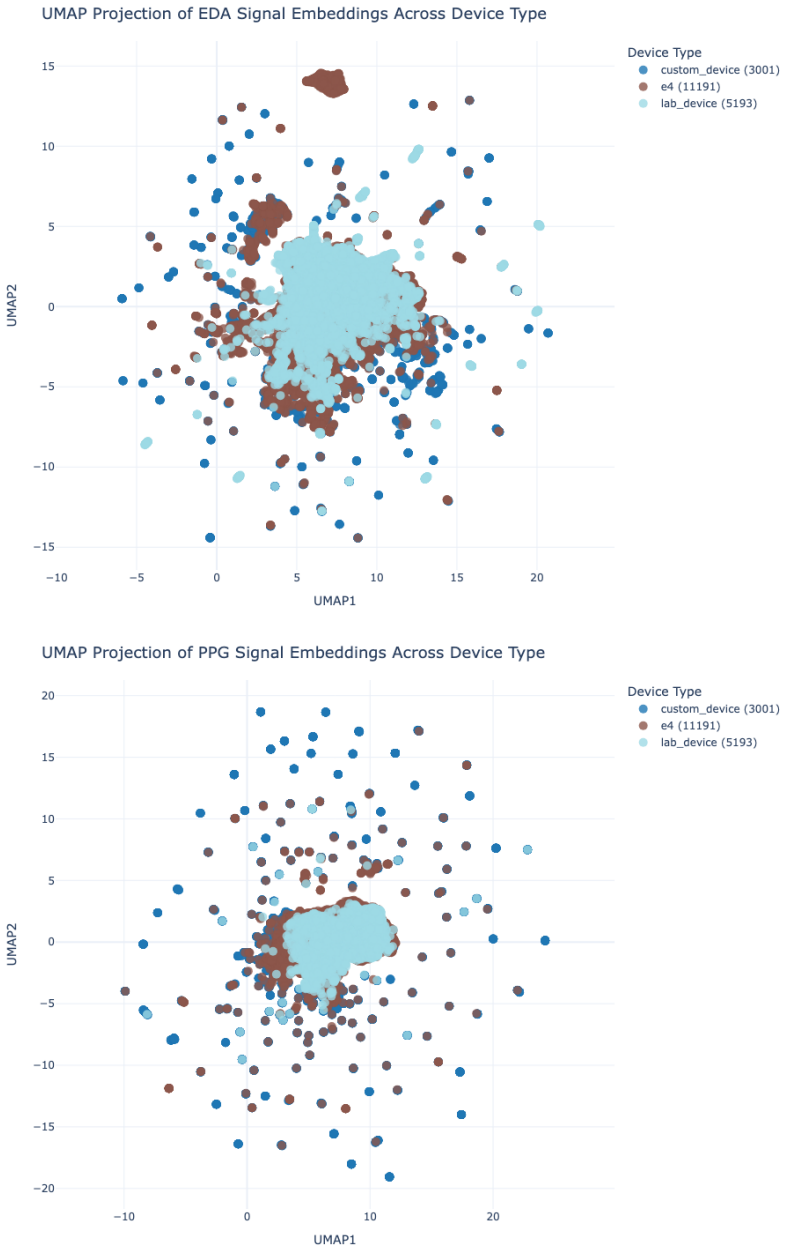
The FEEL cross-dataset evaluation protocol that measures within- and between-dataset performance of 16 architectures on 19 public EDA and PPG datasets for arousal and valence classification.
If this is right
- Training on real-life setting data produces models that reach F1 of 0.79 on lab settings and 0.78 on constraint-based settings.
- Expert-annotated training data transfers to stimulus-labeled datasets at F1 0.72 and to self-reported datasets at F1 0.76.
- Models trained on laboratory devices transfer to custom wearable devices at F1 0.81 and to the Empatica E4 at F1 0.73.
- Handcrafted features remain essential for performance in low-resource, noisy physiological signal environments.
Where Pith is reading between the lines
- Developers of consumer wearable apps could reduce retraining costs by adopting the handcrafted-feature pipelines and contrastive pretraining shown to transfer across device types.
- Future studies should include streaming or continuous-recording test sets to check whether the observed cross-dataset robustness holds in real-time deployment.
- The transfer patterns suggest that standardizing a small set of physiologically motivated features may be more practical than collecting ever-larger labeled datasets for every new sensor.
Load-bearing premise
The 19 selected public datasets together capture enough of the real variation in devices, settings, and labeling practices to support conclusions about generalization to new conditions.
What would settle it
Train the reported top models on the existing datasets and test them on a newly collected EDA/PPG dataset recorded with an unseen wearable in everyday conditions using only self-reported labels; the claim fails if F1 on both arousal and valence drops below the within-dataset levels shown in the paper.
Figures














read the original abstract
Emotion recognition from physiological signals has substantial potential for applications in mental health and emotion-aware systems. However, the lack of standardized, large-scale evaluations across heterogeneous datasets limits progress and model generalization. We introduce FEEL, the first large-scale benchmarking study of emotion recognition using electrodermal activity (EDA) and photoplethysmography (PPG) signals across 19 publicly available datasets. We evaluate 16 architectures spanning traditional machine learning, deep learning, and self-supervised pretraining approaches, structured into four representative modeling paradigms. Our study includes both within-dataset and cross-dataset evaluations, analyzing generalization across variations in experimental settings, device types, and labeling strategies. Our results showed that fine-tuned contrastive signal-language pretraining (CLSP) models (71/114) achieve the highest F1 across arousal and valence classification tasks, while simpler models like Random Forests, LDA, and MLP remain competitive (36/114). Models leveraging handcrafted features (107/114) consistently outperform those trained on raw signal segments, underscoring the value of domain knowledge in low-resource, noisy settings. Further cross-dataset analyses reveal that models trained on real-life setting data generalize well to lab (F1 = 0.79) and constraint-based settings (F1 = 0.78). Similarly, models trained on expert-annotated data transfer effectively to stimulus-labeled (F1 = 0.72) and self-reported datasets (F1 = 0.76). Moreover, models trained on lab-based devices also demonstrated high transferability to both custom wearable devices (F1 = 0.81) and the Empatica E4 (F1 = 0.73), underscoring the influence of heterogeneity. More information about FEEL can be found on our website https://alchemy18.github.io/FEEL_Benchmark/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces FEEL, the first large-scale benchmarking study of emotion recognition from EDA and PPG signals across 19 public datasets. It evaluates 16 architectures spanning traditional ML, deep learning, and self-supervised pretraining in four paradigms, reporting within- and cross-dataset results. Key findings include fine-tuned CLSP models achieving highest F1 in 71/114 cases, handcrafted-feature models outperforming raw-signal models in 107/114 cases, and cross-dataset transfer F1 scores of 0.79 (real-life to lab), 0.78 (to constraint-based), 0.72-0.76 (annotation types), and 0.73-0.81 (device types).
Significance. If statistically supported, this provides a valuable reference benchmark quantifying heterogeneity and generalization in physiological emotion recognition, with practical implications for mental health and affective computing applications. The scale (19 datasets, multiple paradigms) and public website are strengths that could guide future work on robust models.
major comments (2)
- [Results] Results section: The central claims of CLSP superiority (71/114 wins) and handcrafted-feature outperformance (107/114) rest on aggregated win counts of F1 scores without reported confidence intervals, paired statistical tests (e.g., McNemar or Wilcoxon), or weighting by dataset size/class balance. Given the heterogeneity in the 19 datasets, these aggregates may not reliably establish consistent superiority.
- [Cross-dataset evaluation] Cross-dataset transfer subsection: The reported transfer F1 scores (e.g., 0.79 real-life to lab, 0.81 lab-device to custom wearable) are single point estimates with no per-pair variances, standard errors, or significance tests against within-dataset baselines. This is load-bearing for the generalization claims across experimental settings, labeling strategies, and device types.
minor comments (2)
- [Abstract] Abstract: The parenthetical counts (71/114, 107/114) would benefit from a brief parenthetical explanation of what the denominator represents (e.g., total dataset-task combinations) to improve immediate readability.
- [Methods] The manuscript could add a summary table listing the 19 datasets with key metadata (size, setting, device, labeling method) to support the heterogeneity analysis.
Simulated Author's Rebuttal
We thank the referee for their positive assessment of the paper's significance and for the constructive major comments. We address each point below, agreeing that additional statistical rigor can strengthen the presentation of our results.
read point-by-point responses
-
Referee: [Results] Results section: The central claims of CLSP superiority (71/114 wins) and handcrafted-feature outperformance (107/114) rest on aggregated win counts of F1 scores without reported confidence intervals, paired statistical tests (e.g., McNemar or Wilcoxon), or weighting by dataset size/class balance. Given the heterogeneity in the 19 datasets, these aggregates may not reliably establish consistent superiority.
Authors: We appreciate this observation. The win counts serve as an intuitive aggregate metric to summarize performance across 114 classification tasks (arousal and valence from 19 datasets, with multiple models). Given the substantial heterogeneity in dataset sizes, experimental conditions, and class balances, we chose not to weight by size to avoid biasing toward larger datasets. However, we agree that confidence intervals and statistical tests would enhance the claims. In the revision, we will add bootstrap-derived 95% confidence intervals for the win proportions and perform non-parametric paired tests (e.g., Wilcoxon signed-rank on per-task F1 differences) to assess if the observed superiorities are statistically significant. This addresses the concern about reliability amid heterogeneity. revision: yes
-
Referee: [Cross-dataset evaluation] Cross-dataset transfer subsection: The reported transfer F1 scores (e.g., 0.79 real-life to lab, 0.81 lab-device to custom wearable) are single point estimates with no per-pair variances, standard errors, or significance tests against within-dataset baselines. This is load-bearing for the generalization claims across experimental settings, labeling strategies, and device types.
Authors: Thank you for highlighting this. The reported F1 values are averages over the multiple cross-dataset transfer pairs within each category (e.g., all real-life to lab transfers). To provide more transparency, we will include the standard deviation across these pairs and report the number of pairs for each aggregate in the revised manuscript. Additionally, we will conduct significance tests comparing the cross-dataset F1 to the corresponding within-dataset baselines using appropriate paired tests. This will better substantiate the generalization findings. revision: yes
Circularity Check
No circularity: purely empirical benchmarking with no derivations or self-referential reductions
full rationale
The paper conducts a large-scale empirical evaluation of 16 model architectures (traditional ML, deep learning, self-supervised) on 19 public EDA/PPG datasets for arousal/valence classification. All reported results consist of direct F1 scores from within- and cross-dataset training/evaluation runs; no equations, first-principles derivations, fitted parameters presented as predictions, or uniqueness theorems appear. Aggregated counts (71/114, 107/114) and transfer F1 values are simple tallies of experimental outcomes, not reductions to inputs by construction. No self-citations are invoked to justify load-bearing premises, and the study is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
Impact of Validation Strategy on Machine Learning Performance in EEG-Based Alcoholism Classification
Nested cross-validation reveals optimistic bias in standard validation for EEG alcoholism classification, with AdaBoost reaching 78.3% accuracy and most model differences not statistically significant per McNemar's test.
Reference graph
Works this paper leans on
-
[1]
doi: 10.1038/s41597-021-00945-4
ISSN 2052-4463. doi: 10.1038/s41597-021-00945-4. URL https://www.nature.com/ articles/s41597-021-00945-4. Publisher: Nature Publishing Group. Jainendra Shukla, Miguel Barreda-Ángeles, Joan Oliver, G. C. Nandi, and Domènec Puig. Feature Ex- traction and Selection for Emotion Recognition from Electrodermal Activity.IEEE Transactions on Affective Computing, ...
-
[2]
URL https://www.ahajournals.org/doi/abs/ 10.1161/CIRCEP.111.964973
doi: 10.1161/CIRCEP.111.964973. URL https://www.ahajournals.org/doi/abs/ 10.1161/CIRCEP.111.964973. Rui Wang, Fanglin Chen, Zhenyu Chen, Tianxing Li, Gabriella Harari, Stefanie Tignor, Xia Zhou, Dror Ben-Zeev, and Andrew T. Campbell. StudentLife: assessing mental health, academic performance and behavioral trends of college students using smartphones. InP...
-
[3]
0_back" were considered low in cognitive demand and thus assigned low arousal and positive 20 valence. Conversely, tasks labeled as
Institutional review board (IRB) approvals or equivalent for research with human subjects 17 Question: Does the paper describe potential risks incurred by study participants, whether such risks were disclosed to the subjects, and whether Institutional Review Board (IRB) approvals (or an equivalent approval/review based on the requirements of your country ...
2018
-
[4]
• Low Arousal:
Textual Prompts for Arousal Classification: • High Arousal:"The participant felt a strong physical reaction, like a racing heart or tense body, and experienced high-energy emotions such as excitement, enthusiasm, surprise, anger, and nervousness." • Low Arousal:"The participant felt low energy and relaxed, with calm emotions like peacefulness, relaxation,...
-
[5]
The participant felt bad and was in a negative mood, with emotions like sadness, fear, anger, worry, hopelessness, and frustration
Textual Prompts for Valence Classification: • Negative Valence:"The participant felt bad and was in a negative mood, with emotions like sadness, fear, anger, worry, hopelessness, and frustration." • Positive Valence:"The participant experienced a positive mood characterized by emotions such as happiness, joy, gratitude, serenity, interest, hope, pride, am...
-
[6]
Strong physical reaction with intense negative emotions like anger, fear, frustration, anxiety, or panic
Textual Prompts for Four Class Classification: • High Arousal Negative Valence:"Strong physical reaction with intense negative emotions like anger, fear, frustration, anxiety, or panic." • High Arousal Positive Valence:"Strong physical activation with energizing positive emotions like joy, enthusiasm, exhilaration, or amusement." • Low Arousal Negative Va...
-
[7]
Cross-Setting Generalization is Asymmetric but Promising • Real → Lab/Constraint:Models trained on real-world data generalized well to lab and constraint-based settings (F1 up to 0.79 for valence), particularly with CLSP-based models and EDA input. • Constraint → Real:Constraint-trained models showed strong transferability to real-world data, achieving th...
-
[8]
Cross-Label Generalization Benefits from High-Quality Annotations 32 • Expert-Annotated → Self/Stimulus:Expert-annotated training led to strong generalization across label types (F1 up to 0.76 for valence), showing that high-quality temporal labels help bridge subjective and task-derived annotations. • Self-report → Expert/Stimulus:Surprisingly strong per...
-
[9]
Cross-Device Generalization is Strongest with High-Fidelity Sensors • Wearable → Custom:Training on commercial wearable devices transferred well to custom wearables (F1 up to 0.82 for valence), especially using CLSP models, suggesting sensor fidelity supports robust feature learning. • Wearable → Lab-Based Device: Transfer from Wearable (E4) to lab-based ...
-
[10]
Influence of Demographics on Generalization:Cross-demographic evaluations indicate strong transferability across gender and age for valence classification (F1 = 0.71 and 0.73, respectively). In contrast, arousal transfer remains weak, nearing random performance, implying that arousal- related physiological patterns are more susceptible to individual varia...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.